はじめに
この記事は自分自身の勉強がてら書いています。そのため暖かく見守っていただき、またご指導願えればと思います。勉強ということで今流行りのデータ解析でしょ!ってことで
「気象庁に落ちてある過去の気象データを用いてデータ的に天気を予測」
って自分なりに目標を立ててみました。
え?すでにその技術は確立されてるって?
そんなことは知りません、自分のアウトプットが目的ですから・・・
目標
・各地点の計測データを用いて、ある地点の天気を予測する。 ・多変量LSTMの勉強 ・データ解析の勉強 ・Pythonの勉強CSVデータの準備
気象庁からデータを入手します。APIが準備されていれば良かったのですが、無いためぐぐったらダウンロードのためのスクリプトが出てきたのでこちらを参考にデータをダウンロードしました。
データとしては2007年1月1日から2016年12月31日までの6時間毎の「気温・降水量・雲量・気圧」の4つの数値です。
6時間毎としたのは「雲量」だけがどうやら6時間毎で取得されているためです。

最終的にこんなかんじのCSVデータを作成しました。データは神戸のものを使っています。上から「気温・降水量・雲量・気圧」です。 途中で切れていますが、実際は1要素16072個×4=64288個ほどデータがあります。
全部で「稚内、仙台、東京、神戸、下関、鹿児島、那覇」の7つの地点のデータを準備しました。
ディープラーニングを行うための準備
PC環境
・macOS HighSierra 10.13.1
・Macbook 1.4Ghz Core i7 RAM 16GB
開発環境
・python3
・PyCharm professional
・Project interpreter→anaconda3
使用ライブラリ
・keras(バックエンドはtensor-flow)
・numpy
必要なライブラリはanacondaに入れてます。
それぞれの導入記事はqiitaにいっぱいありますし、そちらを参照にするほうが質がいいと思いますので探してみてください。
データの形成とCSVの読み込み
ここが一番めんどくさいかもしれません。 世間様が思っているほど今の時点ではディープラーニングは優秀ではなく、きちんとディープラーニングが学習できるデータを形成してあげなければなりません。 そのまま生のデータを渡しても恐らく何も学習しませんので。 もしかしたら5年後には生のデータをそのまま渡してもきちんと学習しているかもしれませんが、、、5てか年後化にはそうなっていることを祈ります。先に概要だけ図で紹介しておきます。

入力と出力に関しては上の図のような感じです。
こんな感じにスライスしていく事により、時系列データを作成します。
また、各0時や6時の中には、
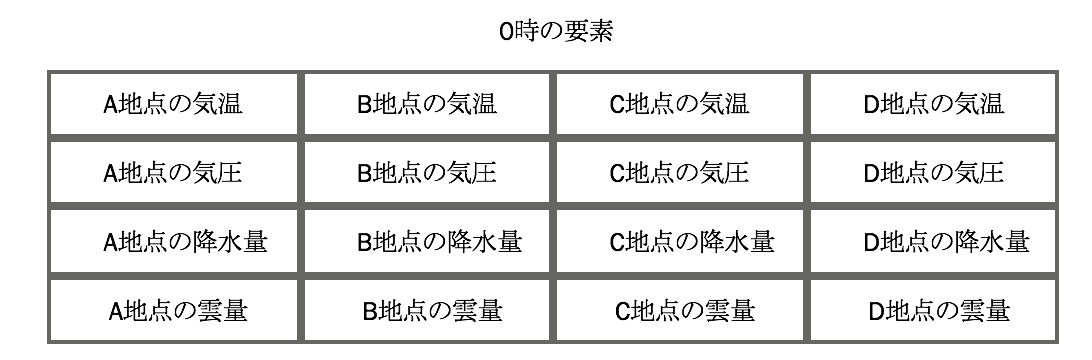
各地点の気温や降水量などの入ったデータを形成しておきます。
csvファイルを読み込んで、上の図たちのようなデータを形成します。
ではここからコードで解説していきます。
import csv
import glob
dir = '/*.csv' #CSVファイルのあるディレクトリパス
path = [file_path for file_path in glob.glob(dir)] #各CSVへのパスの入ったリスト
まずはcsvファイルの入ったフォルダのパスからフォルダ内に存在するすべてのcsvファイルを読み込みます。
全てのcsvファイルを読み込みますので、関係ないcsvファイルは別のところへ移動しておいてください。
# CSVファイルから要素ごとのリストに入れ直す
kion = []
rain = []
unryo = []
kiatu =[]
# 時間ごとのデータを作成するためのリスト
pre_x = []
各リストを宣言しておきます。正直、ここからさきはもっと良いコードができると思います、、、笑
# CSVファイルを読み込んでいき、とりあえず要素のリストへ放り込む。
for filename in path:
csv_file = open(filename, "r", encoding="ms932", errors="", newline="")
f = csv.reader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"',
skipinitialspace=True)
print(filename)
count = 0
for i in f:
for j in i:
if(count == 0):
kion.append(j)
if(count == 1):
rain.append(j)
if(count ==2):
unryo.append(j)
if(count == 3):
kiatu.append(j)
counter = counter +1
count = count + 1
予めリストに入れていた各csvへのpathをfor文で読み込みながらcsvファイルを開きます。
csvファイルは「気温,降水量,雲量,気圧,気温,降水量,雲量,気圧,......]のような形になっているので、とりあえず各要素ごとに上で宣言したリストに入れていきます。
ここではcountで0番目、4番目、8番目は気温リストへ。1番目、5番目、9番目は降水量リストへ。って感じにしてます。
このままでは気温とかの要素が
[A地点の気温のデータ、B地点の気温のデータ、C地点の気温のデータ]
と時間的な順番ではなく、単に連結しているだけなので
これを
[A地点の0時の気温,B地点の0時の気温,C地点の0時の気温],[A地点の1時の気温,B地点の1時の気温,C地点の1時の気温]
と時間ごとに並べます。
if(len(kion)==len(rain)==len(unryo)==len(kiatu)):
length = len(kion)//len(path)
for h in range(length):
tmp1 = []
tmp = kion[h::length]
tmp1.append(tmp)
tmp = rain[h::length]
tmp1.append(tmp)
tmp = unryo[h::length]
tmp1.append(tmp)
tmp = kiatu[h::length]
tmp1.append(tmp)
pre_x.append(tmp1)
else:
print("length of list is different ")
csvデータが正しければ各要素(気温とか降水量とか)ごとのリストの長さは正しいのでチェックする必要はありませんが一応if文で確認しておきます。
length = len(kion)//len(path)
である1地点での気温とかの要素のデータの個数を求めます。
ぶっちゃけここで求めなくても、もうちょい上のコードで求めてもいい気がしますが。
つまり今は、全ての地点での要素のデータが連結してしまっているので、1地点での要素の個数の間隔で、新たなリストを作成すると
[A地点の0時の気温,B地点の0時の気温,C地点の0時の気温],[A地点の1時の気温,B地点の1時の気温,C地点の1時の気温]
ってなるよねって話です。
このまま時系列データを作成してLSTMに読み込ませたかったんですが、Keras の LSTM入力データは、 [サンプル数, time steps, 特徴量の数]の形式の三次元配列として渡す必要があるらしいので、
[Aの0時の気温,Aの0時の降水量,Aの0時の雲量,Aの0時の気圧,Bの0時の気温,Bの0時の降水量,Bの0時の雲量,Bの0時の気圧,・・・・・]
のように一括に纏めました。
7地点のデータを用意したので7地点×4要素=28の特徴量を持つデータを作成してやります。
時系列データの作成に移ります。
for i in range(len(pre_x)-4-1):
a = pre_x[i:i+4]
data_x.append(a)
data_y.append(pre_x[i+4])
これで上で示した図のような時系列の完成です。
data_x[1][3]とdata_y[0]が同じ値を示していれば大丈夫です。(yデータは次の日の時間のデータの為)
このソースコード中の4というのは1日の24時間から6時間毎にデータを取得しているため24÷6=4の4です。
LSTMのモデル作り
モデルを作っていきます。 その前にkerasのLSTMはnumpy形式を入力と出力とするので上で作った時系列データを変換します。
trainX = np.array(data_x)
trainY = np.array(data_y)
kerasのモデルづくりは簡単です
model = Sequential()
model.add(LSTM(28,input_shape=(4,28),return_sequences=True))
model.add(Dense(28))
model.add(Dense(28))
model.compile(loss='mean_squared_error', optimizer='adam')
層を積み重ねるっていうイメージですね。
ここでinput_shapeには
input_shape=time_step(時系列データのときのずらした量)、特徴量
という感じにモデルに教えてあげます。
損失関数には平均二乗誤差(mean_squared_error)を使いました。
model.add(Dense(28))
model.add(Dense(28))
と2層重ねたのは1回だけだと思ったようには損失関数の値が落ちなかったためです。
何層も重ねたらもっといい感じに学習するのかも・・・?
学習
model.fit(trainX, trainY, epochs=300, batch_size=15, verbose=1)
model.save('model.h5')
epochsとbatch_sizeに関しては適当にしているだけなので、もっと良い値があると思います。
実際300もエポックを回す前に損失関数の値は収束してました。
Epoch 3/300
15/16062 [..............................] - ETA: 30s - loss: 29.5792
60/16062 [..............................] - ETA: 27s - loss: 23.2120
105/16062 [..............................] - ETA: 25s - loss: 20.6139
135/16062 [..............................] - ETA: 26s - loss: 21.1341
180/16062 [..............................] - ETA: 25s - loss: 20.2873
210/16062 [..............................] - ETA: 26s - loss: 20.6040
一部ですがこんな感じに学習しています。
結果
鹿児島の2017年1月の実際の気温データを6時間毎にプロット その気温データを予測しようとしたもの
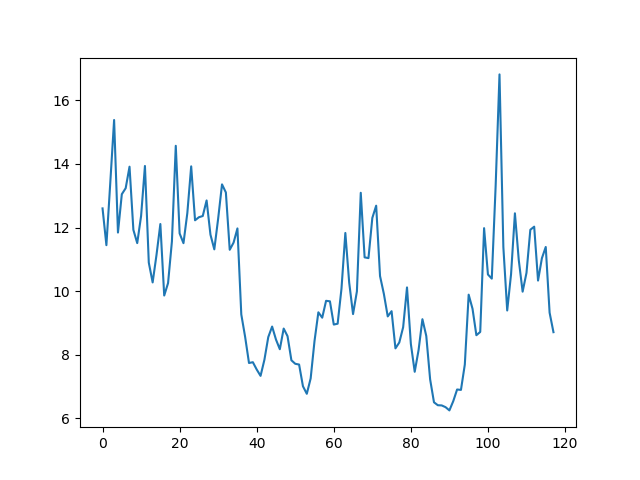
こんな感じの結果となりました。x軸の65ぐらい見てもらえればなんとなくそれっぽい予測が出来ているような気もしないような。
実データがx軸1進むだけでy軸が激しく上下しているのが予測データは少しましになった?6時間ごとに取得しているから気温は予測難しいのかなと思ったり...
1時間毎の予測だとどうなるか試してみたいところです。
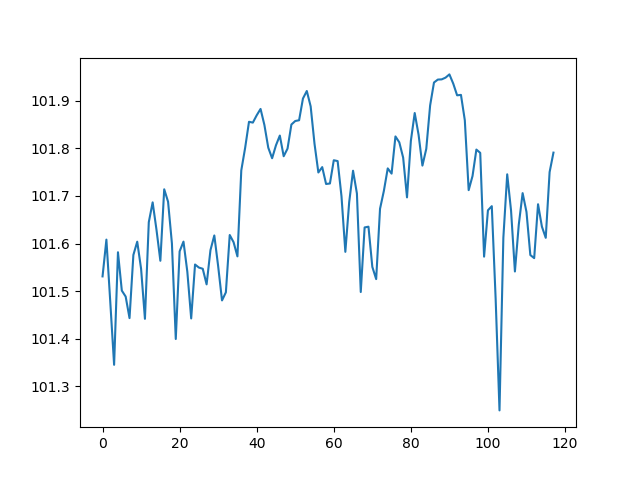
いやいや、これは気温だからだろ!って気圧の予測を見てみると、
鹿児島の気圧データ
値は10で割ってます
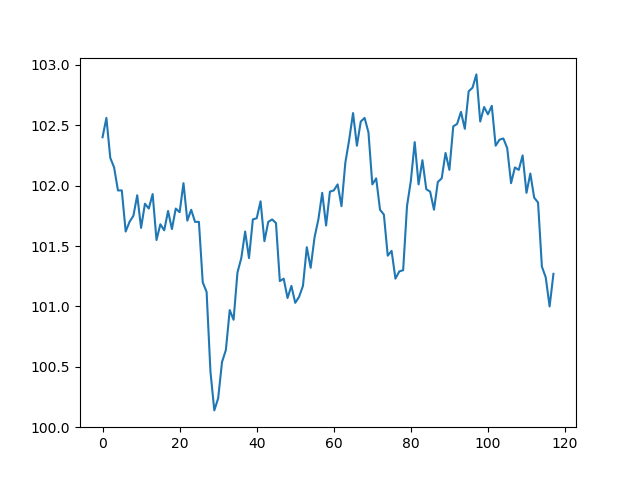
こっちが予測データ
反省
実用に耐え難き、てか全く予測できてない気もします。原因①:
データの作り方が悪かった、なんたって28の特徴量を読み込んで28の特徴量の予測。もっと全部を予測するのではなく、28の特徴量を読み込んで1特徴量のみ予測すれば精度はあがるかも?
原因②:
データの正規化してない、気圧は流石に大きすぎるから10で割ったけど、他の値は特に何もなしでそのまま突っ込んでいる。
原因③:
x入力データやy出力データ(ラベルデータ)を作成するときのtime_stepというかずらし方がまずかった?
あとがき
予測結果は散々でしたが、このプログラム書くために色々とLSTMやらデータの形成やら勉強したり、pythonのコード自体も書くことが苦ではなくなってきたのは良かったかと。また時間があればリベンジしてみたい題材ですね。
ここはこうするべきなんやで、とかここの考え方はこうやでとかあれば遠慮なくコメント頂ければと思います。