TL;DR
ColabのTPUを使って今すぐCNNを試してみよう。ものすごい速いぞ。
はじめに
9/26夜、Google Colaboratoryユーザーに激震が走った。
**ハードウェアアクセラレータにTPUが使えるようになってる!?**TPU(Tensor Processing Unit)凄さはこのニュースを見れば恐ろしいほど伝わってくる。
COOL Chips 21 - GoogleのWebサービスを支える「TPU」
https://news.mynavi.jp/article/20180424-621091/
TPU v1はIntelのHaswell CPUとNVIDIAのK80 GPUと比較すると、性能は15~30倍、電力効率は30~80倍になっているという。
NVIDIA K80は現在ColabのGPUアクセラレータとして用いられているGPUだ。もしこの15~30倍という値が本当なら、1080Tiを2枚刺し程度ではとてもかなわないぐらいのモンスター計算リソースであることは間違いない。しかも無料で使えるのだ。早速それを体感してみたい。
9/28 追記:9/27に書いたコードだと並列化が効いてなくて本来のパワーが出せていませんでした。そのため大幅に内容を変えて書き直しました。お詫びして訂正します。
10/1 追記:NVIDIAの中の人に紹介されました。ありがとうございます!
TPUは素晴らしいデバイスですが、K80がかわいそうなのでちょっと補足。
— Kuninobu SaSaki (@_ksasaki) 2018年9月30日
・K80は4年前のモデル、V100の3世代前。
・K80は2発のGK210を搭載、8.74TFLOPSは2発の合計。ColabのK80はその片方だけで性能は半分
・上記性能数値は単精度、TPUの数値は半精度。V100なら半精度(単精度との混合精度)は125TFLOPS https://t.co/iHXs4Zvytl
ちなみに「K80を半分だけ提供」というのは、AWSのp2.xlarge、AzureのNC6の他Google CloudやOracle Cloudでも使えてクラウドでは割と一般的。
— Kuninobu SaSaki (@_ksasaki) 2018年9月30日
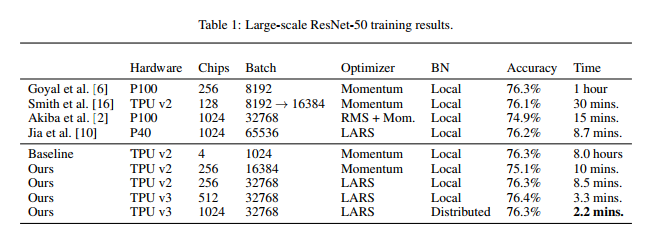
追記(11/22):GoogleがクラウドTPUv3を使ってImageNetのデータをResNet-50で「2.2分」で訓練することに成功したらしい
2018/11/16付けのarXivの論文。
(1) Chris Ying, Sameer Kumar, Dehao Chen, Tao Wang, Youlong Cheng. Image Classification at Supercomputer Scale
https://arxiv.org/abs/1811.06992v1
これによると、TPUv3のチップ1024個を使い精度を落とすことなく、ImageNetの訓練を2.2分で完了することに成功したとのこと。実は似た研究でChainer+GPU(P100×1024)を使って15分で訓練を終わらせたという論文が約1年前に出ています。これは皆さんご存知、Preferred Networksの方の論文です。
(2) Takuya Akiba, Shuji Suzuki, Keisuke Fukuda. Extremely Large Minibatch SGD: Training ResNet-50 on ImageNet in 15 Minutes
https://arxiv.org/abs/1711.04325
これは2017/11/12の論文です。ちなみにこのPFNの記録は、2018/7/30の論文でP40×1024を使い8.7分での訓練に成功したことで破られています。
(3) Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes
https://arxiv.org/abs/1807.11205
(2),(3)どちらの論文も(1)の論文に引用されています。図は(1)の論文からです。
TensorFlow/KerasはTPUに対応しました。PyTorchはTPU対応することが表明されています。これを見てまだchainerってTPU対応なさらないんですか? 記録見て真っ青になってる暇あったら対応したほうがいいのではないでしょうか?
多層パーセプトロンを試してみる
上の記事を読むと、TPUの使用頻度のうち6割がMLP(多層パーセプトロン)であるという。それを考えるとMLP向けにチューニングされていてもおかしくはない。そこで、CIFAR-10をMLPとCNNで分類してみたい。TPUの扱い方は以下のノートブックが参考になる1。
-
Hello, TPU in Colab
https://colab.research.google.com/notebooks/tpu.ipynb#scrollTo=PUINPtMG_w9i -
Predict Shakespeare with Cloud TPU in Keras
https://colab.research.google.com/github/tensorflow/tpu/blob/master/tools/colab/shakespeare_with_tpu_and_keras.ipynb
keras.layersを使うとエラーが出てしまったのだが、全てtensorflow.kerasで置き換えたら上手く行った。
import tensorflow as tf
import tensorflow.keras.backend as K
import numpy as np
from tensorflow.contrib.tpu.python.tpu import keras_support
from tensorflow.keras.layers import Input, Conv2D, BatchNormalization, Activation, AveragePooling2D, Dense, Dropout, Flatten
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.utils import to_categorical
import os
def basic_mlp_module(input, units):
x = Dense(units)(input)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Dropout(0.5)(x)
return x
def create_mlp_model():
input = Input((32*32*3,))
x = basic_mlp_module(input, 2048)
x = basic_mlp_module(x, 1024)
x = basic_mlp_module(x, 512)
x = basic_mlp_module(x, 256)
x = basic_mlp_module(x, 128)
x = basic_mlp_module(x, 64)
x = basic_mlp_module(x, 32)
x = basic_mlp_module(x, 16)
x = Dense(10, activation="softmax")(x)
return Model(input, x)
def main():
K.clear_session()
# CIFAR
(X_train, y_train), (_, _) = cifar10.load_data()
X_train = (X_train / 255.0).reshape(50000, -1)
y_train = to_categorical(y_train)
# モデルを作成
model = create_mlp_model()
model.compile(tf.train.AdamOptimizer(learning_rate=1e-3), loss="categorical_crossentropy", metrics=["acc"])
# TPU
tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy)
model.fit(X_train, y_train, batch_size=1024, epochs=10)
if __name__ == "__main__":
main()
通常、CIFAR-10をMLPで分類することはまずないが、今回TPUの性能を見るためにあえてこのようにした。「FC→BatchNorm→ReLU→Dropout」を組み合わせたシンプルにしてみた。ログはこのように出てくる。確かに上手く行っている。
INFO:tensorflow:Found TPU system:
INFO:tensorflow:*** Num TPU Cores: 8
INFO:tensorflow:*** Num TPU Workers: 1
INFO:tensorflow:*** Num TPU Cores Per Worker: 8
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, -1, 16911076375941495341)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 17179869184, 14217586846733244505)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_GPU:0, XLA_GPU, 17179869184, 5317398272108338030)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 17179869184, 9074497440691214240)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 17179869184, 9715813986861894326)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 17179869184, 6334736007584168012)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 17179869184, 17383481095617712477)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 17179869184, 1899635486749140573)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 17179869184, 443377032706268906)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 17179869184, 16261774136557817830)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 17179869184, 9123581018776995322)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 17179869184, 10366433732083123166)
WARNING:tensorflow:tpu_model (from tensorflow.contrib.tpu.python.tpu.keras_support) is experimental and may change or be removed at any time, and without warning.
INFO:tensorflow:Connecting to: b'grpc://10.99.185.170:8470'
Epoch 1/10
INFO:tensorflow:New input shapes; (re-)compiling: mode=train, [TensorSpec(shape=(128, 3072), dtype=tf.float32, name='input_10'), TensorSpec(shape=(128, 10), dtype=tf.float32, name='dense_8_target_10')]
INFO:tensorflow:Overriding default placeholder.
INFO:tensorflow:Remapping placeholder for input_1
INFO:tensorflow:Started compiling
INFO:tensorflow:Finished compiling. Time elapsed: 5.3501341342926025 secs
INFO:tensorflow:Setting weights on TPU model.
48128/50000 [===========================>..] - ETA: 0s - loss: 2.6785 - acc: 0.0976INFO:tensorflow:New input shapes; (re-)compiling: mode=train, [TensorSpec(shape=(106, 3072), dtype=tf.float32, name='input_10'), TensorSpec(shape=(106, 10), dtype=tf.float32, name='dense_8_target_10')]
INFO:tensorflow:Overriding default placeholder.
INFO:tensorflow:Remapping placeholder for input_1
INFO:tensorflow:Started compiling
INFO:tensorflow:Finished compiling. Time elapsed: 4.035495758056641 secs
50000/50000 [==============================] - 36s 720us/step - loss: 2.6708 - acc: 0.0979
Epoch 2/10
50000/50000 [==============================] - 12s 245us/step - loss: 2.4277 - acc: 0.1070
Epoch 3/10
50000/50000 [==============================] - 13s 251us/step - loss: 2.3457 - acc: 0.1099
Epoch 4/10
50000/50000 [==============================] - 12s 249us/step - loss: 2.3090 - acc: 0.1054
Epoch 5/10
50000/50000 [==============================] - 13s 250us/step - loss: 2.2848 - acc: 0.1238
Epoch 6/10
50000/50000 [==============================] - 12s 238us/step - loss: 2.2673 - acc: 0.1296
Epoch 7/10
50000/50000 [==============================] - 12s 245us/step - loss: 2.2325 - acc: 0.1387
Epoch 8/10
50000/50000 [==============================] - 12s 248us/step - loss: 2.2095 - acc: 0.1485
Epoch 9/10
50000/50000 [==============================] - 12s 249us/step - loss: 2.1710 - acc: 0.1618
Epoch 10/10
50000/50000 [==============================] - 12s 246us/step - loss: 2.1408 - acc: 0.1576
全く同じモデルをGoogle ColabのGPUで実行して比較していこう。TPUの設定を無視できる。main()の部分を以下のようにする。tensorflow.kerasを使っているが、よくあるKerasの例と同じなので詳細は省略。
def main():
K.clear_session()
# CIFAR
(X_train, y_train), (_, _) = cifar10.load_data()
X_train = (X_train / 255.0).reshape(50000, -1)
y_train = to_categorical(y_train)
# モデルを作成
model = create_mlp_model()
model.compile(tf.train.AdamOptimizer(learning_rate=1e-3), loss="categorical_crossentropy", metrics=["acc"])
model.fit(X_train, y_train, batch_size=1024, epochs=10)
ログに出てくる1エポックあたりの秒数と、ステップあたりのマイクロ秒数に着目する。これをバッチサイズを変えて、TPUとGPUで比較する。時間は10エポックのうち最も少ない(速かった)値とした。
| batch_size | TPU [s/epoch] | TPU [us/step] | GPU [s/epoch] | GPU [us/step] |
|---|---|---|---|---|
| 256 | 35 | 710 | 7 | 131 |
| 1,024 | 12 | 246 | 3 | 59 |
| 4,096 | 6 | 118 | 2 | 44 |
| 8,192 | 5 | 90 | 2 | 41 |
| 16,384 | 4 | 80 | 2 | 41 |
| 50,000 | 3 | 64 | 2 | 41 |
環境:Google Colaboratory(2018/9/28測定), TensorFlow==1.11.0-rc2, Keras==2.1.6
意外なことに、単体の計算性能を比べるとまだGPUのほうが速かった。ただ3秒と2秒の差なら「どっちも速いからいいじゃん」で良さそうな気はする。ただしTPUはバッチサイズを小さくすると露骨に遅くなる。ここだけは注意が必要だ。
ちなみにTPUの場合、8個ワーカーがあるので、バッチサイズ÷8サイズのテンソルを並列処理する。例えばバッチサイズが1024なら128個のサンプルを同時並列に、バッチサイズが8192なら1024個を同時並列にとなる。1024×8=8192あたりがよさげ?(追記:128の倍数ならなんでもいいらしい)
バッチサイズが256ではGPUが約5.4倍差で速かったが、バッチサイズを5万まで限りなく大きくすると、GPUとTPUの速度差は1.5倍程度に縮んだ。ただGPUはメモリの制約が問題になることが多いので、OOM(OutOfMemory)するバッチサイズを比べないと計算性能はよくわからない。
畳み込みニューラルネットワークを試してみる
畳み込みニューラルネットワーク(CNN)の例としてAlexNetも試してみよう。CNNはGPUの場合、バッチサイズを大きくするとすぐOOMするがTPUの場合どうだろうか。
def basic_cnn_module(input, chs):
x = Conv2D(chs, 3, padding="same")(input)
x = BatchNormalization()(x)
x = Activation("relu")(x)
return x
def create_cnn_model():
input = Input((32,32,3))
x = basic_cnn_module(input, 96)
x = AveragePooling2D(2)(x)
x = basic_cnn_module(x, 256)
x = AveragePooling2D(2)(x)
x = basic_cnn_module(x, 384)
x = basic_cnn_module(x, 384)
x = basic_cnn_module(x, 256)
x = Flatten()(x)
x = Dense(10, activation="softmax")(x)
return Model(input, x)
5層の畳み込みレイヤーからなるモデル(AlexNet)を定義し、main()内のmodel生成を以下のように変える。
model = create_cnn_model()
これで同様にTPUとGPUを比較してみよう。結果は以下の通り。記事では「CNN向けに最適化するのは間違い」とは言っているがどのぐらいの速度が出るだろうか。
| batch_size | TPU [s/epoch] | TPU [us/step] | GPU [s/epoch] | GPU [us/step] |
|---|---|---|---|---|
| 256 | 20 | 407 | 28 | 567 |
| 1,024 | 10 | 197 | 27 | 534 |
| 4,096 | 6 | 115 | OOM | OOM |
| 8,192 | 5 | 110 | OOM | OOM |
| 16,384 | 5 | 94 | OOM | OOM |
| 50,000 | 4 | 82 | OOM | OOM |
条件はMLPと同じだが、結果は打って変わってCNNではTPUの独壇場となってしまった。OOMとならずに比較できる範囲内でもTPUはGPUより3倍近く速い。ColabのGPUはTesla K80というGPUの中でもかなり速い部類なので、これに完全勝利したのは強いを通り越して末恐ろしい。
OOMはCUDA OutOfMemoryを示す。またTPUはメモリ性能も良くて、GPUの場合はバッチサイズが4096でOOMとなり力尽きてしまったが、TPUの場合はバッチサイズCIFAR5万枚全部1バッチで処理することができた。いくら軽いAlexNetといえど、1バッチで5万枚同時に画像入れられるというのは正気の沙汰とは思えない。
Google謹製のTPU、やばい。ちなみにこれで「CNN向けに最適化するのは間違い」とか言うものだからクレイジーすぎる。
まとめ
- GoogleColabで無料で使えるTPUとGPUを比較してみた。Colab版の無料のアクセラレータでは、MLPはGPUのほうがまだ速いが、CNNはTPUの完全勝利。これで無料版なので、有料のCloud版ならもっと速いと思う。Cluoud版なら評定どおりのK80の15~30倍という速さが出てもおかしくはない。測定結果を随時募集中。
- メモリ性能は無料版で既にGPU(ColabのK80:11GB)を超えている。ビッグデータや高解像度の画像処理に対しては無類の強さを発揮すると思われる。ここでは試していなかったがLSTMもよさそう?
- Googleは神。海外でも「Marry me, Google」と言われてるようにGoogleと結婚したい。
以上です。皆さんもぜひGoogle ColabのTPUを体験してみてください。
追記
-
tensorflow.kerasとkerasでどう違うのか?
Colabにプリインストールされているkeras2.1.6前提だとTPU未対応なのかエラーが出る。これは「!pip install keras==2.2.0」でアップデートしても変わらない。各レイヤー(keras.layers)、モデル(keras.model)、オプティマイザー(keras.optimizers)を「tensorflow.keras.~」に全て置き換えると動く。importの部分をtensorflow.kerasに置き換えればいいだけで、TensorflowのAPIに置き換える必要はない。他にもエラーが出る場合は、バックエンド(keras.backend)、コールバック(keras.callbacks)を置き換えると動いた。とりあえずエラー出たらtensorflowのものに変えればよさそう。後で調べたら、オプティマイザーはtf.train.~に置き換えなくてもよくて、KerasAPIのオプティマイザーでよい。 -
ColabはTPUv2を使っているらしい
9/27の「TensorFlow and Deep Learning Singapore」の発表資料より。
https://www.dropbox.com/s/jg7j07unw94wbom/TensorFlow%20Keras%20Colab%20TPUs.pdf?dl=0
この方が書いているMNISTサンプル。https://colab.research.google.com/drive/1F8txK1JLXKtAkcvSRQz2o7NSTNoksuU2 -
計算性能は最大で45TFLOPS?
この記事を読むと、TPU v2は1チップあたり最大で45TFLOPSと書かれている。K80の性能が最大で~~8.74TFLOPS~~(ColabのはK80は半分のみ使っているそうです。補足してくださった方ありがとうございました2)であることを踏まえると、そのぐらい出ていてもおかしくはないと思う。ただ、TPUの場合はGPUとモデルのコンパイルが全く違っていて、大きいモデルだとコンパイルの時間がかかったり、他のボトルネックとなる要素もかなり目につく。例えば同じ分析でモデルを深くしても計算速度が変わってなかったり、TPUの計算処理以外の部分がボトルネックとなっているということもある。必ずしも最大FLOPSの性能を引き出せるとは限らないということは頭の片隅においておいたほうが良さそう。GPUのFLOPSからはかなり割り引いて考えたほうがいい。
-
メモリが足りないって怒られた
とりあえずカーネルを再起動してみよう。それでも怒られたら仕方ない。 -
save_weightsしたときにhdf5形式で保存できない
TensorFlowの仕様変更が原因。詳しくはこちらに書いた。 -
ものすごい遅いんだけど
自分も同じケースになったことがある。おそらくmodelをTPU用のモデルに変換していないから(例えばself.modelで定義しているところをmodelと書いていないか?)。**TPU用のモデルに変換しなくても動くことは動く(ここポイント)**だが物凄い遅いので注意が必要。
関連記事
-
前作ったResNetのベンチマークをTPU版
https://blog.shikoan.com/colab-tpu-resnet-benchmarks/ - ColabのTPUでNASNet Largeを訓練しようとして失敗した話
https://blog.shikoan.com/tpu-nasnet-large-failed/
続編できました(10/12)
Google ColabのTPUで対GPUの最速に挑戦する
https://qiita.com/koshian2/items/fb989cebe0266d1b32fc
バグかもしれないこと
- KerasのLearningRateSchedulerが機能せず、全体の50%で学習率を1/10にするというようなことができない。Callbackでオプティマイザーのlrを直接変更してもできない。
解決法募集中です。
- TPU環境でhistoryが消える→TPU用にモデルを変換したためです。keras.callbacks.Historyを使いましょう。こちらに解決法を書きました。
-
こちらのツイートでTPUの扱い方の突破口が見えました。感謝! https://twitter.com/tomo_makes/status/1045198738614976513 ↩