Kerasを用いて回帰分析を行う
ライブラリ&データの読み込み
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
df = pd.read_csv("https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
df.head()
dfから説明変数と目的変数を分ける
df_features = df.copy()
df_labels = df_features.pop('Age')
df_features = np.array(df_features)
訓練データとテストデータに分割する&標準化
X_train, X_test, y_train, y_test = train_test_split(df_features, df_labels, test_size=0.2)
y_train = y_train.reset_index(drop=True)
sc = StandardScaler()
sc.fit(X_train)
sc.fit(X_test)
簡単なkerasモデルを作成する
def build_model():
model = keras.Sequential([layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)])
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model
k-foldを行い、MAEを算出
k = 4
num_val_samples = len(X_train) // k
num_epochs = 100
all_scores = []
best_mae_per_fold = []
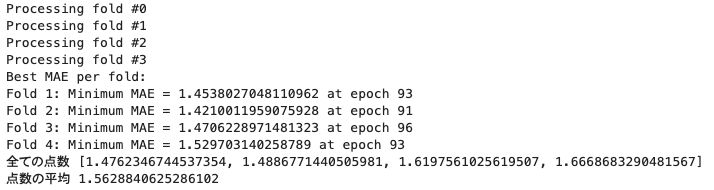
for i in range(k):
print(f'Processing fold #{i}')
val_data = X_train[i*num_val_samples: (i+1)*num_val_samples]
val_targets = y_train[i*num_val_samples: (i+1)*num_val_samples]
partial_train_data = np.concatenate([X_train[:i*num_val_samples], X_train[(i+1)*num_val_samples:]], axis=0)
partial_train_targets = np.concatenate([y_train[:i*num_val_samples], y_train[(i+1)*num_val_samples:]], axis=0)
model = build_model()
history = model.fit(partial_train_data, partial_train_targets, validation_data=(val_data, val_targets), epochs=num_epochs, batch_size=16, verbose=0)
mae_history = history.history['val_mae']
min_mae = min(mae_history)
min_mae_epoch = mae_history.index(min_mae) + 1
best_mae_per_fold.append((min_mae, min_mae_epoch))
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
print("Best MAE per fold:")
for fold, (mae, epoch) in enumerate(best_mae_per_fold, 1):
print(f"Fold {fold}: Minimum MAE = {mae} at epoch {epoch}")
print('全ての点数', all_scores)
print('点数の平均', np.mean(all_scores))
k-foldを行いグラフを算出
num_epochs = 500
all_mae_histories = []
for i in range(k):
print(f'Processing fold #{i}')
val_data = X_train[i*num_val_samples: (i+1)*num_val_samples]
val_targets = y_train[i*num_val_samples: (i+1)*num_val_samples]
partial_train_data = np.concatenate([X_train[:i*num_val_samples], X_train[(i+1)*num_val_samples:]], axis=0)
partial_train_targets = np.concatenate([y_train[:i*num_val_samples], y_train[(i+1)*num_val_samples:]], axis=0)
model = build_model()
history = model.fit(partial_train_data, partial_train_targets, validation_data=(val_data, val_targets), epochs=num_epochs, batch_size=16, verbose=0)
mae_history = history.history['val_mae']
all_mae_histories.append(mae_history)
average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
plt.plot(range(1, len(average_mae_history)+1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()

グラフをEpochs10の後から見てみる
truncated_mae_history = average_mae_history[10:]
plt.plot(range(1, len(truncated_mae_history) + 1), truncated_mae_history, linewidth=1)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
