はじめに
本記事では、ディープラーニングを使って作成した、1枚のRGB画像から深度推定(Depth Prediction)を行うモデルを動かしてみたので、その内容を共有します。
ちなみに、ディープラーニング、Tensorflowについて初心者が記載しているので、その点ご了承ください。
深度推定は何に使うのか?
深度推定は、単眼カメラでとらえた映像から、そこに写っているものの距離の割り出しを行い、周辺環境を三次元的に捉えるのに役立ちます。
そのため、主な用途の一つに、ステレオカメラを搭載できないロボットやドローン、自動車などにおける自動運転を行う際の、周辺空間の三次元地図の作成と自位置の推定(これは、SLAM: Simultaneous Localization and Mapping 技術と呼ばれています)への利用があります。
今回試してみた手法
ディープラーニングによる深度推定は、色々な研究があるようですが、今回Tensorflow用のコードがGitHubで公開されていた下記論文の手法によるモデルを試しました。
- 論文名: Deeper Depth Prediction with Fully Convolutional Residual Networks
- 発効日: 2016年6月1日
- 論文のURL: https://arxiv.org/abs/1606.00373
- GitHubのURL: https://github.com/iro-cp/FCRN-DepthPrediction
今回試してみた環境
| 項目 | 内容 |
|---|---|
| 端末 | MacBook Air (13-inch, Early 2015) |
| スペック | CPU 1.6 GHz デュアルコアIntel Core i5、メモリ 8GB 1600 MHz DDR3 |
| OS | macOS Catalina バージョン 10.15.1 |
本手法の概要
本手法の非常にざっくりした内容は下記です。
- 画像の分類を行うための、50層の畳み込みニューラルネットワークである、ResNet-50 をベースにしている
- ネットワークの前半(17層あたり)は、ほぼResNet-50を踏襲しており、畳み込みを行なっている
- ネットワークの後半は、畳み込んで縮小された特徴マップに、4回アップサンプリング(2倍の拡大)をかけている
論文に掲載されているニューラルネットワークの図を載せられれば、もう少し分かりやすくなると思うのですが、著作権的が気になったので、やめておきます(上記論文URLから参照できるpdfの3ページ目にあります)。
深度推定してみる
Githubには、深度推定モデルを学習させるためのTensorflow用のコードがありますが、すでに学習済みのモデルが公開されているので、それを動かしてみました。
環境構築
最初に環境構築を行います。下記は、pythonをvirtualenv で独立した環境として構築する例になります。
(1) リポジトリのクローン
$ git clone https://github.com/iro-cp/FCRN-DepthPrediction.git
$ cd FCRN-DepthPrediction
(2) Python 3.7 の仮想環境の構築
$ virtualenv -p python3.7 python3.7
$ source python3.7/bin/activate
(python3.7)$
virtualenvは、Mac OSのパッケージ管理ツールであるbrewを使ってインストールしたものを使っています。
2つ目のコマンドで、python3.7の仮想環境を有効化しており、プロンプトが "(python3.7)$" に変わっています。
ちなみに仮装環境を抜ける場合は deactivate コマンドを実行してください。
(3) 必要なパッケージのインストール
(python3.7)$ pip install tensorflow==1.15.0
(python3.7)$ pip install opencv-python
(python3.7)$ pip install matplotlib
(python3.7)$ pip install Pillow
(python3.7)$ pip install numpy
(python3.7)$ pip install argparse
クローンに含まれる python スクリプトが tensorflowの2系に対応していないため、バージョン1系を指定しています。
(4) 学習済みモデルのダウンロード
クローンしたREADME.md に学習済みのモデルのダウンロードリンクが記載されているので、今回はこれを使います。トップディレクトリ配下の tensorflow/models に展開します。
(python3.7)$ cd tensorflow/models
(python3.7)$ wget http://campar.in.tum.de/files/rupprecht/depthpred/NYU_FCRN-checkpoint.zip
(python3.7)$ unzip NYU_FCRN-checkpoint.zip
[クローンしたトップディレクトリ]/tensorflow/models 配下は下記のファイルがあるはずです。
NYU_FCRN-checkpoint.zip NYU_FCRN.ckpt.index __init__.py network.py
NYU_FCRN.ckpt.data-00000-of-00001 NYU_FCRN.ckpt.meta fcrn.py
推定モデルの実行
準備ができました。リポジトリには、推定モデル実行用のpythonスクリプトが用意されています。
深度推定したい画像(今回JPEG画像で試しました)を用意して下記を実行します。
(python3.7)$ cd .. ([クローンしたトップディレクトリ]/tensorflow に移動)
(python3.7)$ ls (下記のファイル/フォルダがあるはず)
models predict.py
(python3.7)$ python predict.py models/NYU_FCRN.ckpt [入力画像のファイルパス]
実行結果の出力は、入力画像の縦横半分のサイズの、各ピクセルの推定深度(単位:メートル)の配列ですが、モデル実行のスクリプトではカラーマップに変換したものを表示してくれます。
学習済みモデルについて(補足)
上記でダウンロードした学習済みモデルについて少し補足します。
本モデルは、「NYU Depth v2」と呼ばれる公開されている、深度推定用のデータセットで、Microsoft Kinect (ステレオカメラ) でキャプチャされた屋内の64シーンを学習データに使用しています。
そのため、主に屋内の深度推定を対象としたモデルとなります。
実行結果
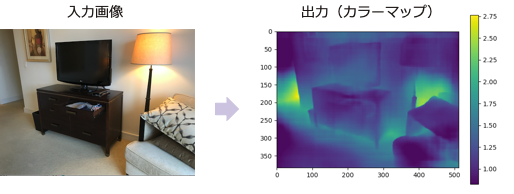
屋内の画像について実施した結果のサンプルが下記です。
出力画像の右のバーは、色と深度(メートル)の対応を示しています。
屋内画像の実行サンプル
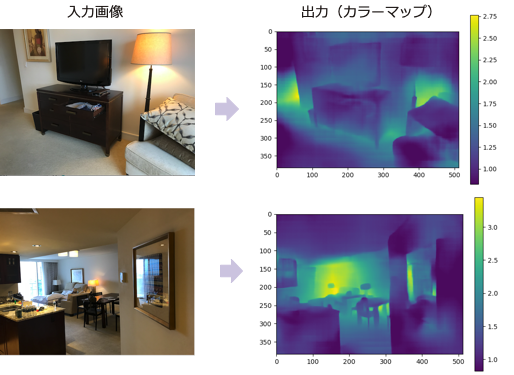
実際の距離とのきちんとした付き合わせは行なっていませんが、一見それっぽく見えるものの、一番明るい(距離が遠い)部分の範囲が実際とは異なるように見受けられます。
2番目の画像では、額縁内のガラスの反射部分が遠い距離と出力されています(本当は近い)。
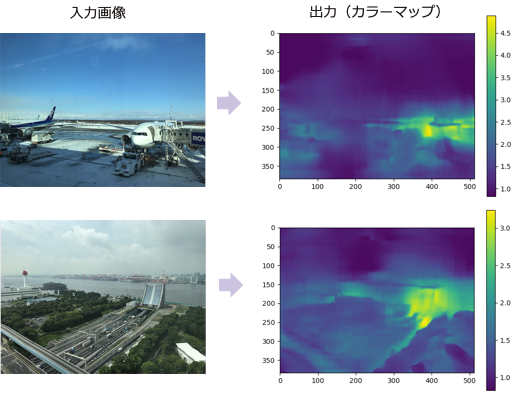
屋外画像の実行サンプル
今回の学習済みモデルは、屋内画像を元にして学習したものですが、一応、屋外画像に対しても実行してみました。
結果は、やはり微妙で、空は近距離と判断されてしまっているようです。
実行時間
実行時間は、入力画像のサイズが大きいほど長くなります。
参考まで、今回の環境で、同じ元画像をいくつかのサイズに変換して実行した結果を下記に掲載しておきます。
| 画像ピクセルサイズ | 実行時間[秒](3回分) | 平均実行時間[秒] |
|---|---|---|
| 960x720 | 10.81, 9.09, 8.87 | 9.59 |
| 480x360 | 3.03, 2.53, 5.60 | 3.72 |
| 240x180 | 1.24, 1.38, 2.15 | 1.59 |
移動物体のカメラ映像(連続画像)をリアルタイムの推定したい場合は、実行時間をどうクリアするかもポイントになると思います。
その他の手法
最後に深度推定に関するその他の手法についても、いくつか掲載しておきます。
| 論文名 | 概要 | URL | 発効日 | 実装 |
|---|---|---|---|---|
| Unsupervised Learning of Depth and Ego-Motion from Video | 単眼ビデオからの深度推定とエゴモーション推定 | https://people.eecs.berkeley.edu/~tinghuiz/projects/SfMLearner/cvpr17_sfm_final.pdf | 2017 | |
| Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos | 単眼ビデオからの深度推定とエゴモーション推定にオブジェクトサイズ制限を加えた改良版 | https://arxiv.org/abs/1811.06152 | 2018/11/15 | https://sites.google.com/view/struct2depth |
以上です。