threadingとmultiprocessing
現代の主なOSと言ったら、Mac OS,UNIX,Linux,Windowsなどがあります。これらのOSは「マルチタスク」機能をサポートしています。
マルチタスクとは?と思うかもしれませんが、例えばブラウザーを立ち上げて、音楽聴きながら、Wordでレポートを書くというシチュエーションでは、少なくとも3つのタスクが同時進行しています。そして、表のタスク以外に、裏ではOS関連の様々なタスクがこっそり動いています。
マルチコアのCPUで、マルチタスクが処理できるのは理解しやすいですが、シングルコアのCPUでもマルチタスクが可能です。OSはそれぞれのタスクを交替に実行しています。例えば、タスク1を0.01秒、タスク2を0.01秒、タスク3を0.01秒、タスク1を0.01秒......繰り返して実行していきます。CPUは速いので、ほぼ同時進行のように感じます。この交替実行のことをしばしば「並行処理(concurrent computing)」と言います。
もちろん、シングルコアCPUはあくまでも交替で実行しているので、本当の意味での同時進行はマルチコアCPUのみ可能です。マルチコアCPUである時刻に複数のタスクをそれぞれのコアで同時に処理するのを「並列処理(parallel computing)」と言います。ほとんどの場合、実行しているタスクの数はコアの数を遥かに超えるため、マルチコアにおいても「交替実行」の作業が行われています。
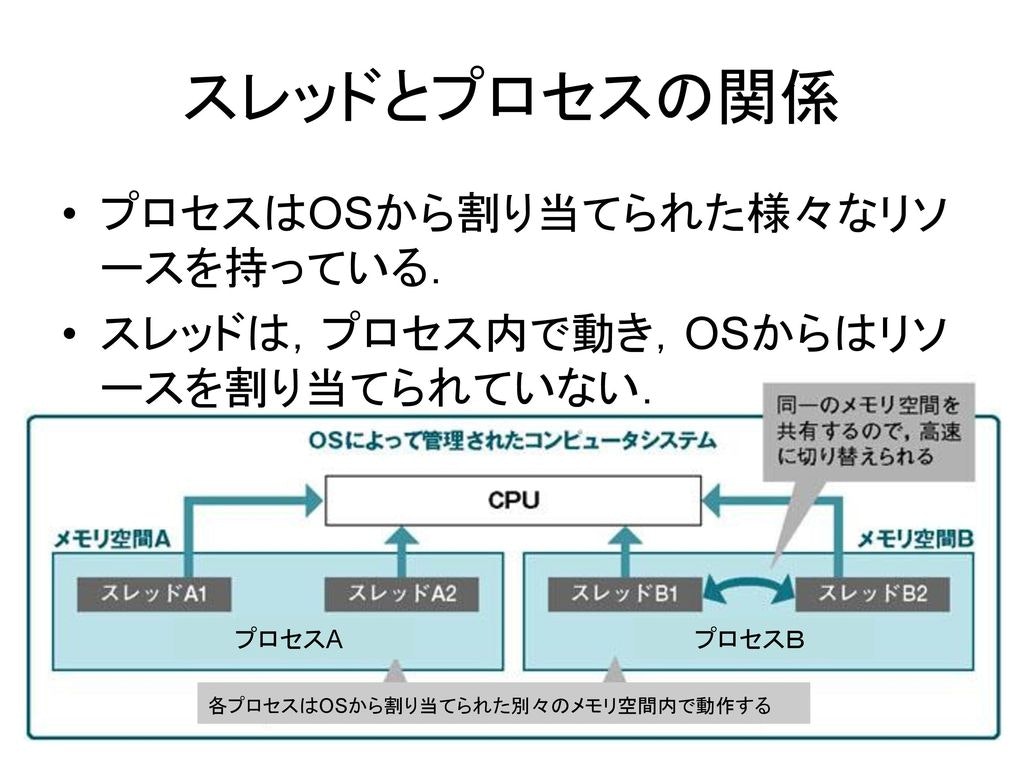
OSにとって、1個のタスクは1個のプロセス(Process)になります。例えば、ブラウザーを立ち上げると、1個のブラウザープロセスが作成されます。同じく、Wordを開いたら、Wordプロセスが作られます。
1個のプロセスは1個の処理とは限りません。例えば、Wordではユーザーの入力をモニタリングする処理と、スペルチェック、UI表示などたくさんの処理が行われています。これらの「サブタスク」はスレッド(Thread)と言います。1個のプロセスには最低限1個のスレッドがあります。複数のスレッドがある時、プロセスと同じく交替に実行します。
Pythonでマルチタスクを同時に処理したい時は主に2通りのやり方があります。
- 複数のプロセスを立ち上げます。それぞれ1個のスレッドしか持ってないですが、プロセスが複数あるため、複数のタスクを処理できます。
- 1個のプロセスの中で複数のスレッドを立ち上げます。
もちろん、複数のプロセスで複数のスレッドを立ち上げることもできますが、モデルが複雑になるため、あまりお勧めしません。
マルチタスクを処理する時、タスク間の通信や協力が必要だったり、タスク2が実行する時タスク1の一時停止が必要だったり、タスク3とタスク4が同時進行できなかったりするケースがあるため、プログラムがやや複雑になります。
(出典:システムソフトウェア講義の概要)
1. threading
Unix系のOSではスレッド周りで主に以下のシステムコール関数が使えます。
| 関数 | 説明 |
|---|---|
| start() | スレッドを開始する |
| setName() | スレッドに名前をつける |
| getName() | スレッドの名前を取得 |
| setDaemon(True) | スレッドをデーモンにする |
| join() | スレッドの処理が終わるまで待機 |
| run() | スレッドの処理をマニュアルで実行する |
Pythonのスレッドはプロセスでシミュレートしたものではなく、本物のシステムスレッドで、UnixやLinux系ではPOSIXスレッドを、WindowsではWindowsスレッドを利用します。これらのスレッドは完全にOSによって管理されています。Pythonの標準ライブラリーから、_threadとthreadingの2つのモジュールが使えます。_threadは低レベルのモジュールで、threadingはそれをカプセル化したモジュールです。なので、通常threadingを使います。
1-1. インスタンス化
関数などを導入してThreadのインスタンスを作成し、startで開始させると、スレッドを立ち上げられます。
import threading
import time
def run(n):
# threading.current_thread().nameはgetName()を呼び出す
print("task: {} (thread name: {})".format(n, threading.current_thread().name))
time.sleep(1)
print('2s')
time.sleep(1)
print('1s')
time.sleep(1)
print('0s')
time.sleep(1)
t1 = threading.Thread(target=run, args=("t1",))
t2 = threading.Thread(target=run, args=("t2",), name='Thread T2') # ここではsetName()が呼び出される
# start()
t1.start()
t2.start()
# join()
t1.join()
t2.join()
# join()を呼び出したため
# メインスレッドは上記のスレッドが終わるまで待機し
# 全部終わったらprintする
print(threading.current_thread().name)
実行結果:
task: t1 (thread name: Thread-1)
task: t2 (thread name: Thread T2)
2s
2s
1s
1s
0s
0s
MainThread
t1とt2が交替で実行されていることが確認できます。交替ルールの1つはIO操作(ここではprint操作が該当する)の後で、1.5 GILのところでまた詳しく説明します。
1-2. カスタマイズ
Threadを継承して、スレッドクラスのrunメソッドをカスタマイズした上での利用も可能です。
import threading
import time
class MyThread(threading.Thread):
def __init__(self, n):
super(MyThread, self).__init__()
self.n = n
# run()を書き直す
def run(self):
print("task: {}".format(self.n))
time.sleep(1)
print('2s')
time.sleep(1)
print('1s')
time.sleep(1)
print('0s')
time.sleep(1)
t1 = MyThread("t1")
t2 = MyThread("t2")
t1.start()
t2.start()
実行結果:
task: t1
task: t2
2s
2s
1s
1s
0s
0s
1-3. スレッド数を計算
active_countでアクティブなスレッド数を数えることができます。ただし、REPL環境ですと、モニタリングするスレッドが複数存在するため、予想したスレッド数より多くなります。
以下のコードをスクリプトで実行してください。
import threading
import time
def run(n):
print("task: {}".format(n))
time.sleep(1)
for i in range(1, 4):
t = threading.Thread(target=run, args=("t{}".format(i),))
t.start()
time.sleep(0.5)
print(threading.active_count())
実行結果:
task: t1
task: t2
task: t3
4
メインスレッドのprintが実行された時他のスレッドはまだ実行中のため、スレッド数 = 3 + 1(メインスレッド)。
import threading
import time
def run(n):
print("task: {}".format(n))
time.sleep(0.5)
for i in range(1, 4):
t = threading.Thread(target=run, args=("t{}".format(i),))
t.start()
time.sleep(1)
print(threading.active_count())
実行結果:
task: t1
task: t2
task: t3
1
実行時間を調節し、メインスレッドのprintを遅らせることで、アクティブスレッド数がメインスレッドのみの1になります。
1-4. デーモンスレッド
スレッドをデーモンとして起動します。
import threading
import time
def run(n):
print("task: {}".format(n))
time.sleep(1)
print('3')
time.sleep(1)
print('2')
time.sleep(1)
print('1')
for i in range(1, 4):
t = threading.Thread(target=run, args=("t{}".format(i),))
# setDaemon(True)
t.setDaemon(True)
t.start()
time.sleep(1.5)
print('スレッド数: {}'.format(threading.active_count()))
実行結果:
task: t1
task: t2
task: t3
3
3
3
スレッド数: 4
t1、t2、t3はメインスレッドのデーモンスレッドに設定したので、メインスレッドの終了とともに停止します。
例えば、Wordのスペルチェックはデーモンスレッドで、無限ループで実行されますが、メインスレッドが落ちると一緒に落ちます。
1-5. GIL
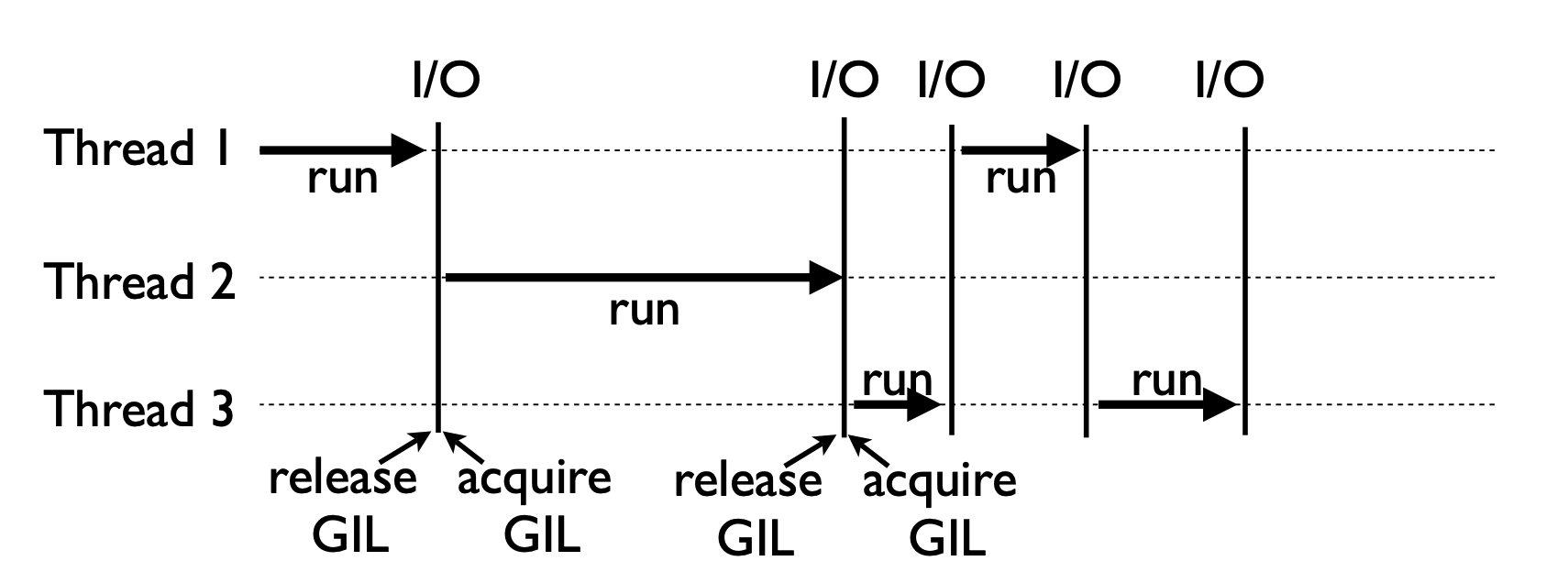
他のプログラミング言語で、マルチコアのCPUを利用する際、同時にコア数のスレッドが実行できます。しかし、CPythonでは1つのインタープリタープロセスでは、ある時刻において1つのスレッドしか実行されません。つまり、CPythonのマルチスレッドは完全に並行処理です。その理由はGIL(Global Interpreter Lock)にあります。
(出典:Understanding the Python GIL)
GILは1種の排他制御です。CPythonが設計された当初、データセキュリティー(1-6. スレッド制御で説明)やC言語のライブラリとの結合しやすさのために、GILを実装しました。ソースコードについてはここを参照してください。CPythonでは、スレッドを実行する時、GILを取得する必要があリます。GILはパスポートみたいなもので、GILを持ってないスレッドはCPUリソースを獲得できません。ちなみに、CPython以外のPython実装、例えばPyPyとJythonにGILは存在しません。また、GILの付いた有名な言語としてRubyが挙げられます。
1-5-1. CPythonでのマルチスレッドの手順
- リソースを取得
- GILをリクエストする
- PythonインタプリタはOSのネイティブスレッドを調達
- OSはCPUを操作して計算する
- GIL回収ルールを満たしたら、計算が終わっているか否か、GILが回収される
- 他のスレッドが上記手順を繰り返す
- GILがまた回ってきたら、再度GIL回収ルールが満たされるまで前回の引き続きを処理する(context switch)
1-5-2. 異なるバージョンのGIL回収ルール
- Python 3.2以前
- IO操作が発生したら回収
- ticksが100になったら回収
- ticksはGIL用のカウンターで、Python仮想処理の回数を記録する
- 100になったらGILが回収され、0にリセットする
-
sys.setcheckintervalで閾値を設定できる
- Python 3.2以降
- IO操作が発生したら回収
- ticksは廃棄された
- グローバル変数
gil_drop_requestが設置され、0の時は実行し続けて大丈夫だが、1になったらGILを回収 -
cv_wait(gil, TIMEOUT)でgil_drop_requestを制御 -
TIMEOUTで設定した時間を超えたら回収- デフォルトは5ms
実験として、簡単な無限ループを実行してみます。
import threading
import multiprocessing
def loop():
x = 0
while True:
x = x ^ 1
for i in range(multiprocessing.cpu_count()):
t = threading.Thread(target=loop)
t.start()

ご覧の通り、GILのせいで、シングルプロセスで、どんなに頑張っても、CPUの利用率は100%ぐらいに止まっています(クアッドコアのCPUで最大400%利用できるはず)。
1-5-3. 違う種類のタスクにおけるPythonプログラムの計算効率
- CPUバウンドタスク
- 一定時間後GILが回収され、スレッドを切り替えるため、余計に計算コストがかかり、遅くなります。
- IOバウンドタスク
- IO操作が行われる度に、スレッドを切り替えます。遅いファイルの読み書きなどを待たずに他の処理に回せるため、効率が良いです。
- CPU・IO混在タスク
- ケースバイケースにはなりますが、CPUバウンドタスクとIOバウンドタスクを違うスレッドで実行する時、Convoy Effectを注意しなければなりません。Convoy Effectは遅いタスクに引きずられて、システム全体が遅くなるという性質です。例えば、遅いCPUバウンドタスクと速いIOバウンドタスクをそれぞれのスレッドに実行させる時、処理が速くて本来スレッドの切り替えが不要なIOタスクは、GIL回収ルールによって処理ごとに切り替えが発生します。遅いCPUバウンドタスクは遅いので、毎回5msまで実行してまたGILがIOタスクのほうに回ってくるというようなタスクは、IOバウンドタスクは遅いCPUバウンドタスクに引きずられて、無駄な切り替えでシステム全体が遅くなります。
- マルチコアCPUを最大限利用したいなら、multiprocessingのほうがお勧めです。各プロセスには独自のGILが存在します。
1-6. スレッド制御
同じプロセスのスレッド間はリソースがシェアされます。そして、スレッドの切り替えは順番性がなくランダムに行われるため、データがおかしくなることがあります。
import threading
# 貯金額とする
balance = 0
def change_it(n):
# 出金と入金でプラマイ0になるはず
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(100000):
change_it(n)
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
上記のコードを何回か実行してみると分かると思いますが、結果が0でなくなります。
balance = balance + nは2つの不可分操作(atomic operation)に分割できます。
x = balance + n
balance = x
ここのxはローカル変数で、それぞれのスレッドは独自のxを持っています。上記のコードが順番に実行されると以下のようになります。
balance = 0 # 初期値
t1: x1 = balance + 5 # x1 = 0 + 5 = 5
t1: balance = x1 # balance = 5
t1: x1 = balance - 5 # x1 = 5 - 5 = 0
t1: balance = x1 # balance = 0
t2: x2 = balance + 8 # x2 = 0 + 8 = 8
t2: balance = x2 # balance = 8
t2: x2 = balance - 8 # x2 = 8 - 8 = 0
t2: balance = x2 # balance = 0
balance = 0 # 結果が正しい
しかし、順番が違うと結果も異なります。
balance = 0 # 初期値
t1: x1 = balance + 5 # x1 = 0 + 5 = 5
t2: x2 = balance + 8 # x2 = 0 + 8 = 8
t2: balance = x2 # balance = 8
t1: balance = x1 # balance = 5
t1: x1 = balance - 5 # x1 = 5 - 5 = 0
t1: balance = x1 # balance = 0
t2: x2 = balance - 8 # x2 = 0 - 8 = -8
t2: balance = x2 # balance = -8
balance = -8 # 結果が間違っている
このように、マルチスレッドにおいて計算結果が予測不可能になる現象をスレッドアンセーフ(Thread-unsafe)と言います。
これを解決するには、スレッドにロックをかけて制御する必要があります。
また、1-5. GILではCPythonが当初GILを採用した理由の1つは「データセキュリティー」と記載しました。PythonのGCは参照カウントベースで、参照カウントはスレッドセーフの操作ではないため、制御ロックが必要です。辞書やリストなどのデータ構造にロックを掛けると、性能が著しく落ちるため、CPythonは当時1番シンプルの方法であるグローバルなロック、つまりGILを採用したわけです。
1-6-1. 排他制御(mutex)
import threading
# 貯金額とする
balance = 0
def change_it(n):
# ロックを取得
lock.acquire()
global balance
balance = balance + n
balance = balance - n
# ロックを解放
lock.release()
def run_thread(n):
for i in range(100000):
change_it(n)
lock = threading.Lock() # ロックをインスタンス化
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
排他制御を使うことで、ロックが解放されるまで、他のスレッドがリソースにアクセスできません。こうすることで、計算結果は必ず0になります。
1-6-2. 再帰的排他制御
ネスト構造になったロックを再帰的に解除できる排他制御です。
import threading
# 貯金額とする
balance = 0
def add_it(n):
lock.acquire()
global balance
balance = balance + n
return balance
def sub_it(n):
lock.acquire()
global balance
balance = balance - n
return balance
def change_it(n):
# ロックを取得
lock.acquire()
global balance
balance = add_it(n)
balance = sub_it(n)
# 再帰的ににロックを解放
lock.release()
def run_thread(n):
for i in range(1000):
change_it(n)
lock = threading.RLock() # ロックをインスタンス化
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
ここではadd_itとsub_itの内部もロックを取得しています。再帰的排他制御を使用することで、それぞれのロックの解放をする必要がなく、一発で全部解放できます。ただし、非常に計算コストがかかるため、ループ数を減らしています。
1-6-3. 有限セマフォ(BoundedSemaphore)制御
排他制御は、ある時刻において、リソースを処理できるのは1つのスレッドのみに制限するのに対して、セマフォは一定数のスレッドの同時処理を許容する制限です。例えば、トイレに3つの便座があって、同時に3人が使ってて、他の人は並んで待つシチュエーションがセマフォに該当します。
import threading
import time
def run(n):
semaphore.acquire()
time.sleep(1)
print("current thread: {}\n".format(n))
semaphore.release()
semaphore = threading.BoundedSemaphore(5) # 5個のスレッドの同時処理を許容する
for i in range(22):
t = threading.Thread(target=run, args=("t-{}".format(i),))
t.start()
while threading.active_count() != 1:
pass # print(threading.active_count())
else:
print('-----全てのスレッドが終了した-----')
上記のコードを実行すると、5個ずつcurrent threadの文字列が出力されることが確認できます。
1-6-4. イベント(Event)制御
スレッドのイベントはメインスレッドが他のスレッドをコントロールするためのものです。Eventには以下のメソッドが提供されます。
| メソッド | 説明 |
|---|---|
| clear | flagをFalseにする |
| set | flagをTrueにする |
| is_set | flagがTrueの時Trueを返す |
| wait | flagをモニタリングし続ける;flagがFalseの時はブロッキング(blocking)する |
import threading
import time
event = threading.Event()
def lighter():
'''
flag=True: 青信号
flag=False: 赤信号
'''
count = 0
event.set() # 初期値は青信号
while True:
if 5 < count <= 10:
event.clear() # 赤信号にする
print("\33[41;1m赤信号...\033[0m")
elif count > 10:
event.set() # 青信号にする
count = 0
else:
print("\33[42;1m青信号...\033[0m")
time.sleep(1)
count += 1
def car(name):
while True:
if event.is_set(): # 青信号がどうかをチェック
print("[{}] 前進する...".format(name))
time.sleep(1)
else:
print("[{}] 赤信号のため、信号を待つ...".format(name))
event.wait()
# flag=Trueになるまでここでブロッキングする
print("[{}] 青信号のため、前進開始...".format(name))
light = threading.Thread(target=lighter,)
light.start()
car = threading.Thread(target=car, args=("MINI",))
car.start()
上記のコードで信号機と車のスレッド間の簡単な通信をイベントで実現しました。
1-6-5. タイマー(Timer)制御
タイマーを使って時間でスレッドを制御することもできます。
from threading import Timer
def hello():
print("hello, world")
t = Timer(1, hello)
t.start() # 1秒後helloが実行される
1-6-6. 条件(Condition)制御
条件判定でスレッドを制御する方法もあります。Conditionには以下のメソッドが提供されます。
| メソッド | 説明 |
|---|---|
| wait | 通知されるか引数のtimeout時間に達するまでスレッドをハングアップする |
| notify | ハングアップされたスレッド(デフォルトn=1)に通知する;ロックを取得した状態でしか使えない |
| notifyAll | ハングアップされた全てのスレッドに通知する |
import threading
import time
from random import randint
from collections import deque
class Producer(threading.Thread):
def run(self):
global stocks
while True:
if lock_con.acquire():
products = [randint(0, 100) for _ in range(5)]
stocks.extend(products)
print('生産者{}は{}を生産した。'.format(self.name, stocks))
lock_con.notify()
lock_con.release()
time.sleep(3)
class Consumer(threading.Thread):
def run(self):
global stocks
while True:
lock_con.acquire()
if len(stocks) == 0:
# 商品が無くなったら生産されるまで待つ
# notfifyされるまでスレッドをハングアップ
lock_con.wait()
print('お客様{}は{}を買った。在庫: {}'.format(self.name, stocks.popleft(), stocks))
lock_con.release()
time.sleep(0.5)
stocks = deque()
lock_con = threading.Condition()
p = Producer()
c = Consumer()
p.start()
c.start()
実行結果:
生産者Thread-1はdeque([73, 2, 93, 52, 21])を生産した。
お客様Thread-2は73を買った。在庫: deque([2, 93, 52, 21])
お客様Thread-2は2を買った。在庫: deque([93, 52, 21])
お客様Thread-2は93を買った。在庫: deque([52, 21])
お客様Thread-2は52を買った。在庫: deque([21])
お客様Thread-2は21を買った。在庫: deque([])
生産者Thread-1はdeque([6, 42, 85, 56, 76])を生産した。
お客様Thread-2は6を買った。在庫: deque([42, 85, 56, 76])
お客様Thread-2は42を買った。在庫: deque([85, 56, 76])
お客様Thread-2は85を買った。在庫: deque([56, 76])
お客様Thread-2は56を買った。在庫: deque([76])
お客様Thread-2は76を買った。在庫: deque([])
お客様に在庫を全部買われたら、生産者が5個商品を生産するという簡単なプログラムです。
1-6-7. バリア(Barrier)制御
指定された数のスレッドがバリアを通ったら、まとめて実行される制御です。例えば、オンライン対戦ゲームで、チームが指定人数になるまで一定時間待機するのをバリアで実装できます。Barrierには以下のメソッドが提供されます。
| メソッド | 説明 |
|---|---|
| wait | スレッドがバリアを通る;指定された数のスレッドが通ったら、waitしているスレッドが全部解放されます |
| reset | バリアを空にする;waitしているスレッドにBrokenBarrierErrorを返す |
| abort | バリアをbroke状態にする;現在の全てのスレッドが終了する;これ以降にバリアを通ろうとするスレッドにBrokenBarrierErrorを返す |
import threading
num = 4
def start_game():
print('{}人になったため、ゲーム開始。'.format(num))
lock = threading.Lock()
barrier = threading.Barrier(num, action=start_game)
class Player(threading.Thread):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def run(self):
try:
if not barrier.broken:
print('{}さんが参加しました。'.format(self.name))
barrier.wait(2)
except threading.BrokenBarrierError:
print('ゲーム開始できないため、{}が退出しました。'.format(self.name))
players = []
for i in range(10):
p = Player(name='Player {}'.format(i))
players.append(p)
for p in players:
p.start()
実行結果
Player 0さんが参加しました。
Player 1さんが参加しました。
Player 2さんが参加しました。
Player 3さんが参加しました。
4人になったため、ゲーム開始。
Player 4さんが参加しました。
Player 5さんが参加しました。
Player 6さんが参加しました。
Player 7さんが参加しました。
4人になったため、ゲーム開始。
Player 8さんが参加しました。
Player 9さんが参加しました。
ゲーム開始できないため、Player 8が退出しました。
ゲーム開始できないため、Player 9が退出しました。
スレッドはランダムに実行されるため、必ず上のような順番で出力されるわけではありません。ここでは、Player 8とPlayer 9のチーム(バリア)は時間内指定人数に達せなかったから、強制退出(BrokenBarrierError)されました。
1-7. ThreadLocal
スレッド間のデータは共有されるため、正確の出力を計算するためにロックをかける必要があるというのを説明しました。しかし、時々それぞれのスレッドに独自のローカル変数を処理させたい時があります。
import threading
import time
def print_local_x():
x = local.x
print('{}のx: {}'.format(threading.current_thread().name, x))
def set_thread_local_x(x):
local.x = x
print('{}のxを設定しました'.format(threading.current_thread().name))
time.sleep(1)
print_local_x()
# グローバルスコープでThreadLocalオブジェクトを作成
local = threading.local()
t1 = threading.Thread(target=set_thread_local_x, args=(5, ), name="Thread-A")
t2 = threading.Thread(target=set_thread_local_x, args=(10, ), name="Thread-B")
t1.start()
t2.start()
t1.join()
t2.join()
実行結果:
Thread-Aのxを設定しました
Thread-Bのxを設定しました
Thread-Bのx: 10
Thread-Aのx: 5
上記の処理で、time.sleep()でスレッドの切替をさせました。ここのlocalはグローバル変数ですが、ThreadLocalオブジェクトであるため、それぞれのスレッドからお互い影響することなく、インスタンス変数xを操作できます。localを辞書のように、各スレッド固有のデータを保存するものだと見ることもできます。ThreadLocalの使い方として、それぞれのスレッドに独自のDBコネクション、httpリクエストなどを作ることができます。スレッドからすると、受け取った全てのデータはローカル変数同然で、他のスレッドに構わず操作することが可能です。
2. multiprocessing
Unix系OSではfork()というシステムコールで、プロセスを作成できます。fork()を呼び出すと、現在のプロセスをコピーします。コピーされたプロセスを子プロセスと言い、元のプロセスはその親プロセスになります。fork()の戻り値は、子プロセスと親プロセス両方に返します。そして、子プロセスの戻り値は0で、親プロセスの中では子プロセスのIDが返されます。その理由は、親プロセスは子プロセスのIDを記録しなければならないからです。子プロセスからgetppidで親プロセスのIDを取得できます。
PythonのOSモジュールでは、システムコール系がカプセル化されています。
import os
print('Process ({}) start...'.format(os.getpid()))
# Only works on Unix/Linux/Mac:
pid = os.fork()
if pid == 0:
print('I am child process ({}) and my parent is {}.'.format(os.getpid(), os.getppid()))
else:
print('I ({}) just created a child process ({}).'.format(os.getpid(), pid))
実行結果:
Process (19148) start...
I (19148) just created a child process (19149).
I am child process (19149) and my parent is 19148.
ここでは親プロセスと子プロセスはそれぞれ違う条件分岐に入ります。Windowsはfork()というシステムコールを持ってないため、実行できませんのでご注意ください。
fork()を使うことで、プロセスが新しいタスクを引き受けた時、新しいプロセスを作って処理させることができます。例えば、かの有名なApacheサーバーは親プロセスがポートをモニタリングし、新しいhttpリクエストが来たら、fork()して子プロセスに処理させます。
Pythonのマルチプロセスのプログラムを作成する時は、標準ライブラリのmultiprocessingモジュールを使うのをお勧めします。multiprocessingモジュールは並列処理可能なモジュールです。threadingモジュールはGILのせいで並列処理ができないため、multiprocessingモジュールが実装されたとも言われています。
また、multiprocessingモジュールはクロスプラットフォームで、Windowsでもマルチプロセスのプログラムを作成できます。前述のように、Windowsはfork()を持ってないため、multiprocessingモジュールでプロセスを作る時は、擬似fork()の処理をしています。やり方として、親プロセスの全てのPythonオブジェクトをPickleでシリアライズして、子プロセスに渡すようにしています。なので、Windowsでmultiprocessingモジュールの呼び出しが失敗したら、Pickleのほうで失敗している可能性があります。
子プロセスを作って、外部コマンドを実行させたい時は、標準ライブラリのsubprocessが使えますが、ここではまず、Python処理をマルチプロセスモジュールmultiprocessingの機能ついて紹介します。
2-1. プロセス(Process)
プロセスを使って簡単に子プロセスを作成できます。
from multiprocessing import Process
import os
# 子プロセスが実行する処理
def run_proc(name):
print('Run child process {} ({})...'.format(name, os.getpid()))
print('Parent process {}.'.format(os.getpid()))
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join()
print('Child process end.')
実行結果:
Parent process 19218.
Child process will start.
Run child process test (19219)...
Child process end.
実行関数と引数をProcessに渡して、インスタンスを作って、startで起動します。fork()より、簡単に子プロセスを作れます。ここのjoinを使うことで、スレッドの時と同じく、親プロセスは子プロセスの実行が終わるまで待機します。
2-2. プロセスプール(Process Pool)
子プロセスを作るのに非常に計算コストがかかるため、大量に作りたい時は、Poolでプロセスプールを作ったほうが効率的です。Poolの主なメソッドは以下のようになります。
| メソッド | 説明 |
|---|---|
| apply | 同期処理 |
| apply_async | 非同期処理 |
| terminate | 直ちに終了する |
| join | 親プロセスは子プロセスの処理が終わるまで待機する;プロセスのjoinはcloseかterminateの後でしか実行できない |
| close | 全てのプロセスの処理が終わったら終了する |
from multiprocessing import Pool
import os
import time
import random
def long_time_task(name):
print('Run task {} ({})...'.format(name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task {} runs {} seconds.'.format(name, (end - start)))
print('Parent process {}.'.format(os.getpid()))
p = Pool(4) # 同時に最大4個の子プロセス
for i in range(5):
p.apply_async(long_time_task, args=(i,))
# 非同期処理のため、親プロセスは子プロセスの処理を待たずに、
# 次のprintをする
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
実行結果:
Parent process 19348.
Waiting for all subprocesses done...
Run task 0 (19349)...
Run task 1 (19350)...
Run task 2 (19351)...
Run task 3 (19352)...
Task 1 runs 0.8950300216674805 seconds.
Run task 4 (19350)...
Task 2 runs 1.0132842063903809 seconds.
Task 4 runs 0.3936619758605957 seconds.
Task 3 runs 2.3689510822296143 seconds.
Task 0 runs 2.776203155517578 seconds.
All subprocesses done.
プールサイズは4なので、task 4はtask 0からtask 3のどれかが終了してから実行し始めます。
2-3. プロセス間通信
スレッドと違って、プロセス間のデータはシェアされません。OSはプロセス間通信の方法をたくさん提供しています。multiprocessingはOSの低レベルの機能をカプセル化し、使いやすくしています。
2-3-1. キュー(Queue)
FIFOのデータ構造キューはよく、プロセス間通信に使われます。
from multiprocessing import Process, Queue
import os
import time
import random
# Queueにデータを書き込む
def write(q):
print('Process to write: {}'.format(os.getpid()))
for value in ['A', 'B', 'C']:
print('Put {} to queue...'.format(value))
q.put(value)
time.sleep(random.random())
# Queueからデータを読み取り
def read(q):
print('Process to read: {}'.format(os.getpid()))
while True:
value = q.get(True)
print('Get {} from queue.'.format(value))
# 親プロセスがQueueを作って、子プロセスに渡す
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# pwを起動し、書き込み開始
pw.start()
# prを起動し、読み取り開始
pr.start()
# pwが終了するのを待つ
pw.join()
# prは無限ループなので、強制終了
pr.terminate()
実行結果:
Process to write: 19489
Put A to queue...
Process to read: 19490
Get A from queue.
Put B to queue...
Get B from queue.
Put C to queue...
Get C from queue.
仮に読み取りが遅くても、FIFOのため正確な順番に取り出せます。
2-3-2. パイプ(Pipe)
名前の通りパイプはパイプ状のデータ構造と考えて良いと思います。パイプの片方にデータを入れて(sendメソッド)、もう片方にデータ受け取る(recvメソッド)というふうにデータが伝達されています。2つのプロセスが同時に同じパイプにデータを入れたり受け取ったりすると、データが破損する可能性がありますのでご注意ください。
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
parent_conn, child_conn = Pipe()
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv())
p.join()
実行結果:
[42, None, 'hello']
2-3-3. 共有メモリ(Shared memory)
プロセス間のデータはシェアされないと説明しましたが、実は嘘です...
OSの機能として、プロセス間の共有メモリを作ることができます。PythonではValueとArrayで、数値データと配列デートを共有メモリ上に保持することができます。余談ですが、ValueとArrayはC言語のデータ構造をそのまま利用しています。Pythonの数値(numbersクラスを継承したもの)は基本不変(immutable)であるため、直接書き換えることはできないです。
from multiprocessing import Process, Value, Array
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
num = Value('d', 0.0) # double型数字
arr = Array('i', range(10)) # 配列
p = Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])
実行結果:
3.1415927
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
python 3.8からmultiprocessing.shared_memoryモジュールが追加され、共有メモリを使ってプロセス間のデータ交換ができるようになりました。
ここでまず1つのターミナル(プロセス)を起動します。
import numpy as np
from multiprocessing import shared_memory
a = np.ones((3, 3))
shm = shared_memory.SharedMemory(create=True, size=a.nbytes, name='shm') # shmという共有メモリを作成
b = np.ndarray(a.shape, dtype=a.type, buffer=shm.buf) # 共有メモリでaと同じ形のb行列を作成
b[:] = a[:] # aをbにコピーする
print(b)
実行結果:
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
もう1つのターミナル(プロセス)を起動します。
import numpy as np
from multiprocessing import shared_memory
existing_shm = shared_memory.SharedMemory(name='shm') # shmという共有メモリを取得
c = np.ndarray((3, 3), dtype=np.float64, buffer=existing_shm.buf)
print(c)
# ここでcを変更するとterminal_1のbも変わる
実行結果:
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
2-3-4. マネージャ(Manager)
マネジャーはデータを伝達しているというよりシェアしていると言ったほうが的確かもしれません。Manager()はマネージャーオブジェクトを返してサーバープロセスを作ります。サーバープロセスを通して、他のプロセスはプロキシ方式で、Pythonオブジェクトを操作することが可能になります。マネージャーオブジェクトはPythonのlist, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value, Arrayオブジェクトをサポートしています。
from multiprocessing import Process, Manager
def f(d, l, i):
d[i] = i
d[str(i)] = str(i)
l.append(i)
print(l)
with Manager() as manager:
shared_dict = manager.dict()
shared_list = manager.list()
p_list = []
# 10個のプロセスを作成
for i in range(10):
p = Process(target=f, args=(shared_dict, shared_list, i))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('All subprocesses done.')
print(shared_dict)
print(shared_list)
実行結果:
[0]
[0, 1]
[0, 1, 2]
[0, 1, 2, 3]
[0, 1, 2, 3, 4]
[0, 1, 2, 3, 4, 5]
[0, 1, 2, 3, 4, 5, 6]
[0, 1, 2, 3, 4, 5, 6, 8]
[0, 1, 2, 3, 4, 5, 6, 8, 7]
[0, 1, 2, 3, 4, 5, 6, 8, 7, 9]
All subprocesses done.
{0: 0, '0': '0', 1: 1, '1': '1', 2: 2, '2': '2', 3: 3, '3': '3', 4: 4, '4': '4', 5: 5, '5': '5', 6: 6, '6': '6', 8: 8, '8': '8', 7: 7, '7': '7', 9: 9, '9': '9'}
[0, 1, 2, 3, 4, 5, 6, 8, 7, 9]
マネージャーでプロセス間共有のリストと辞書を作成してみました。ここでは、プロセスの処理は順番に行われてないことが確認できます。
Python 3.8からmultiprocessing.managers.SharedMemoryManagerモジュールが追加され、共有メモリマネージャーが使えるようになりました。
from multiprocessing import Process
from multiprocessing.managers import SharedMemoryManager
def assign(l, start, end, v):
for i in range(start, end):
l[i] = v
if __name__ == '__main__':
# withで共有メモリマネージャーを起動する
# withを使わない場合はsmm.start()とsmm.shutdown()が必要
with SharedMemoryManager() as smm:
sl = smm.ShareableList(range(2000)) # マネージャーで共有リストを作成
# それぞれのプロセスで同時に共有リストを操作する
p1 = Process(target=assign, args=(sl, 0, 1000, 0))
p2 = Process(target=assign, args=(sl, 1000, 2000, 1))
p1.start()
p2.start()
p1.join()
p2.join()
total_result = sum(sl) # 共有リストslはwithを抜けた後に消滅する
print(total_result)
実行結果:
1000
2-3-5. プロセス制御
スレッドと同じように、プロセスもロックによる制御ができます。
from multiprocessing import Process, Lock
def f(i):
lock.acquire()
try:
print('hello world', i)
finally:
lock.release()
lock = Lock()
for num in range(10):
Process(target=f, args=(num,)).start()
実行結果:
hello world 0
hello world 1
hello world 2
hello world 3
hello world 4
hello world 5
hello world 6
hello world 7
hello world 8
hello world 9
ロックがかかったことで数字が順番に出力されています。ただし、マルチプロセスの性能を発揮できなくなります。
2-4. 分散型プロセス処理
multiprocessingモジュールのmanagersサブモジュールはプロセスを複数のマシンに分散できます。通信プロトコルが分からなくても、分散型プロセス処理のプログラムが書けます。
分散型プロセス処理にはタスクをスケジューリングするサーバープロセスと、タスクを実際に処理するワーカープロセスが必要です。まず、サーバープロセスのtask_master.pyを実装します。
ここでは、managersでキューをAPIとしてインターネットに公開します。サーバープロセスはキューを起動して、タスクを入れると、他のマシンからアクセスすることが可能になります。
import random
import queue
from multiprocessing.managers import BaseManager
# タスクを送るキュー
task_queue = queue.Queue()
# 結果を受け取るキュー
result_queue = queue.Queue()
class QueueManager(BaseManager):
pass
# 2つのキューをAPIとして登録する
# Windowsの場合はAPI登録にlambdaが使えないので、素直に関数を定義してください
QueueManager.register('get_task_queue', callable=lambda: task_queue)
QueueManager.register('get_result_queue', callable=lambda: result_queue)
# ポート5000を使い、認証暗号を'abc'にする
# Windowsの場合はアドレスを明記する必要がある(127.0.0.1)
manager = QueueManager(address=('', 5000), authkey=b'abc')
# 起動する
manager.start()
# ネット経由でキューオブジェクトを取得
task = manager.get_task_queue()
result = manager.get_result_queue()
# タスクを入れてみる
for i in range(10):
n = random.randint(0, 10000)
print('Put task {}...'.format(n))
task.put(n)
# resultキューから結果を受け取る
print('Try get results...')
for i in range(10):
# 10秒超えたらtimeoutで終了
r = result.get(timeout=10)
print('Result: {}'.format(r))
# 終了
manager.shutdown()
print('master exit.')
次に、ワーカープロセスのtask_worker.pyを実装します。上で公開したmanager.get_task_queueというAPIでタスクを取得して、処理します。
import time
import queue
from multiprocessing.managers import BaseManager
# 同じQueueManagerを作る
class QueueManager(BaseManager):
pass
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue')
# サーバーに接続する
server_addr = '127.0.0.1'
print('Connect to server {}...'.format(server_addr))
# 同じポートと認証暗号を設定する
m = QueueManager(address=(server_addr, 5000), authkey=b'abc')
# 接続
m.connect()
# それぞれのキューを取得
task = m.get_task_queue()
result = m.get_result_queue()
# taskキューからタスクを受け取って
# 処理結果をresultキューに格納する
for i in range(10):
try:
n = task.get(timeout=1)
# ここでは簡単な二乗計算をタスクとする
print('run task {} * {}...'.format(n, n))
r = '{} * {} = {}'.format(n, n, n*n)
time.sleep(1)
result.put(r)
except queue.Empty:
print('task queue is empty.')
# 終了
print('worker exit.')
ローカルマシンでも実行可能です。
まず、サーバープロセスはまずタスクをtask_queueに入れます。全部入れたら、result_queueの中に結果が入るのを待ちます。
実行結果:
Put task 7710...
Put task 6743...
Put task 8458...
Put task 2439...
Put task 1351...
Put task 9885...
Put task 5532...
Put task 4181...
Put task 6093...
Put task 3815...
Try get results...
続いて、ワーカープロセスはサーバーに接続し、task_queueにあるタスクを取り出して、処理をします。処理結果はresult_queueに送ります。
Connect to server 127.0.0.1...
run task 7710 * 7710...
run task 6743 * 6743...
run task 8458 * 8458...
run task 2439 * 2439...
run task 1351 * 1351...
run task 9885 * 9885...
run task 5532 * 5532...
run task 4181 * 4181...
run task 6093 * 6093...
run task 3815 * 3815...
worker exit.
result_queueの中に結果が入ってきたら、サーバープロセスは順に出力します。
Put task 7710...
Put task 6743...
Put task 8458...
Put task 2439...
Put task 1351...
Put task 9885...
Put task 5532...
Put task 4181...
Put task 6093...
Put task 3815...
Try get results...
Result: 7710 * 7710 = 59444100
Result: 6743 * 6743 = 45468049
Result: 8458 * 8458 = 71537764
Result: 2439 * 2439 = 5948721
Result: 1351 * 1351 = 1825201
Result: 9885 * 9885 = 97713225
Result: 5532 * 5532 = 30603024
Result: 4181 * 4181 = 17480761
Result: 6093 * 6093 = 37124649
Result: 3815 * 3815 = 14554225
master exit.
ワーカープロセスではキューを作成してないので、全てのキューはサーバープロセスの中に存在します。
 (出典:[廖雪峰的官方网站](https://www.liaoxuefeng.com/wiki/1016959663602400/1017631559645600))
(出典:[廖雪峰的官方网站](https://www.liaoxuefeng.com/wiki/1016959663602400/1017631559645600))
このように分散型プロセスをPythonで実現できます。複数ワーカーを使って処理させることで、強力な計算パワーが手に入ります。
3. subprocess
Unix系OSではfork()で、子プロセスとして現在のプロセスのコピーを作成するのを説明しました。つまり、Pythonでos.forkを呼び出すと、Pythonプログラムの子プロセスが作成されます。しかし、Pythonプログラムではなく、外部コマンドが実行できる子プロセスが必要な時もあります。
Unix系OSにはもう1つexec()というシステムコールが存在します。Pythonの中ではos.execveとして実装されています。exec()は現在プロセスを他のプログラムで置き換える関数です。つまり、os.forkでPythonプログラムの子プロセスを作り、os.execveで他のプログラム(シェルで実行できるls、pingのようなプログラム)で置き換えることができます。
標準ライブラリsubprocessは外部プログラムを実行する子プロセスを作成するためのモジュールです。そして、subprocessで外部プログラムを実行する時は、Pythonプロセスと子プロセスの間にプロセス間通信用のパイプ(Pipe)を構築し、パラメータを渡したり、戻り値やエラーを受け取ったりすることが可能になります。
3-1. subprocess.run
Python 3.5以降は、subprocess.runでコマンドを実行することが公式的に推奨されます。ここでは、古いAPIのsubprocess.callなどの説明を省略します。
subprocess.run(args, *, stdin=None, input=None,
stdout=None, stderr=None, shell=False, timeout=None, check=False, universal_newlines=False)
subprocess.runはCompletedProcessクラスのインスタンスを返します。CompletedProcessクラスの属性は以下になります。
| 属性 | 説明 |
|---|---|
| args | 子プロセスに渡したパラメータ;文字列またはリスト |
| returncode | 実行後のステータスコードを格納 |
| stdout | 実行後の標準出力 |
| stderr | 実行後の標準エラー |
| check_returncode() | ステータスコードが0ではないとき(実行失敗)、CalledProcessErrorを起こす |
subprocess.runの使用例を少し紹介します。
subprocess.PIPEで標準出力をキャッチできます(キャッチしないと出力が捨てられる)。
import subprocess
obj = subprocess.run(["ls", "-l"], stdout=subprocess.PIPE)
print('stdout:\n{}'.format(obj.stdout.decode()))
実行結果:
stdout:
total 128
-rw-r--r--@ 1 kaito staff 692 Feb 16 19:35 1-1.py
-rw-r--r--@ 1 kaito staff 509 Feb 17 23:39 1-2.py
-rw-r--r--@ 1 kaito staff 364 Feb 19 16:48 2-10.py
-rw-r--r--@ 1 kaito staff 645 Feb 19 19:12 2-17.py
-rw-r--r--@ 1 kaito staff 213 Feb 19 19:14 2-18.py
-rw-r--r--@ 1 kaito staff 209 Feb 19 19:18 2-19.py
-rw-r--r--@ 1 kaito staff 318 Feb 19 23:53 2-20.py
-rw-r--r--@ 1 kaito staff 194 Feb 19 23:57 2-21.py
-rw-r--r--@ 1 kaito staff 230 Feb 20 15:46 2-23.py
-rw-r--r--@ 1 kaito staff 131 Feb 18 19:39 2-4.py
-rw-r--r--@ 1 kaito staff 543 Feb 18 19:50 2-8.py
-rw-r--r--@ 1 kaito staff 240 Feb 18 22:29 2-9.py
-rw-r--r-- 1 kaito staff 1339 Feb 27 00:25 task_master.py
-rw-r--r-- 1 kaito staff 1086 Feb 27 00:31 task_worker.py
-rw-r--r-- 1 kaito staff 446 Feb 27 20:26 test.py
-rw-r--r-- 1 kaito staff 199 Feb 27 20:31 test2.py
checkをTrueにすると、ステータスコードが0以外の時にエラーを起こします。
subprocess.run("exit 1", shell=True, check=True)
実行結果:
Traceback (most recent call last):
File "test2.py", line 4, in <module>
subprocess.run("exit 1", shell=True, check=True)
File "/Users/kaito/opt/miniconda3/lib/python3.7/subprocess.py", line 487, in run
output=stdout, stderr=stderr)
subprocess.CalledProcessError: Command 'exit 1' returned non-zero exit status 1.
CompletedProcessクラスの__repr__はこんな感じです。
print(subprocess.run(["ls", "-l", "/dev/null"], stdout=subprocess.PIPE))
実行結果:
CompletedProcess(args=['ls', '-l', '/dev/null'], returncode=0, stdout=b'crw-rw-rw- 1 root wheel 3, 2 Feb 27 20:37 /dev/null\n')
3-2. subprocess.Popen
高度な操作はsubprocess.Popenクラスを利用することができます。
class subprocess.Popen(args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None,
preexec_fn=None, close_fds=True, shell=False, cwd=None, env=None, universal_newlines=False,
startup_info=None, creationflags=0, restore_signals=True, start_new_session=False, pass_fds=())
subprocess.Popenクラスのメソッドは以下のようになります。
| メソッド | 説明 |
|---|---|
| poll | 子プロセスの実行が終了したらステータスコードを返す;終了してないならNoneを返す |
| wait | 子プロセスの実行が終了するのを待つ;timeoutになったらTimeoutExpiredエラーを起こす |
| communicate | 子プロセスと通信を行う |
| send_signal | 子プロセスにシグナルを送る;例えばsignal.signal(signal.SIGINT)はUNIX系OSのコマンドラインで、Ctrl+Cを押した時のシグナル |
| terminate | 子プロセスを終了する |
| kill | 子プロセスを強制終了 |
subprocess.Popenの使用例も少し紹介します。
Pythonコードを外部プログラムとして実行することができます。
import subprocess
# 標準入力、標準出力、標準エラーにパイプを繋ぐ
p = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# 標準入力にデータを書き込む
p.stdin.write(b'print("stdin")\n')
# communicateの入力としてデータを渡す
out, err = p.communicate(input=b'print("communicate")\n')
print(out.decode())
実行結果:
stdin
communicate
|を使ったパイプライン処理は2つの子プロセスの標準出力と標準入力をパイプで繋ぐことで構築可能です。
# 2つの子プロセスをパイプで繋ぐ
p1 = subprocess.Popen(['df', '-h'], stdout=subprocess.PIPE)
p2 = subprocess.Popen(['grep', 'Data'], stdin=p1.stdout, stdout=subprocess.PIPE)
out, err = p2.communicate() # df -h | grep Data
print(out.decode())
実行結果:
/dev/disk1s1 466Gi 438Gi 8.0Gi 99% 1156881 4881295959 0% /System/Volumes/Data
map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /System/Volumes/Data/home
4. concurrent.futures
Pythonのマルチスレッドとマルチプロセスについて一通り紹介しました。やや複雑で理解しにくいイメージを持っているかもしれませんが、それは事実です(笑)。Goのような最初からシンプルな並列・並行処理を設計哲学とする言語はプログラミング言語の進化の方向を示しているかもしれません。
ただし、Pythonの進化もまだ止まってません。concurrentというthreadingとmultiprocessingを更にカプセル化して、使いやすくした高レベルモジュールはPython 3.2から追加されました。
今のconcurrentにはfuturesというモジュールしかないです。futuresはFutureパターンのPython実装です。ここでは、現時点使える機能について紹介したいと思います。
4-1. ExecutorとFuture
concurrent.futuresはThreadPoolExecutorとProcessPoolExecutorを提供していて,これらはExecutorクラスを継承したものになります。
ThreadPoolExecutorとProcessPoolExecutorはmax_workersというスレッド数またはプロセス数を指定する引数を受け取ります。submitメソッドで1つのタスクを実行して、Futureクラスのインスタンスを返します。
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import requests
def load_url(url):
return requests.get(url)
if __name__ == '__main__':
url = 'https://www.python.org/'
executor = ProcessPoolExecutor(max_workers=4) # ThreadPoolExecutor(max_workers=4)
future = executor.submit(load_url, url)
print(future)
while 1:
if future.done():
print('status code: {}'.format(future.result().status_code))
break
実行結果:
<Future at 0x10ae058d0 state=running>
status code: 200
簡単なhttpリクエストです。ここで注意すべきはProcessPoolExecutorを使う時は__main__モジュールが必要であるため、REPL環境で実行しないことです。
The __main__ module must be importable by worker subprocesses. This means that ProcessPoolExecutor will not work in the interactive interpreter.
4-2. map、as_completedとwait
submitメソッドは1個のタスクしか実行できないので、複数のタスクを実行したい時はmap、as_completedとwaitを使います。
mapメソッドは実行関数とシーケンスを引数として受け取り、実行結果のジェネレーターを返します。
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import requests
URLS = ['https://google.com', 'https://www.python.org/', 'https://api.github.com/']
def load_url(url):
return requests.get(url)
if __name__ == '__main__':
# with ThreadPoolExecutor(max_workers=4) as executor:
with ProcessPoolExecutor(max_workers=4) as executor:
for url, data in zip(URLS, executor.map(load_url, URLS)):
print('{} - status_code {}'.format(url, data.status_code))
実行結果:
https://google.com - status_code 200
https://www.python.org/ - status_code 200
https://api.github.com/ - status_code 200
as_completedメソッドはFutureオブジェクトのジェネレーターを返します。そして、タスクが完成されないとブロッキングします。
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor, as_completed
import requests
URLS = ['https://google.com', 'https://www.python.org/', 'https://api.github.com/']
def load_url(url):
return url, requests.get(url).status_code
if __name__ == '__main__':
with ProcessPoolExecutor(max_workers=4) as executor:
tasks = [executor.submit(load_url, url) for url in URLS]
for future in as_completed(tasks):
print(*future.result())
実行結果:
https://google.com 200
https://www.python.org/ 200
https://api.github.com/ 200
waitメソッドはメインスレッド、メインプロセスをブロッキングさせます。return_whenという引数で、3つの条件を設定できます。
| 条件 | 説明 |
|---|---|
| ALL_COMPLETED | 全タスクが完成したらブロッキングを解放する |
| FIRST_COMPLETED | 任意のタスクが完成したらブロッキングを解放する |
| FIRST_EXCEPTION | 任意のタスクがエラーを起こしたらブロッキングを解放する |
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor, wait, ALL_COMPLETED
import requests
URLS = ['https://google.com', 'https://www.python.org/', 'https://api.github.com/']
def load_url(url):
requests.get(url)
print(url)
if __name__ == '__main__':
with ProcessPoolExecutor(max_workers=4) as executor:
tasks = [executor.submit(load_url, url) for url in URLS]
wait(tasks, return_when=ALL_COMPLETED)
print('all completed.') # 3つのprintの後にメインプロセスが解放されprintする
実行結果:
https://www.python.org/
https://api.github.com/
https://google.com
all completed.
参考
並行実行
threading --- スレッドベースの並列処理
multiprocessing --- プロセスベースの並列処理
subprocess --- サブプロセス管理
concurrent.futures -- 並列タスク実行