はじめに
Treasure Dataを使ってアクセスログの可視化を行なった際に、分析クエリの設計のポイントを説明します。
ページ遷移するアプリケーションで、特定のページのアクセス状況を可視化します。各ページが表示されるタイミングで、アクセスログとして、リクエスト日時、ユーザID、セッションID、ページIDが出力されているとします。
また、本記事で紹介するクエリはPrestoで実行しています。
分析対象のモデル
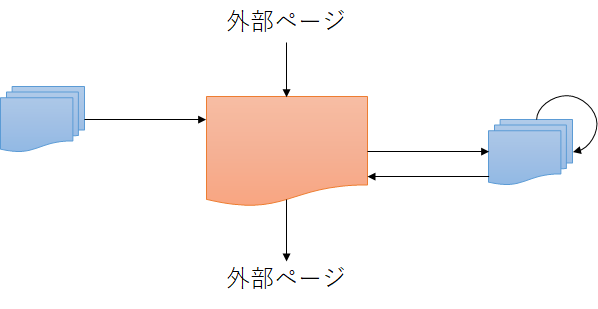
アクセスログ(access_log)
UU数、PV数、セッション数を計測する
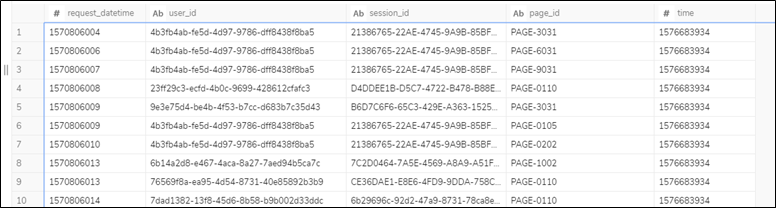
計測対象のページ(ページIDの「PAGE-0110」ページを対象とする。以下同じ)のUU数、PV数、セッション数はクエリ(LogAnalysis01.sql)で計測できます。
select
page_id,
count(distinct user_id) as uu,
count(distinct session_id) as session_count,
count(1) as pv
from
access_log
where
page_id = 'PAGE-0110'
group by
page_id
クエリの実行結果のイメージは以下となります。

遷移元、遷移先のページを計測する
次に計測対象のページを閲覧するきっかけとなったページ(遷移元)、計測対象のページの閲覧後に訪問したページ(遷移先)の情報を可視化します。
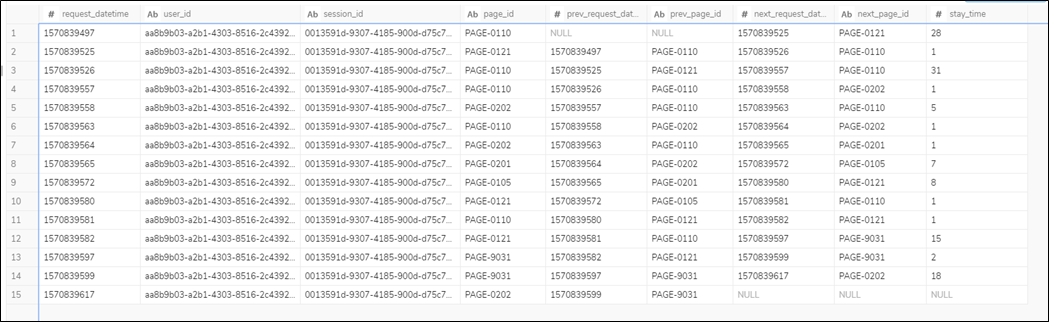
Windows関数を使用して、アクセスログを加工します(Step1.sql)。LAG関数、LEAD関数を使うと指定したパーティション内の前後のレコードを参照できます。
セッションID毎にリクエスト日時でソートしたパーティションを指定し、LAG関数で遷移元のリクエスト日時、ページIDを、LEAD関数で遷移先のリクエスト日時、ページIDを取得しています。
また、対象ページの滞在時間を 遷移先のリクエスト日時 - 計測対象のページのリクエスト日時 で計算しています。
select
request_datetime,
user_id,
session_id,
page_id,
LAG(request_datetime) OVER (PARTITION BY session_id order by request_datetime) as prev_request_datetime,
LAG(page_id) OVER (PARTITION BY session_id order by request_datetime) as prev_page_id,
LEAD(request_datetime) OVER (PARTITION BY session_id order by request_datetime) as next_request_datetime,
LEAD(page_id) OVER (PARTITION BY session_id order by request_datetime) as next_page_id,
LEAD(request_datetime) OVER (PARTITION BY session_id order by request_datetime) - request_datetime as stay_time
from
access_log
クエリ実行後のテーブルのイメージは以下となります。LAG関数、LEAD関数で前後のレコードが存在しない場合に値は```NULL``になります。
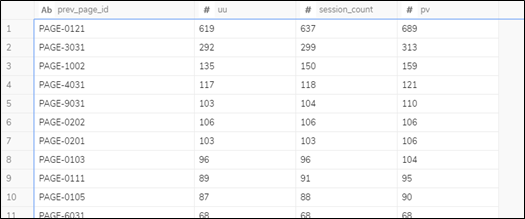
access_log_step1 に対してクエリ(LogAnalysis02.sql)を実行すると、遷移元のページ毎のUU数、PV数、セッション数を計測できます。
select
prev_page_id,
count(distinct user_id) as uu,
count(distinct session_id) as session_count,
count(1) as pv
from
access_log_step1
where
page_id = 'PAGE-0110'
and prev_page_id is not null
group by
prev_page_id
order by
4 desc
クエリの実行結果のイメージは以下となります。 prev_page_id を next_page_id に変更すると遷移先のページを計測できます。
外部サイトからの訪問数、離脱数、直帰数を計測する
access_log_step1 を利用して、さらに外部サイトからの訪問数、離脱数、直帰数を計測できます。
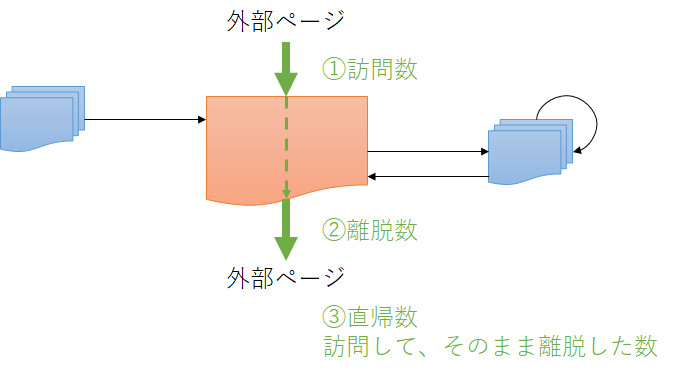
外部サイトから直接、計測対象のページを訪問した訪問数は、遷移元の情報が存在しない条件と同義になります。
クエリ(LogAnalysis03.sql)を実行すると、外部サイトから訪問した場合の計測対象のページUU数、PV数、セッション数を計測できます。
select
page_id,
count(distinct user_id) as uu,
count(distinct session_id) as session_count,
count(1) as pv
from
access_log_step1
where
page_id = 'PAGE-0110'
and prev_page_id is null
group by
page_id
クエリの実行結果のイメージは以下となります。

クエリ(LogAnalysis03.sql)のWHERE句の条件 prev_page_id is null を変更することで、離脱数、直帰数を計測できます。
離脱数は、計測対象ページを閲覧したあとそのまま外部サイトに移動した場合で、計測対象ページの遷移先が存在しない条件 next_page_id is null となります。
直帰数は、外部サイトから計測対象ページを訪問したあとそのまま外部サイトに移動した場合で、計測対象ページの遷移元、遷移先が存在しない条件 prev_page_id is null and next_page_id is null となります。
計測対象のページから遷移後のページ遷移回数を計測する
計測対象のページから次のページに遷移した後、再び計測対象のページに戻ってくるまで、または遷移先で離脱するまでに回遊したページ遷移回数を計測します。
access_log_step1 を順番に加工して、計測に必要な情報を求めます。
まず、クエリ(access_log_step2.sql)では、計測対象のページから再び計測対象のページに戻ってくるまでの時間( lead_request_datetime )を付加しています。
便宜上、遷移先で離脱した場合に lead_request_datetime = 9999999999 の値が入るようにしています。
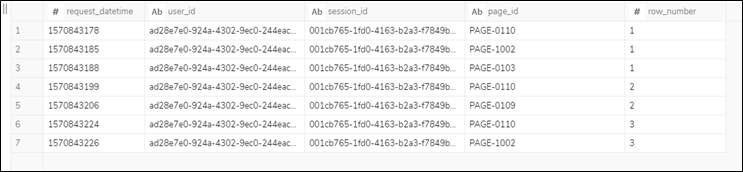
WHERE句の条件に計測対象ページのページIDを指定し絞り込んだ後で、LEAD関数で次のレコードを取得しているところがポイントになります。また、同一セッションIDの中のレコードを一意に識別できるようにROW_NUMBER関数で番号を付加しています。
select
request_datetime,
user_id,
session_id,
page_id,
COALESCE(LEAD(request_datetime) OVER (PARTITION BY session_id order by request_datetime), 9999999999) as lead_request_datetime,
ROW_NUMBER() over (PARTITION BY session_id order by request_datetime) as row_number
from
access_log
where
page_id = 'PAGE-0110'
クエリの実行結果のイメージは以下となります。

次に、 access_log_step1 と access_log_step2 をJOINして、計測対象のページから再び計測対象のページに戻ってくるまでのレコードを1つのグループにまとめます。 access_log_step1 のテーブルに access_log_step2.row_number を付加しています。
select
access_log_step1.request_datetime,
access_log_step1.user_id,
access_log_step1.session_id,
access_log_step1.page_id,
access_log_step2.row_number
from
access_log_step1
join
access_log_step2
on
access_log_step1.session_id = access_log_step2.session_id
and access_log_step1.request_datetime >= access_log_step2.request_datetime
and access_log_step1.next_request_datetime < access_log_step2.lead_request_datetime
クエリの実行結果のイメージは以下となります。
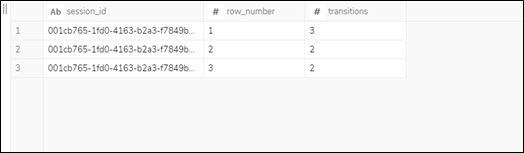
access_log_step3 をセッションID、row_numberでグループ化すると、回遊したページ数を計測できます。(LogAnalysis04.sql)
select
session_id,
row_number,
count(1) as transitions
from
access_log_step3
group by
session_id,
row_number
クエリの実行結果のイメージは以下となります。
LogAnalysis04.sql の実行結果をさらに、集約することでユーザ全体のページ遷移回数の傾向がわかります。(LogAnalysis05.sql)
select
MIN(transitions) as transitions_min,
APPROX_PERCENTILE(transitions, 0.25) AS transitions_p25,
APPROX_PERCENTILE(transitions, 0.5) AS transitions_median,
APPROX_PERCENTILE(transitions, 0.75) AS transitions_p75,
MAX(transitions) as transitions_max,
ROUND(AVG(transitions), 2) as transitions_avg
from
LogAnalysis04
クエリの実行結果のイメージは以下となります。

おわりに
本記事ではアクセスログの可視化の方法について紹介しました。
SQLのクエリで分析できるものの、識別キーを持たないログを扱う場合にテーブルの結合条件で苦労する部分が多く、Windows関数を使った中間テーブルを設計していくことで解決できるところが多くあります。
また本記事では割愛していますが、実際にシステムで出力するログを扱う際にはノイズとなるデータを除くことや、同一の日時で出力されたログの扱いを決めるところも大切になります。特に、Window関数を使う場合には、指定したパーティションのなかでレコードの並び順が一意になるようにログ出力を設計する必要があります。