はじめに
非エンジニア職でも分析で荒れ地のような大量のcsvデータを捌かなければいけないときありますよね。私はあります![]()
下記のような住所の入力度合いが行により異なるCSVを、適するカテゴリに分類したい場面に遭遇したので、Pythonで自動分類した話を紹介します。

しかし今回の方法は完璧ではありません…。
ここまでの結果を投稿させて頂きつつ、今後も方法を模索して参ります。
イカれたCSVを紹介するぜ!
住所の番地以降が入力されているCSVで、
部屋番号まで入力されているものもあれば、建物名までや、
番地までの入力に留まるものもあり、しかも行によって建物名が別カラムに来る、
カオスなCSVが今日のゲストです(架空の住所となります)。
※戸建てはないものとして想定してください。

振り分け区分としては、
「号室まで」、「建物(マンション)名まで」、「番地まで」、「市区町村まで」としたいです。
以下が割り振った時の理想形です。
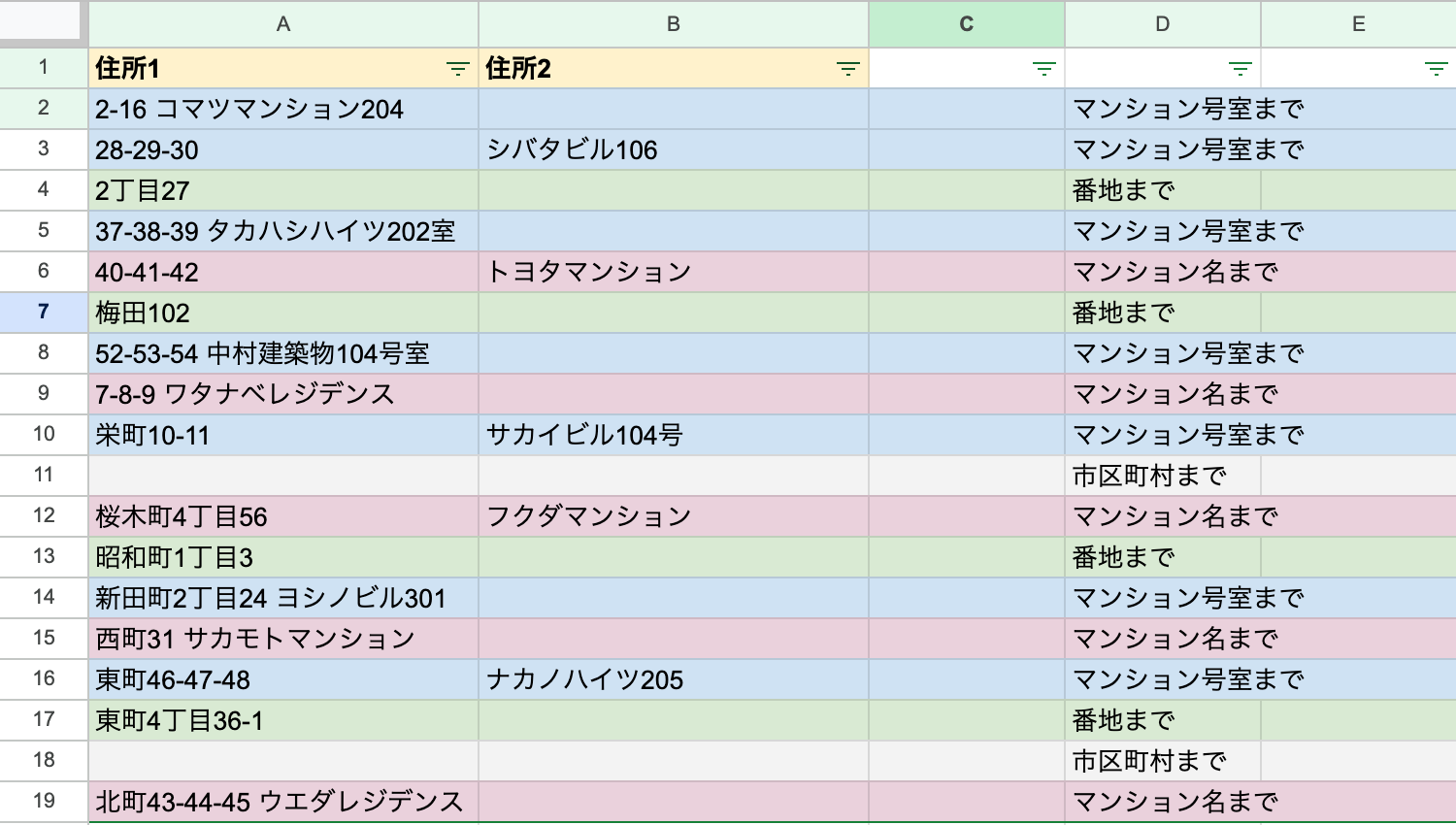
既に色による刺激で私の目がおかしくなりつつありますが、手作業は難しいのでPythonを使い自動判別していきます。
作業の事前準備
・[必須]Pythonのインストール
先人の参考記事
Pythonには主要なバージョンで「Python」と「Python3」が存在し、
同時にインストールすると複雑なことになるため片方のみが推奨です。
・[必須]必要ライブラリのインストール
コマンドプロンプトもしくはターミナルを開いて以下のコマンドを実行してください。
(Python3のコード例を記載)
pip3 install tkinter
・[推奨]VSCodeのインストール
先人の参考記事
必須ではないですが、メモ帳などに記載していくよりはこちらの方が快適です
完成品(サンプルコード)
※自由にコピペして活用して改変して使ってください。
# ライブラリのインポート
import csv
import re
import tkinter as tk
from tkinter import filedialog
# ファイル選択ダイアログを開く
root = tk.Tk()
root.withdraw()
file_path = filedialog.askopenfilename()
# 住所の区分を判定する関数
def classify_address(address: str) -> str:
# 値が空の場合は市区町村までの入力とする
if address is None or not address:
return "市区町村まで"
# 最後が"号"または"室"の場合、もしくは最終文字が3〜4桁の数字であり、直前が指定の文字列以外の場合は号室までの入力とする
elif re.search(r'(室|号)$|[^番地|町|丁目|ー|-]\d{3,4}$', address):
return "号室まで入力"
# 最後に数字以外の入力がある場合は建物名まで入力とする
elif re.search(r'\d+[^番地|町|丁目|ー|-]+\D$', address):
return "建物名まで入力"
# 入力した内容に数字が含まれている場合は番地までの入力とする
elif re.search(r'\d', address):
return "番地まで入力"
# 住所が空でない場合は分類不可とする
else:
return "分類不可"
# 区分ごとに辞書を用意する
classified_addresses = {
"市区町村まで": [],
"号室まで入力": [],
"建物名まで入力": [],
"番地まで入力": [],
"分類不可": []
}
# CSVファイルを読み込む
with open(file_path, "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
# 住所2が空の場合は住所1を参照する
if not row["住所2"] or not row["住所2"].strip():
address = row["住所1"]
else:
address = row["住所2"]
# 住所を区分する
classified_address = classify_address(address)
# 区分ごとにリストに追加する
classified_addresses[classified_address].append(row)
# 区分ごとにファイルを保存する
for key, value in classified_addresses.items():
if value:
with open(f"{key}.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.DictWriter(f, fieldnames=reader.fieldnames)
writer.writeheader()
writer.writerows(value)
挙動・解説
コンソールからファイルのあるディレクトリで、python3 [ファイル名]で実行してください(Python3系の場合)
python3 address_classifier.py
すると、ファイルダイアログが開きますので対象のCSVを選択します。
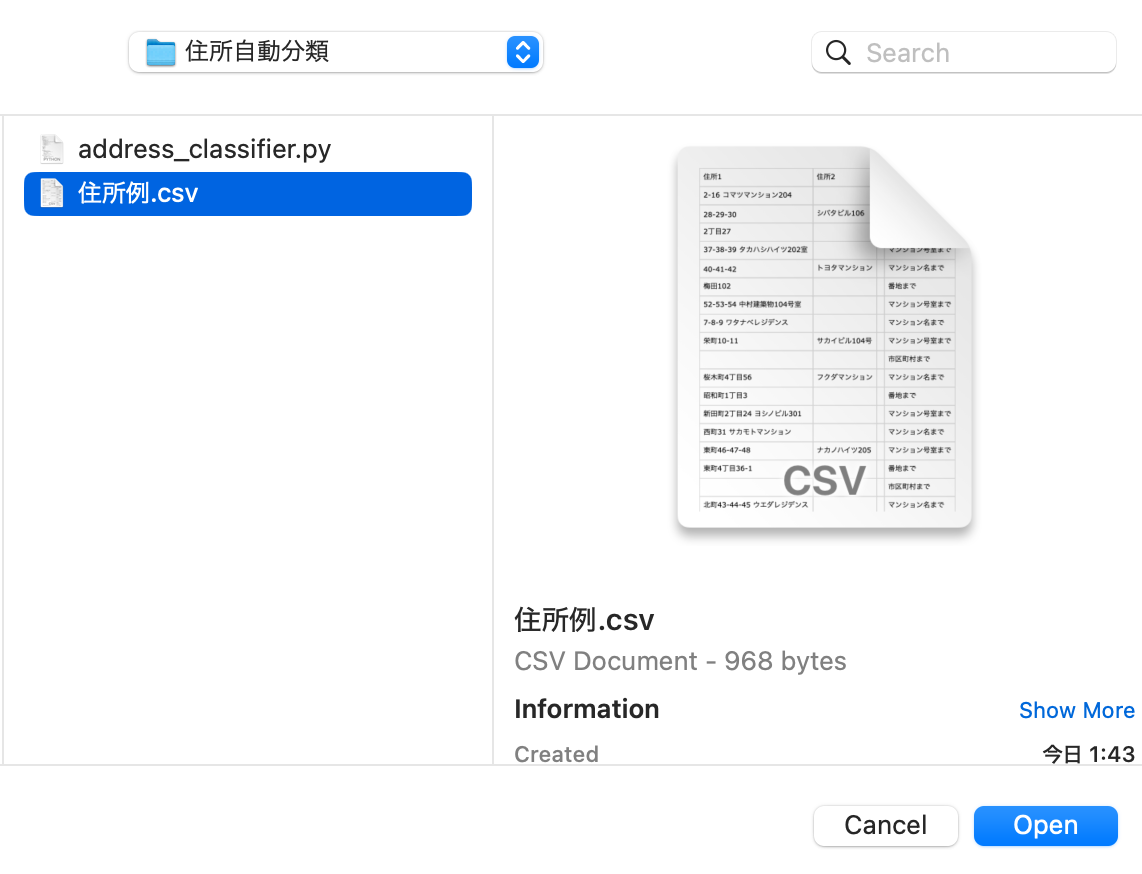
一瞬でCSVファイルがそれぞれの区分別で生成されます。
生成されたCSV「号室まで入力」を開いてみると、
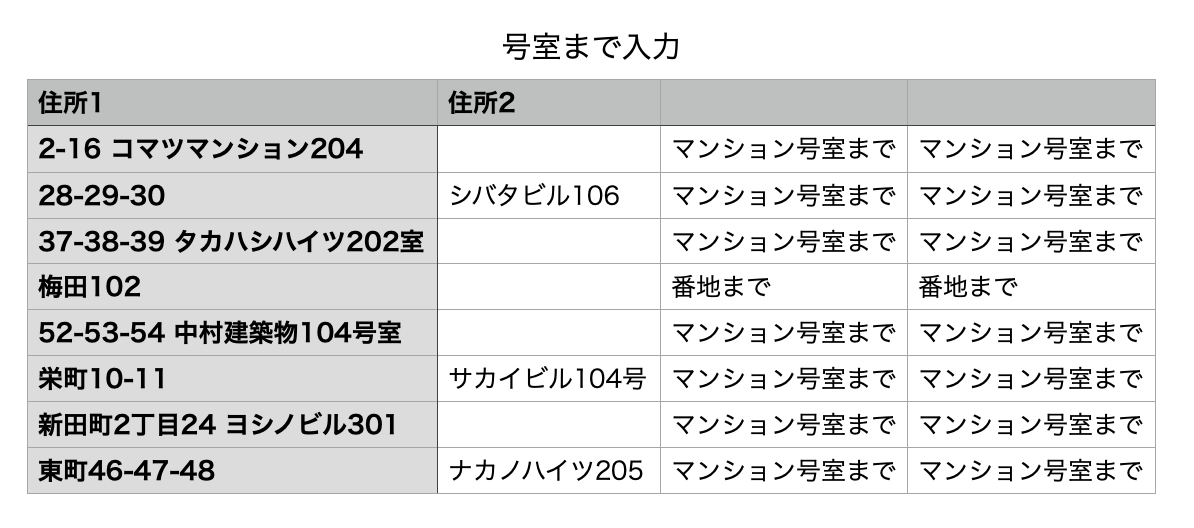
ん〜?おおよそはいいものの、[番地まで入力]に分類されるべきものがいますね…。
では何故こうなるのか振り分けロジックを解説いたします。
振り分けロジック
上から優先順位をつけて割り振っており、一度割り振られるとその行はそこで確定となります。
① 市区町村まで
今回は番地以降の入力ですので住所1と2のどちらにも入力がないものが振り分けられます。
if address is None or not address:
return "市区町村まで"
② 号室まで入力
建物名が部屋番号まであるものが対象となります。
"101号"や"102号室"など、最後が"室"や"号"のものは部屋番号の可能性が高いため対象とし、
"101"や"1012"など、3〜4桁の数字で終わっている場合も部屋番号の可能性が高いのですが、
番地の可能性もあるので、数字の直前に[番地],[町],[丁目],[-]の存在しない場合に限定しています。
が、ここが落とし穴で"梅田102"など地名のあとにすぐ3〜4桁の数字が来る場合、ここに割り振られてしまう訳ですね…(しかし、建物名と被らない前提で地名を指定できない)。
elif re.search(r'(室|号)$|[^番地|町|丁目|ー|-]\d{3,4}$', address):
return "号室まで入力"
③ 建物名まで入力
号室で引っかからなかったものなので、最後が数字ではない文字がある場合が対象です。
ただし、念の為、どこかには数字も存在する場合に限定しています。
(「○○区」だけと言ったイレギュラーに備えて)
elif re.search(r'\d+[^番地|町|丁目|ー|-]+\D$', address):
return "建物名まで入力"
④ 番地まで入力
いずこかに数字があれば対象とします。
elif re.search(r'\d', address):
return "番地まで入力"
⑤ 分類不可
ここまでどこにも当てはまらなかったものは分類不可としています。
(このようにどこかに割り振らないと万が一残った際にエラーを起こす)
else:
return "分類不可"
おわりに
正規表現とelifを組み合わせてのカテゴライズや一瞬での処理に便利さを感じた一方、
日本の住所に対しては一筋縄でいかない複雑さを感じました![]()
とは言えデータ分析をしようと思っても綺麗な状態のデータが出てくることは稀なので、
こういったtipsを溜めていき、データ準備の前段階を効率化して行きたいと思います![]()
参考
▼正規表現 — Pythonオンライン学習サービス PyQ(パイキュー)ドキュメント
https://docs.pyq.jp/python/library/re.html
▼[Python]正規表現のみで住所を「都道府県/市区町村/その他」に分割する方法
https://magicode.io/bitcoinkubera/articles/a6f0f69b77fb48239093af0af8f36974