ウイイレのデータ解析自動化してくよ! part3
どうもヤジュンです!
本記事はシリーズもので、Part3です。よかったら一緒に読んでもらえたらと思います。
ソフトはPythonで書いています。■参考URL
■宣伝
- ウイイレのイベント告知用Bot作成したので、利用してもらえたら幸いです。
- コンテンツ発信のおかげか、eスポーツ人材の紹介サイトに登録させてもらえました。リンク
- 今後、解析ソフトと連動した取り組みをYoutube上でする予定です。リンク
■はじめに
-
今までの活動で、データ抽出からグラフ解析までのソフトを作成し、新しい機能追加を目指していました!
「もっとデータを集めて新たな解析をしよう!」 「ウイイレの攻略法を導きだそう!」しかし、ある問題が開発効率を大きく下げてました...それは
作成した文字認識ソフトの精度が95%だったのです!


▼精度95%がダメな理由
-
データ解析のフローを載せました
「②文字データ抽出」精度が95%ということは、残5%のエラーを修正しなくてはいけません。
1試合分のデータで数箇所直す感じです。仮に解析サービスを、顧客10人に6か月続けるとします。
プロや配信者をターゲットとし、年2000試合のデータが来ると仮定します。10人 x 2000試合(1年) x 0.5(半年) = 10000試合分1試合数個の修正でも、10000試合分だと破綻しますね。。。
したがって、データ抽出精度100%は必須要件なのです。

■ゴール
- 「ウイイレの試合結果画像からのデータ抽出精度を100%にする」をゴールとしました。
■方法
▼方法 : OCR
-
最初はOCRをベースとして、精度100%にする取り組みをしました.
OCRは画像に含まれる文字から、文字データを抽出する技術です。
結論から言うと、性能は達成できませんでした。
ただ、OCRを使いたいエンジニア向けに私の経験を残しておきます。OCRの精度は、以下の因子によって構成されます。
①入力データのノイズ ②ツール・ライブラリの性能 ③動作モード ④出力結果からのノイズ削除
①入力データ
- PS4からの付属のスクリーンショット機能で、画像を取得しているので画質等の改善は難しいです。
OCRは、物体から特徴量を抽出するので、入力データの品質は重要です.
②ツール・ライブラリの性能
- Part1から採用していたのは、tesseract-ocrです。
無料のライブラリで、pythonで利用されることも多く、参考にできるサイトがたくさんあります。
- 次に検討したのは、Google Vision APIです。
なんと、ツール紹介ページでデモ実行ができる神仕様!さすがGoogle様や。。。入社したかった。。。
早速、ウイイレの試合結果画像を突っ込んでみました。


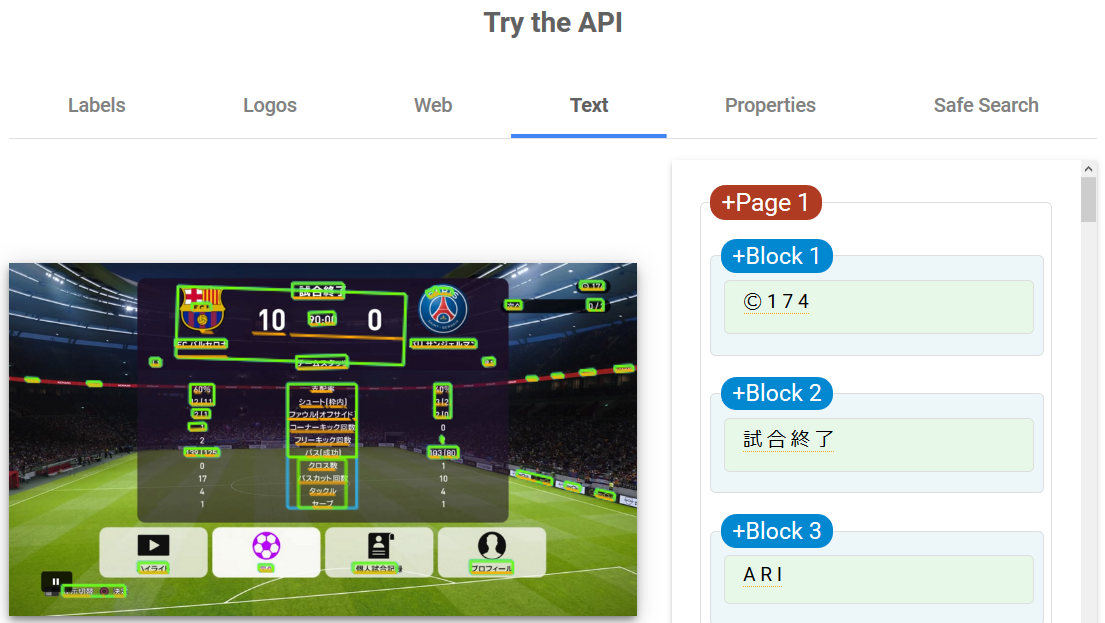
-
かっこいいUIですね!タブ毎に情報が出されます。
Labal Logos Web Text Properties Safe Search -
注目するのは「Text」タブで、画像からの文字データを認識しています。
結論から言うと期待する性能はなさそうです。
文字として認識した場所は、緑色で枠どられていますが、「クロス本数」などの数字データは認識してません。
(ロゴからサッカーチームを特定するのは個人的に感動した!)
- 他のライブラリも考えましたが、Google先生の性能をベースに考えると無駄な可能性が高いです。
素直に、Tesseractで開発を進めることにしました。
③動作モード
-
OCRのライブラリには、動作モードの指定ができます。
解析対象は、「1文字なのか?」「文字列なのか?」「縦書きか?」「横書きか?」「数字なのか?」「アルファベットなのか?」などを指定するのです。出力結果が数字でなかったりした場合は、動作モードを変えて再実行するようにします。
④出力結果からのノイズ削除
-
最終的に出てくる文字列に、「.」や[|]などのノイズがあることもあります。
そのため、文字列から数字データ以外の文字を削除するようにソフトを書きます。これだけやった結果が、認識精度95%なのです。。。
実際の出力結果が見たい人は■結果
▼方法 : Template Matching
-
さあ真打登場!
Template Matchingは、ある画像から特定の画像を探すという画像処理の一つです。ライブラリはOpencvを使います。
入力データである「ウイイレ試合結果」は、Template Matchingにとって有利な特徴を持っています。
詳細は以下の通り。回転しない ゆがまない 各データの位置は統一 フォントも統一 サイズも統一
・前準備
- 特徴を知ったところで、どんどん進んでいきましょう!
Template Matching用データとしてウイイレの試合結果から「数字データ画像」を集めます。
(面倒くさいです!!)

・デモプレイ
-
集めた画像データをTemplateとして、Template Matchingを実行します。
使用した関数はcv2.matchTemplate()です。
数字が小さいほど緑色、大きいほど赤色の枠で囲まれるデモコードを書いて実行します。
確実にGoogle Vision APIの性能を超えてますね!!枠が表示された場所に、該当する数字があるとしてデータを保存します。
その際、場所によって「どのパラメータの数字か」を判断させることで、画像からデータを抽出する仕組みです。

・検出感度
-
この欄は、エンジニア向けに技術的な話を書いておきます。
Template Matchingにとって、エンジニアを悩ませるのが「検出感度」です。
「検出感度」によって変わるのは、偽陽性と偽陰性です。
今回のソフトを例にすると偽陽性:本当は数字が「ない」場所で、数字が「ある」と判定してしまうこと 偽陰性:本当は数字が「ある」場所で、数字が「ない」と判定してしまうことこれを調整できるのが「検出感度」です。
「偽陽性と偽陰性の両方がなくなるように検出感度調整すればいいじゃん!」と思われるかもしれませんが、大抵無理です!
理由は、「偽陽性と偽陰性がある検出感度の区間は被っていることが多い」からです。

-
では、どうするのか?
検出感度を「偽陽性か偽陰性のうち片方しかない」ように設定するのです。
あとは結果から偽物を発見・排除するようにソフトを書きます。
仮に、偽陽性と偽陰性が共存する感度だと、コードが複雑になります。ちなみに、今回のソフトは偽陽性側に振っています。
オブジェクト数(数字の数)が不定なので、偽陰性は検出はできないからです。▼偽陰性を検出するためのロジック▼ あるはずの数字の数 - 検出できた数字の数 = 差分があれば偽陰性あり
■結果
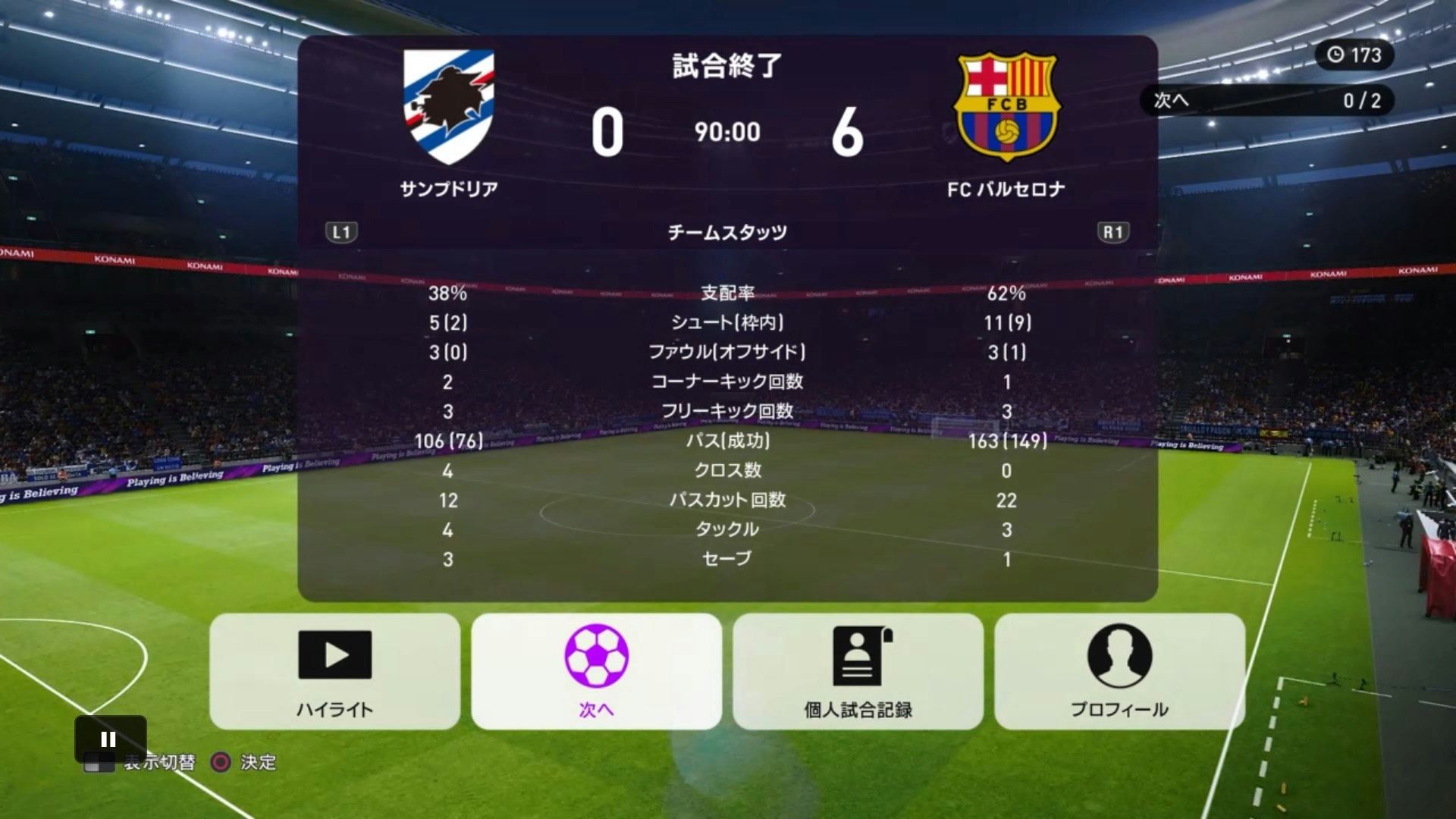
- 以下の5枚を入力画像として、ソフトを実行してみました。
▼結果 : 入力画像




▼結果 : 出力結果
-
出力データはCSVで出ます。
差分がわかりやすいように、「改善したOCRソフト」の結果も載せて比較します。
正解データと比較して、誤っているセルは色付きで表示させています。正答率100%を達成できました!!わーい(祝)


■おわりに
-
ここまで読んでくれてありがとうございます!
文字認識精度を100%にできたので、データ抽出からグラフ作成まで完全自動化できました!
これで、何試合でも解析可能です♪あと、偽陽性/偽陰性を考慮したソフト設計は、エンジニアの方にも勉強になったのではないでしょうか?
誰かのお役に立ててたら幸いです。今後も、ソフトへの機能追加・性能改善を進めていきます。
part4をお楽しみに!