概要
ELMoやBERTといった自然言語処理モデルは文脈を考慮した単語分散表現を与えるため、複数の意味を持つ多義語が文章の中でどういった意味で使われているのかを区別することができると期待できます。以前に投稿した記事
では英語版のELMoとBERTを使って、"right"という単語の「右」「正しい」「権利」という3つの意味を区別できるかの検証を行いました。今回は日本語版の事前学習済みELMoとBERTを使って、日本語の多義語に対して同様の実験を行ってみます。
日本語事前学習済みのELMoとBERTは、どちらもストックマークが公開しているモデルを使用します。
問題設定
英語版の実験では"right"の3つの意味を区別しましたが、日本語では3つ以上の意味を持つ良い例が見つからなかったので、2つの意味を持つ多義語を複数考えることにします。「結構」「失敬」「無心」「首」という4つの多義語の一つの意味ごとに4文ずつ、合計32の例文を使います。例文のほとんどはネット上の国語辞書などから採取したもので、一部は改変しています。
- 結構 ― 意味A(完全ではないが、それなりに十分であるさま。)
初めてクッキーを作ったけど、難しくなかったし、結構おいしく作れたと思う。
彼は口には出さないけど、背が小さいことをを結構気にしています。
あそこのレストランは、安いのに結構おいしいんですよ。
トイレのあとで、手を洗わない人は結構たくさんいます。
- 結構 ― 意味B(それでよいさま。 それ以上必要としないさま。)
もう十分いただきました。これ以上は結構です。
そんなことまでしていただかなくても結構です。
この際には土地はいただかないことにして、金でお願いができますれば結構だと存じていたのでございますが。
それでも、先生はほかの人と違って、遊びながらお仕事が出来るので結構でございます。
- 失敬 ― 意味A(失礼。無礼。)
昨晩はお見苦しいところをお見せして失敬しました。
全体あなたがたはこんな失敬なことを言っていて、自分では気がつかんのですか。
失敬な発言ばかりが口をついて出てしまう彼は、案の定職場で上手くいかず、すぐに辞めてしまった。
何を言うんだ。失敬な事を言うな。ここは、お前たちの来るところでは無い。帰れ!
- 失敬 ― 意味B(盗むこと。)
兄の本棚からちょっと失敬してきた。
このボールペンを失敬させてもらいますね。
一人の学生が巡査の帽子を失敬して一目散に走り出した。
さて退出するときに、彼はテーブルから自分のものでない手紙を失敬して行ったのですよ。
- 無心 ― 意味A(雑念や欲心のないこと。)
月の輝きを無心に眺めているうちに、天吾の中に古代から受け継がれてきた記憶のようなものが呼び起こされていった。
そして、この努力を無心に続ければいつかはなにか突破口につながると思いたかった。
すすきの花の向い火や、きらめく赤褐の樹立のなかに、鹿が無心に遊んでいます。
波の音は、無心に、終日岸の岩角にぶつかって、砕けて、しぶきをあげていました。
- 無心 ― 意味B(人に金品をねだること。)
これを訪ね身の振り方を相談した途端に、姉の亭主に、三百円の無心をされた。
そのとき、ちょうど門口へ乳飲子をおぶった女こじきが立って、無心をねがったのでした。
逮捕された男の母親が取材に対し、容疑者から前日に金を無心され暴行されていたことを明らかにしました。
その結果はちょいちょい耕太郎が無心の手紙を持たされて、一里の道を老父の処へ使いにやらされた。
- 首 ― 意味A(脊椎動物の頭と胴をつないでいる部分。)
首をかたむけた時に邪魔になるので、髪の毛はいつもしばっています。
首を後ろに反らせながら、引きつったような声で笑う。
長めな首の美しさを引き立てるためか、洋服の襟に白い飾りがあった。
従業員は眉を少ししかめ、考えを巡らせ、それから丁寧に首を横に振った。
- 首 ― 意味B(解雇。)
労働災害による休業中の労働者を、首にすることはできません。
このプロジェクトには、このチーム一人一人の首がかかっている。
首になりたくなければ、ちゃんと成果を上げろ!
会社を首にされたが、家族には言い出せず、毎日会社に行くふりをして公園で過ごしている。
「首」の意味Bについてはカタカナで「クビ」と書くのが一般的だと思いますが、意味Aと同じ表現とするために漢字で書いています。
これらの例文をELMoおよびBERTに入力して対象単語の埋め込みベクトルを取り出し、ベクトルどうしのコサイン類似度
cossim(\mathbf{u} ,\mathbf{v} ) = \frac{\mathbf{u} \cdot \mathbf{v}}{|\mathbf{u}| \, |\mathbf{v}|}
を計算して、同じ意味の単語どうしの類似度が高くなるかを検証します。
実装
計算はGoogle colaboratory上で行いました。TensorFlowはバージョン1.x系を使用します。
準備
必要なライブラリをインポートし、Google Driveをマウントします。
import json
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# matplotlibで日本語を使うためのライブラリ
!pip install japanize_matplotlib
import japanize_matplotlib
# Google Driveをマウント
from google.colab import drive
drive.mount('/content/drive')
ストックマークの事前学習モデルはトークナイザーにMeCab+NEologd辞書が使用されています。インストール手順はこちらの記事に書いた通りですが、再掲しておきます。
# MeCabインストール
!apt install aptitude swig
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
# NEologd辞書インストール
%cd /content
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
%cd mecab-ipadic-neologd
!echo yes | ./bin/install-mecab-ipadic-neologd -n
# pythonでMeCabを呼び出すためのライブラリをインストール
!pip install mecab-python3
!pip install unidic-lite # これがないとmecab-python3実行時にエラーが出る
import MeCab
作業は/content/drive/'My Drive'/synonym_classificationというディレクトリで行います。
%cd /content/drive/'My Drive'/synonym_classification
次に、使用する例文のリストを準備します。
target_words = ["結構", "失敬", "無心", "首"]
texts1 = ["初めてクッキーを作ったけど、難しくなかったし、結構おいしく作れたと思う。",
"彼は口には出さないけど、背が小さいことをを結構気にしています。",
"あそこのレストランは、安いのに結構おいしいんですよ。",
"トイレのあとで、手を洗わない人は結構たくさんいます。",
"もう十分いただきました。これ以上は結構です。",
"そんなことまでしていただかなくても結構です。",
"この際には土地はいただかないことにして、金でお願いができますれば結構だと存じていたのでございますが。",
"それでも、先生はほかの人と違って、遊びながらお仕事が出来るので結構でございます。"]
texts2 = ["昨晩はお見苦しいところをお見せして失敬しました。",
"全体あなたがたはこんな失敬なことを言っていて、自分では気がつかんのですか。",
"失敬な発言ばかりが口をついて出てしまう彼は、案の定職場で上手くいかず、すぐに辞めてしまった。",
"何を言うんだ。失敬な事を言うな。ここは、お前たちの来るところでは無い。帰れ!",
"兄の本棚からちょっと失敬してきた。",
"このボールペンを失敬させてもらいますね。",
"一人の学生が巡査の帽子を失敬して一目散に走り出した。",
"さて退出するときに、彼はテーブルから自分のものでない手紙を失敬して行ったのですよ。"]
texts3 = ["月の輝きを無心に眺めているうちに、天吾の中に古代から受け継がれてきた記憶のようなものが呼び起こされていった。",
"波の音は、無心に、終日岸の岩角にぶつかって、砕けて、しぶきをあげていました。。",
"そして、この努力を無心に続ければいつかはなにか突破口につながると思いたかった。",
"すすきの花の向い火や、きらめく赤褐の樹立のなかに、鹿が無心に遊んでいます。",
"これを訪ね身の振り方を相談した途端に、姉の亭主に、三百円の無心をされた。",
"そのとき、ちょうど門口へ乳飲子をおぶった女こじきが立って、無心をねがったのでした。",
"逮捕された男の母親が取材に対し、容疑者から前日に金を無心され暴行されていたことを明らかにしました。",
"その結果はちょいちょい耕太郎が無心の手紙を持たされて、一里の道を老父の処へ使いにやらされた。", ]
texts4 = ["首をかたむけた時に邪魔になるので、髪の毛はいつもしばっています。",
"首を後ろに反らせながら、引きつったような声で笑う。",
"長めな首の美しさを引き立てるためか、洋服の襟に白い飾りがあった。",
"従業員は眉を少ししかめ、考えを巡らせ、それから丁寧に首を横に振った。",
"労働災害による休業中の労働者を、首にすることはできません。",
"このプロジェクトには、このチーム一人一人の首がかかっている。",
"首になりたくなければ、ちゃんと成果を上げろ!",
"会社を首にされたが、家族には言い出せず、毎日会社に行くふりをして公園で過ごしている。"]
BERTにはファイルから入力する必要があるので、テキストファイルに書き込んでおきます。
with open('texts1.txt', mode='w') as f:
f.write('\n'.join(texts1))
with open('texts2.txt', mode='w') as f:
f.write('\n'.join(texts2))
with open('texts3.txt', mode='w') as f:
f.write('\n'.join(texts3))
with open('texts4.txt', mode='w') as f:
f.write('\n'.join(texts4))
ELMoへの入力はあらかじめトークン化しておく必要があるので、トークナイザー関数を用意して、各文章をトークン化します。
def mecab_tokenizer(texts,
dict_path="/usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"):
mecab = MeCab.Tagger("-Owakati -d " + dict_path)
token_list = []
for s in texts:
parsed = mecab.parse(s).replace('\n', '')
token_list += [parsed.split()]
return token_list
token_list1 = mecab_tokenizer(texts1)
token_list2 = mecab_tokenizer(texts2)
token_list3 = mecab_tokenizer(texts3)
token_list4 = mecab_tokenizer(texts4)
token_list1の中身は以下のようになります。
['初めて', 'クッキー', 'を', '作っ', 'た', 'けど', '、', '難しく', 'なかっ', 'た', 'し', '、', '結構', 'おいしく', '作れ', 'た', 'と', '思う', '。']
['彼', 'は', '口', 'に', 'は', '出さ', 'ない', 'けど', '、', '背', 'が', '小さい', 'こと', 'を', 'を', '結構', '気', 'に', 'し', 'て', 'い', 'ます', '。']
['あそこ', 'の', 'レストラン', 'は', '、', '安い', 'のに', '結構', 'おいしい', 'ん', 'です', 'よ', '。']
['トイレ', 'の', 'あと', 'で', '、', '手', 'を', '洗わ', 'ない', '人', 'は', '結構', 'たくさん', 'い', 'ます', '。']
['もう', '十分', 'いただき', 'まし', 'た', '。', 'これ', '以上', 'は', '結構', 'です', '。']
['そんな', 'こと', 'まで', 'し', 'て', 'いただか', 'なく', 'て', 'も', '結構', 'です', '。']
['この', '際', 'に', 'は', '土地', 'は', 'いただか', 'ない', 'こと', 'に', 'し', 'て', '、', '金', 'で', 'お願い', 'が', 'でき', 'ますれ', 'ば', '結構', 'だ', 'と', '存じ', 'て', 'い', 'た', 'の', 'で', 'ござい', 'ます', 'が', '。']
['それでも', '、', '先生', 'は', 'ほか', 'の', '人', 'と', '違っ', 'て', '、', '遊び', 'ながら', 'お仕事', 'が', '出来る', 'ので', '結構', 'で', 'ござい', 'ます', '。']
多義語を判別するというタスクのためにはターゲットとしている単語が単一のトークンとして分離されている必要がありますが、確かにどの文章でも「結構」が一つのトークンとなっています。他のターゲット単語も同様にトークン化できていました。実は、この条件を満たす多義語を選定するのが今回一番苦労した部分です。
本当はストックマークのモデル以外にも他の日本語事前学習済みBERTも使って結果を比較したかったのですが、NEologd辞書以外の辞書だと例えば「結構です」が一つのトークンとなったり、WordPieceやSentencePieceでトークン化すると「結」と「構」が分離されてしまったりして、多義語を判別するというタスクが実行できませんでした。このような理由で、今回はストックマークの事前学習済みELMoとBERTのみの比較となっています。
ELMo
ELMoモデルはこちらの実装をストックマークの事前学習済みパラメータとともに使用します。使用方法は以前に書いたこちらの記事
と同じです。
!pip install overrides
!git clone https://github.com/HIT-SCIR/ELMoForManyLangs.git
%cd ./ELMoForManyLangs
!python setup.py install
%cd ..
ストックマークの事前学習モデルをこちらからダウンロードしてフォルダ./ELMo_ja_word_levelに配置します。モデルは「単語単位埋め込みモデル」と「文字単位・単語単位埋め込みモデル」がありますが、今回は「単語単位埋め込みモデル」を使用します。
これでモデルの準備が整いましたので、Embedderインスタンスを作成し、ターゲットの単語の埋め込みベクトルを計算して取り出すための関数を定義します。
from ELMoForManyLangs.elmoformanylangs import Embedder
from overrides import overrides
elmo_model_path = "./ELMo_ja_word_level"
elmo_embedder = Embedder(elmo_model_path, batch_size=64)
def my_index(l, x, default=-1):
return l.index(x) if x in l else default
def find_position(token_list, word):
pos_list = [my_index(t, word) for t in token_list]
assert -1 not in pos_list
return pos_list
def get_elmo_word_embeddings(token_list, target_word):
embs_list = elmo_embedder.sents2elmo(token_list, output_layer=-2)
pos_list = find_position(token_list, target_word)
word_emb_list = []
for i, embs in enumerate(embs_list):
word_emb_list.append(embs[:, pos_list[i], :])
return word_emb_list
Embedderインスタンスのメソッドsents2elmoの引数output_layerは埋め込みベクトルを取り出す層を指定するもので、詳細は以下の通りです。
0: 文脈に依存しない最初の単語埋め込み層
1: 1層目のLSTM層
2: 2層目のLSTM層
-1: 3つの層の平均 (default)
-2: 3つの層すべてを出力
今回は出力層による違いを比較するためにoutput_layer=-2を指定しています。
トークン化した文章を入力して、ターゲットの単語の埋め込みベクトルを計算します。
elmo_embeddings = get_elmo_word_embeddings(token_list1, target_words[0])
elmo_embeddings += get_elmo_word_embeddings(token_list2, target_words[1])
elmo_embeddings += get_elmo_word_embeddings(token_list3, target_words[2])
elmo_embeddings += get_elmo_word_embeddings(token_list4, target_words[3])
elmo_embeddings = np.array(elmo_embeddings)
print(elmo_embeddings.shape)
# (32, 3, 1024)
最初の層の文脈に依存しない単語埋め込みは多義語を判別するのには使えませんので、LSTM1層目、2層目とELMoベクトルと呼ばれる3層の平均を使用することにします。
elmo_lstm1_embeddings = elmo_embeddings[:, 1, :]
elmo_lstm2_embeddings = elmo_embeddings[:, 2, :]
elmo_mean_embeddings = np.mean(elmo_embeddings, axis=1)
埋め込みベクトルのコサイン類似度を計算する前に、BERTの埋め込みベクトルも準備します。
BERT
ストックマークの事前学習済みBERTモデルの使用方法についても、基本的に以前に書いたこちらの記事
に準じます。まず、ストックマークの事前学習済みモデル(TensorFlow版)をこちらのリンクからダウンロードし、ディレクトリ./BERT_base_stockmarkに配置します。
次に、TensorFlow version1.x系をインポートし、公式のBERTリポジトリをクローンします。
%tensorflow_version 1.x
import tensorflow as tf
!git clone https://github.com/google-research/bert.git
クローンしたリポジトリのコードのうち、tokenization.pyをトークナイザーにMeCabを使用するように変更する必要があります。こちらに関しては長くなるので再掲しませんので、こちらの記事を参照してください。埋め込みベクトルを取り出すコードextract_features.pyについては今回は変更する必要はありません。
以下のように実行することで、bert_embeddings*.jsonlにすべてのトークンに対する埋め込みベクトルが出力されます。埋め込みベクトルを取り出す層としてはすべての層を指定しています。
# BERT実行
for i in range(1, 5):
input_file = 'texts' + str(i) + '.txt'
output_file = 'bert_embeddings' + str(i) + '.jsonl'
!python ./bert/extract_features_mecab_neologd.py \
--input_file=$input_file \
--output_file=$output_file \
--vocab_file=./BERT_base_stockmark/vocab.txt \
--bert_config_file=./BERT_base_stockmark/bert_config.json \
--init_checkpoint=./BERT_base_stockmark/output_model.ckpt \
--layers 0,1,2,3,4,5,6,7,8,9,10,11
出力されたjsonlファイルからターゲットの単語の埋め込みベクトルだけを取り出します。
def extract_bert_embeddings(input_path, target_token, target_layer=10):
with open(input_path, 'r') as f:
output_jsons = f.readlines()
embs = []
for output_json in output_jsons:
output = json.loads(output_json)
for feature in output['features']:
if feature['token'] != target_token: continue
for layer in feature['layers']:
if layer['index'] != target_layer: continue
embs.append(layer['values'])
return np.array(embs)
bert_embeddings = []
for i in range(12):
emb1 = extract_bert_embeddings('./bert_embeddings1.jsonl',
target_layer=i, target_token=target_words[0])
emb2 = extract_bert_embeddings('./bert_embeddings2.jsonl',
target_layer=i, target_token=target_words[1])
emb3 = extract_bert_embeddings('./bert_embeddings3.jsonl',
target_layer=i, target_token=target_words[2])
emb4 = extract_bert_embeddings('./bert_embeddings4.jsonl',
target_layer=i, target_token=target_words[3])
embeddings = np.vstack([emb1, emb2, emb3, emb4])
bert_embeddings.append(embeddings)
bert_embeddings = np.array(bert_embeddings)
結果
2つのモデルの埋め込みベクトルが準備できましたので、単語の類似度を判定していきます。
最初に、コサイン類似度の相関行列を計算する関数を準備します。
def calc_sim_mat(arr):
num = len(arr) # number of vectors contained in arr
sim_mat = np.zeros((num, num))
norm = np.apply_along_axis(lambda x: np.linalg.norm(x), 1, arr) # norm of each vector
normed_arr = arr / np.reshape(norm, (-1,1))
for i, vec in enumerate(normed_arr):
sim = np.dot(normed_arr, np.reshape(vec, (-1,1)))
sim = np.reshape(sim, -1) #flatten
sim_mat[i] = sim
return sim_mat
まずは、ELMoはLSTMの2層目、BERTは最後から2層目の埋め込みベクトルを使用した結果を見てみます。
sim_mat_elmo = calc_sim_mat(elmo_lstm2_embeddings)
sim_mat_bert = calc_sim_mat(bert_embeddings[10])
計算結果を可視化する関数を用意して実行します。
def show_sim_mat(sim_mat, labels, title=None, export_fig=False):
sns.set(font_scale=1.1, font="IPAexGothic")
g = sns.heatmap(
sim_mat,
vmin=0,
vmax=1,
cmap="YlOrRd")
ticks_pos = range(2, 32, 4)
plt.xticks(ticks=ticks_pos, labels=labels, rotation='vertical')
plt.yticks(ticks=ticks_pos, labels=labels)
for i in range(8, 25, 8):
plt.plot([0, 32], [i, i], ls='-', lw=1, color='b')
plt.plot([i, i], [0, 32], ls='-', lw=1, color='b')
for i in range(4, 29, 8):
plt.plot([0, 32], [i, i], ls='--', lw=1, color='b')
plt.plot([i, i], [0, 32], ls='--', lw=1, color='b')
if title:
plt.title(title, fontsize=24)
if export_fig:
plt.savefig(export_fig, bbox_inches='tight')
plt.show()
labels = ['結構A', '結構B', '失敬A', '失敬B', '無心A', '無心B', '首A', '首B']
show_sim_mat(sim_mat_elmo, labels, 'ELMo', 'ELMo.png')
show_sim_mat(sim_mat_bert, labels, 'BERT', 'BERT.png')
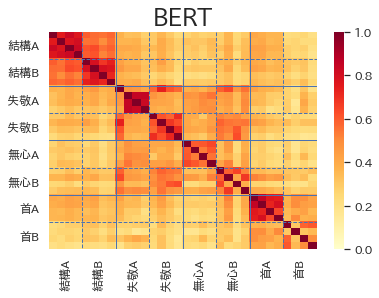
結果は以下の通りです。32の例文の単語間の類似度を32×32マスのヒートマップで表しています。多義語が同じ意味で使われている4文ごとに区切り線を引いています。4×4マスの対角ブロックの色が濃くなり、それ以外の非対角部分の色が薄くなるのが理想なのですがいかがでしょうか。
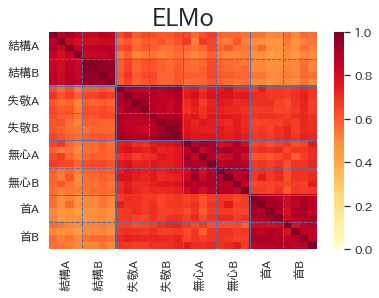
ELMoに関しては、こちらの記事の計算でもそうでしたが、埋め込みベクトルどうしの角度が小さくなる傾向があり、全体的に類似度の値が大きく色が濃くなっています。少なくとも同じ単語の8×8マスの対角ブロックの色は他の部分より濃くなっているのはわかりますが、多義語の意味はそれほどはっきり区別できているようには見えません。
一方でBERTに関しては、4×4マスの対角ブロックの色が非対角部分と比べて濃くなっている箇所がはっきりと見て取れます。特に、結構A・Bと首Aは結構うまく判別できているのではないでしょうか。
さて、ヒートマップを見るだけでは正確な精度評価はできませんので、定量的な指標を使って結果を評価しましょう。多義語の一つの意味につき4つの例文を用意していますので、各多義語は同じ意味の仲間を3つづつ持っていることになります。従って、各多義語に対し類似度上位の3つがモデルが推論した同じ意味の多義語ということになります。このモデルの推論に対する適合率(precision)を計算します。
以下の関数のblock_sizeは上のヒートマップの一つの対角ブロックのサイズで今の場合は4です。32の例文それぞれに対する適合率のリストとその平均値を出力します。
def eval_precision(sim_mat, block_size):
num_data = len(sim_mat)
precision_list = []
for i in range(num_data):
block_id = int(i / block_size)
pred = np.array([1 if (block_id * block_size <= j and j < (block_id+1) * block_size)
else 0 for j in range(num_data)])
sorted_args = np.argsort(sim_mat[i])[::-1]
sorted_pred = pred[sorted_args]
precision = np.mean(sorted_pred[1:block_size])
precision_list.append(precision)
precision_arr = np.array(precision_list)
av_precision = np.mean(precision_arr)
return av_precision, precision_arr
# ELMo LSTM 2層目
av_precision, precision_arr = eval_precision(sim_mat_elmo, block_size=4)
print(np.round(av_precision, 2))
for i in range(8):
print(np.round(precision_arr[4*i:4*(i+1)], 2))
# BERT 11層目
av_precision, precision_arr = eval_precision(sim_mat_bert, block_size=4)
print(np.round(av_precision, 2))
for i in range(8):
print(np.round(precision_arr[4*i:4*(i+1)], 2))
結果は以下のようになりました。
[ELMo LSTM 2層目]
平均 0.54
| 例文1 | 例文2 | 例文3 | 例文4 | |
|---|---|---|---|---|
| 結構A | 1.0 | 0.33 | 0.67 | 0.67 |
| 結構B | 0.67 | 1.0 | 0.33 | 0.67 |
| 失敬A | 0.33 | 0.33 | 0.33 | 0.33 |
| 失敬B | 0.33 | 0.67 | 0.67 | 1.0 |
| 無心A | 0.67 | 0.33 | 0.67 | 0.33 |
| 無心B | 0.67 | 0.33 | 0.33 | 0.67 |
| 首A | 0.67 | 0.67 | 1.0 | 0.67 |
| 首B | 0.67 | 0 | 0 | 0.67 |
[BERT 11層目]
平均 0.78
| 例文1 | 例文2 | 例文3 | 例文4 | |
|---|---|---|---|---|
| 結構A | 1.0 | 1.0 | 1.0 | 1.0 |
| 結構B | 1.0 | 1.0 | 1.0 | 1.0 |
| 失敬A | 0 | 0.67 | 0.67 | 0.67 |
| 失敬B | 1.0 | 0.67 | 0.67 | 0.67 |
| 無心A | 1.0 | 1.0 | 1.0 | 1.0 |
| 無心B | 0.67 | 0.67 | 0.33 | 0.33 |
| 首A | 1.0 | 1.0 | 1.0 | 1.0 |
| 首B | 0.67 | 0 | 0.67 | 0.67 |
やはり定量的に見てもBERTの精度が高いという結果になりました。英語版での実験では適合率の平均値はELMo 0.61、BERT 0.78でしたので、どちらのモデルも英語版とほぼ同じ水準の精度となっています。
両モデル共に首の意味Bで苦戦していますが、クビではなく首と書いたことが影響しているのでしょうか。
最後に、埋め込みベクトルを取り出す層による精度の比較をします。BERTについてはすべての層の平均と後半6層の平均の埋め込みベクトルも計算します。
# ELMo
# LSTM1層目
sim_mat_elmo = calc_sim_mat(elmo_lstm1_embeddings)
av_precision, _ = eval_precision(sim_mat_elmo, block_size=4)
print('LSTM1', np.round(av_precision, 2))
# LSTM2層目
sim_mat_elmo = calc_sim_mat(elmo_lstm2_embeddings)
av_precision, _ = eval_precision(sim_mat_elmo, block_size=4)
print('LSTM2', np.round(av_precision, 2))
# 3層平均
sim_mat_elmo = calc_sim_mat(elmo_mean_embeddings)
av_precision, _ = eval_precision(sim_mat_elmo, block_size=4)
print('mean', np.round(av_precision, 2))
# BERT
# 各層
for i in range(12):
sim_mat_bert = calc_sim_mat(bert_embeddings[i])
av_precision, _ = eval_precision(sim_mat_bert, block_size=4)
print(i+1, np.round(av_precision, 2))
# 全層平均
sim_mat_bert = calc_sim_mat(np.mean(bert_embeddings, axis=0))
av_precision, _ = eval_precision(sim_mat_bert, block_size=4)
print('average-all', np.round(av_precision, 2))
# 後半6層平均
sim_mat_bert = calc_sim_mat(np.mean(bert_embeddings[-6:], axis=0))
av_precision, _ = eval_precision(sim_mat_bert, block_size=4)
print('average-last6', np.round(av_precision, 2))
結果は以下の通りです。すべての例文に対する適合率の平均を示しています。
[ELMo]
| 層 | 適合率平均 |
|---|---|
| LSTM1層目 | 0.52 |
| LSTM2層目 | 0.54 |
| ELMo | 0.54 |
[BERT]
| 層 | 適合率平均 |
|---|---|
| 1層目 | 0.42 |
| 2層目 | 0.48 |
| 3層目 | 0.67 |
| 4層目 | 0.73 |
| 5層目 | 0.73 |
| 6層目 | 0.73 |
| 7層目 | 0.72 |
| 8層目 | 0.73 |
| 9層目 | 0.78 |
| 10層目 | 0.78 |
| 11層目 | 0.78 |
| 12層目 | 0.77 |
| 全層平均 | 0.77 |
| 最終6層平均 | 0.77 |
英語版の実験ではELMoはLSTM1層目、BERTは中間あたりの層で最高精度が達成されていたのですが、今回はELMoはLSTM2層目と3層の平均、BERTは最終層以外の最後の方の層で最高精度となっています。このあたりの傾向は、事前学習データやタスクによって異なるのだと思います。
おわりに
ネタとしては以前に書いた記事と同じでしたが、分かち書きが必要となることなど日本語ゆえの難しさを感じました。ELMoとBERTの比較では、英語版と同様にBERTのほうが精度よく多義語を判別できるという結果となりました。トークナイザーの違いのせいで他の日本語事前学習済みモデルとの比較ができなかったのが残念なところでした。