はじめに
日立製作所クラウドビジネス推進センタの西谷淳平です。今までの連載の中では、分散トランザクションのACID特性と、その背後に潜む分散トランザクションの原則であるCommitment Orderingに着目し、Microservicesで流行っているSagaデザインパタンの整合性担保能力を語りました。その中で、SagaデザインパタンはIsolationだけではなく、A/Cの特性が失われているという事実を指摘し、その結果としてデータ破壊が起こり得るということを説明しました。
そして、Sagaにおける並行制御機能の欠落を埋めるには2Phase Lockの仕組みを導入し、2Phase CommitやTCCのような形態にするしかないとも話しました。では、この2Phase CommitはMicroserviceに親和性があるのでしょうか?今回はその点について触れたいと思います。
本シリーズの予定
- マイクロサービストランザクションの動向
- トランザクションの原則:ACID特性とCommitment Ordering前編
- トランザクションの原則:ACID特性とCommitment Ordering後編
- 合意理論から見る2Phase commitとMicroservice (今回)
- 結果整合性は本当に整合するのか
ゴール
2Phase CommitがMicroserviceで使えるのかを理解する。
2Phase Commitとは何か
2Phase Commitは大昔から存在する分散トランザクションの手法であり、分散合意の手法です。分散したリソースで更新をするときの原子性(全部更新するか、全部更新しないかのall or nothing)を実現するために、調停者・Coordinatorが全参加リソースに対して、更新確定のお伺いをたて(Prepare)、全員が更新に確定して大丈夫(Prepare OK)との返事を受けたあと、Coordinatorが状態確定(Commit)を指示する、二段階を踏みます。この動作が翻って「2Phase」という名前の由来になっています。
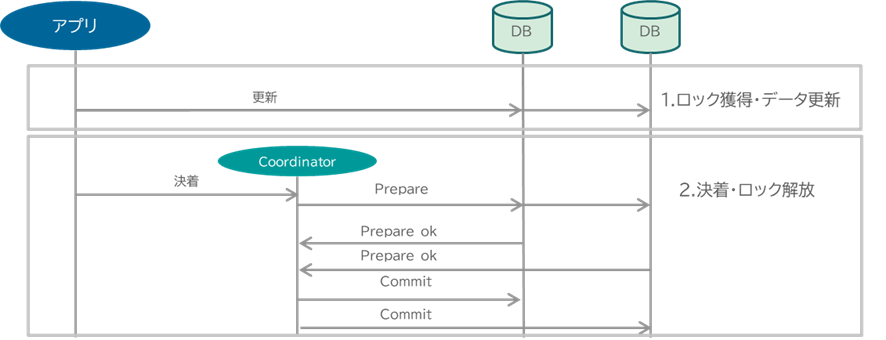
Sagaに対して2Phase Commitには以下2つのメリットがあります。
- 2Phase Lock(更新~状態確定(commit or rollback)の間を排他区間の設定)に代表される直列化機構を搭載していることによって、コンカレンシーによる不整合を防止できる。
- 巻き戻しや排他制御は分散リソースの機能を使用し、トランザクションモニターがそれら機能を使うことによって2phase Commitが動作する。その結果、業務アプリでトランザクション制御を実装する必要がなくなり、JTA/@Transactionalアノテーションのように、業務アプリに対するTransaction制御機能の露出を最低一行程度と極めて少なくできる。このことは、業務ロジックの疎結合性・生産性向上につながる。
そして、Commitment Orderingを実現するために必要な4機能(巻き戻し・並行制御・状態遷移先の出力・分散合意)も搭載しており、分散トランザクションとして使うには申し分ないように見えます。しかし、先に述べた利点があるにも関わらず、Microserviceの世界で2Phase Commitはアンチパタンとみなされており、Microservice以外の世界でも2Phase Commitの評判はあまりよくありません。これにはいくつかの原因があるようです。
2Phase Commitに対するエンジニアの見解
2Phase Commitが嫌われている原因について、いくつかの主張を見てみましょう。
Microservices.io
まず、Microserviceに関する著名サイトであるmicroservices.ioを見てみます。この中に分散トランザクションに関する記載があり、ここで以下のように述べています。
2PC is not an option
この記述以外に言及がないので、これだけだとちょっとわかりません。
RedHat
次にRedHat Developerの記事です。彼らは”Disadvantages of using 2pc”として以下の点を挙げています。
microservices have long delays with RPC calls, especially when integrating with external services such as a payment service. The lock could become a system performance bottleneck. Also, it is possible to have two transactions mutually lock each other (deadlock) when each transaction requests a lock on a resource the other requires.
ただ、これは欠点ととらえるべきか疑問です。前回の記事にも記載しましたが、ロックとはリソースへの並行書き込みでデータ破壊がおこることを防ぐ手段です。データ破壊を起こしてもパフォーマンスをとるのでしょうか?また、そのパフォーマンス・性能に関しても、RDBMSは行単位ロックが基本ですので、ロックの衝突が起こらない限り、パフォーマンスに影響がありませんし、ロックの衝突を極力減らすようなデータ設計も可能です。デッドロックもそれを起こさないようなデータ設計をすればよいのではないかと思います。したがって、以上の理由は2Phase Commitのデメリットとは言えないように思います。
Microsoft
次にMicrosoftです。この記事には以下のような記載が載っています。
Distributed transactions like the two-phase commit (2PC) protocol require all participants in a transaction to commit or roll back before the transaction can proceed. However some participant implementations, such as NoSQL databases and message brokering, don't support this model.
これはその通りです。Microserviceではサービスの特性に合ったリソースを選択できることがメリットとなっていますので、分散トランザクションを行うために2Phase Commit用のXAインタフェースを搭載したRDBMSしか選べず、NoSQLを選べないのであれば、たしかに2Phase Commitのデメリットとなります。
ただ、このデメリットは昨今Scalar DB の取り組みのような形で、徐々に解消されてきているように思います。
IBM
最後にIBMの主張を見てみましょう。彼らは、
Two-phase commit is a well known pattern in database systems. This pattern can also be used for microservices to implement distributed transactions.
として、わりと2Phase Commitに対して好意的です。しかし、
Even though 2PC can help provide transaction management in a distributed system, it also becomes the single point of failure as the onus of a transaction falls onto the coordinator.
とのことで、Coordinatorが単一障害点になるとのことです。以降は、この点についてもう少し深く見ていこうと思います。
Coordinatorの単一障害点
実は2Phase CommitはMicroserviceが流行する以前から、Coordinator/Transaction Managerの単一障害点が問題視されていました。特に、2Phase Commitにおける二相目、CommitフェーズでCoordinatorの障害が発生すると、DBはCommit指示を受け取ることができず待ち続けることになります。そうなると、トランザクションで更新した対象のデータ領域は排他が解かれることがなく、業務停滞につながります。また、このときDBによってはタイムアウトしてRollbackに倒れてしまう可能性があり、トランザクションに参加したほかのDBはCommitしているにも関わらずRollbackで決着するという、原子性の破壊につながります。この障害を一般的に”ヒューリスティックハザード”と呼びます。
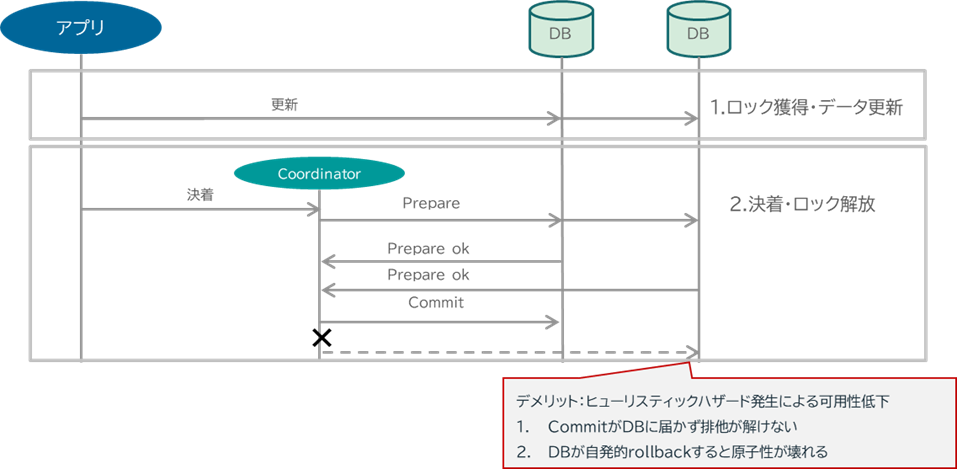
原子性が破壊されるとシステムのオペレータは大変です。トランザクション管理システムで担保できなかった原子性の破壊を修正するのですから、一旦システムを止めて、関係するDBすべての状態を遡り、原子性が壊れた地点から整合性の修正を行って、データを整えることになり、そもそもオペレータの作業が大変ですし、その時間システムが止まるわけですから、可用性・稼働率も低下します。2Phase CommitはCoordinatorの単一障害に極めて脆弱なのです。
Primary backupによる単一障害点の解消
このCoordinator単一障害をどうやって回避するかというと、障害時にHAにて系を切り替える”Primary-Backup”と呼ばれる形態が古くから採用されてきました。決着中のトランザクションの状態を記憶装置に永続化し、Coordinatorに障害が起こったとき、HAの司令塔となるフェンシング装置がそれを検知し、系切り替えを行います。切り替わった後のCoordinatorは記憶装置に永続化されたトランザクションの状態を復元し、故障したCoordinatorから引き継いでトランザクションの決着を行います。
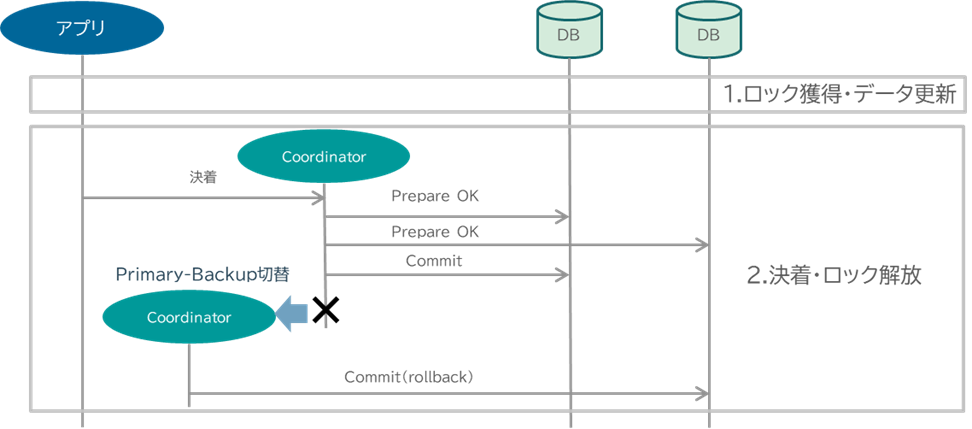
HAによる系切り替えは今の世界でも普通に行われていることですので、一見すると問題がないように思われます。しかし、じつはこのPrimary-Backupという形態が正しく動作するためには条件があるのです。
それは”故障通知が即座に正しくフェンシング装置に伝わること”です。裏を返せば故障通知がフェンシング装置に伝わらなかった場合、当然ながら系が切り替わらないことになり、その間トランザクションの決着が待たされるわけですから、その間、業務停滞も起こすしDBが自発的にrollbackしてしまうリスクに晒されます。
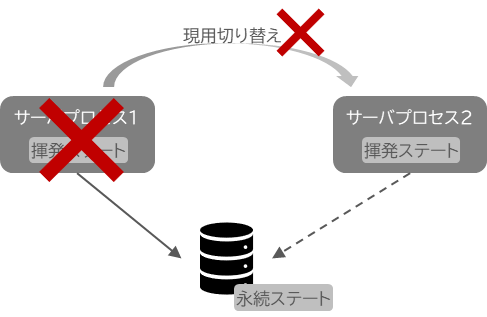
そして、”故障通知を正しく即座に”は簡単に見えてかなり難しい技術 になります。
まず、ネットワークが不安定になっていたら故障通知は常に遅延するリスクに晒されます。また、「故障」も様々バリエーションがある以上、「何をもって故障とするか」判断しにくい。ITシステムの運用として、故障のパトランプが光ったら、マシンの電源を落としてLANケーブルを引っこ抜くくらいすることもあるくらいです。
仮にこのように”確実に止める”という運用をせず、”一定時間の反応がないと故障とみなす”ような運用をした場合、場合によってはさらに最悪なことが発生します。それは、「スプリットブレインシンドローム」という事象です。具体的には、停止したと思われていたノードが実は生きているにも関わらず系切り替えを行ってしまって、現用系と待機系の両方が共用する記憶装置に更新をかける、その結果競合したデータが意図しない値に上書きされてデータ破壊が起こってしまう、という事象です。
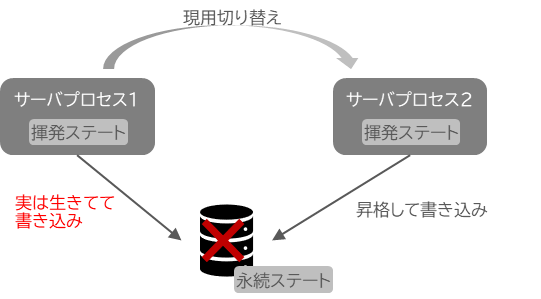
つまり、Primary-Backup形態は、それを構成するネットワークインフラストラクチャが素早く、且つ故障判断も正確にできるという前提で動作する形態であるといえます。これは、Primary-BackupがMicroservice、およびそれを構成する基盤と極めて相性が悪いことも同時に意味します。
- 第一に、現在Microserviceを構成するKubernetesを代表とされるソフトウェア群は、クラウドネイティブと言われるくらいですので、クラウド環境で動作することが多い。そして、クラウドですからIaaSとPaaSの層は切り離されており、トランザクション管理のようなPaaS/SaaS層の故障確定のためにIaaS層に手を入れる必要がでてくる可能性があります。それができるか定かではない上に、仮にできたとしてもハードウェアフェンシング装置の導入や、場合によっては、先述した電源断のようなオペレーションが必要になる可能性さえありこれがIaaSとPaaSを分離した利点を壊しかねない。
- 第二に、IaaSを隠蔽/抽象化した形で動作するKubernetesでMicroserviceを作るということは、動作するノードを固定化しないことに意義があります。だとすると、サービスは信頼性の低くなりかねないノードでも動作するリスクにさらされます。そしてMicroserviceは分散指向のアーキテクチャですから、サービス粒度は細かく、ノードを跨って分散していくことになり、分散していくとその分、通信の遅延が影響する可能性が高まっていきます。
故障モデルから考える2Phase CommitとPrimary-Backup
以上のように、2Phase Commitと、その単一障害点問題を克服するPrimary-Backup/HA構成はインフラストラクチャの故障に脆弱 です。これは、実は学術的にも言われています。
2Phase CommitはAll or nothingの更新を分散リソースで合意することを目的としていることから、分散合意の文脈でも語られることがありますが、この分散合意の学術分野では「故障モデル」というインフラストラクチャの信頼性段階レベルが存在します。
分散リソースを構成するノードが壊れた状況における復旧対処の厳しさを段階的に切り分けたモデルとなっており、段階は信頼性が高い順に以下のとおりとなっています。
| インフラの信頼性 | 故障モード | 説明 |
|---|---|---|
| 高 | Failure Nothing | 故障がない環境 |
| ↑ | Synchronous Fail-Stop | 故障が存在し、故障を即座に観測できる環境 |
| ↓ | Asynchronous Fail-Stop | 故障が存在し、故障の観測が遅延する環境 |
| ↓ | Crash-Recovery | 故障もするが有限時間内に回復する可能性もあり故障判定をしにくい環境 |
| 低 | Byzantine | Fail-StopやCrash-Recoveryを内包しつつ、誤情報を注入するノードまで存在する環境 |
以上で示した故障モデルでは、各段階において分散リソースが同一の状態に収束できる合意アルゴリズムを定義しています。とくに気にするべきポイントは、「信頼性の高い環境が前提で動く合意アルゴリズムは、信頼性が低い環境で動作するとは限らない」ということです。Synchronous Fail-Stopで動作する合意アルゴリズムがAsynchronous Fail-Stopで動作するとは限らない、ということですね。
さて、この故障モデルでは、2Phase CommitやPrimary-Backupはどのように位置づけられているのでしょうか。まず2Phase Commitですが、これはこの記事によるとFailure-Nothingに相当するようです。Coordinatorの単一障害を意識していない単純なアルゴリズムだからですね。なお、故障を想定していないという意味ではSagaパタンも同様で、こちらもFailure-Nothingな環境で動作するアルゴリズムと言えるでしょう。
次に、Primary-Backupはどうでしょうか。「分散システムについて語らせてくれ」においては、Primary-backupはSynchronous Fail-Stopに該当しています。これは、先述したとおり「故障通知が即座に正しくフェンシング装置に伝わること」がPrimary-Backupが正しく動作する条件だからです。なお、実際の運用で施されていた、障害ハードのオペレータによる電源断や、LANを抜いた後系切り替えを行うような運用は、故障モデルの観点から言えば、その目的が確実に故障していることを保証することであることからして「動作環境をSynchronous Fail-Stopに近似する」ことと同義です。
以上のように分類すると2Phase CommitやSaga、Primary-Backupの組み合わせは、故障モデルの見地からはAsynchronous Fail-Stop環境で動作しないことがわかります。
故障モデル的見地からみる現代ITシステム
それでは、これから先のITシステムを我々は故障モデルのどの段階まで下がることを想定してくみ上げるべきでしょうか?私は少なくとも”Asynchronous Fail-Stop”よりも信頼性は低くなることを想定すべきだと考えています。
- 第一に、これから先のITシステムがCloud/Microserviceが主流になると、ハードウェア資源とPaaS/アプリケーションレイヤが分離されていくことになります。これは、オンプレミスに比べてアプリが地理的に分散しやすいような状況であることを意味します。アプリが分散すれば、そのぶん通知の遅延が発生しやすくなるので故障通知も遅延し始めるでしょう。
- 第二に、昨今国内を騒がしてる、国内ITシステムの事故事例を見ると、そもそもオンプレミスだったとしてもSynchronous Fail-Stopを実現できておらずAsynchronous Fail-Stopだった可能性が高い。例えば、平成24年に起こった東証株式売買システムの障害においては、ハードウェア障害を契機とした予備系への切り替えに失敗していますし、そのほかにも”バックアップシステムへの切り替えに失敗した”という障害報告は昨今でも散見されます。このことから、たとえオンプレミスであったとしても”故障通知を即座に正しく”を実現するのは大変難しいのではないでしょうか。
以上の理由より、私はこれから先のITシステムはAsynchronous Fail-Stop以上に信頼性が低くなることを想定すべきと考えた次第です。
ただ、”今後のITシステムは常にAsynchronous Fail-Stopである”と述べたいわけではありません。
当たり前ですが、ITシステムのインフラストラクチャをそんな不安定な状態で運用を続けたいエンジニアはいないわけで、一時信頼性が下がったとしても、いずれ故障がないような信頼性の高い状態に復旧させるでしょう。
つまり、ITシステムは、ある段階でCrash-Recoveryのような信頼性の低い状態になりつつも、いずれはFailure-Nothingに落ち着くような、時間とともに信頼性が変動する世界で動作している と考えています。イメージとしては以下で(手書きでゴメンナサイ!) 、ある段階でAsynchronous Fail-Stop以上に信頼性が下がったとしても、ある期間で信頼性が回復し、Synchronous Fail-Stop/Failure Nothingのような状態に収束していく。
このように、時間経過で信頼性が高くなるシステムを分散合意の学術的には「Partial Synchrony/部分同期」と呼ばれています。
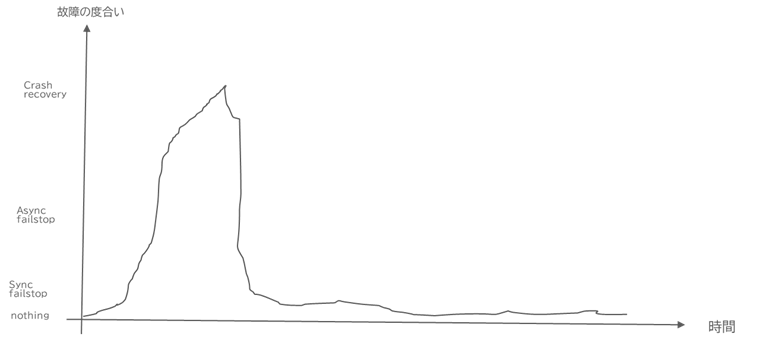
今後クラウドが主流となる分散型のITシステムにおいて、この部分同期的なインフラストラクチャでITシステムを構築することを念頭においてシステム設計を行う必要があります。
なお、仮に以下のように信頼性が低い状態で安定するようなITシステムにおいては、どんなに高尚な合意アルゴリズムを駆使しても合意に至れないケースが存在してしまいます。

これはFLP不可能性として、学術的にすでに言われていることですが、現実システムはおそらくこうはなっていないでしょう。
とはいえ、2Phase Commit/Saga/Primary-Backupを組み合わせて部分同期の世界で整合させようとすると、系がAsynchronous Fail-Stop以上に信頼性が低くなっている状態で故障したとき、合意に至れず、復旧もできないような深刻な事態が発生してしまう可能性があることは頭に入れるべきことだと思います。
部分同期の世界においては、システムの信頼性が低い状態で無理やり更新を決着させることは悪手と言えます。それは、上述のとおり、データ破壊/不整合が起こってしまうからです。
部分同期であれば、時間がたつとシステムの信頼性が回復することが予想されますから、信頼性が低い状態では合意を待ち、信頼性が高い状態に至ったときに合意に至るような形にすると、部分同期の世界でも合意に至ることは可能となるでしょう。実は、Crash Recoveryでも動作するといわれているPaxos/Raft/ViewStamped-Replicationといった合意アルゴリズムは、一時の信頼性が低下しても時間がたつと信頼性が安定する、部分同期的なITシステムを前提に、合意に至れるよう設計した合意アルゴリズムなのです。
余談:CAP Conjecture(通称CAP定理)の誤り
なお、ITシステムを部分同期(Partial Synchrony)に近似できるとすると、CAP Conjecture(通称CAP定理)は成立しません。
CAP Conjectureはノード間状態複製において、一貫性(Consistency)・可用性(Availability)・分断耐性(Partition-tolerance)がトリレンマ、つまり同時に三つを保証できないという予測(Conjecture) です。
この予測が有名になった結果、可用性(Availability)+分断耐性(Partition-tolerance)を重視する、結果整合性(Eventual Consistency)という曖昧な概念が誕生したわけですが、このCAPにおける分断耐性(Partition-tolerance)とは、故障モデルにおいてはFLP不可能性で合意ができない、大変信頼性の低いインフラストラクチャで安定した世界を前提とした予測になっています。
前提が違えば予測も違う結果になるのは当たり前で、現実世界が部分同期(Partial-Synchrony)であれば、Paxos/Raftのような合意アルゴリズムを駆使することで、一貫性(Consistency)・可用性(Availability)・分断耐性(Partition-tolerance)を全て同時に成立させることが可能となります。
以上が、CAP定理が成立しない簡単な根拠ですが、CAP定理・結果整合性は、その曖昧な概念より分散トランザクションに転用され、あらぬ誤解を与えているように思います。こちらについては、別の機会にまた論じ直してみようと思います。
まとめ
以上を纏めると、2Phase CommitはやはりMicroserviceに適用することが難しいといえるでしょう。その理由は、Microserviceのエンジニアが言うような、「ロックによるパフォーマンス低下」や「限定的な連携リソース」のせいではなく、2Phase Commitという合意形態が本質的に抱える問題である「故障への耐性のなさ」にあると言えます。これはSagaについても同様です。
それではどうすればいいでしょうか?Microserviceで2Phase CommitやSagaを検討している限り、この問題はどうすることもできません。
しかし、ITシステムを故障モデルの観点で検討し、部分同期的なアプローチで合意問題を解こうとしたとき、その解が見えてきます。ということで、以降の連載では部分同期モデルでAll or Nothingを合意するMicroservice Transaction手法を論じていこうと思います。
なお、このアプローチで実装したMicroservice Transactionシステムは、現在動作させるに至っているので、近々ここで言及していこうかと思っています。
他社商品,商標等の引用に関する表示
- Kubernetesは、The Linux Foundationの米国およびその他の国における登録商標または商標です。
- Red Hatは,米国およびその他の国でRed Hat, Inc. の登録商標もしくは商標です。
- Microsoftは,米国Microsoft Corporationの米国およびその他の国における登録商標または商標です。
- IBMは、世界の多くの国で登録されたInternational Business Machines Corporationの商標です。