概要
機械学習の画像分類で、学習用データが少ない場合、"fine-tuning"によりどの程度の精度(accuracy)を出せるのか評価してみました。ハイパーパラメーターのチューニングによる精度の変化の傾向についても評価してみました。
ベースとする学習済みモデルはVGG16, ResNet50, XceptionなどKerasに含まれる代表的なものを用いました。データセットは Intel Image Classification(風景画像, クラス数6)を用いました。
評価の結果、学習用データ(訓練データおよび検証データ)を1クラスあたり100件(合計600件)に制限しても、ResNet50やXceptionにより、約88%のaccuracyを得られることが確認できました。ハイパーパラメーターのチューニングについては、評価対象のデータセットに関しては、「学習率1e-4、凍結レイヤなし」(または入力層に近い一部のレイヤのみ凍結)とした時に最高値に近い精度が出やすいようです。
さらに、今回の評価での経験にもとづいて、ハイパーパラメーターのチューニングなどにあまり手間をかけないfine-tuning(=簡易fine-tuning)の方法についても検討してみました。
参考として、末尾に評価に用いたコードと簡単な説明をつけます(2021/3/21追記:Google Colab上で動くコードをGitHubでも公開しました)。以下のような予測結果を出力します。(各画像の上のテキストは、上から予測ラベル、予測確率、正解ラベル。画像は Intel Image Classification より引用。)

「fine-tuning とは?」など基本概念の説明については、以下のようなよい記事が既にありますので、そちらをご参照ください。本記事では説明を省きます。
- [1] Kaggle Facial Keypoints DetectionをKerasで実装する/転移学習
- [2] Building powerful image classification models using very little data
動機:なぜ、この評価を行ったのか?
機械学習の利用を検討するための初期の評価段階では、様々なアイディアを試してみるため、あるいは、使える予算が限られているため、あまり時間やコストをかけずに評価結果を出したいということが多いのではないでしょうか。そのような時に、学習データの数を絞ったり、ハイパーパラメーターをチューニングするための実験回数を減らしても、それなりに高い精度を出すことができれば、機械学習の応用の可能性が広がると思われます。fine-tuningを用いる時、そのような簡易的な方法(=簡易fine-tuning)がどの程度有効か評価してみたいというのが、今回の評価の動機です。
評価条件
評価に用いたデータセット、前処理、学習モデル、実行環境の概要は以下のとおりです。
-
データセット:
- [3] Intel Image Classificationを使用した。自然や都市の(クールな!)風景画像のデータセット。
- 学習用データ数(訓練データ数および検証データ数の合計):約14,000件(1クラス2,000-2,500件)
- テストデータ数:3000件(1クラス500件)
- クラス数:6 ['buildings', 'forest', 'glacier', 'mountain', 'sea', 'street']
- 画像サイズ:150x150
-
使用した学習用データ数: 以下の2つのケースを評価した。
- [ケースA] : 全データを使用した場合。(合計データ数=約14,000件)
- [ケースB] : 各クラス100件に制限した場合。(合計データ数=600件)
-
前処理: (詳細は後述のコードを参照)
- リサイズ: ベースとする学習済みモデルが画像サイズを制限している以下の場合のみ実施した。
- MobileNetV2 : 150x150 → 128x128
- リサイズ: ベースとする学習済みモデルが画像サイズを制限している以下の場合のみ実施した。
-
学習モデル: (詳細は後述のコードを参照)
- ベースとする学習済みモデル(base model):以下のモデルを評価した。
- VGG16
- ResNet50
- Xception
- InceptionResNetV2
- MobileNetV2
- 最適化アルゴリズム: Adamを使用。EarlyStopping あり。
- 学習率(lr): 次の値を評価した。1e-2, 1e-3, 1e-4, 1e-5, 1e-6
- 凍結対象レイヤの範囲(frozen): frozenは整数のハイパーパラメーターで、ベースとする学習済みモデル上の第0番目のレイヤ(入力レイヤ)から第(frozen - 1)番目のレイヤまでのパラメーターを固定(凍結)しておくという評価条件を表す。ただし、BatchNormalizationレイヤは凍結の対象外とする。(Kerasの実装ではBatchNormalizationを凍結すると精度が大きく低下することが報告されているため。Referenceの[6][7]を参照。) 選択可能なfrozenの値は多数あり全てを評価できないので、ベースとする学習済みモデル(base model)ごとに評価対象値を5件以上選定し、評価対象値のみを評価した。
- ベースとする学習済みモデル(base model):以下のモデルを評価した。
-
実行環境:
- CPU: Intel Core i7-6700K (4.0GHz, 4core, 8thread)
- GPU: GeForce GTX1070 (Mem: 8GB)
- Memory: 16GB
- OS:Windows10 64bit
- Python:3.7.4
- TensolFlow: 1.13.1
- Keras :2.2.4
評価方法
評価条件のケースA/B、base model、lr、frozenの各選択肢の組み合わせを1テストケースとし、1テストケースごとにモデル構築/学習/評価を行う実験を10回実施しました。テストケースごとに以下の評価項目を算出しました。
- 評価項目
- 平均Test Acc : テストデータに対するaccuracyの平均
- STD : テストデータに対するaccuracyの標本標準偏差(標本の不偏分散の平方根)
- 平均epoc : EarlyStoppingにより終了した時点のepoc数の平均
- 平均time : 学習時間の平均
考えられるテストケースは多数あるため、全てのテストケースを評価することはしていません。評価対象としたテストケースは、後述の「ハイパーパラメーターと平均Test Accの関係」のグラフ内で示します。
評価結果
ケースA/Bごとに、各base modelの平均Test Accの最高値を出したテストケースを以下に示します。
ケースA: 使用した学習用データ=全データ(約14000件)
| base model | lr | frozen | 平均Test Acc | STD | 平均epoc | 平均time |
|---|---|---|---|---|---|---|
| ResNet50 | 1e-4 | 7 | 93.61% | 0.37% | 15.6 | 22m 38s |
| Xception | 1e-4 | 16 | 93.37% | 0.39% | 12.1 | 19m 29s |
| MobileNetV2 | 1e-4 | 1 | 92.68% | 0.29% | 18.1 | 12m 20s |
| InceptionResNetV2 | 1e-4 | 40 | 92.55% | 0.50% | 13.1 | 36m 1s |
| VGG16 | 1e-5 | 4 | 92.35% | 0.43% | 18.5 | 20m 33s |
ケースB: 使用した学習用データ=各クラス100件(合計600件)
| base model | lr | frozen | 平均Test Acc | STD | 平均epoc | 平均time |
|---|---|---|---|---|---|---|
| Xception | 1e-4 | 26 | 88.47% | 0.67% | 16.8 | 1m 27s |
| ResNet50 | 1e-3 | 143 | 88.43% | 0.86% | 35.4 | 2m 21s |
| MobileNetV2 | 1e-4 | 37 | 87.09% | 0.76% | 21.7 | 0m 43s |
| InceptionResNetV2 | 1e-3 | 367 | 86.47% | 0.85% | 29.0 | 3m 29s |
| VGG16 | 1e-4 | 1 | 86.45% | 0.60% | 20.3 | 1m 25s |
- ケースAでの平均Test Accの最高値は、ResNet50の場合の93.61%
- ケースBでの平均Test Accの最高値は、Xceptionの場合の88.47%
- ケースA/Bいずれの場合も、ResNet50とXceptionは、残りの3つのモデルよりも、平均Test Accが有意に高かった。ResNet50とXceptionの比較では、有意差を検出できなかった。(Welchのt検定を用いた有意水準5%の片側検定により評価した。ケースAでResNet50とXceptionの2つの有意差を検出するには、少なくとも両者のテストケースについて15回以上の実験が必要になる見込み。)
ハイパーパラメーターと平均Test Accの関係
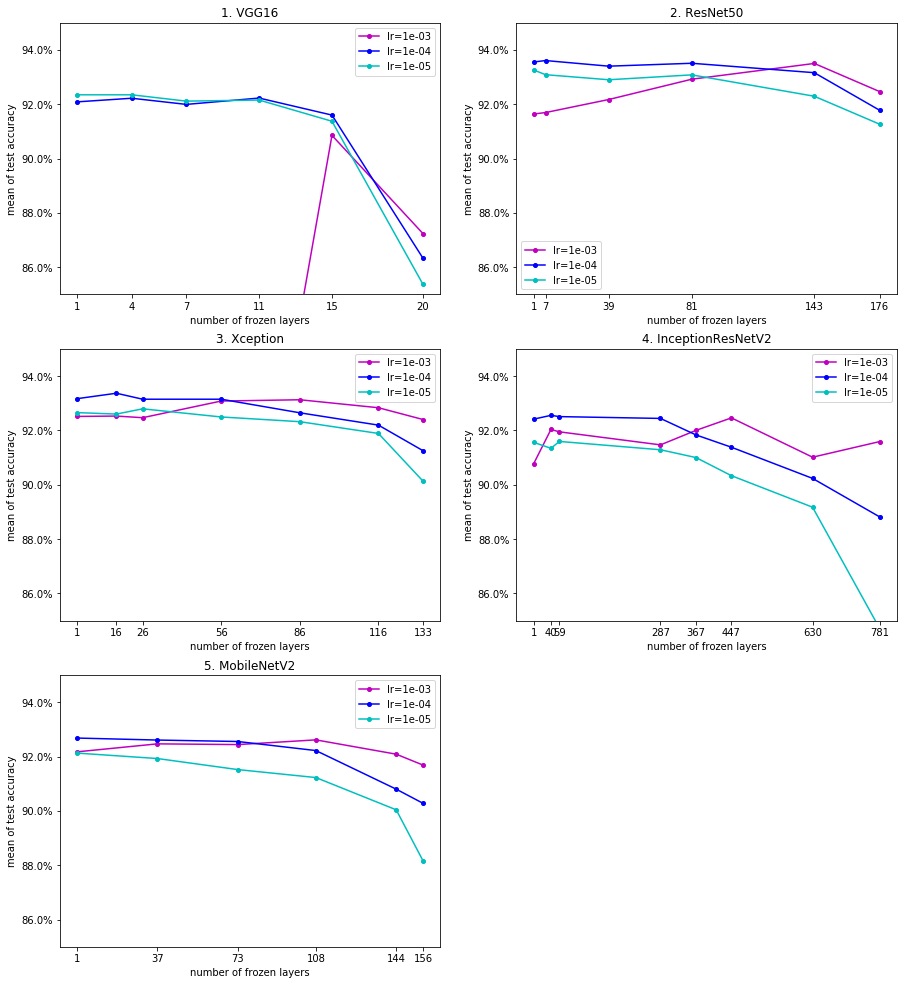
学習率(lr)および凍結対象レイヤの範囲(frozen)と、平均Test Accの関係を表したグラフを以下に示します。各図上のそれぞれの折れ線グラフは学習率(lr)の評価対象値(1e-2,1e-3,1e-4,1e-5,1e-6)に対応しています。折れ線グラフ上のそれぞれのマーク(●)は一つのテストケースに対応しています。なお、平均Test Accが低かったテストケースは省略しています(グラフの枠外に出ています)。
ケースA:
ケースB:
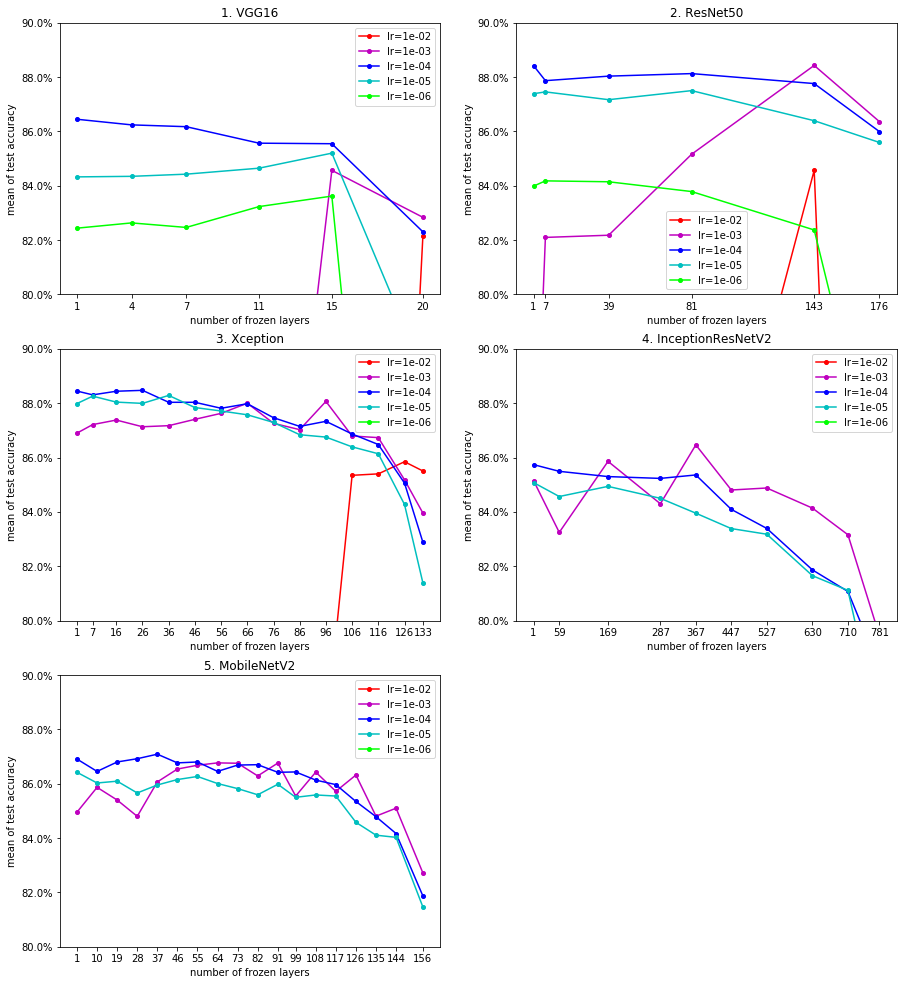
以上の評価結果より、以下を確認することができました:
- 学習率(lr)について(ケースA/B、base model、frozenが同一のテストケースを比較した場合)
- 凍結レイヤの割合が高い場合(frozenの値が相対的に大きい場合、つまり、グラフの右側)を除き、全般的に、lr=1e-4の場合のテストケースが最も高い精度またはそれに近い値を出しているケースが多い。
- 凍結レイヤの割合が高い場合を除き、全般的に、lr=1e-5の場合のテストケースが上位2位以内に入っているケースが多い。
- 凍結レイヤの割合が高い場合、lr=1e-2やlr=1e-3の場合のテストケースが最も高い精度となるケースもある。
- 凍結対象レイヤの範囲(frozen)について(ケースA/B、base model、lrが同一のテストケースを比較した場合)
- lr=1e-4およびlr=1e-5の場合、frozen=1の場合(レイヤを全く凍結しない場合)のテストケースが最も高い精度かそれに近い値を出しているケースが多い。また、frozenの値が大きくなるほど、精度は低下する傾向にある。
- lr=1e-2およびlr=1e-3の場合、frozenの値による精度の変動が大きい。
今回の評価対象のデータセットでは、「学習率1e-4、レイヤの凍結なし」という条件を中心にハイパーパラメーターを探索すると、安定的に高い平均Test Accを得られる可能性が高いようです。
簡易fine-tuningの検討
今回の評価の経験より、簡易fine-tuning(学習データの数を限定し、ハイパーパラメーターをチューニングするための実験回数を限定した簡易的なfine-tuning)の進め方として、以下が考えられると思います。
-
精度の最高値、最適なbase model、最適なハイパーパラメーターの特定は目的としない: これらを特定するには相当の回数の実験が必要。例えば、ケースBのResNet50とXceptionで精度の最高値を出したテストケースの比較では、平均Test Accの差は0.04%しかないが、標本標準偏差STDは0.6~0.9%もあり、100回程度の実験では有意差を検出できない可能性が高い。そのため、これらの特定を簡易fine-tuningの目的とするのは現実的ではない。少数の有望な学習モデルとハイパーパラメーターの組み合わせを評価対象として選択し、それらをおおまかに評価することを目的とするのが現実的と思われる。
-
評価対象とする学習モデルとハイパーパラメーターの組み合わせは、既知の評価結果を参考に、精度の平均が高く、分散が小さくなりそうなものを選ぶ: 学習モデルとハイパーパラメーターの組み合わせの選択では、既知の評価結果(できればターゲットのデータセットに類似するデータセットの評価結果)を参考に、精度の平均が高くなりそうなものを選ぶことが定石と思われる。実際、今回の評価でも既知の評価結果のハイパーパラメーターを参考にすることで、早期に最高値に近い精度に到達できた。簡易fine-tuningでは、実験回数が限られていて試行錯誤を行えないので、既知の評価結果を参考にする必要性はなおさら高い。さらに、予想される精度の平均に大差がなければ、精度の分散が小さくなりそうなものを優先した方がよいと思われる。実験回数が限られているため、分散が大きければ誤った評価をするリスクが高まるので。
-
同じ条件の実験を複数回行い、精度の平均と分散を評価する: 1回の実験で高い精度が出ても、同じ学習モデルとハイパーパラメーターの組み合わせでその精度を容易に再現できるとは限らない。100回に1回しか出ないような高い精度が偶然最初に出ただけという可能性もある。実際、今回の評価では、平均Test Accが62%で標本標準偏差(SED)が31%というケースもあった。平均と分散の情報がなければ、何らかの意思決定に役立つ情報にはならないと思われる。一方、簡易fine-tuningでは実験回数が制限されているので、全ての学習モデルとハイパーパラメーターの組み合わせに対して、精度の平均と分散を評価することは難しい。そこで、高い精度が出た学習モデルとハイパーパラメーターの組み合わせに対してのみ平均と分散を評価するというような妥協策をとることも必要と思われる。
以上の1.~3.が妥当だと仮定し、未知のデータセットに対して簡易fine-tuningを実施する場合の評価計画を、今回の評価結果にもとづいて考えてみました。実験回数を10回に制限する場合、以下のような評価計画が考えられると思います。
- 実験1回目: base model=ResNet50, lr=1e-04, frozen=1
- 実験2回目: base model=ResNet50, lr=1e-04, frozen=81
- 実験3回目: base model=ResNet50, lr=1e-03, frozen=143
- 実験4回目: base model=Xception, lr=1e-04, frozen=1
- 実験5回目: base model=Xception, lr=1e-04, frozen=26
- 実験6回目: base model=Xception, lr=1e-05, frozen=96
- 実験7~10回目: 実験1~6回目で精度が最も高かった学習モデルとハイパーパラメーターの組み合わせに対して、4回の追加評価を行い、合計5回の実験結果から精度の平均と分散を評価する
今回評価したデータセットに類似する傾向を持つデータセットであれば、この評価計画で最高値に近い平均精度が出ると思われます(後出しジャンケンなので当たり前ですが)。今回は1種類のデータセットに対する評価しかしていませんので、世の中の「一般的な」画像のデータセットに対して、上記の評価計画がどの程度有効なのかは分かりません。機会があれば評価してみたいと思います。
ハイパーパラメータ探索手法と簡易fine-tuningの関係
上で示した簡易fine-tuningの方法と、グリッドサーチ、ランダムサーチ、ベイズサーチなどのハイパーパラメーター探索手法(Referenceの[8][9]を参照)を比較し、メリット・デメリットを検討してみます。
上で示した簡易fine-tuningの方法では、評価対象とするハイパーパラメーターの組み合わせの選択を、既知の評価結果に全面的に頼ってしまっています。つまり、過去の経験的な知見にもとづいて、ハイパーパラメーターの組み合わの探索を発見的に数回行っているだけと言えます。一方、ハイパーパラメーター探索手法でハイパーパラメーターの組み合わせを選択すれば、経験的な知見への依存を減らし、簡易fine-tuningより高い精度を出せるハイパーパラメーターの組み合わせに到達できる可能性がある というメリットがあると思います。
しかし、ハイパーパラメーター探索手法を用いると、評価に必要な実験回数が簡易fine-tuningの場合よりも増える というデメリットがあるかもしれません。なぜならば、ハイパーパラメーター探索手法を用いる場合であっても、ハイパーパラメーターの探索範囲の決定は経験的な知見に頼らざるをえないと思われます。つまり、ハイパーパラメーター探索手法は、経験的な知見により有望と思われるハイパーパラメーターの組み合わせの領域を、できるだけ効率的に探索する手法と捉えることができると思われます。一方、上で示した簡易fine-tuningの方法は、経験的な知見により有望と思われるハイパーパラメーターの組み合わせの領域から、エイヤーと数個の点を選んで評価を済ませてしまうというものです。そのため、ハイパーパラメーター探索手法の方が実験回数が多くなりやすいと思われます。
以上より、両者に一長一短があるので、最初は簡易fine-tuningで有望と思われるハイパーパラメーターの組み合わせの領域を大まかに絞り込み、さらに必要があればハイパーパラメーター探索手法を用いて望ましいハイパーパラメーターの組み合わせを絞り込んでいく、というように組み合わせて使うのがよい方法かもしれません。
まとめ
- Kerasが提供する学習済みモデルを利用することで、比較的容易にfine-tuningを実現できることを確認できました。学習済みモデルのAPIが統一されているため、学習済みモデルの変更や比較を容易に行えることを確認できました。
- データ数が1クラスあたり100件の小さなデータセットに対しても、fine-tuningを適用することで、高い予測精度を達成できることを確認できました。
- 簡易fine-tuningの方法を検討し、その評価計画の例を示しました。
おわりに(感想)
fine-tuningと言うと、以前、私は複雑な学習済みモデルに微調整を慎重に加えていき最高の予測精度を追求する世界を想像していました。しかし、実際に使ってみると、Keras上での簡易的なチューニングだけでも意外とよい結果が出てしまいました。簡易fine-tuningによる評価だけでも役立つことが多いのかもしれません。簡易fine-tuningでもよいので、fine-tuningをどんどん使っていった方がよいだろうと思います。
(参考)コード
評価に用いたコードと簡単な説明を示します。合わせて、fine-tuning 実現上のポイント(今回得られた経験)を紹介していきます。
本コードは以下を参考にさせていただきました:
[4] Keras学習済みモデルをFine-tuningさせて精度比較
前処理
Intel Image Classification のデータセットをdownloadして解凍すると seg_test.zip と seg_train.zip が展開されます。これらのファイルを、 ./datasets/intel-image-classification/ に配置してください(あるいは、コードを適宜修正してください)。zipファイル内の画像データのパス名は以下の形式になっています。
- seg_train.zip内: seg_train/(label名フォルダ)/....jpg
- seg_test.zip内 : seg_test/(label名フォルダ)/....jpg
前処理では、これらのzipファイル内の画像データを読み込み、リサイズ、正規化し、訓練データ/検証データ/テストデータに分割しています。
import zipfile, io, re
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from sklearn.model_selection import train_test_split
def preprocessing(image_size, train_data_volume=0, test_data_volume=0):
'''データセットを取得し前処理を行う
parameters:
image_size - 画像サイズ。
train_data_volume - 1ラベルの訓練データ数の上限値。0にすると上限なし。
test_data_volume - 1ラベルのテストデータ数の上限値。0にすると上限なし。
returns:
X_train, y_train, X_valid, y_valid, X_test, y_test, labels, num_classes
'''
train_datasets_path = './datasets/intel-image-classification/seg_train.zip'
test_datasets_path = './datasets/intel-image-classification/seg_test.zip'
# 訓練データをzipファイルから読み込む
with zipfile.ZipFile(train_datasets_path) as z:
# ラベルを抽出する
labels = []
for data_path in z.namelist(): # データファイルのリスト
match = re.search('^seg_train/(.*)/$', data_path)
if match: labels.append(match.group(1))
labels.sort()
num_classes = len(labels)
print('labels:', labels)
# 画像データを読み込み加工する。ラベルを対応づける。
X_train, y_train = get_imgs_with_labels(
z, 'seg_train/', labels, image_size, train_data_volume)
# テストデータをzipファイルから読み込む。
with zipfile.ZipFile(test_datasets_path) as z:
# 画像データを読み込み加工する。ラベルを対応づける。
X_test, y_test = get_imgs_with_labels(
z, 'seg_test/', labels, image_size, test_data_volume)
# 正規化
X_train = X_train.astype('float32') / 255
X_test = X_test .astype('float32') / 255
# ラベルをone-hot-vector化する。
y_train = np.identity(num_classes, dtype=int)[y_train]
y_test = np.identity(num_classes, dtype=int)[y_test ]
# trainデータをtrainデータとvalidationデータに分割する。
X_train, X_valid, y_train, y_valid = train_test_split(
X_train, y_train, random_state = 0,
stratify = y_train, test_size = 0.2 )
# データの確認
print(X_train.shape, y_train.shape)
print(X_valid.shape, y_valid.shape)
print(X_test .shape, y_test .shape)
i = 0
plt.title(labels[y_train[i].argmax()])
plt.imshow(X_train[i])
plt.show()
return X_train, y_train, X_valid, y_valid, X_test, y_test, labels, num_classes
def get_imgs_with_labels(z, src_dir, labels, image_size, data_volume=0):
''' 画像データを読み込み加工する。ラベルを対応づける。
parameters:
z - 読み込み元のZipFileオブジェクト
src_dir - 画像データの抽出元ディレクトリ
labels - ラベルのリスト
image_size - リサイズ後の画像サイズ
data_volume - 各ラベルに対応するデータ数の上限値。0にすると上限なし。
returns:
X, y
'''
# 画像データのパスとラベルのリストを作る
data_paths = z.namelist() # データファイルのリスト
img_paths = []
y = []
for i, label in enumerate(labels):
src_path_pattern = '^' + src_dir + label + '/.*jpg$'
c = 0
for data_path in data_paths:
if re.search(src_path_pattern, data_path):
img_paths.append(data_path)
y.append(i)
c += 1
if c == data_volume: break
# 画像データを読み込み、リサイズし、配列に変換する。
X = []
for img_path in img_paths:
image = Image.open(io.BytesIO(z.read(img_path))) # 読み込み
image = image.convert('RGB') # RGB変換
image = image.resize((image_size, image_size)) # リサイズ
data = np.asarray(image) # 配列に変換
X.append(data)
X = np.array(X)
y = np.array(y)
return X, y
image_size = 150
train_data_volume = 0
test_data_volume = 0
X_train, y_train, X_valid, y_valid, X_test, y_test, labels, num_classes \
= preprocessing(image_size, train_data_volume, test_data_volume)
学習モデルの構築
# 機械学習関連のパッケージ
from keras.models import Model, load_model
from keras.layers.core import Dense
from keras.layers.pooling import GlobalAveragePooling2D
from keras.layers.normalization import BatchNormalization
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau
from keras.optimizers import Adam
# fine tuningに用いる学習済みモデル
from keras.applications.vgg16 import VGG16
from keras.applications.resnet50 import ResNet50
from keras.applications.xception import Xception
from keras.applications.inception_resnet_v2 import InceptionResNetV2
学習済みモデルを読み込みます。以下は VGG16 の例です。他の学習済みモデルを利用する場合も、たいていは、base_model への代入式の右辺のクラス名を変更するだけで済みます。(VGG16, ResNet50, Xception, InceptionResNetV2, MobileNetV2 について確認済み。)
base_model = VGG16(
include_top=False, weights='imagenet',
input_shape=(image_size, image_size, 3))
読み込んだ学習済みモデルに、出力部分のネットワークを追加します。出力部分のネットワーク構造は様々な工夫やチューニングができる部分ですが、今回は「簡易fine-tuning」なので、実績のある構造をそのまま固定で使うことにします。
def build_FT_model(base_model, num_classes):
# bese_model に top_model を追加する
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(num_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.summary() # モデル構造を確認
print('total number of layers', len(model.layers))
return model
model = build_FT_model(base_model, num_classes)
fine-tuning
次に、layerごとに、パラメーターを再学習するか、凍結するか(読み込んだ学習済みモデルのパラメーター値を維持するか)を決めます。凍結するレイヤ数 n_frozen_layers の指定に従い、第0層から第(n_frozen_layers - 1)層までのパラメーターを凍結し、それ以降の層は再学習対象とします。
学習済みモデルのニューラルネットワークが複数のブロック(機能的に関連する複数のlayerを一つにまとめた単位)から構成されている場合、n_frozen_layers はブロックとブロックの境界の位置を指定するのがよいと思われます。1つのブロック内で一部のパラメーターのみ凍結すると、意図しない動作をするかもしれないので。
ただし、BatchNormalization層は凍結の対象外としています。Kerasを用いる場合、BatchNormalization層を凍結すると精度が大きく低下することが報告されているためです(Referenceの[6][7]を参照)。しっかり検証したわけではないですが、数回の実験では、実際にそのとおりでした。
再学習させるパラメーターを決めた後は、通常のCNNと同じように、コンパイル、学習、評価を行います。
model_dir = './model/'
def eval_FT_model(
model, model_name,
X_train, y_train, X_valid, y_valid, X_test, y_test,
n_frozen_layers=0, lr=1e-3):
# 学習させるlayerを指定する
for i in range(len(model.layers)):
# 前から(n_frozen_layers)個のlayerのパラメーターは学習不可にする。
# ただし、Batch Normalization layerは全て学習可のままにする。
model.layers[i].trainable = \
(i >= n_frozen_layers) or \
isinstance(model.layers[i], BatchNormalization)
# コンパイル
model.compile(optimizer=Adam(lr=lr),
loss='categorical_crossentropy', metrics=['accuracy'] )
# Data Augmentation の方法を定義
datagen = ImageDataGenerator(
width_shift_range=0.1, height_shift_range=0.1,
horizontal_flip=True, vertical_flip=False )
# 学習
hist = model.fit_generator(
datagen.flow(X_train, y_train, batch_size=32),
steps_per_epoch=X_train.shape[0] // 32,
epochs=50,
validation_data=(X_valid, y_valid),
callbacks=[
EarlyStopping(monitor='val_loss', patience=10, verbose=1),
ReduceLROnPlateau(monitor='val_loss',
factor=0.25, patience=4, verbose=1)],
shuffle=True, verbose=1 )
# 学習曲線のプロット
learning_plot(model_name, hist.history)
# モデル評価
last_score = model.evaluate(X_test, y_test, verbose = 1)
print(f'test loss for the last model: {last_score[0]:.4f}')
print(f'test acc for the last model: {last_score[1]:.2%}')
model.save(f'{model_dir}model_{model_name}_last.hdf5')
# 学習曲線のプロット
def learning_plot(model_name, history):
plt.figure(figsize = (18,6))
# loss
plt.subplot(1, 2, 1)
plt.plot(history['loss'], label='loss', marker='o')
plt.plot(history['val_loss'], label='val_loss', marker='o')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.title(model_name)
plt.legend(loc='best')
plt.grid(color='gray', alpha=0.2)
# accuracy
plt.subplot(1, 2, 2)
plt.plot(history['acc'], label='acc', marker='o')
plt.plot(history['val_acc'], label='val_acc', marker='o')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.title(model_name)
plt.legend(loc='best')
plt.grid(color='gray', alpha=0.2)
plt.show()
model_name = 'VGG16'
n_frozen_layers = 17 # 凍結するlayer数
lr = 1e-4
eval_FT_model(
model, model_name,
X_train, y_train, X_valid, y_valid, X_test, y_test,
n_frozen_layers=n_frozen_layers, lr=lr)
予測結果を確認します。
import random
def pred_model(model_name, X_test, y_test):
# モデル読み込み
model = load_model(f'{model_dir}model_{model_name}_last.hdf5')
# モデル評価
score = model.evaluate(X_test, y_test, verbose = 0)
print(f'test loss for the last model: {score[0]:.4f}')
print(f'test acc for the last model: {score[1]:.2%}')
# ランダムに30件のデータを抽出する
samples = random.sample(range(len(X_test)), 30)
X_samples = X_test[samples]
y_samples = y_test[samples]
# 正解ラベル、予測ラベル、予測確率を算出
true_label_idx = np.argmax(y_samples, axis=1) # 正解ラベル
pred_label_idx = np.argmax(model.predict(X_samples), axis=1) # 予測ラベル
pred_probs = np.max (model.predict(X_samples), axis=1)
pred_probs = [f'{i:.4f}' for i in pred_probs] # 予測確率
# 表示
plt.figure(figsize = (16, 16))
for i in range(30):
plt.subplot(5, 6, i+1)
plt.axis('off')
plt.title(
f'pre : {labels[pred_label_idx[i]]}\n' +
f' {pred_probs[i]}\n' +
f'true: {labels[true_label_idx[i]]}',
color=('black' if pred_label_idx[i] == true_label_idx[i] else 'red' ) )
plt.imshow(X_samples[i])
plt.show()
model_name = 'VGG16'
pred_model(model_name, X_test, y_test)
(2021/3/21追記)コードをGitHubで公開しました
上記のコードをGitHubで公開しました: easy_fine_tuning_with_keras
なお、以下の修正を加えています。
- Google Colab上で動作するように修正しました。
- 現在、Google Colab上では、Keras 2.4 が使われています。Keras 2.3よりmetricsの指定方法が変更になった ( hist.history[key]のkeyの値として指定する文字列が変更になった )ため、metricsの名前の'acc'を'accuracy'に、'val_acc'を'val_accuracy'に変更しました。 (この修正によりKeras 2.2以前では動かなくなりました。Keras 2.2以前で動かす場合は、'acc', 'val_acc'に戻してください。)
- データの置き場所を指定する変数(base_path) を追加し、初期値をGoogle Colabの環境に合わせて設定しました。
- Intel Image Classificationのデータセットの構造変更に対応しました。
- 本記事の公開後、Intel Image Classificationのデータセットarchive.zipの中の画像データの格納パスが、seg_train/seg_train/(label)/....jpg に変更されました。これに対応するため、画像データの読み込みをしている
preprocessing関数を修正しました。
ちょっと残念なのですが、Google ColabのKeras 2.4上では、条件によっては学習がうまくできなくなる場合があるようです。例えば:
- ベースモデルをResNet50、1クラスあたりのデータ数を100件とした場合、localのKeras 2.2上では学習に成功しました。accuracyは88%程度でした。
- ベースモデルをResNet50、1クラスあたりのデータ数を100件とした場合、Google ColabのKeras 2.4上では学習に失敗しました。accuracyは17%程度=1/6でした。
- ベースモデルをResNet50、1クラスあたりのデータ数を300件とした場合、Google ColabのKeras 2.4上でも学習に成功しました。accuracyは91%程度でした。
使用するKerasのバージョンの違いが影響しているのかもしれません。ライブラリのバージョンに合わせたチューニングの余地があるのかもしれません。
Reference
記事内で参照している情報:
[1] Kaggle Facial Keypoints DetectionをKerasで実装する/転移学習
[2] Building powerful image classification models using very little data
[3] Intel Image Classification
[4] Keras学習済みモデルをFine-tuningさせて精度比較
[5] Keras Documentation - Available models
[6] KerasでBatchNormalization層を転移学習をする際の注意点
[7] The Batch Normalization layer of Keras is broken
[8] ハイパーパラメータ探索手法の紹介・比較
[9] ハイパーパラメータ自動調整いろいろ
使用したモデルの提案論文:
[VGG16] Very Deep Convolutional Networks for Large-Scale Image Recognition
[ResNet50] Deep Residual Learning for Image Recognition
[Xception] Xception: Deep Learning with Depthwise Separable Convolutions
[InceptionResNetV2] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
[MobileNetV2] MobileNetV2: Inverted Residuals and Linear Bottlenecks
変更履歴
2019/ 9/30 第1版(仮)公開
2019/10/ 8 第2版 使用コードと、その説明を追加。
2019/10/ 9 第3版 説明文を改善。
2019/10/ 9 第4版 MobileNetV2の暫定評価、予測結果確認用コード、Referenceを追加。
2019/10/21 第5版 最新の評価結果を反映。タイトル変更: 適当fine-tuning→簡易fine-tuinig(「適当」な感じが減ってきたので(笑))。
2019/10/23 第6版 最新の評価結果を反映。評価条件を明確化。
2019/11/11 第7版 「ハイパーパラメーターと平均Test Accの関係」、「簡易fine-tuningの検討」、「ハイパーパラメータ探索手法と簡易fine-tuningの関係」を追加。最新の評価結果を反映。
2019/11/25 第8版 ケースAの追加評価結果(VGG16, ResNet50, Xception)を反映。
2019/12/ 1 第9版 ケースAの追加評価結果(InceptionResNetV2, MobileNetV2)を反映。(当初、予定していた評価が完了しました。)
2021/3/21 GitHubで公開したコードの紹介を追記。