はじめに
昨日と同じく決定木をコーディングしてみます。
昨日と違うところは、特徴量に文字列を使いたい場合、BoWとtf-idfを使って特徴量を無理やり作成することをしたいと思います。どこまで意味があるのかわかりませんが、やってみます。
※正直意味はないかもしれませんが、文字列データも分析に使用できるようにしていきたいなと思いました。
使用するデータ
使用するデータは、
https://qiita.com/iwasaki_kenichi/items/43ba6e5d037b0edd247f
の記事でも使用している、kaggleのHuman Resource DataSetを使います。
https://www.kaggle.com/rhuebner/human-resources-data-set
このデータの、HRDataset_v9.csvを使用します。
コーディング
import numpy as np
import pandas as pd
from sklearn import tree
from sklearn.tree import export_graphviz
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
まずは各種インポートします。
今回は新しく、from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizerをインポートしています。
CountVectorizerはBoW(Bag of Words)、
TfidVectorizerはTF-IDF(Term-frequency-inverse document frequency)です。
とても簡単にいうと
BoW:ある文書における単語の出現回数を数えるアルゴリズム
TF-IDF:ある文書における、単語の重要度を計算するアルゴリズム
単語数(BoW)か、単語の重要度(TF-IDF)になります。
df = pd.read_csv("human-resources-data-set/HRDataset_v9.csv")
# notebookの場合、columns数が多いと途中が省略されてしまうので、set_optionにて見れるcolumns数を変更しております。
pd.set_option('display.max_columns', 50)
df.head()
ここは、前回の記事でも書きましたが、データは下記のような感じです。
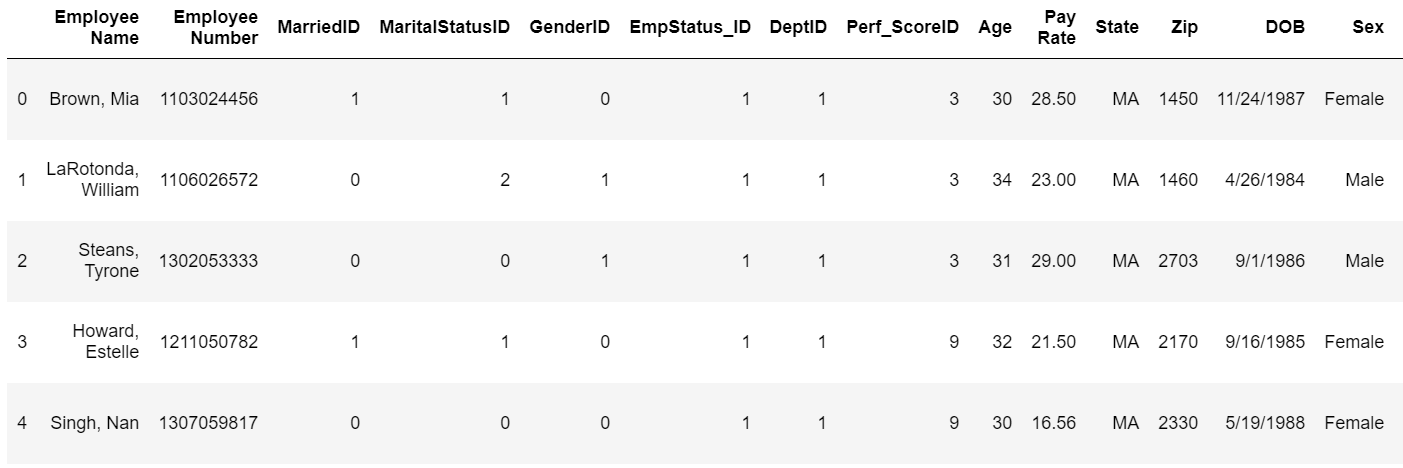


今回は、これらのデータの中でもEmployee Nameを特徴量にしたいと考えます。
その前に、このEmployee Nameがカテゴリカル変数じゃないことを確認してみます。
len(df)
df["Employee Name"].nunique()
df全体の大きさと、df["Employee Name"]を確認してみましたが、どちらも310でした。これでカテゴリカル変数じゃないことを確認できたので、特徴量に使えるよう、文字列を数値に変換していきたいと思います。
countvectorizer = CountVectorizer(min_df=2)
countvectorizer = countvectorizer.fit(df["Employee Name"])
tfidvectorizer = TfidfVectorizer(min_df=2)
tfidvectorizer = tfidvectorizer.fit(df["Employee Name"])
countvectorizerとtfidvectorizerをを作成し、fit関数を適用します。
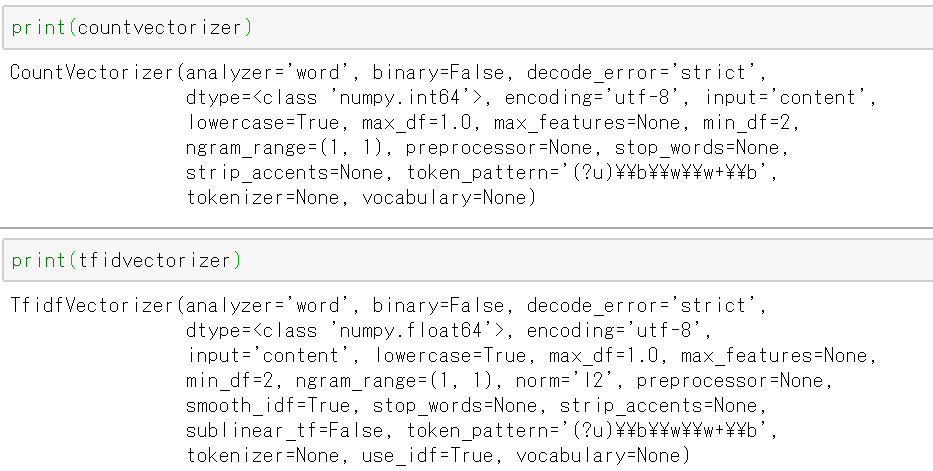
print(len(countvectorizer.vocabulary_))
print(dict(list(countvectorizer.vocabulary_.items())))
print(len(tfidvectorizer.vocabulary_))
print(dict(list(tfidvectorizer.vocabulary_.items())))

CountvectorizerもTfidVectorizerもデータの中身は同じみたいです。
具体的にデータの中身を見てみます。
df_vec = countvectorizer.transform(df)
df_tfid = tfidvectorizer.transform(df)
ddf_vec = pd.DataFrame(df_vec.toarray(),columns=countvectorizer.get_feature_names())
ddf_tfid = pd.DataFrame(df_tfid.toarray(),columns=tfidvectorizer.get_feature_names())
ddf_vec
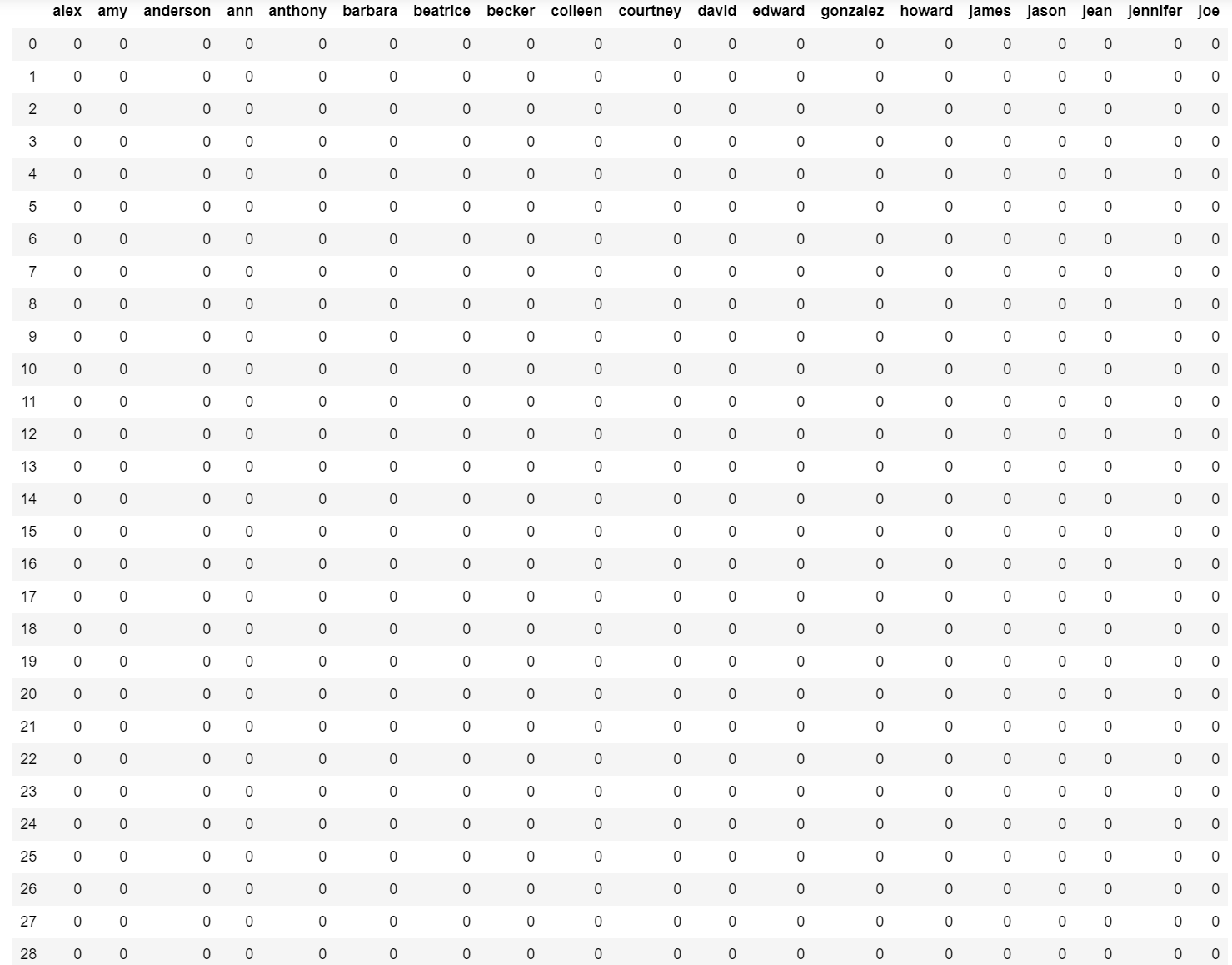
ddf_tfid
CountVectorizerは整数でTfidVectorizerは実数だということがわかりました。
ただ、データの中身はほとんど同じみたいですね。
以上で、データの中身はわかりました。
今回は、あくまでも文字列データを数値(BoWやTFD-IDによる数値変換)に変換し、変換したデータをトレーニングデータ、テストデータとして使います。
なので、fit_transform関数を使います。
cv = countvectorizer.fit_transform(df["Employee Name"])
tfid = tfidvectorizer.fit_transform(df["Employee Name"])
Sparse型はほとんどゼロの疎行列になります。
このままだとSparse型なので、toarray()でndarray型に変換します。
dffcv = cv.toarray()
dfftfid = tfid.toarray()
疎行列のままだと分析に使いにくい形なので、各行の総和をsum関数にて計算します。さらに、カラム名を”EmployeeNameFeature”と変更します。
変更したあとはpd.concat関数にて、データフレームを横方向にくっつけています。
dffcv_sum = pd.DataFrame(np.sum(dffcv,axis=1))
dfftfid_sum = pd.DataFrame(np.sum(dfftfid,axis=1))
dffcv_sum.columns=['EmployeeNameFeature']
dfftfid_sum.columns=["EmployeeNameFeature"]
df_cv = pd.concat([df,dffcv_sum],axis=1)
df_tfid = pd.concat([df,dfftfid_sum],axis=1)
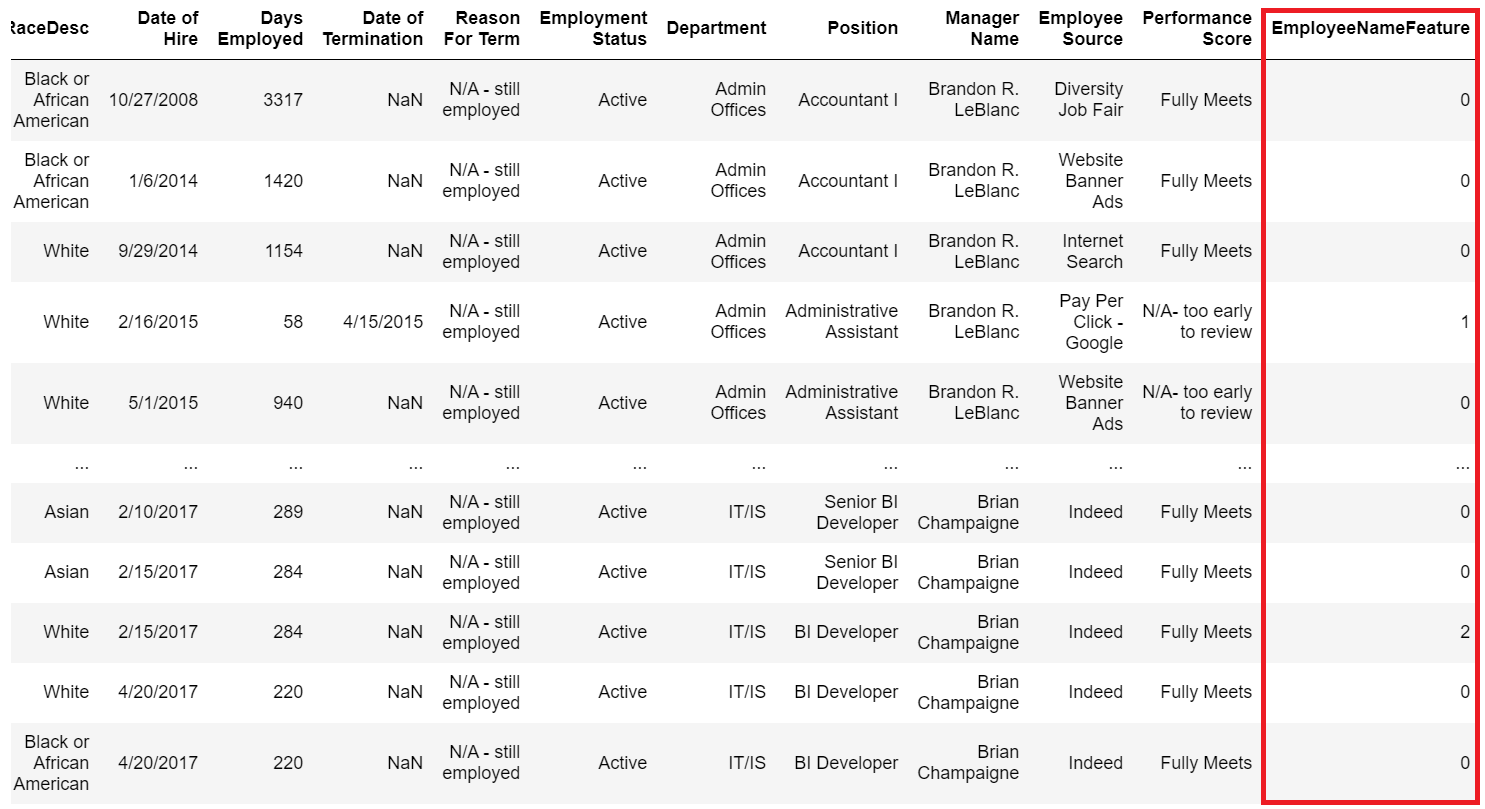
赤枠が、今回新しく作った特徴量です。
今回の分析では、以下のように説明変数や目的変数を設定します。
特徴変数:MarriedID以外
目的変数:GenderID,DeptID,Perf_ScoreID,EmployeeNameFeature
feature=["GenderID","DeptID","Perf_ScoreID","EmployeeNameFeature","EmployeeNameFeature"]
y_cv = df_cv["MarriedID"]
X_cv = df_cv[feature]
y_tfid = df_tfid["MarriedID"]
X_tfid = df_tfid[feature]
処理を実行します。
# CountVectorizer
X_train,X_test,Y_train,Y_test = train_test_split(X_cv,y_cv,train_size=0.7,random_state=0)
tree_clf = tree.DecisionTreeClassifier().fit(X_train, Y_train)
print(tree_clf.score(X_test, Y_test))
# TfidVectorizer
X_train,X_test,Y_train,Y_test = train_test_split(X_tfid,y_tfid,train_size=0.7,random_state=0)
tree_clf = tree.DecisionTreeClassifier().fit(X_train, Y_train)
print(tree_clf.score(X_test, Y_test))
結果は下記のようになりました。
・0.4731182795698925
・0.4731182795698925
全く同じ値になりました。
おわりに
文字列の変換を今回新しくやってみました。たくさんしてみたいですが、そもそもデータセットが無いような気もします。。。