はじめに
データ分析形の仕事の際、膨大なエクセルデータを誰かに見せる際に
表形式のまま提示すると、伝えたいことも伝えにくいことがある。
最近はRを使っているので、ggplot2を学んだ。備忘録的に書きます。
扱うデータ
使い慣れているアボカドデータを使います。
URLはhttps://www.kaggle.com/neuromusic/avocado-pricesです。
カテゴリカルデータ、実数値、時系列と揃っているので扱いやすいです。
しかもデータ自体も軽いので、個人的におすすめです。
ggplot2について
色々なことが記事を書いているので、わざわざ書くまでもありませんが、
Rの可視化パッケージです。pythonでいうSeabornだと認識しております。
ggplot2のほうが簡単だなと思いました。。というよりもRstudio上で画像が確認できるのが楽でいいなと思いました。「Pythonだってnotebookのインラインで画像出せるよ!」と言われそうですが、私の使っているパソコンでは
スペックが足りないのか重く感じます。
とりあえずEDA
Rの記事で恐縮ですが、一旦pandas-profilingsでデータ探索しました。(Rでも似たようなパッケージはないのでしょうか。。あると嬉しいのですが)

どんなデータなのか、ざっくり見ると面白いです。
pandas-profilingsは、各変数ごとの相関が高いものは分析してくれないです。これは、重回帰分析をする際、高すぎる相関を持つ変数を説明変数とするとモデルの当てはまりが悪くなるだと思います。わざわざ消してくれているのですね。今回の場合、4225と4046が0.9以上の相関を持つため、4225は処理していないです。
※4225などの数字はavocadoの種類を指します。
詳細はこちら
AveragePriceをみると、正規分布っぽい形をしています。1~1.5あたりが最も多いみたいですね。
regionは、valueをみるとわかるかもしれませんがアメリカの都市が格納されているみたいです。たとえば、ChicagoやLosAngelesなどです。これはカテゴライズ変数のようですね。
typeもカテゴライズで、本データセットのアボカドはconventionalかorganicに属するみたいですね。なんとなくですが、organicのAveragePriceのほうが高そうです。
Pandas-Profilingsでもある程度はわかるかもしれません。ただ、やはりまだまだ詳細に見てみたい部分が出てくるかと思います。それをggplot2でコーディングしながら見ていきたいと思います。
ggplot
散布図
ggplot(df,aes(x=Total.Volume,y=X4046,colour=region,shape=type))+
geom_point()
ggplot(df,aes(x=Total.Volume,y=X4225,colour=region,shape=type))+
geom_point()
ggplot(df,aes(x=Total.Volume,y=X4770,colour=region,shape=type))+
geom_point()
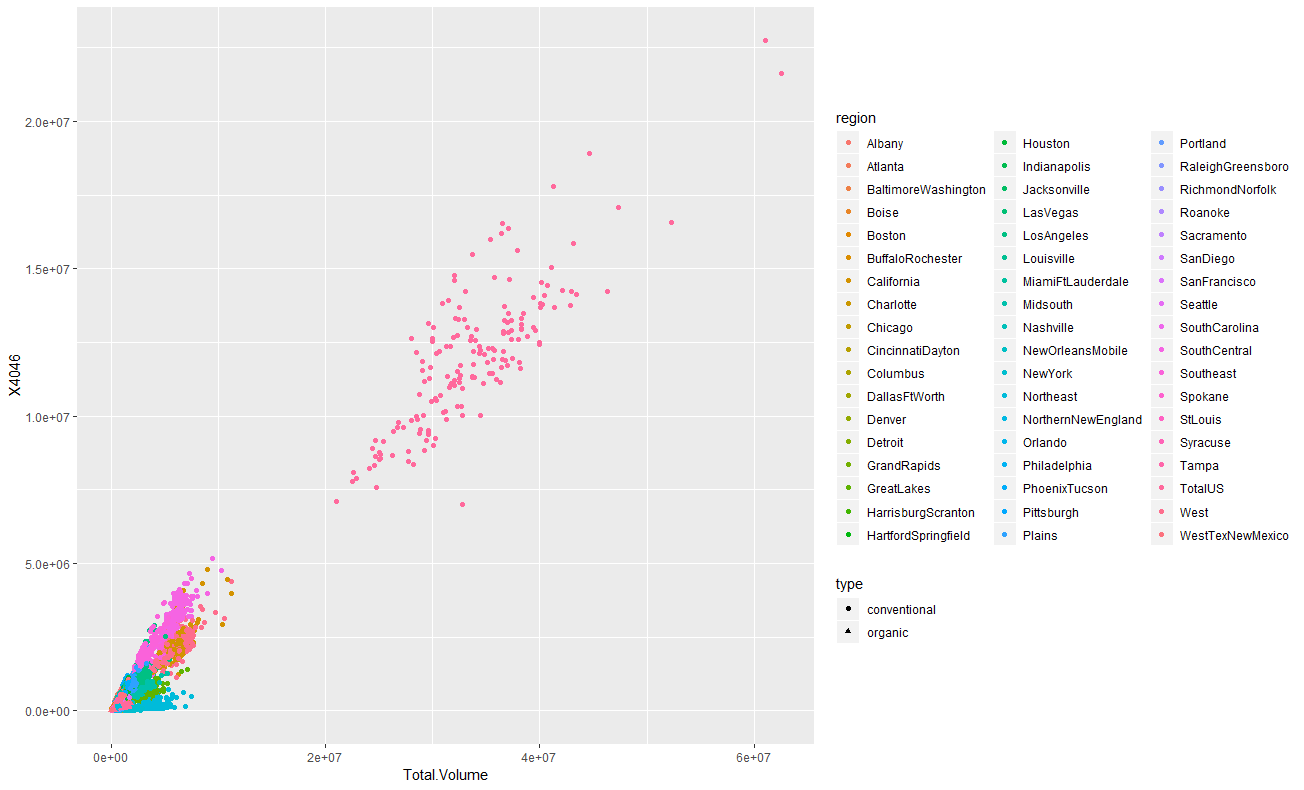
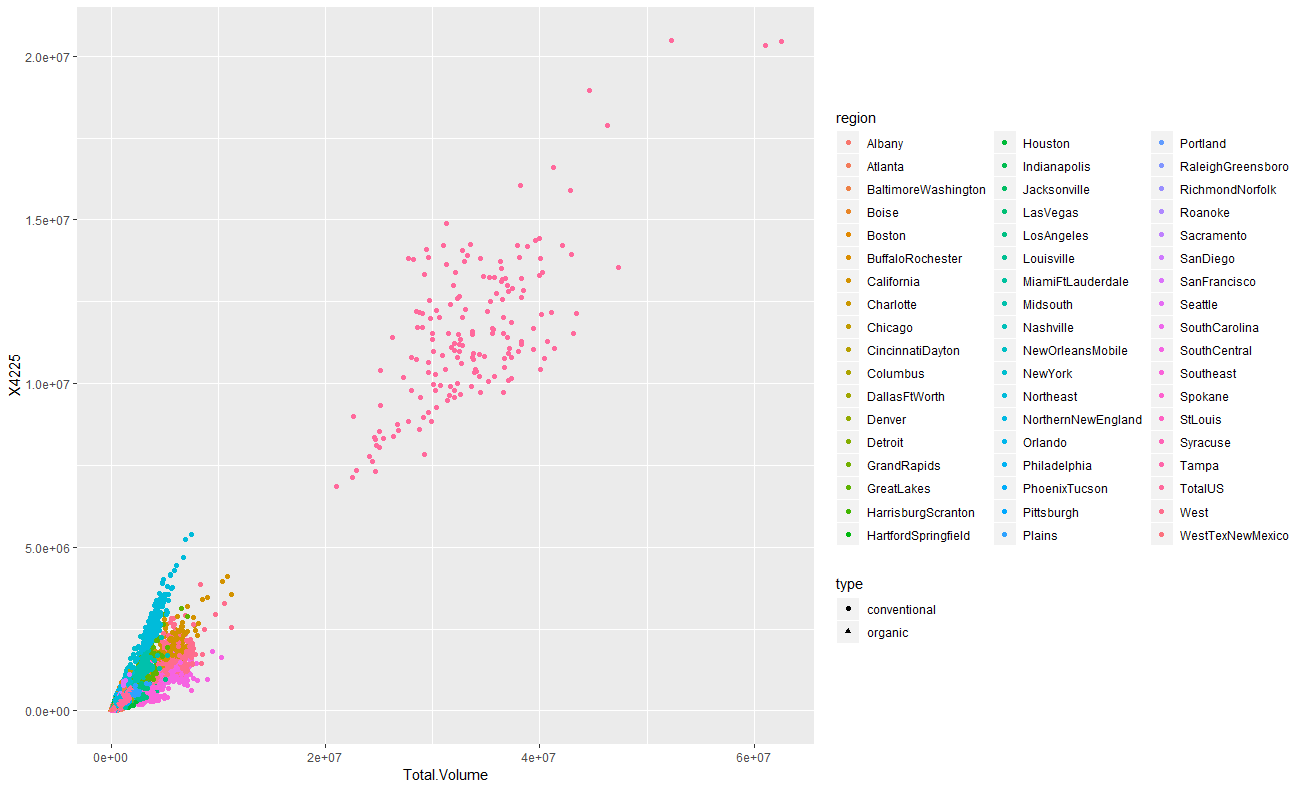
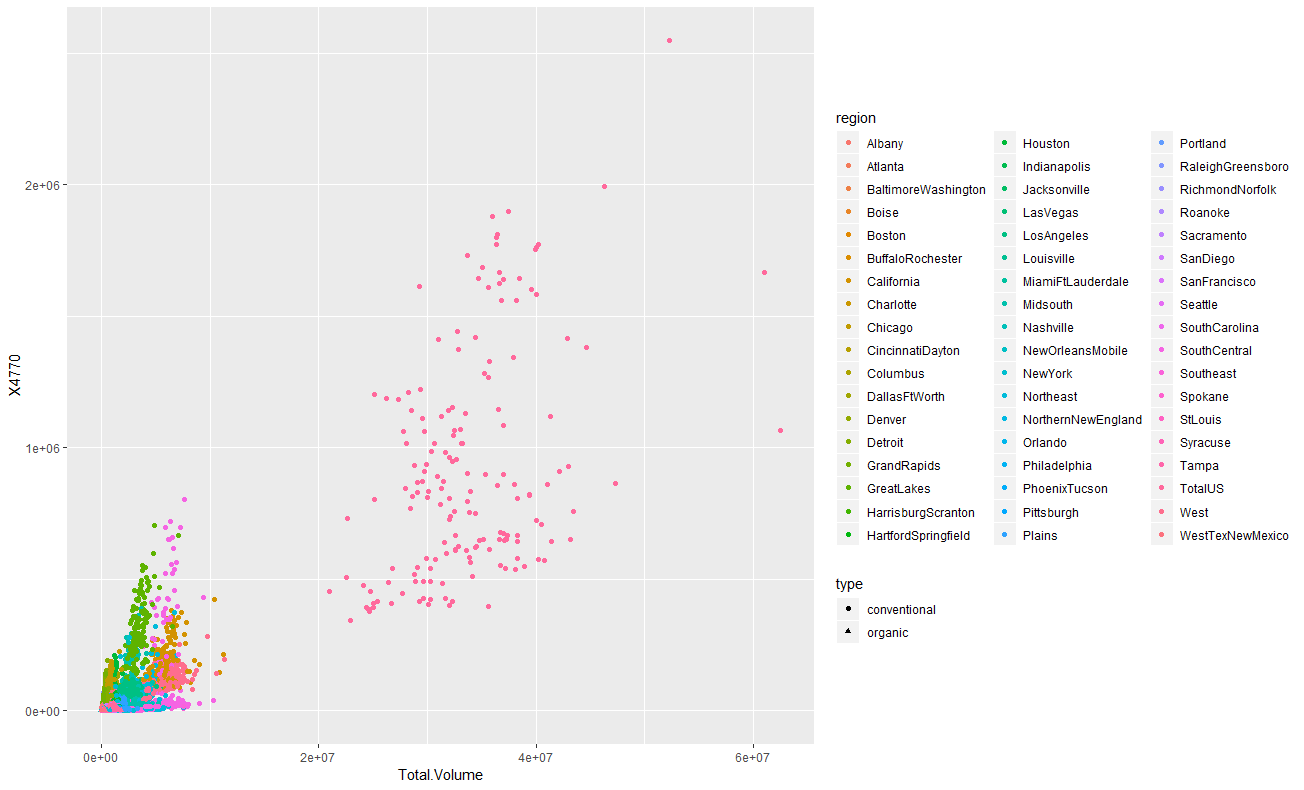
geom_pointで散布図を描画します。横軸はTotal.Volumeで縦軸は4046と4225と4770です。regionで色付けしてみると、TotalUSという区分の
データが広範囲に渡って散らばっています。4046と4225はなんとなく相関がありそうな形をしていますね。
今度はregionで色分けをせずに、3つのアボカドをプロットしてみます。
ggplot(df,aes(x=Total.Volume))+
geom_point(aes(y=X4225,color="X4046"))+
geom_point(aes(y=X4770,color="X4225"))+
geom_point(aes(y=X4770,color="X4770"))
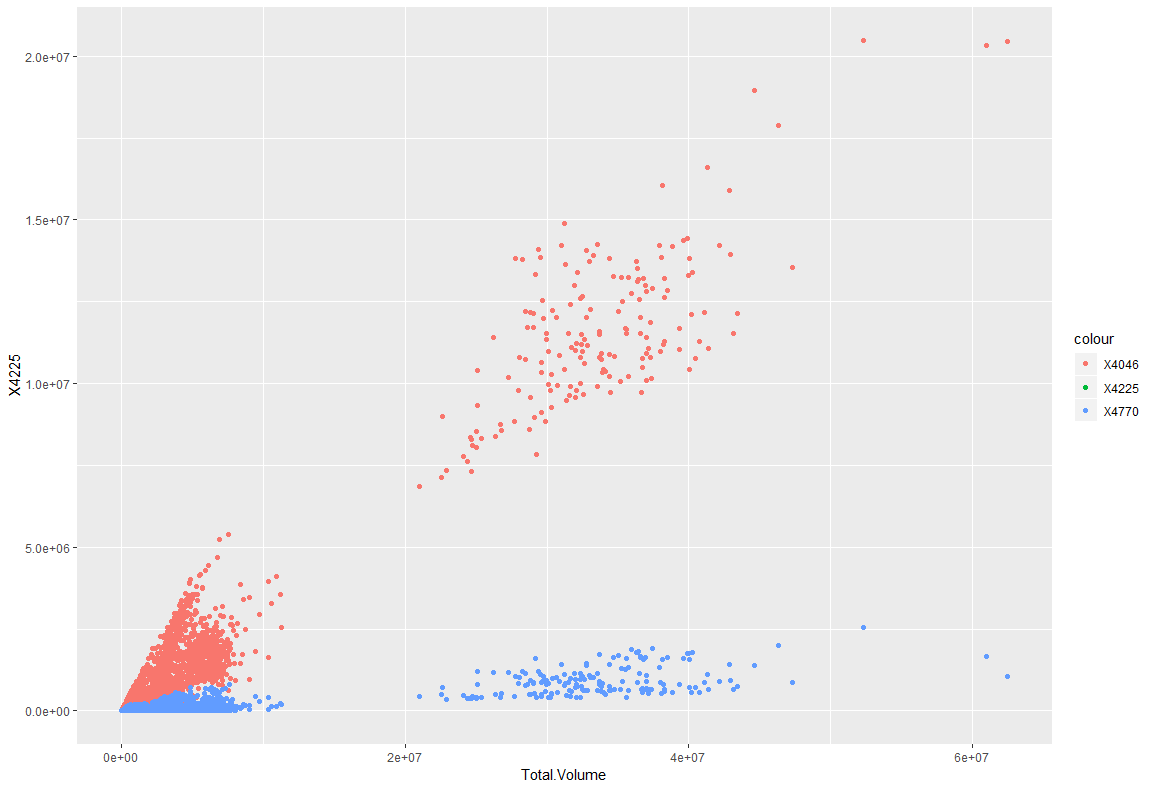
x軸を4046,4225,4225のTotal.Volumeとし、y軸を4046,4225,4225として描画した結果、最もTotal.Volumeに影響しているのは4046ということがわかりました。4225が見えないのは、データの値がかなり小さいため、表示できていないだけだと考えられます。
ヒストグラム
横軸をAveragePriceにし、ヒストグラムを描画してみました。
ggplot(df,aes(x=AveragePrice,fill=type))+
geom_histogram(position="dodge")+
geom_density(alpha=0.5)+
geom_vline(xintercept=mean(df$AveragePrice),linetype=1)
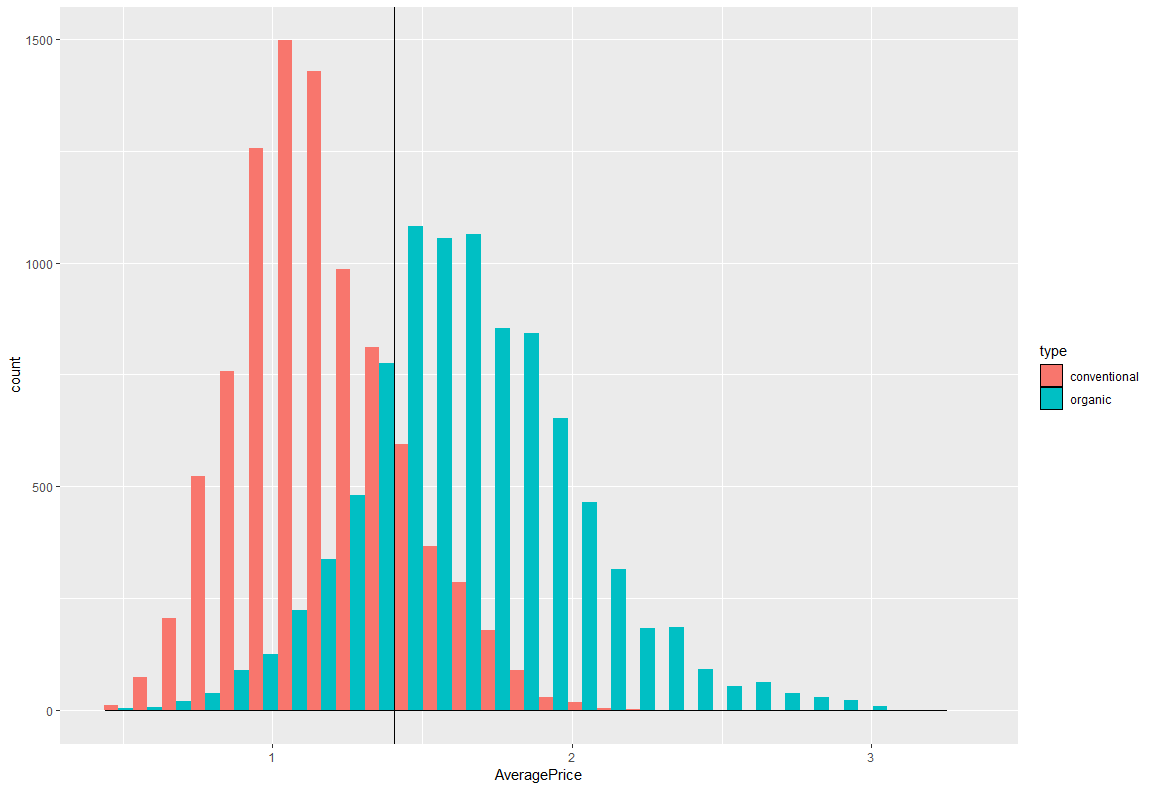
最初に書いたとおり、organicの高いですね。
ただ、これじゃあ少し見にくいので、確率密度分布に変更してみます。
ggplot(df,aes(x=AveragePrice,y=..density..,fill=type))+
geom_histogram(position="dodge")+
geom_density(alpha=0.5)+
geom_vline(xintercept=mean(df$AveragePrice),linetype=1)
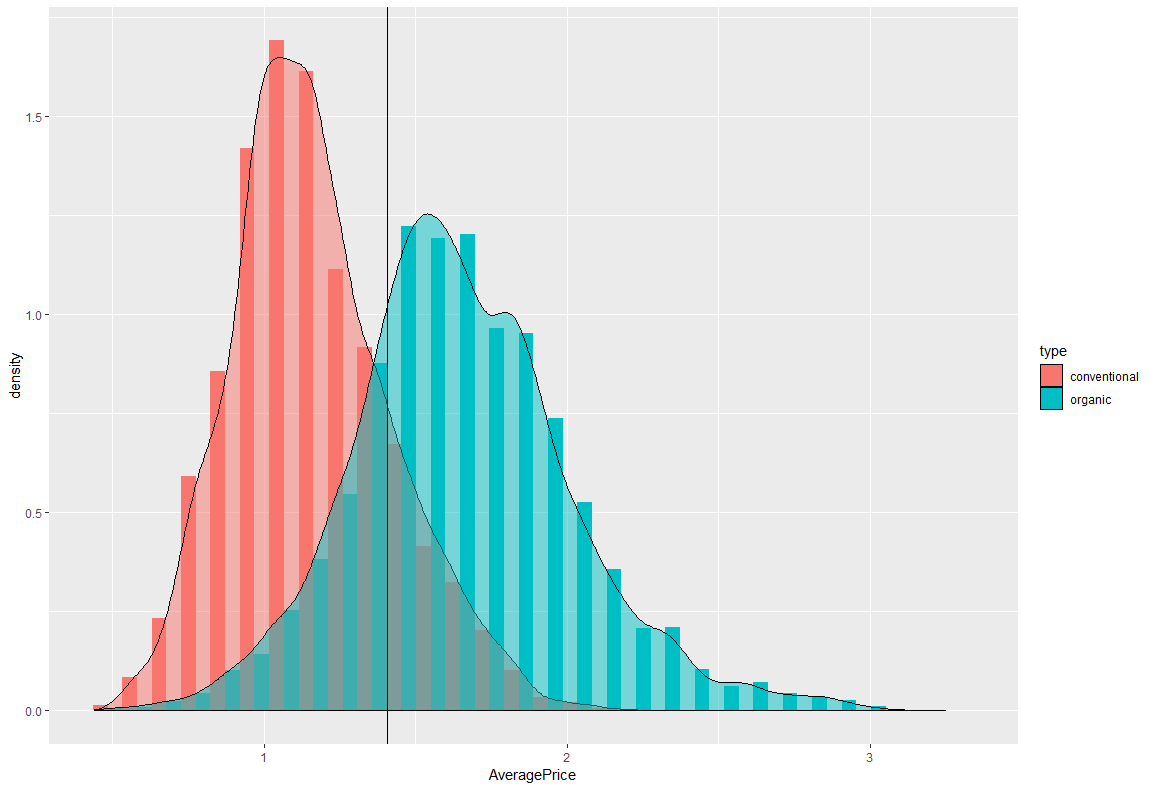
少し見やすくなりました。また、縦棒の線はAveragePriceの平均線です。ちょうど山と山の間に線があるのは面白いですね。価格調整などしているのでしょうか。
線グラフ
時系列のグラフです。
まず、POSIXct型に変更する必要があります。
df$Date <- as.POSIXct(df$Date)
ggplot(df,aes(x=Date,y=AveragePrice,colour=type))+
geom_line()+
#なぜかdate_breaksでエラーがおきるため、コメントアウト
#scale_x_datetime(breaks=date_breaks("100 days"))
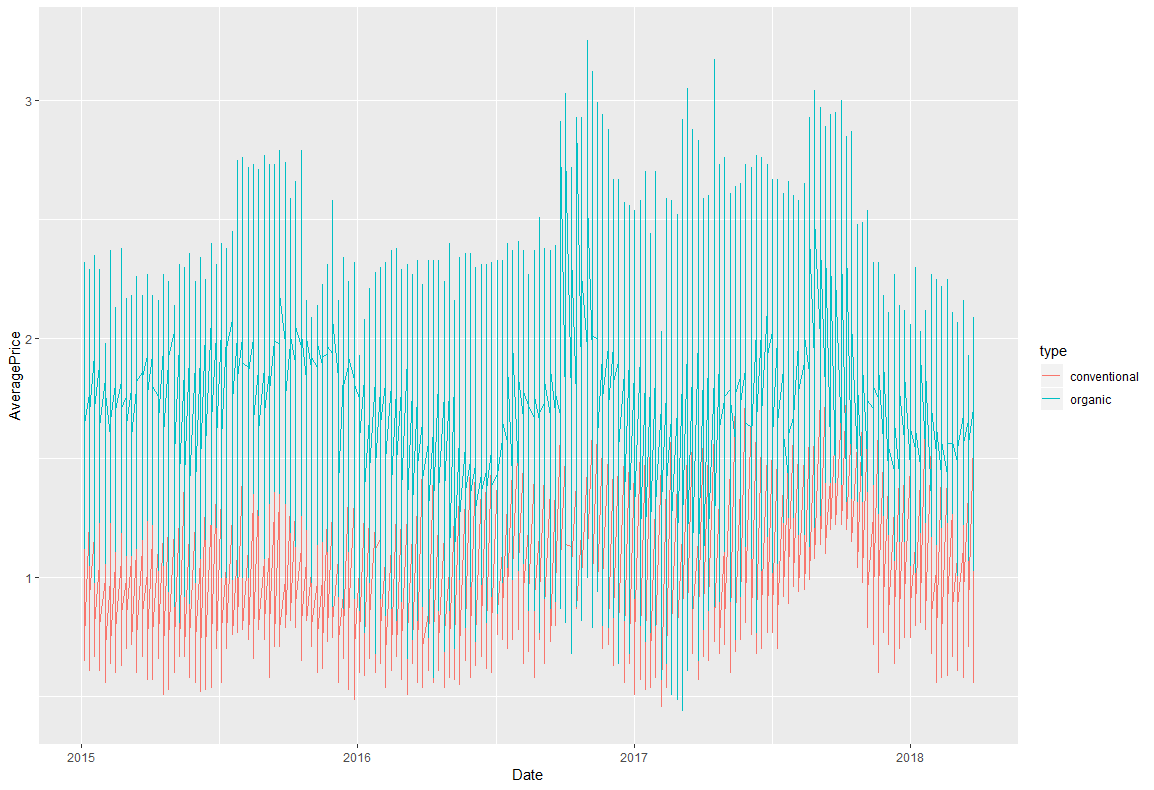
全体的な傾向としても、organicがずっと高いですね。
2017年の後半にconventionalが急激に高くなっているのが気になります。
棒グラフ
年ごとの分布を見てみました。単なるカウント値をみています。
ggplot(df,aes(x=year))+
geom_bar()
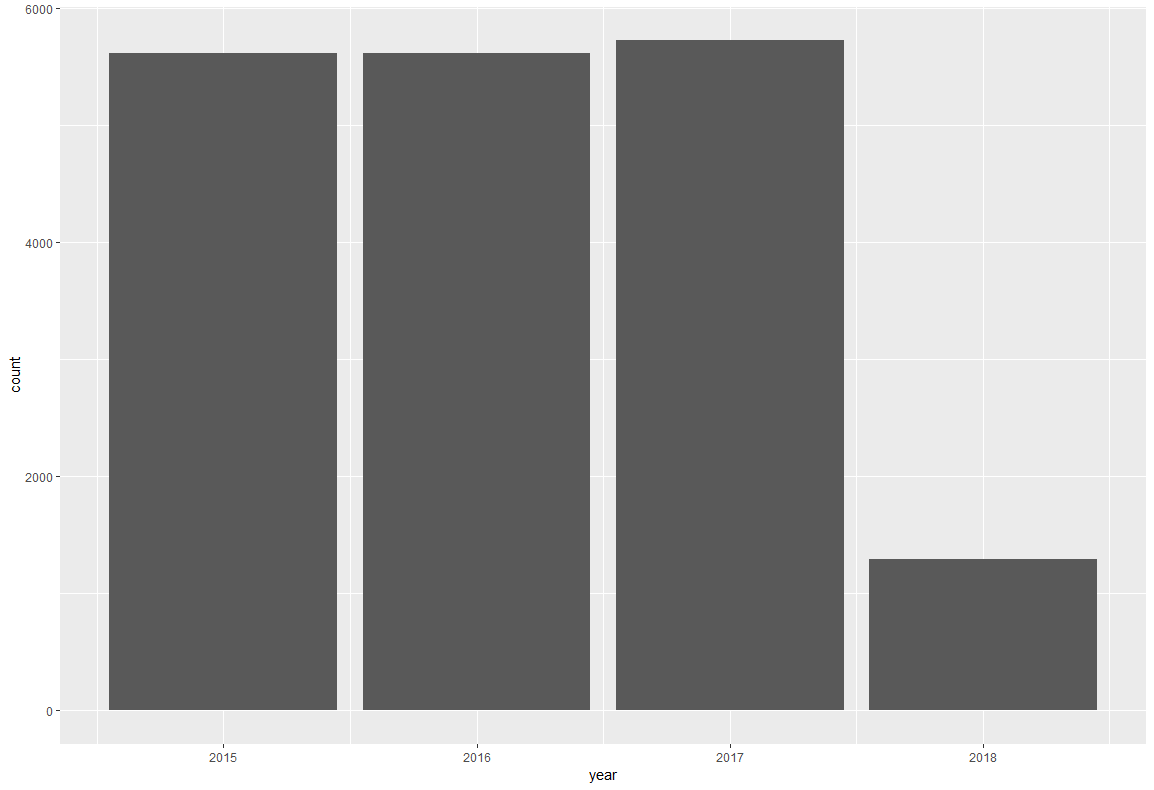
2018年のデータはほとんどないことがわかりました。
こうやって並べてみると、かなりわかりやすいですね。
次はカウント値ではなく、AveragePriceを年ごとに見ました。さらに、各年の平均値を予め計算しておき、平均値以下のところは色を変更しました。
ggplot(df,aes(x=year,y=AveragePrice,fill=AveragePrice>=me))+
geom_bar(stat = "summary",fun.y = "mean")
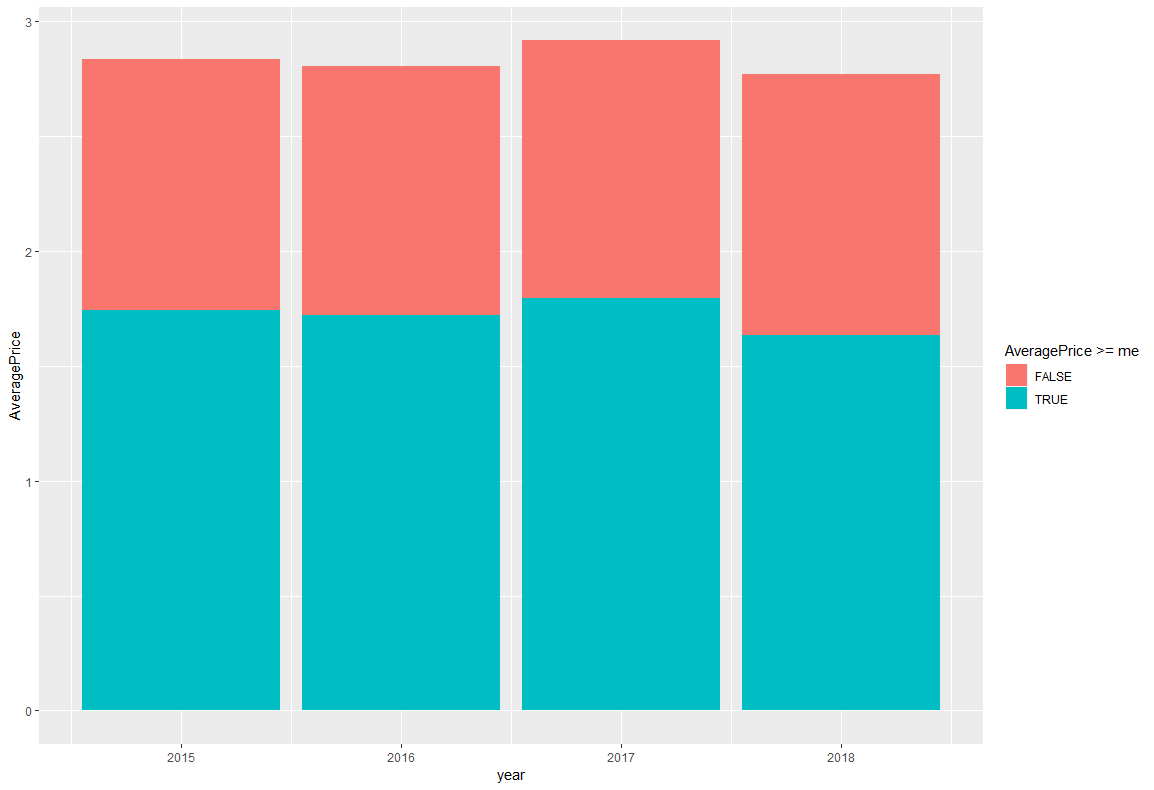
グリッド上に描画させています。前年比などを見る際には見やすそうですね。
ggplot(df,aes(x=type,y=Total.Volume))+
geom_bar(stat="summary",fun.y = "mean",aes(fill=type))+
facet_grid(. ~year)
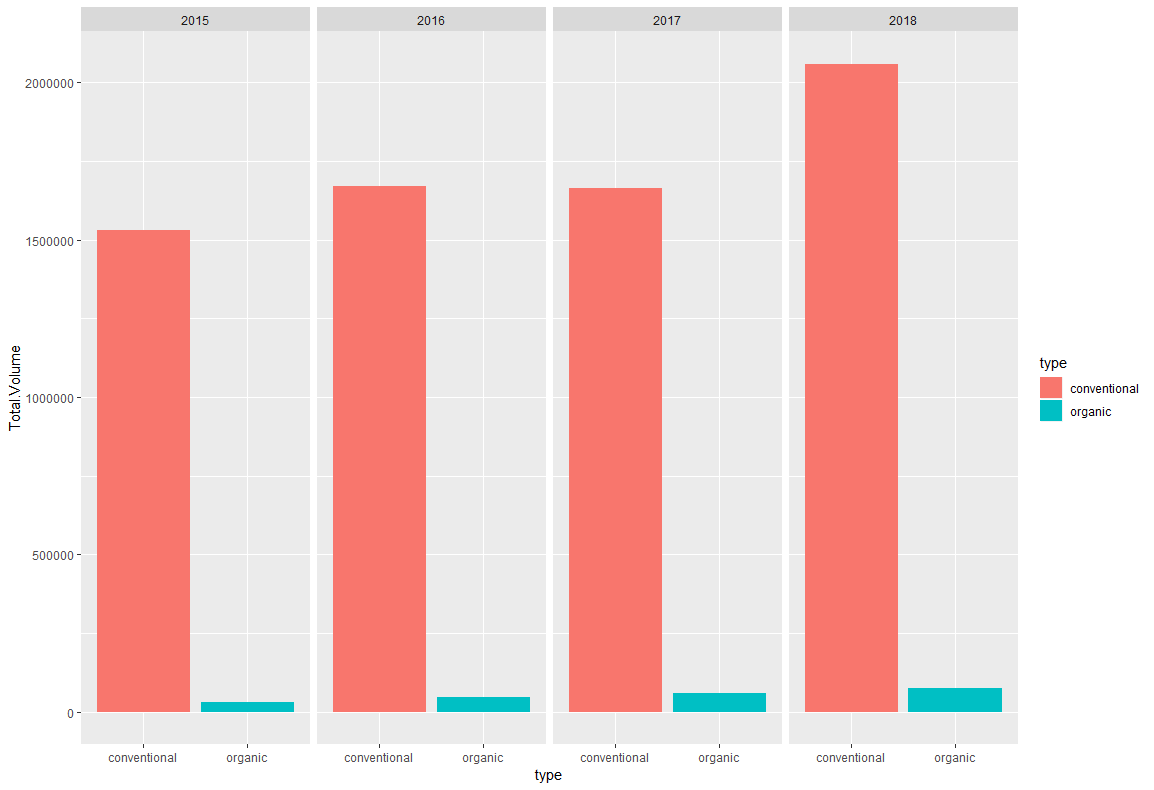
おわりに
まだまだ色々なグラフが書けそうです。他にもどのようなグラフが書けるのか引き続き調べてみたいなと思いました。
また、今回感じたのは、グラフを作成する際には自分の中で何らかの仮説がないと、ただ作るだけになってしまうと感じました。
なぜか可視化するのか、X軸y軸はどうするのか。グルーピング粒度はどうするのか。などなど、可視化をする前にやらなきゃいけないことが多くあります。
可視化という単なる”作業”に入る前に、まずは可視化するための整理をしっかりやろうと感じました。
参考サイト
http://motw.mods.jp/R/ggplot_geom_bar.html
https://mrunadon.github.io/images/geom_kazutanR.html