この記事について
Google Coral Edge TPU USB Acceleratorの動作を解析します。
前回は、データ入出力に注目して解析を行いました。
今回は、Operationやモデル構造がパフォーマンスに与える影響を調べます。
前回の解析結果で、入出力データ量がパフォーマンスに与える影響が大きいことが分かったので、その影響を受けないようなモデルを作って解析を行います。
また、解析用のモデルだけだとつまらないので、最後にはMobileNet, MobileNetV2, Mobilenet SSDのパフォーマンス測定を、いくつかの条件下で実施しました。
お願いと注意
基本的には実際に動かして確認した結果をベースに書いています。
が、考察や推測の部分は完全に僕の考えです。そのため、間違えや誤解を与えてしまうところがあるかもしれません。
その際には、ぜひご指摘いただけると嬉しいです。
結論
- 入出力データ量が少ない、特殊な実験用モデルの場合
- Convは速い。TPUはCPUの150~200倍高速
- ガチのモデルを作ったら、2.1TOPS出た (スペック値は4TOPS)
- Dense(Fully Connected)は遅い。TPUはCPUの1/2~1/5程度の速度。CONV(Edge TPU)と比べてると1/3500程度の速度
- これは、TPUが採用しているシストリックアレイの特性によるものだと思われる
- Edge TPUの処理が支配的な場合(これはかなり特殊な場合)は、CPU性能が速度に与える影響は小さい
- パラメータがOff-chipメモリに配置された場合
- USB3.0の場合、速度性能への影響は少ない (速度性能は5%程度低下)
- USB2.0の場合、速度低下の原因になる (速度性能は35%低下)
- Convは速い。TPUはCPUの150~200倍高速
- 入出力データの有る通常のモデルの場合(e.g. MobileNet)
- TPUはCPUの10~40倍高速
- USB2.0, USB3.0の違いは、速度に影響を与える。
- USB2だとUSB3に比べて、1/3~1/5程度の速度になる
- パラメータがon-chipに配置されたとしても遅い。入出力データ転送等が影響を受けるため?
- CPU性能が速度に与える影響も大きい
- 5Wモードだと10Wモードに比べて1/1.5程度の速度になる
※ CPUはJetson Nano(10W mode:CortexA57@1.43 GHz x 4 core, 5W mode:CortexA57@0.92 GHz x 2 core)です
※ 今回の実験結果に基づく結論です。別のケースでは当てはまらないかもしれません
ちなみに、TPUを使った同様の実験は、こちらの記事(https://qiita.com/koshian2/items/25a6341c035e8a260a01 )で既に行われています。
こちらは、ColabのTPUですが、結果はやはり同じで、Convだと超速い、だけどDense(MLP)だと遅い、のようです。
コードやログやデータ
TPUアーキテクチャ概要
まずはこちらの記事をご一読ください。TPUをやるなら一度は読んでおいた方が良いと思います。
こちらはCloud用のTPUなので、Edge TPUとは異なる可能性がある点にご注意ください。
日本語: https://cloudplatform-jp.googleblog.com/2017/05/an-in-depth-look-at-googles-first-tensor-processing-unit-tpu.html
英語: https://cloud.google.com/blog/products/gcp/an-in-depth-look-at-googles-first-tensor-processing-unit-tpu
以下、自分なりに理解した要約です。
- TPUは8-bit精度のCISC
- 行列の積和演算に特化している
- Matrix Multiplier Unitを持つ
- シストリックアレイを採用 (上記サイトのアニメーションが分かりやすいです)
- 積と加算のパイプラインが2次元的に行われるイメージ (パイプラインという表現が正しいか分からないですが)
- 計算の途中にメモリアクセスが発生しない
TPUはCISCだと思えば、Edge TPU compilerが、「モデルコンバータ」ではなく「コンパイラ」というのも納得です。
記事中で、「モデルパラメータ」という言葉を使っていますが、「命令データ」という方が正確かもしれません。Edge TPU用のモデルにコンパイルされた時点で、それはもはやモデルではなく、TPU用の命令コードのはずなので。
追記(2019/06/23)
上記記事はCloudで使用しているTPUの説明資料です。
Edge TPUでは異なる可能性がありますので、ご注意ください。
が、行列の積和演算を高速にするという目的は同じで、原理的にも「シストリックアレイに似た何か」を使っているのは間違いないと思われます。本記事ではこの「Cloud用TPUで使われているシストリックアレイ似た何か」がEdge TPUにも使われているとして、解析・考察を行います。記事内での記載は単に「シストリックアレイ」とします。
環境
前回と同じ
https://qiita.com/iwatake2222/items/922f02893355b30dab2e#%E7%92%B0%E5%A2%83
Conv層のパフォーマンス解析
実験用モデルの作成
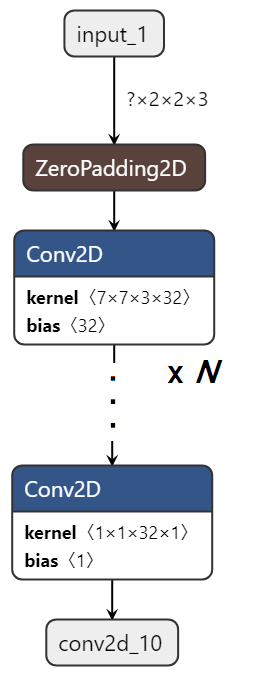
Conv層だけから成るモデルを作ります。
入出力が大きいと別の要因を受けるので、モデル内部でパディングして入力データを生成します。また、出力段でStride幅を大きくしたConv層を挟むことで、出力データを小さくしています。
- モデル構造
- 内部サイズ: 128 x 128 x 3
- カーネルサイズ: 7 x 7 x 32
- レイヤ数: 10, 50, 100, 150, 200, 250, 300
Edge TPU用に変換
前回と同じ手順で変換します。 https://qiita.com/iwatake2222/items/922f02893355b30dab2e#edge-tpu%E7%94%A8%E3%81%AB%E5%A4%89%E6%8F%9B
実行
前回と同じコードで、Jetson Nano上で推論実行します。
https://qiita.com/iwatake2222/items/922f02893355b30dab2e#%E5%AE%9F%E8%A1%8C
結果
| Layer Num | Model Size [MiB] | 処理時間 [msec] | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10W | 5W | ||||||||||
| tflite | edgetpu | On-chip memory available | On-chip memory used | Off-chip memory used | CPU | EdgeTPU | EdgeTPU (USB2.0) | CPU | EdgeTPU | EdgeTPU (USB2.0) | |
| 10 | 0.442 | 0.493 | 5.010 | 0.876 | 0.000 | 1200.5 | 7.8 | 8.5 | 1725.5 | 11.8 | 12.0 |
| 25 | 1.170 | 1.240 | 5.010 | 2.320 | 0.000 | 3165.0 | 20.1 | 21.4 | 4632.2 | 24.9 | 24.6 |
| 50 | 2.379 | 2.481 | 5.010 | 4.710 | 0.000 | 6448.1 | 40.7 | 43.6 | 9244.3 | 44.8 | 46.7 |
| 75 | 3.590 | 3.730 | 5.010 | 5.000 | 1.060 | 9688.7 | 61.6 | 76.8 | 14182.0 | 65.8 | 81.3 |
| 100 | 4.800 | 4.981 | 5.010 | 5.000 | 2.250 | 12991.6 | 82.7 | 113.1 | 18605.9 | 87.5 | 117.2 |
| 150 | 7.221 | 7.478 | 5.010 | 5.000 | 4.650 | 19529.6 | 124.4 | 184.3 | 28021.1 | 129.7 | 189.0 |
| 200 | 9.641 | 9.978 | 5.010 | 5.000 | 7.050 | 26206.6 | 166.0 | 255.4 | 37489.8 | 171.0 | 260.0 |
| 250 | 12.061 | 12.474 | 5.010 | 5.000 | 9.450 | 32536.1 | 207.6 | 326.4 | 46739.1 | 212.8 | 331.1 |
| 300 | 14.478 | 14.974 | 5.010 | 5.000 | 11.850 | 39274.7 | 249.1 | 397.0 | 56159.7 | 260.6 | 407.8 |
結果の素データは上記の通りです。
Model Size
Model Sizeのtfliteは、Edge TPU用にコンパイル前のモデルサイズ。edgetpuは、Edge TPU用にコンパイル後のモデルサイズです。
どちらも、レイヤ数に比例して増加します。
On-chip memory availableは、Edge TPU Compile時に出力される「On-chip memory available for caching model parameters」です。8MByte SRAMの内、パラメータキャッシュ用に使用可能な容量だと思われます。
On-chip memory usedは、Edge TPU Compile時に出力される「On-chip memory used for caching model parameters」です。実際にパラメータキャッシュ用に割り当てられる容量だと思われます。
Off-chip memory usedは、Edge TPU Compile時に出力される「Off-chip memory used for streaming uncached model parameters」です。キャッシュには割り当てられず、実行時にHOSTからストリーム転送されるモデルパラメータの容量だと思われます。
On-chip memoryは8MByteあるはずですが、使用可能なのは5MByteのようです。内部のデータキャッシュ用などに使われる分が引かれているのだと思われます。
それでも、使用可能な5MByteはフルに使うようにコンパイルしてくれています。
また、「レイヤ数が50まではoff-chipは未使用でon-chip memoryだけでやりくりできている、レイヤ数が50以降はoff-chip memoryが使用されている」という点に着目して、以下をお読みください。
速度 vs レイヤ数
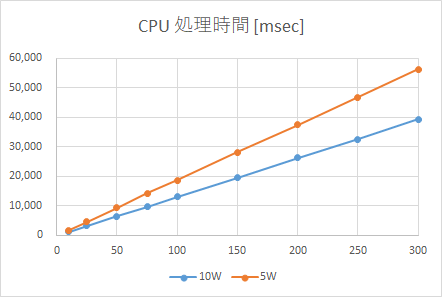
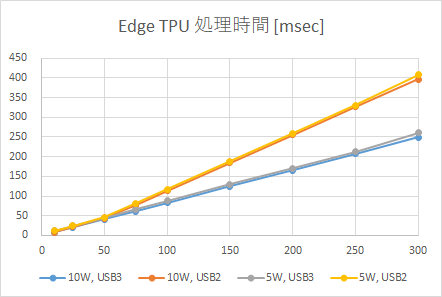
レイヤ数と処理時間のグラフを上に示します。
CPUに関しては、レイヤ数と処理時間は綺麗に比例します。レイヤ数と演算量は比例関係になるので、これは当然の結果です。
Edge TPU(10W, USB3)(青)も同様に、綺麗に比例して増加します。これは意外な結果でした。当初の予想では、off-chip memoryが使われると、そこで処理時間が一気に増加すると思っていました。具体的には、レイヤ数50以降で一気に処理時間が増加すると思っていましたが、実際にはそうはなりませんでした。その後、レイヤ数が増加しても、処理時間は比例して増加しました。恐らく、以下が要因だと思われます(予想)。
・USB3.0ではパラメータ転送は十分早い
・パラメータ転送は演算と同時実行される(?)ので、全体としてパフォーマンスに影響を与えない。
Edge TPU(5W, USB3)(灰色)は、Edge TPU(10W, USB3)(青)に比べると少し遅くなっています。が、ほぼ同じと言えるレベルだと思います。今回、10Wモード=4コアx1.43GHz、5Wモード=2コアx0.92GHzでした。これが、シングルコアになったりするともっと顕著に影響が出てくるかもしれません。(A57x2コアでも、かなりのハイスペックですからね。。。)
一方、Edge TPU(10W, USB2)(オレンジ)では予想通り面白い結果が得られました。レイヤ数50を境に、処理時間の傾きが増加しています。レイヤ数が50以降のモデルでは、off-chipに配置されるパラメータが出てきます。これがstream転送されるため、USB2ではその影響が見えてしまったのだと考えられます。ただ、処理時間が+αされて一気に増加されると思ったのですが、あくまで線形増加で傾きが変わるといった変化です。
パラメータデータの配置場所が速度性能に影響を与えるという裏付けが取れました。
(もともとはこの結果を見たかっただけなのですが、ずいぶんと大掛かりな解析になってしまいました。)
速度(対CPU比)
| Layer Num | 処理速度 [倍] | |||
|---|---|---|---|---|
| 10W | 5W | |||
| EdgeTPU | EdgeTPU (USB2.0) | EdgeTPU | EdgeTPU (USB2.0) | |
| 10 | 154 | 141 | 146 | 144 |
| 25 | 157 | 148 | 186 | 188 |
| 50 | 158 | 148 | 207 | 198 |
| 75 | 157 | 126 | 215 | 175 |
| 100 | 157 | 115 | 213 | 159 |
| 150 | 157 | 106 | 216 | 148 |
| 200 | 158 | 103 | 219 | 144 |
| 250 | 157 | 100 | 220 | 141 |
| 300 | 158 | 99 | 216 | 138 |
次に、CPUに比べてEdge TPUだと処理速度が何倍速くなったかを見ます。
Edge TPU(10W, USB3)だと約150倍、Edge TPU(5W, USB3)だと約200倍、CPUより高速化されています。5Wモードのレイヤ数=10の結果が少し低いですが、これはメインとなるconv演算の数が少ないため、制御関係の処理時間の影響が大きくなっていることが理由だと思われます。
USB2の場合は、10Wでも5Wでも、レイヤ数が増加するにしたがって処理速度が遅くなっています。これは、前述の通り、USB2ではパラメータ転送の影響を受けるためだと考えられます。
速度(TOPS)
| Layer Num | TOPS | |||||
|---|---|---|---|---|---|---|
| 10W | 5W | |||||
| CPU | EdgeTPU | EdgeTPU (USB2.0) | CPU | EdgeTPU | EdgeTPU (USB2.0) | |
| 10 | 0.014 | 2.103 | 1.925 | 0.010 | 1.392 | 1.373 |
| 25 | 0.013 | 2.042 | 1.921 | 0.009 | 1.651 | 1.668 |
| 50 | 0.013 | 2.018 | 1.884 | 0.009 | 1.836 | 1.760 |
| 75 | 0.013 | 2.002 | 1.605 | 0.009 | 1.873 | 1.518 |
| 100 | 0.013 | 1.989 | 1.454 | 0.009 | 1.879 | 1.402 |
| 150 | 0.013 | 1.982 | 1.338 | 0.009 | 1.902 | 1.305 |
| 200 | 0.013 | 1.981 | 1.288 | 0.009 | 1.923 | 1.265 |
| 250 | 0.013 | 1.980 | 1.259 | 0.009 | 1.932 | 1.242 |
| 300 | 0.013 | 1.980 | 1.243 | 0.009 | 1.893 | 1.210 |
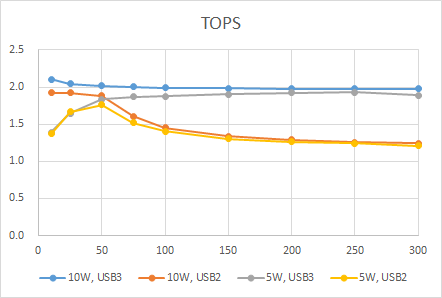
せっかくなので、処理速度性能の指標である、TOPS(Tera Operations Per Second)を計算してみます。
今回使用したフィルタでは、1レイヤ当たりの演算回数は、128x128x7x7x32x32x2回となります。(最後の2は乗算+加算です)。これが、レイヤ数だけ処理されます。
これを見ると、最大で2.1TOPS出せています。スペック値は4TOPSなので、まずまずの結果だと思います。今回は実験のために敢えて大きめのカーネルサイズにしましたが、もう少し小さいフィルタにすればもっとTOPSは上がるかもしれません。
Edge TPU(10W, USB3)の結果(青)を見ると、USB3でもパラメータ転送の影響を多少受けているように見えます。レイヤ数10とレイヤ数300を比べると5%程度遅くなっています。が、ほぼ影響はないと言っていいと思います。
Edge TPU(5W, USB3)の結果(灰色)を見ると、最初は性能が低いのですが、レイヤ数の増加に従って、徐々に速くなっています。これは、レイヤ数が小さいときはEdge TPU内部での演算よりも、CPUが行う制御関係の影響が大きいためだと思います。レイヤ数が増加して、TPU内部での演算の占める割合が増加するにしたがって、10Wモードと同等の性能になりました。
Edge TPU(5W, USB3)の結果(赤)を見ると、レイヤ数50までは、性能が高いのですが、その後速度が低下していきます。これは、先ほど述べたように、レイヤ数増加(パラメータがoff-chipに配置)されるにしたがって、データ転送の影響を受けるためだと考えられます。レイヤ数10とレイヤ数300を比べると35%程度遅くなっています。
Edge TPU(5W, USB2)の結果(黄色)は少し複雑ですが、これまで確認した事象を組み合わせれば説明できます。レイヤ数10程度ではCPUの絡む制御関係がネックとなり性能が出ません。レイヤ数が増加していくとEdge TPU側での処理が支配的となり速度は徐々に上がります。が、レイヤ数が50を過ぎると、今度はパラメータ転送(on USB2)がネックとなり、再び速度が低下します。
通信解析
285 8.259841 host → 2.4.1 USB 72 URB_BULK out
286 8.259902 2.4.1 → host USB 64 URB_BULK out
287 8.259950 host → 2.4.1 USB 61504 URB_BULK out
288 8.260334 2.4.1 → host USB 64 URB_BULK out
289 8.260358 host → 2.4.1 USB 72 URB_BULK out
290 8.260382 host → 2.4.1 USB 80 URB_BULK out
291 8.260415 2.4.1 → host USB 64 URB_BULK out
292 8.260461 2.4.1 → host USB 64 URB_BULK out
293 8.300544 2.4.1 → host USB 72 URB_BULK in
294 8.300564 2.4.2 → host USB 80 URB_BULK in
295 8.300609 host → 2.4.2 USB 64 URB_BULK in
296 8.300643 host → 2.4.1 USB 64 URB_BULK in
# URB length [bytes], Data length [bytes], Leftover Capture Data
373 15.743047 host → 2.4.1 USB 72 URB_BULK out # 8,8,80fa030000000000
374 15.743121 2.4.1 → host USB 64 URB_BULK out # 8,0,
375 15.743188 host → 2.4.1 USB 61504 URB_BULK out # 260736,61440,800f0098fe0000000000000000000000000900009f010000
376 15.743403 host → 2.4.1 USB 72 URB_BULK out # 8,8,
377 15.743424 host → 2.4.1 USB 80 URB_BULK out # 16 ,16,80808080808080808080808000000000
378 15.743441 host → 2.4.1 USB 72 URB_BULK out # 8,8,00df3b0002000000
379 15.743833 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,000000000000000000000000000000000000000000000000
380 15.744073 2.4.1 → host USB 64 URB_BULK out # 260736,0,
381 15.744577 2.4.1 → host USB 64 URB_BULK out # 8,0,
382 15.744585 2.4.1 → host USB 64 URB_BULK out # 16,0,
383 15.744593 2.4.1 → host USB 64 URB_BULK out # 8,0,
384 15.745013 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,e71e61a841678c1e9970758290c5feab135795f48742cf41
385 15.746098 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,29968bdfac700de091b106f582f0563f38c58fd73819bc26
386 15.802554 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
387 15.802940 host → 2.4.1 USB 61504 URB_BULK out # 777984,61440,c504abe33d36d2d74c4d280a9e0a3b4c7d61c91205cd328a
388 15.819983 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
389 15.820096 host → 2.4.1 USB 72 URB_BULK out # 8,8,2000040000000000
390 15.820216 host → 2.4.1 USB 61504 URB_BULK out # 262176,61440,800f000000010000000000000000000080f6ff1f8a000000
391 15.837408 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
392 15.837501 host → 2.4.1 USB 72 URB_BULK out # 8,8,00b7600002000000
393 15.837888 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,000000000000000000000000000000000000000000000000
394 15.850631 2.4.1 → host USB 64 URB_BULK out # 777984,0,
395 15.850650 2.4.1 → host USB 64 URB_BULK out # 8,0,
396 15.851107 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,d1ada8fe1935ece81f307f777899bfb24066590ada29cd32
397 15.851249 2.4.1 → host USB 64 URB_BULK out # 262176,0,
398 15.851840 2.4.1 → host USB 64 URB_BULK out # 8,0,
399 15.852279 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,63c67b4b1f817556884b265ace3c9573ae76ddeb4a4d07a1
400 15.867370 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
401 15.867835 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,037e551b6b3f5c775fa236268b0b7484228be68fb17a50fb
402 15.884789 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
403 15.885261 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,da5e29713109729592e6e63077cd9331090a0b0ffc9b6eab
404 15.902221 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
405 15.902730 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,787bc5b3f1f8f62851da861e0613c9edf5d490f19c5ef049
406 15.919641 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
407 15.919761 host → 2.4.1 USB 46912 URB_BULK out # 46848,46848,0f56e7ca12953cb45b0a1eecde77f9fcbdeac055f25dbd2f
408 15.937085 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
409 15.937180 host → 2.4.1 USB 72 URB_BULK out # 8,8,9060010000000000
410 15.937233 host → 2.4.1 USB 61504 URB_BULK out # 90256,61440,800f001c58000000000000000000000080f6ff1f08010000
411 15.954509 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
412 15.954610 host → 2.4.1 USB 72 URB_BULK out # 8,8,
413 15.955003 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,000000000000000000000000000000000000000000000000
414 15.955306 2.4.1 → host USB 64 URB_BULK out # 46848,0,
415 15.955732 2.4.1 → host USB 64 URB_BULK out # 8,0,
416 15.955742 2.4.1 → host USB 64 URB_BULK out # 90256,0,
417 15.955750 2.4.1 → host USB 64 URB_BULK out # 8,0,
418 15.956194 host → 2.4.1 USB 61504 URB_BULK out # 1048576,61440,81f27bdddafc74131fbb7da073a0e09f33a7a41f3e07f586
419 15.956948 host → 2.4.1 USB 61504 URB_BULK out # 65920,61440,b87351d2f862e5abf7f340e2ceabe792e2669637905952e6
420 15.972055 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
421 15.989481 2.4.1 → host USB 64 URB_BULK out # 1048576,0,
422 15.991049 2.4.1 → host USB 64 URB_BULK out # 65920,0,
423 15.991865 2.4.1 → host USB 72 URB_BULK in # 8,8,0000000000000000
424 15.991881 2.4.2 → host USB 80 URB_BULK in # 16,16,00000000000000000000000004000000
425 15.991936 host → 2.4.2 USB 64 URB_BULK in # 16,0,
426 15.991958 host → 2.4.1 USB 64 URB_BULK in # 1024,0,
上記が、レイヤ数50のモデルと、レイヤ数300のモデルを推論実行した時のUSBキャプチャログです。
レイヤ数50の場合には、パラメータ転送は最初の1回しか行われていません。(61504バイトの転送)
一方、レイヤ数が300の場合には、処理中も随時転送が行われています。
レイヤ数300のログには、右側に、URB length [bytes], Data length [bytes], Leftover Capture Data を記載しました。
800f00 から始まるデータ列がパラメータと思われます。途中で、それ以外の大きな(1MByteの)データ転送がありますが、途中のパラメータということでしょうか? また、最初の数十バイトしか見れないのですが、オール0のデータもあるようです。これはただのパディングかも。
377フレーム目が入力データです。(All128のデータ = 0x80808080)
実際に転送されるデータ量が、URB lengthなのか、Data lengthなのかが分からないので、両方載せておきました。普通に考えたらData lengthが転送されるデータ量だと思うのですがで、前回実験した結果だとURB lengthのようにも見えました。
あと、処理の終わりは424フレームです。毎回必ず、00000000000000000000000004000000 というデータがEdge TPUから送られて終了しているようです。
USB強い人がさらなる解析をしてくれることを期待して、余計な情報を書いてしまいましたが、ここで言いたいのは、「パラメータ数が増えると、Edge TPUで処理中もデータ転送(host->Edge TPU)が行われる」ということです。
そして、USB2だと処理時間に大きな影響を与えます。
Conv層まとめ
- Conv層だけなら、Edge TPUは超速くなる (スペック値4TOPSに対して、2.1TOPS達成)
- USB3であれば、モデルサイズが大きくなって、パラメータがoff-chipに配置されても、速度への影響は少ない (5%程度速度低下)
- USB2だと、モデルサイズが大きくなるに従って、速度への影響が大きくなる (レイヤ数が300の場合、35%程度速度低下)
- Edge TPU側での処理が多い場合(数十msec)、4コア->2コア程度の違いだと、CPUが速度性能に与える影響は少ない
あくまで、Conv演算だけに注目した結論です。
今回は入出力データ量がほぼ0です。前回の実験結果で、入出力データがある場合にはCPUスペックが処理速度に影響を与えることが分かっています。
Dense(Fully Connected)層のパフォーマンス解析
実験用モデルの作成
Dense層だけから成るモデルを作ります。
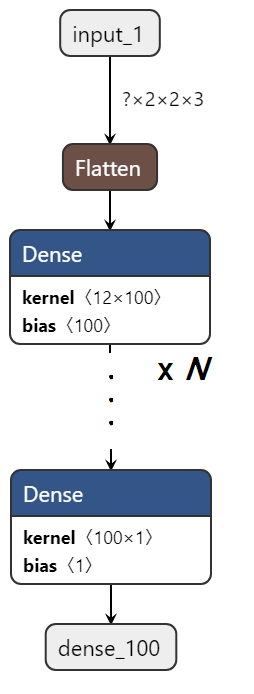
入出力が大きいと別の要因を受けるので、モデル内部でパディングして入力データを生成します。また、出力段でUnit数1のDenseを入れることで、出力データを小さくしています。
- モデル構造
- Denseの出力次元(Units): 100
- レイヤ数: 100, 200, 300, ..., 900
結果
| Layer Num | Model Size [MiB] | 処理時間 [msec] | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10W | 5W | ||||||||||
| tflite | edgetpu | On-chip memory available | On-chip memory used | Off-chip memory used | CPU | EdgeTPU | EdgeTPU (USB2.0) | CPU | EdgeTPU | EdgeTPU (USB2.0) | |
| 100 | 1.027 | 1.458 | 8.020 | 0.993 | 0.268 | 0.8 | 1.4 | 12.2 | 1.1 | 2.2 | 14.6 |
| 200 | 2.063 | 2.911 | 8.020 | 0.993 | 1.540 | 1.8 | 5.8 | 53.9 | 2.3 | 7.1 | 59.5 |
| 300 | 3.095 | 4.368 | 8.020 | 0.993 | 2.810 | 2.4 | 9.4 | 95.3 | 3.1 | 10.1 | 100.5 |
| 400 | 4.131 | 5.825 | 8.020 | 0.993 | 4.080 | 2.9 | 13.1 | 136.8 | 4.0 | 14.1 | 142.5 |
| 500 | 5.162 | 7.278 | 8.020 | 0.993 | 5.350 | 3.6 | 16.7 | 178.3 | 4.9 | 17.7 | 184.2 |
| 600 | 6.196 | 8.735 | 8.020 | 0.993 | 6.620 | 4.3 | 20.4 | 219.7 | 6.0 | 21.2 | 225.5 |
| 700 | 7.229 | 10.192 | 8.020 | 0.993 | 7.890 | 5.0 | 24.0 | 261.1 | 6.9 | 24.9 | 266.3 |
| 800 | 8.256 | 11.646 | 8.020 | 0.993 | 9.150 | 5.7 | 27.6 | 302.5 | 7.9 | 28.4 | 308.2 |
| 900 | 9.284 | 13.103 | 8.020 | 0.993 | 10.420 | 6.4 | 31.3 | 344.0 | 8.9 | 32.4 | 350.0 |
結果の素データは上記の通りです。
Model Size
On-chip memoryは8MByteに対して、8MByteフルで使用可能です。
が、実際には0.993MByteしか使ってくれていません。そのため、ほとんどのパラメータがoff-chipに配置されてしまっています。
速度 vs レイヤ数
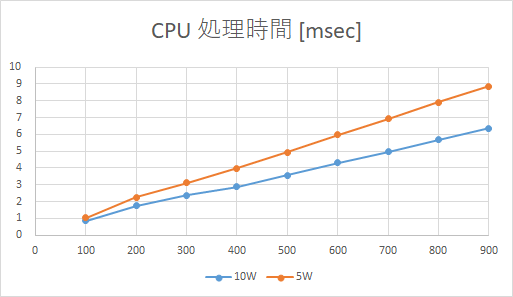
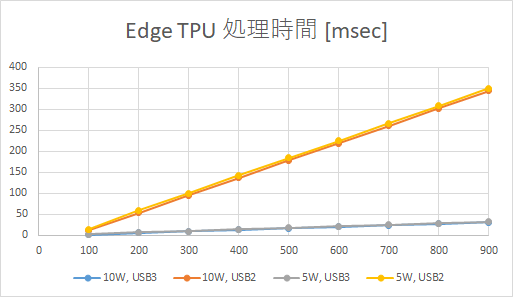
レイヤ数と処理時間のグラフを上に示します。
CPUに関しては、レイヤ数と処理時間は綺麗に比例します。今回も、レイヤ数と演算量は比例関係になるので、これは当然の結果です。
綺麗な直線ではないのですが、これは処理時間が小さいので、測定誤差の影響が入ってしまったのだと思います。
Edge TPUに関しては、今回は常にパラメータがoff-chipに配置されているため、測定した範囲ではレイヤ数と演算量は比例関係になりました。
今回、レイヤ数をいきなり100から初めてしまったのですが、もう少し小さい所から始めたら、先ほどのConvと同様のグラフになったかもしれません。
速度(対CPU比)
| Layer Num | 高速化率 (vs CPU) | |||
|---|---|---|---|---|
| 10W | 5W | |||
| EdgeTPU | EdgeTPU (USB2.0) | EdgeTPU | EdgeTPU (USB2.0) | |
| 100 | 0.590 | 0.069 | 0.478 | 0.072 |
| 200 | 0.302 | 0.033 | 0.317 | 0.038 |
| 300 | 0.253 | 0.025 | 0.311 | 0.031 |
| 400 | 0.221 | 0.021 | 0.284 | 0.028 |
| 500 | 0.212 | 0.020 | 0.280 | 0.027 |
| 600 | 0.211 | 0.020 | 0.282 | 0.027 |
| 700 | 0.207 | 0.019 | 0.278 | 0.026 |
| 800 | 0.205 | 0.019 | 0.278 | 0.026 |
| 900 | 0.204 | 0.019 | 0.274 | 0.025 |
次に、CPUとEdge TPUの速度性能を比較します。
Edge TPU(USB3)だと、CPUに比べて、速度性能が1/2~1/5程度になってしまいます。
傾向としては、先ほどのConvと同じです。
レイヤ数が増えてoff-chipに配置されるパラメータ転送量が大きくなるほど、Edge TPUだと遅くなります。また、USB2だと転送に時間がかかるためかさらに遅くなります。
速度(GOPS)
| Layer Num | GOPS | |||||
|---|---|---|---|---|---|---|
| 10W | 5W | |||||
| CPU | EdgeTPU | EdgeTPU (USB2.0) | CPU | EdgeTPU | EdgeTPU (USB2.0) | |
| 100 | 2.353 | 1.389 | 0.164 | 1.904 | 0.911 | 0.137 |
| 200 | 2.277 | 0.686 | 0.074 | 1.774 | 0.563 | 0.067 |
| 300 | 2.517 | 0.637 | 0.063 | 1.920 | 0.597 | 0.060 |
| 400 | 2.771 | 0.612 | 0.058 | 2.003 | 0.569 | 0.056 |
| 500 | 2.815 | 0.598 | 0.056 | 2.026 | 0.566 | 0.054 |
| 600 | 2.791 | 0.589 | 0.055 | 2.006 | 0.566 | 0.053 |
| 700 | 2.818 | 0.583 | 0.054 | 2.021 | 0.563 | 0.053 |
| 800 | 2.821 | 0.579 | 0.053 | 2.023 | 0.563 | 0.052 |
| 900 | 2.826 | 0.575 | 0.052 | 2.033 | 0.556 | 0.051 |
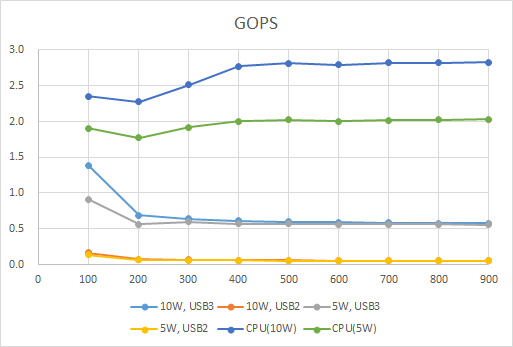
速度性能を算出しまいた。遅いので、単位はGigaであるGOPSです。
まずはCPUに関して。
ちょっと形がいびつですね。綺麗な直線になるのが理想なのですが。が、今回の本筋ではないので、ひとまず気にしないことにします。
10Wのとき、CPUは約2.5GOPSです。先ほどのCONVだと0.013TOP=13GOPSなので、1/5程度の速度性能です。
次にEdge TPUです。
レイヤ数100と200で差が出てしまっていますが、それ以降はほぼ同じです。
先ほどのConvでは2.1TOP程度出たのに対して、こっちは0.6GOPS程度。1/3500程度の速度性能です。
考察: なぜDENSEは遅いのか (CPU実行時)
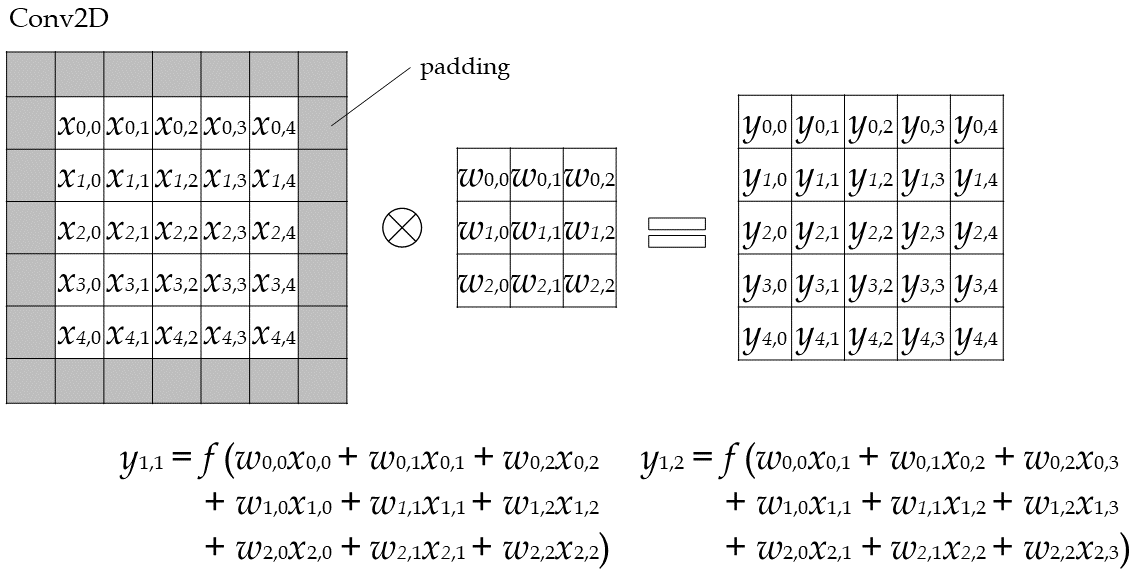
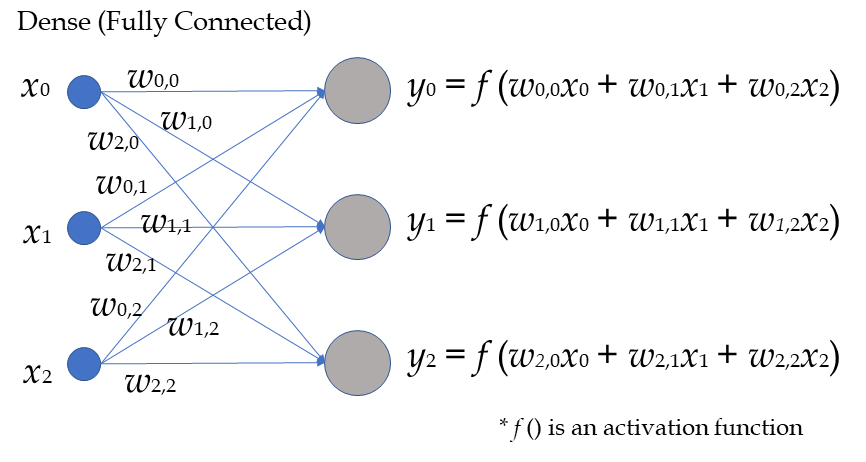
改めて、CONVとDENSEの処理を確認します。
どちらも積和がたくさん出てきます。
Tensorflow(EdgeTPUのCPU実行版)が、どこまでやってくれるのかわからないのですが、SIMD命令的な物は使ってくれていると思います。
また、演算の種別としてはDENSEとCONVに違いはありません。
一方、データに着目するとどうでしょうか?
CONVの方は、同じウェイト(w)と入力データ(x)を何回も使いまわします。出力(y)を出すための計算も局所局所で行うと思うので、キャッシュヒット率が非常に高いのではないかと思います。
比べて、DENSEの方は、入力データ(x)は使いまわせるのですが、ウェイト(w)はそれぞれ1回しか使いません(バッチサイズ1の推論の場合)。そのため、キャッシュヒット率が悪く、パフォーマンス低下の一因となっているのではないかと思われます。
というのが、組み込み屋さん目線で見た、CPU実行時にDENSEが遅い要因考察です。
考察: なぜDENSEは遅いのか (Edge TPU実行時)
CPU上でDENSEがCONVに比べて遅くなるのは分かりました。では、Edge TPU上で実行時に、DENSEがCONVよりも遅くなった、さらに、CPU実行のDENSEに比べても遅くなってしまったのはなぜでしょうか?
まだ読んでいない方は、改めてこちら(https://cloud.google.com/blog/products/gcp/an-in-depth-look-at-googles-first-tensor-processing-unit-tpu )をご一読ください。
TPUは、積和演算に特化したMatrix Multiplier Unit (MXU)を持っています。MXUはシストリックアレイ(systolic array) 構造を採用することで、積和演算を高速実行します。
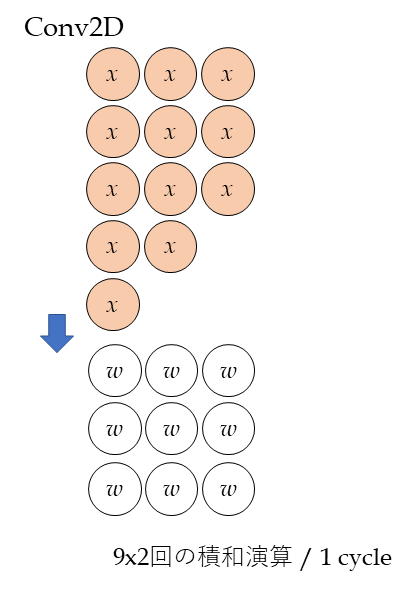
CONVの場合には、上の図のように、大量の入力データが流れてきます。シストリックアレイが最大のパフォーマンスを発揮するのは、全部のALU(積和演算器)が動いている場合です。(イメージ的には上図の肌色の入力データ(x)が、すべてのALU(w)を覆った時です)。
この時、2(積和)xALU数の演算が1cycleで実行されます。上図だと9x2 [Ops/cycle] です。
ちなみに、記事中のTPUではALUの数は65536個なので、65536x2x700MHz = 92TOPSが理論値となっています。
EdgeTPUのシストリックアレイのサイズ(NxM)とクロック周波数(f)も、4TOPS=2xNxMxf という式から推測は出来そうです。
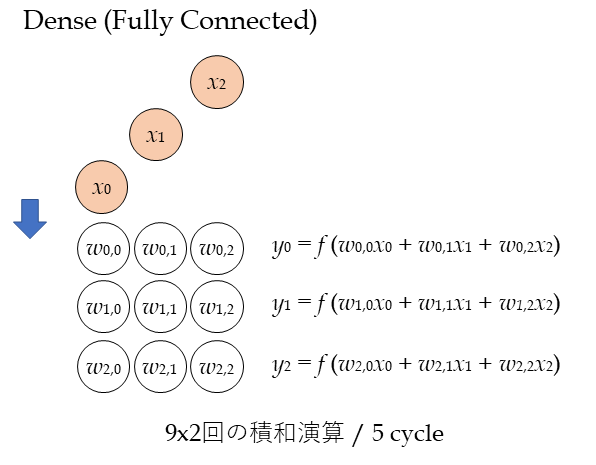
一方、Denseはどうでしょうか?
上の図がDENSEをシストリックアレイで計算した場合の図です。
効率が悪いです。ウェイト(w)は使いまわせないので、斜めに時間差を持って入ってくる入力データ(x)に対する計算が終わるまで、他の計算が出来ません。
入力N、出力MのDENSE計算量はNxMの乗算 + (N-1)xMの加算 になります。簡単のため、2xNxMとします。これを処理するのに必要な時間は、(N-1) + M[cycle] です。これは、上の図でx2がw2,2に到達するまでの時間です。この間、MXUでは他の計算が出来ません。なぜならw0,0等はこの計算にしか使用しないためです。
もしもDENSEだけのモデルを実行したら、処理性能は2xNxMxf / (N-1) + M となります。
つまり、CONVだけのモデルに比べて、1/(N-1)+M ≒ 1/2N の速度性能になります。
今回の結果として、EdgeTPUでConvだけのモデルを動かした場合は2.1TOP=2100GOPS出ました。一方、DENSEだけのモデルだと0.6GOPSでした。ConvとDENSEを比べると、速度差は2100/0.6 = 3500倍でした。
シストリックアレイのサイズ(NxM)が256x256だとすると、理論的な速度差は512倍程度なので、他にもオーバーヘッドがあるのかもしれません。メモリアクセスなど。
で、なんでCPUよりも遅いの? という疑問に戻ります。
Edge TPUは、同時にたくさんの演算をやってパフォーマンスを上げよう! という思想です。ここでいう「同時にたくさんの演算」は、1次元ではなく行列に特化して2次元的にたくさんの演算をやります。リソース使用率が100%のとき、2xNxM [ops/cycle] になります。そのため、クロック周波数はそんなに高くないようです。初期ですがCloud用TPUでも700MHzらしいので、Edge TPU用だともっと低いと思います。
上述した通りDENSEだとリソース使用率が悪くなってしまいます。具体的には、2xNxM / (N-1) + M [ops/cycle] になります。結果として、Edge TPUは単にクロックが遅いプロセッサとなり、CPUよりも遅くなったのだと考えられます。。
所で、今回は推論だけを試しました。
そのため、DENSEで使用するweightはそれぞれ1回しか使用されず、効率が悪くなった、というのが考察の結論です。
これのウェイトを使いまわすことができたら、速くなる可能性があります。
学習時にバッチサイズを大きくしたら、それが可能です。
https://qiita.com/koshian2/items/25a6341c035e8a260a01 の記事でも、バッチサイズを大きくすることで、MLPのEdge TPU実行速度が向上した、的な結果が得られています。
まあ、Edge TPUは普通は推論にしか使わないのですけどね。
Dense(Fully Connected)層まとめ
- CPU性能、USB2/3の差異による影響はCONVと同じ
- DENSEはCONVに比べて非常に遅くなる
- 以下、理由の推測
- シストリックアレイの構造上の理由
- TPUはシストリックアレイを使って、大量の演算を同時実行させようという設計思想。そのため、クロック周波数は抑え気味
- DENSEだと、肝である「大量の演算の同時実行」が出来ないので、単にクロックが低いCISCとなり果てて、CPUよりも遅くなる
一般的なモデルのパフォーマンス
これまで、特定の演算に特化したモデルを見てきました。
また、演算の解析に集中できるように入出力データはほぼ0のモデルを見てきました。
しかし実際には、モデル内部には色々な種類のレイヤがあります。また、入力が画像の場合には、結構な量の入力データ転送が必要になります。
以下の一般的なモデルを例に、パフォーマンスを見てみます。(オリジナルのtfliteが入手可能。Edge TPU用にコンパイル可能。という基準で選びました。)
- mobilenet_v1_1.0_224
- mobilenet_v2_1.0_224
- coco_ssd_mobilenet_v1
- coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.tflite
- http://storage.googleapis.com/download.tensorflow.org/models/tflite/coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip
Edge TPU用に変換
前回と同じ手順で変換します。 https://qiita.com/iwatake2222/items/922f02893355b30dab2e#edge-tpu%E7%94%A8%E3%81%AB%E5%A4%89%E6%8F%9B
実行
前回と同じコードで、Jetson Nano上で推論実行します。
https://qiita.com/iwatake2222/items/922f02893355b30dab2e#%E5%AE%9F%E8%A1%8C
Edge TPU用に変換
Edge TPU Compiler version 1.0.249710469
Input: ./coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.tflite
Output: coco_ssd_mobilenet_v1_1.0_quant_2018_06_29_edgetpu.tflite
Operator Count Status
CUSTOM 1 Operation is working on an unsupported data type
CONCATENATION 2 Mapped to Edge TPU
CONV_2D 34 Mapped to Edge TPU
DEPTHWISE_CONV_2D 13 Mapped to Edge TPU
RESHAPE 13 Mapped to Edge TPU
LOGISTIC 1 Mapped to Edge TPU
いつも通り、Edge TPU Compilerで変換します。
coco_ssd_mobilenet_v1コンパイル時のログを貼り付けます。これまで見てきた他のモデルでは、全ての演算はMapped to Edge TPU でした。が、SSDではOperation is working on an unsupported data type となった演算がでてきてしまいました。モデルを見ると、PostProcessing部分のようです。この部分以降はCPU側で実行されます。
onlineコンパイラの方が明示的に、「この演算はCPUで実行されるよ」と言ってくれて分かりやすいので、onlineコンパイラのキャプチャも貼り付けます。
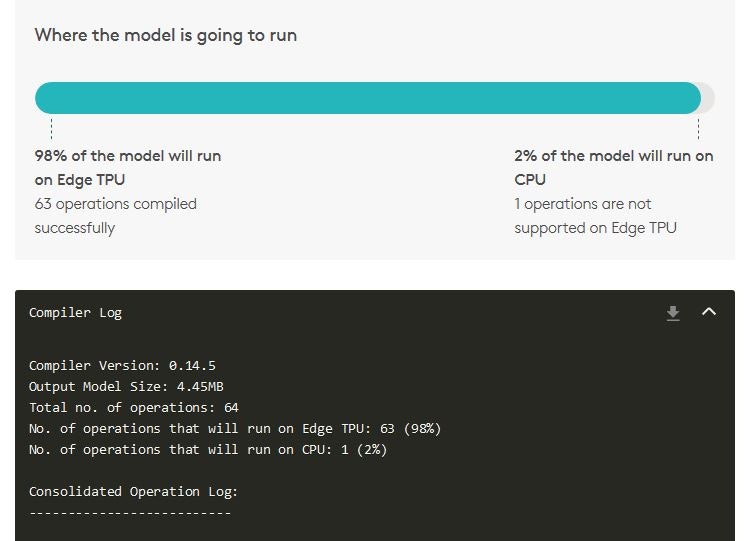
結果
| モデル | Model Size [MiB] | 処理時間 [msec] | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10W | 5W | ||||||||||
| tflite | edgetpu | On-chip memory available | On-chip memory used | Off-chip memory used | CPU | EdgeTPU | EdgeTPU (USB2.0) | CPU | EdgeTPU | EdgeTPU (USB2.0) | |
| mobilenet_v1_1.0_224 | 4.080 | 4.320 | 7.140 | 4.210 | 0 | 107.4 | 2.4 | 8.5 | 159.4 | 3.5 | 11.0 |
| mobilenet_v2_1.0_224 | 3.410 | 3.89 | 6.91 | 3.75 | 0 | 89.7 | 2.5 | 10.0 | 133.7 | 3.5 | 14.5 |
| coco_ssd_mobilenet_v1 | 3.990 | 4.450 | 7.62 | 4.23 | 0 | 149.3 | 11.5 | 32.8 | 222.4 | 16.2 | 49.8 |
結果は上表のとおりです。
10W/5Wモードを比較すると、全体的に1/1.5程遅くなっています。
理由としては以下が考えられます。
- Edge TPU側での処理時間が数msec程度と少なく、制御(CPU使用)にかかる時間の割合が大きい
- 入出力データ転送があるため、その部分でもCPUの影響を受けた (前回実験結果より、CPU性能はデータ入出力に影響有り)
- coco_ssd_mobilenet_v1では、PostProcessがCPU側で実行されるため、CPU性能の影響を受けやすい
USB3/2を比較すると、USB2だと1/3~1/5程度の速度性能です。
パラメータ自体は全部on-chipに配置されるのですが、その初回のパラメータ転送や、入出力データ転送に影響がでているのだと考えれらます。
速度(対CPU比)
| モデル | 処理速度 [倍] | |||
|---|---|---|---|---|
| 10W | 5W | |||
| EdgeTPU | EdgeTPU (USB2.0) | EdgeTPU | EdgeTPU (USB2.0) | |
| mobilenet_v1_1.0_224 | 44.543 | 12.653 | 45.459 | 14.535 |
| mobilenet_v2_1.0_224 | 35.525 | 8.997 | 38.293 | 9.247 |
| coco_ssd_mobilenet_v1 | 12.954 | 4.553 | 13.745 | 4.467 |
CPU実行時との処理速度の比較を上表に示します。
mobilenetだとv1,v2どちらも40倍程度高速です。が、USB2だと10倍程度に低下してしまいます。データ転送の低下の影響だと思われます。
coco_ssd_mobilenet_v1だと、処理速度は13倍程度にとどまりました。これは、一部の処理がCPU側で実行されていることが原因だと思われます。
おわりに
Operationに注目した速度性能の解析を行いました。
Edge TPUには向き不向きな演算があることが分かりました。
CONVのように、連続した積和演算が実行可能なレイヤを多く使たモデルの方がEdge TPUは嬉しいようです。
が、Edge TPU用にガチガチにチューニングしたモデルの開発というのは、最初の段階ではやらない方が良いと思います。
ソフトウェアの高速化で一般的に言われているように、まずは全体、上位のレベルでの最適化を行ってください。
- 要件の確認
- 精度と速度のどっちが重要?
- 何fps必要? 本当に高速化は必要?
- Edge TPUは必須? PC, GPU, クラウドじゃダメ?
- 使用するアルゴリズムの最適化 (MobileNetを使うのか、Inceptionを使うのか、など)
- パラメータチューニング (モデル入力サイズを小さくしたり、グレイスケール入力にしたり)
- 細かい最適化
本記事で述べたことは上記の4番目にようやく出てくるような内容です。
ですので、設計に役立てるというよりかは、「Edge TPUで動かしたときに何か性能が出ない」といった場合の問題解析時に、こんな記事があったなと思いだしていただけると幸いです。