はじめに
日立製作所 クラウドビジネス推進センタの西谷です。
今回は、前回の続きとなります。前回はACID特性をデータベースの状態と状態遷移に当てはめて解説しましたが、それだけでは見えてこない、機能と特性の関係に焦点を当てます。
1992年に書かれたYoav Raz氏の論文「The Principle of Commitment Ordering, or Guaranteeing Serializability in a Heterogeneous Environment of Multiple Autonomous Resource Mangers Using Atomic Commitment」には、「Atomic Commitment」と「Commitment ordering」が言及されており、この二つの仕組みがACID特性を実現する具体的な機能へと結び付ける重要な仕組みとなり、これらを理解することで分散トランザクションに必須となる機能群が明らかになります。
本シリーズの予定
- マイクロサービストランザクションの動向
- トランザクションの原則:ACID特性とCommitment Ordering前編(前回)
- トランザクションの原則:ACID特性とCommitment Ordering後編(今回)
- 合意理論からみる2Phase CommitとMicroserviceマイクロサービス
- 結果整合性は本当に整合するのか
ゴール
- Atomic Commitment を理解する。
- Commitment Ordering を理解する。
- ACID 特性とCommitment Orderingを実現する機能を理解する。
原子性(Atomicity)を実現するAtomic Commitment
前の記事で、分散したDBの原子性(Atomicity)に触れ、この特性は以下であると言及しました。
- 関連する全てのデータを新状態に移行させる。
- 一部のデータが新状態に移行できないのであれば、関連するすべてのDBのデータを新状態に移行させない。つまり、現在の状態を保持しておく。
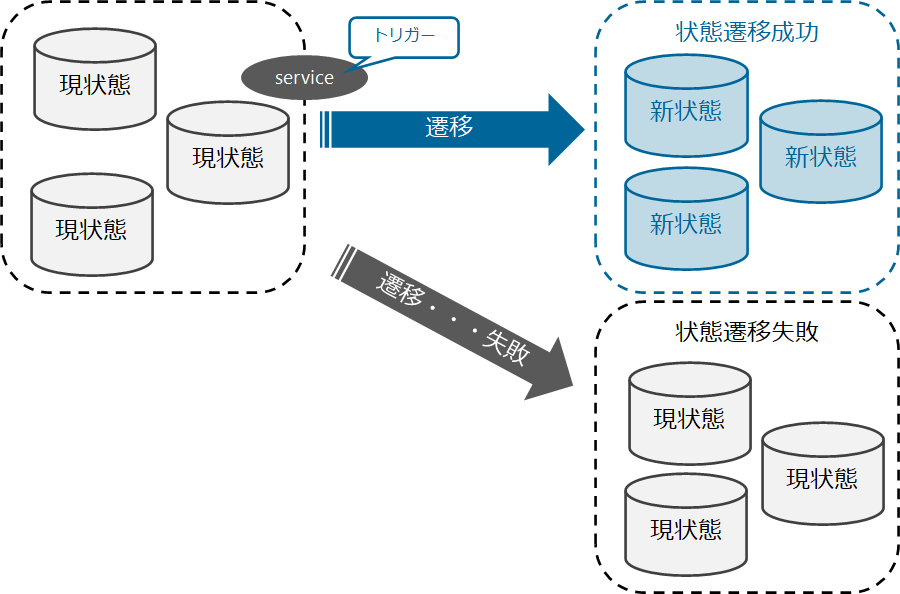
なぜ、このような特性が必須と言えるかというと、__分散トランザクションに参加するリソースが故障する可能性があるから__です。故障したリソースは状態遷移しませんから、ひとつでもリソースが故障していたら、参加リソース全ての更新を取り消さないと辻褄が合わなくなってしまうのです。
このような機能要件を達成するために、分散トランザクションにおいては、関連する全てのデータ変更を一つの処理として扱い、新状態か現状態か、次の状態遷移先を合意したうえで、状態遷移させるような仕組みを作ります。
具体的には、
- データベースは自分が新状態に移行できる段階になったとしても、他のデータベースが新状態に移行できることの確証が得られるまで待っておく。
- 状態遷移先を新状態に移行するか現状態に移行するか、合意してから状態遷移する。

このように複数のデータの変更を一つの処理として扱い、次の状態遷移先を合意しながら処理を進めることを、Atomic Commitment と呼びます。
定性的で分かりにくいと思いますので、Atomic Commitmentを実現している2Phase Commitの例で具体的に説明しましょう。
2Phase Commitを例としたAtomic Commitment の実現
2Phase Commitは、複数データベースへの更新が行われた後、Transaction Coordinator からデータベース群に対するprepare命令とCommit命令の二相の命令を送付することでデータベースを状態遷移させる、分散トランザクションでは広く一般的に知られている手法です。
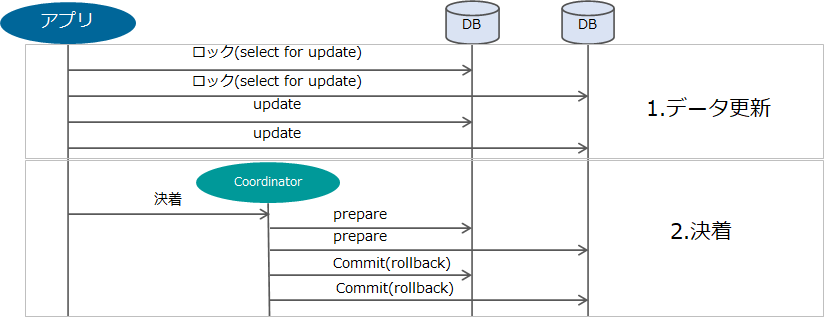
アプリからのSQL実行を通してデータベースを更新しますが、実はこの時点で状態遷移は完了していません。
それ以降、Transaction Coordinatorによる状態遷移の決着フェーズに入り、ここからAtomic Commitmentがはじまります。Transaction Coordinatorは、まずはprepare命令によって、データベース群に対して新状態へ移行できるか探針を打ちます。このとき、データベースが正常であれば、prepare OKとしてTransaction Coordinatorに探針結果が返ります。一方で何らかの異常が発生してデータベースが新状態に移行できない場合は、prepare NGとしてTransaction Coordinatorに探針結果が返ります。このようにしてTransaction Coordinatorには、トランザクション境界内にある全てのデータベース更新に関し、状態遷移の探針結果が集まります。そして、探針結果が全てprepare OKであれば、Commitとして全てのデータベースを新状態に移行させ、一つでもprepare NGがあればrollbackして現状態を維持させます。
このようにしてAtomic Commitmentで状態遷移を確定させていきます。
Atomic Commitment 実現に必須の機能
まず、リソースの状態遷移を途中で止めて、状態遷移先をリソース外部にアウトプットする必要があります。prepareに呼応するprepare ok/ng がそれです。これを「状態遷移先を出力する機能」としておきます。
そして、複数リソースから出力された状態遷移先を、一つの結果に合意する機能が必要です。この機能要件を達成する仕組みは、一般的に 分散合意 と呼ばれています。
纏めると、Atomic Commitmentには以下二点の機能が必要です。
- 状態遷移先(新状態への移行 or 現状態への移行)を出力する機能
- 状態遷移先を入力とした 分散合意機能
なお、分散合意は、上述した「故障」という概念とともに発展した学術分野です。そして、機器故障の程度によって合意可能なアルゴリズムが分類されている構造になりますが、ここはまた、別の記事で解説しようと思います。
隔離性(Isolation)を実現する排他制御
さて、前の記事で隔離性(Isolation)にふれ、状態遷移中の矛盾を外部から観測されないように、状態遷移中の状態を"隔離"するという特性だと説明しました。この特性は、状態遷移中に読み書きされているデータに対し、排他制御することで実現します。排他制御とは、「あるプロセスに資源を独占的に利用させている間、他のプロセスが利用できないようにする」ということです。
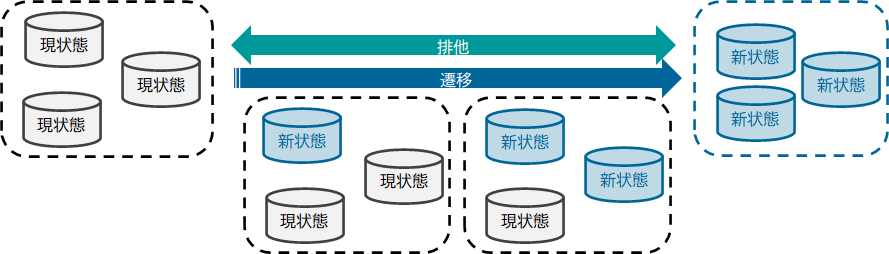
この排他という機能は、実は隔離以外に別の役割があります。
トランザクション多重実行に対する耐性
昨今のシステムは、秒間数千数万個のトランザクションを処理することを要求されますから、システムはトランザクションを並列多重で処理することが必要です。しかし、トランザクションの並列多重実行に対して何も手当をしないと、意図しない値でデータが上書きされデータが壊れてしまいます。
このような不具合の代表例が以下です。
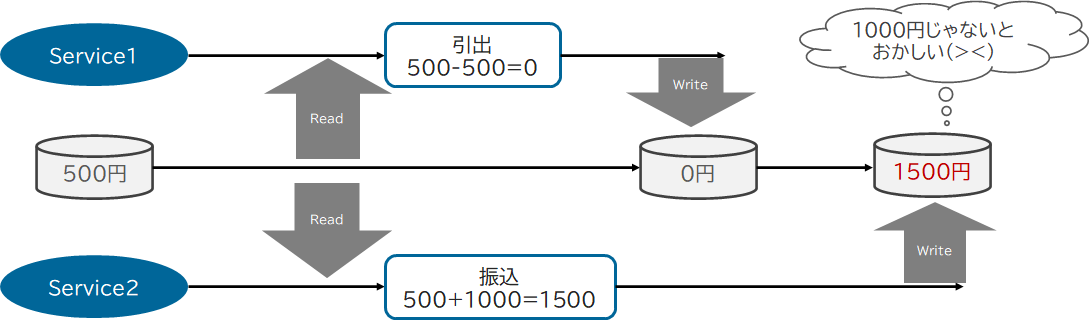
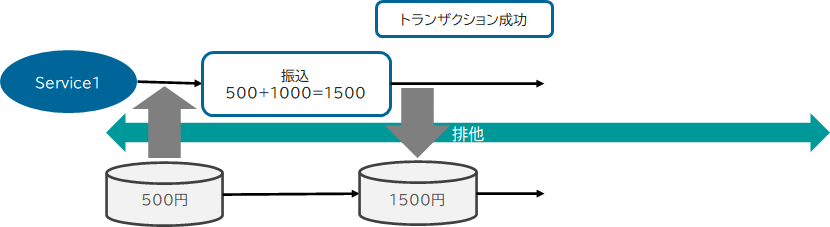
残高500円の口座から500円を引き出すトランザクションと1000円を振り込むトランザクションを同時に実行します。
この両方のトランザクションが実行された結果は、「1000円」となってほしいところですが、そうならないことがあります。
複数のトランザクションが同一時点でのリソースのデータを読んでしまうと、引き出しは500-500=0、振込は500+1000=1500として計算してしまいます。
そして、引き出しのトランザクション結果を、振込のトランザクションが上書きし、結果は「1500円」となってしまいデータが期待通りになりません。期待どおりに処理をさせるには、引き出しトランザクションにおける「500-500」の演算結果を振込トランザクションのインプットにする必要があり、別の言い方をすれば、__引き出しと振込を直列化させる__必要があります。
この直列化に排他制御が寄与します。
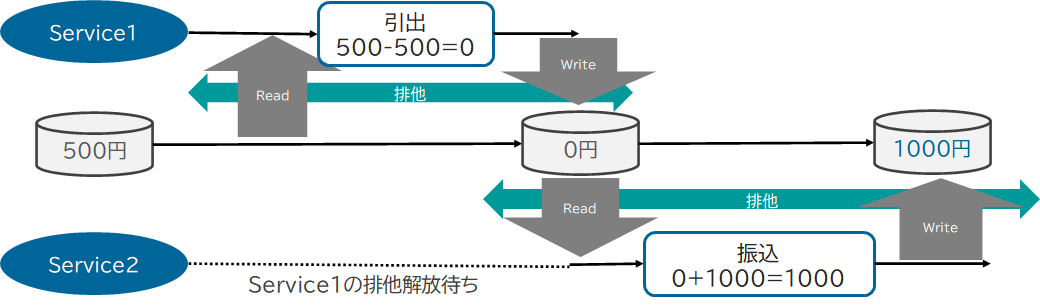
排他を取得すれば、引き出しトランザクションが排他を開放するまで、振込トランザクションは読み込みを待つことになります。そして、引き出しトランザクションの排他解放と同時に、振込トランザクションの読み込みが開始され、結果、引き出しと振込を直列に処理させることができるようになります。この特性を、「 直列化可能性(Serializability) 」と呼びます。
そして、トランザクションを並列多重実行した結果と、トランザクションを直列実行した結果が常に同一になることを「Commitment Ordering」と呼びます。
排他ロックとは、隔離性(Isolation)を達成するのと同時に、トランザクションを直列化し、並行多重実行で発生するデータ破壊を防ぐ効果があるのです。
排他区間の決め方
分散トランザクションでは、更新だけではなく巻き戻しも考慮して排他区間を設定する必要があります。更新と巻き戻しの間で排他が切れていると巻き戻しに失敗することがあるからです。
具体的な例として、「1000円振込」というローカルトランザクションは成功したものの、他ローカルトランザクションによって補償トランザクション-1000円を実行する、Sagaのケースで考えてみます。
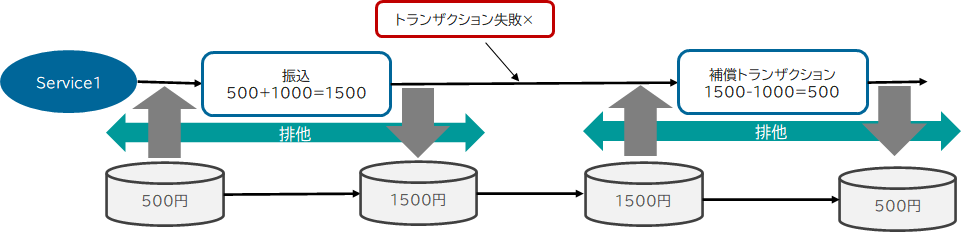
例えば、振込による更新と補償トランザクションによる更新、それぞれで排他をかけると仮定しましょう。このように排他区間を設定すると、振込による更新と補償トランザクションによる更新の間で、排他が切れることになります。
この排他の切れ目で、他のトランザクションが口座残高を全額引き落とした場合、補償トランザクションは残高0円の口座からマイナスすることになります。一般的に口座残高は負値を取れないため、ここで補償トランザクションが失敗してしまいます。
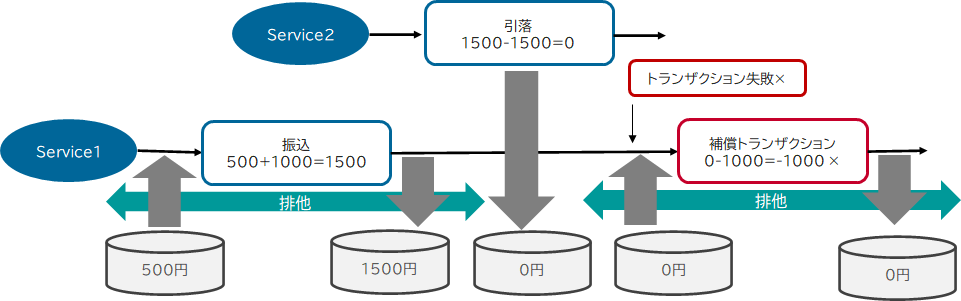
したがって振込の更新から、補償トランザクションの更新も含めて排他区間とする必要が出てきます。
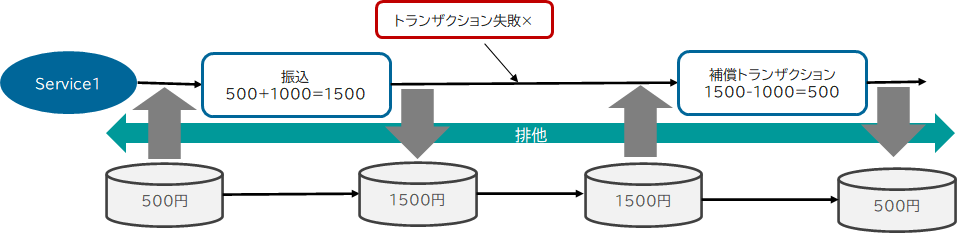
ただ、この状態でSagaが正常終了し、補償トランザクションが一切実行されなかった場合、今度は振込の更新が成功したあとでも排他を解けない、ということになり、サービスは排他を解く機会を失ってしまいます。
この排他を解くために、分散トランザクションに参加している他のトランザクションの成否を、排他をかけてるサービス・リソースに伝える必要でてきて、その結果、調停者・Coordinatorが必要になります。つまり、1「DB更新」2「他ローカルトランザクションの成否で排他を解く」という形になるわけです。
そして「他ローカルトランザクションの成否」とは、Atomic Commitmentで示した「状態遷移先」と同義です。したがって、1「状態遷移先を出力し」2「全てのリソースの遷移先が確定した後にリソースの排他を解く」という、2Phase Commit やTCCと同様の2相形態になるというわけです。リソースが状態遷移先を出力するという機能性は、適切な排他区間を設定するためにも必要な機能だったということになります。
なお、このようにトランザクションの失敗も含めて並列多重実行をできるようにする特性を 回復可能性(Recoverability) とよびます。
隔離性/直列化可能性/回復可能性に必須の機能
以上を踏まえると、直列化可能性と回復可能性をトランザクションシステムに搭載するには、データベースやその周辺に以下の機能を搭載することが必要になります。
- 排他ロック機能
- 巻き戻し機能
- 状態遷移先を出力する機能
ACID特性と機能の依存関係のまとめ
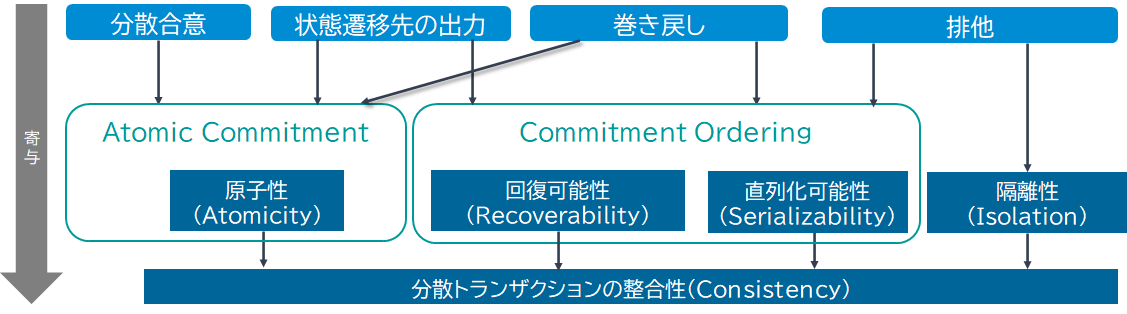
以上の理論より、Atomic CommitmentとCommitment Orderingから見えるACID特性を実現する機能を以下にまとめます。
-
目的:
- 整合性(Consistency)を保った状態を作る。逆に言えば、ノードの故障やトランザクション並列実行で起こる矛盾・データ破壊を防ぐ。
-
手段:
- 原子性/隔離性/直列化可能性/回復可能性を担保して状態遷移させる。
-
手段の実現1:リソース/リソースに近似できるAPI(TCC形態)に以下を搭載する
- 巻き戻し機能
- 排他ロック機能
- 状態遷移先を出力する機能
-
手段の実現2:分散トランザクションシステム全体に以下を搭載する
- 状態遷移先を入力とした__分散合意機能__
- 状態遷移先を入力とした__分散合意機能__
Principle of Commitment Ordering では、以上の「手段の実現1」「手段の実現2」両方が、オンラインでの分散トランザクションを実現する上で「必須」であり、且つ「十分」であると述べています。
Saga パターンとACID特性
以上の理解を踏まえて、再び1987年のSagas論文やmicroservice.ioの紹介ページを見ると、Sagaパターンは、上述の「巻き戻し機能」にのみ該当すると考えられます。したがって、microservice.io のChris Richardson氏が言及した「SagaはACIDのうちのIが欠落している」という発言は正確ではなくて、実際は「SagaはACIが欠けている」となり、また、ACID特性の裏にある直列化可能性も回復可能性も欠けているということになります。
したがって、Sagaパターンのみでシステムを作ってしまうと、以下が発現する可能性が高まるため注意が必要です。
- 原子性が保っていた ノード障害 への耐性がないため、障害時に不整合が発生する。
- 隔離性が保っていた参照への耐性がないため、 状態遷移中の矛盾が観測される し、矛盾が伝播する恐れがある。
- 直列化可能性や回復可能性が保っていたトランザクション多重実行への耐性がないため、 トランザクションの並行実行でデータ破壊が起こる 可能性がある。
さて、以上まで読んだ皆さまの中には、もしかしたら「ACIDはもう古くて、クラウド/マイクロサービスではCAP/BASEが基本ではないか」「理論はわかったけど、では具体的にどうすればいいのさ?」と思う方がいるかもしれません。そのように考えた皆さまに対して、近い将来、CAP/BASEと分散トランザクションの関わり や、いままで紹介した 理論的見地に基づくマイクロサービス分散トランザクションの具体案 について論じてみようかと思います。
余談:排他ロックが性能を低下させる?
マイクロサービスでトランザクションを扱うときに、「トランザクション処理で排他ロックを使うと性能が低下する」というような話をよく耳にしますが、この言説は極端です。
今までの説明のとおり、排他ロックは、整合性を担保しながらトランザクションの多重実行でスループットを向上させるために必要な仕組みです。たしかに単一データへの書き込みが重複し直列化されると、待ちによってレイテンシが増え、スループットは低下するでしょう。しかし、データベースで排他をかける基本は「行単位で排他をかける」ですので、トランザクションの直列化が起こるのは「行の更新が、時間的に重なったとき」に限ります。つまり、行単位排他の衝突率が性能に影響を与えるのであって、衝突率を下げるようなDB設計を行えば、一概に「性能が下がる」とは言えません。
まとめると、
- 単一データへの書き込みが重複し、直列化が起こるとレイテンシが増えスループットが低下する。
- 単一データへの書き込みが重複しなければ、レイテンシ増大の要因にはならない。
- 直列化によるレイテンシ増大を避けてデータに排他をかけない場合、レイテンシは短縮するがその分トランザクションの多重実行によってデータ破壊が起こる。
性能低下を気にして排他ロックをやめ、その結果、データが壊れてしまっては本末転倒というものです。