はじめに
標記の通りです。学習する際にはトレーニングデータとテストデータと分け、トレーニングデータで学習をし、テストデータで学習できているか確認してみます。
使うデータは前にも使ったアボカドデータです。
https://qiita.com/iwasaki_kenichi/items/ea580fd9498ad6950a75
データ分割の方法
色々あると思いますが、ここではscikit-learnのtrain_test_splitを使います。
main1.py
# ライブラリインポート
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,train_size=0.8)
ここで、test_sizeはテストデータのサイズです。テストデータは全体の8割としています。
コード
main1.py
# ライブラリインポート
%matplotlib inline
import numpy as np
from pylab import *
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
# データ読み込み
df = pd.read_csv("hogehoge.csv")
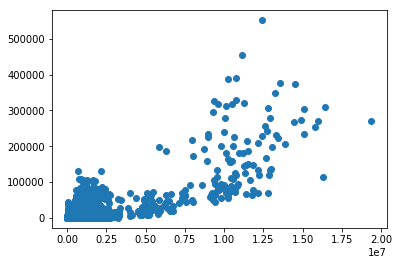
scatter(df["Total Bags"],df["XLarge Bags"])
X = df["Total Bags"]
Y = df["XLarge Bags"]
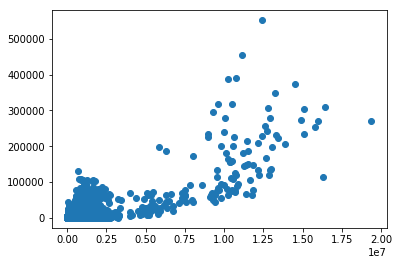
main2.py
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,train_size=0.8)
scatter(X_train,Y_train)
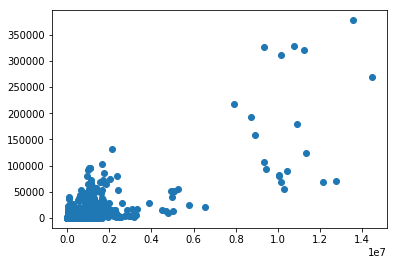
main3.py
scatter(X_test,Y_test)
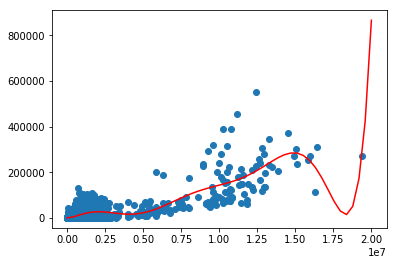
main4.py
p4 = poly1d(np.polyfit(X_train,Y_train,8))
xp = np.linspace(0,20000000,50)
axes = plt.axes()
axes.set_xlim([0,20000000])
axes.set_ylim([0,6000000])
plt.scatter(X_train,Y_train)
plt.plot(xp,p4(xp),c="r")
plt.show()
main5.py
xp = np.linspace(0,20000000,50)
# axes = plt.axes()
axes.set_xlim([0,20000000])
axes.set_ylim([0,6000000])
plt.scatter(X_test,Y_test)
plt.plot(xp,p4(xp),c="r")
plt.show()
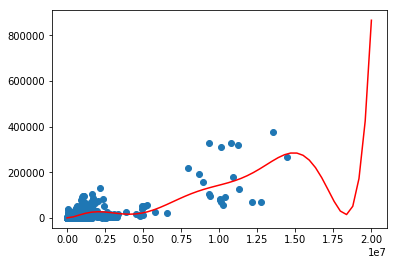
main5.py
r2 = r2_score(Y_test,p4(X_test))
print(r2)
# 結果は0.6496548856957747
r2 = r2_score(Y_train,p4(X_train))
print(r2)
# 結果は0.6945770505912501
おわりに
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,train_size=0.8)は覚えられない。なんかコピペバンバン使いそう。
このあたりもサラッと書けるようになりたい。