初心者に向けるTiDBの学習メニュー
[初心者に向けるTiDBの学習 ~ストレージ編 第1回~] (https://qiita.com/it2911/items/a676bb6a63b07e865558)
初心者に向けるTiDBの学習 ~ストレージ編 第2回~ <- 今ここ
初心者に向けるTiDBの学習 ~ストレージ編 第3回~
初心者に向けるTiDBの学習 ~コンピューティング編 第1回~
初心者に向けるTiDBの学習 ~コンピューティング編 第2回~
初心者に向けるTiDBの学習 ~スケジューリング編~

前回初心者に向けるTiDBの学習 ~ストレージ編 第1回~でデータの格納及びキーバリューを説明しました。今回RocksDB、Raftとリージョンを紹介させていただきます。
RocksDB
持続性のあるストレージエンジンはデータをディスクに格納します。TiKVも例外ではありません。しかし、TiKVがディスクに直接データを書き込むことはありません。最初にTiKVがRocksDBにデータを格納し、RocksDBがデータストレージを行います。このような方法を採っているのは、スタンドアロンのストレージエンジン(特に高パフォーマンスのスタンドアロンエンジン)の開発は相当コストがかかるためです。さまざまな最適化処理に迫られるのです。
PingCAP社はRocksDBが要件をすべて満たす非常に優れたオープンソース・スタンドアロンストレージエンジンであることに気付きました。Facebookチームがこのエンジンの最適化に取り組んでいる間、PingCAP社はさほど手間をかけることなく、改良が進む強力なスタンドアロンエンジンを享受できるというメリットもありす。もちろん、PingCAP社もRocksDBに対して若干のコード提供は行っていますが。このプロジェクトのさらなる改善が期待されます。一言で言うと、RocksDBはスタンドアロンのキーバリューマップと見なすことができます。
Raft
この複合プロジェクトの最初の重要ステップは、信頼性の高い効果的なローカルストレージソリューションを見つけることでしたね。次は、1台のマシンが停止する場合のデータの完全性と正確性をいかにして保護するかという比較的難解な課題です。効果的なのは、データを複数台のマシンに複製するという方法です。
そうすれば、1台のマシンがクラッシュした場合、他のマシン上のレプリカを使用できます。ただし、複製ソリューションは、無効なレプリカが存在する状況に対応できる、信頼性が高く効果的なものでなければなりません。難しそうですが、Raftを利用すれば実現できます。Raftは、Paxosよりも理解しやすい、Paxosと同等のコンセンサスアルゴリズムです。Raftに興味がある方は、Raftの論文を読んでくださいで詳細を参照できます。この外部Raftレポートは基本的なソリューションを提示しているだけであり、このレポートに厳密に従うとパフォーマンスは低いものとなることを指摘しておきます。PingCAPは、Raftを実装するためにさまざまな最適化を行いました。
Raftはコンセンサスアルゴリズムであり、次に示す3つの重要機能があります。
- リーダー選出
- メンバーシップ変更
- ログ複製
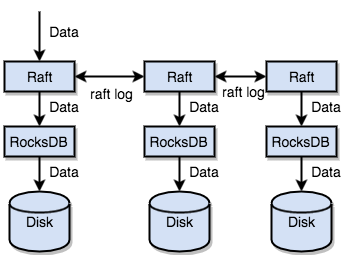
TiKVは、Raftを使用してデータを複製します。各データ変更は、Raftログとして記録されます。データは、Raftのログ複製機能を通じて、安全かつ確実にRaftグループの複数のノードと同期されます。
要約すると、スタンドアロンRocksDBを使用すると、データを迅速にディスクに格納できます。Raftを使用すると、マシン障害に備えて複数のマシンにデータを複製できます。データは、RocksDBに対してではなく、Raftのインタフェースを介して書き込まれます。Raft実装のおかげで分散型のキーバリューシステムを利用できるようになり、今ではマシンの障害について心配する必要がありません。
リージョン
このセクションでは、きわめて重要な概念「リージョン」について紹介します。リージョンは、一連のメカニズムを理解するうえでの基盤となるものです。この概念について考察する前に、Raftのことは忘れて、あらゆるデータにレプリカが1つしかないという状況を想像してみましょう。
前述したように、TiKVは順序付けられた巨大なキーバリューマップと見なすことができます。ストレージの水平方向の拡張性を実現するには、複数のマシンにデータを分散させる必要があります。
キーバリューシステムには、複数のマシンにデータを分散させる典型的なソリューションが2つ存在します。1つは、ハッシュを作成し、ハッシュ値に基づいて対応するストレージノードを選択するというソリューションです。もう1つは、範囲を使用し、シリアルキーのセグメントをストレージノードに格納するというソリューションです。TiKVは、2つ目のソリューションを選択し、キーバリュースペース全体を多数のセグメントに分割しました。各セグメントは、隣接する一連のキーから構成されます。このようなセグメントを当社は「リージョン」と呼んでいます。各リージョンが格納できるデータのサイズには上限があります(デフォルト値は64MBで、このサイズは設定可能)。各リージョンは、左閉右開区間(StartKeyからEndKeyまで)によって表現できます。
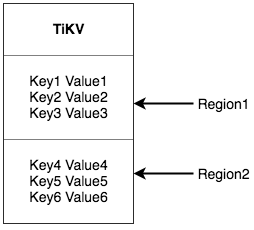
**今ここで話しているリージョンはSQLのテーブルとは何の関係もありませんよ!**今はSQLのことは忘れて、キーバリューに集中してくださいね。
データをリージョンに分割した後、次に示す2つの重要タスクを行います。
- クラスタ内のすべてのノードにデータを分散し、リージョンをデータ移動の基本単位として使用する。各ノードのリージョンの数がほぼ同じであることを確認する必要もあります。
- リージョンでRaftを介した複製とメンバーシップ管理を行う。
これらの2つのタスクは非常に重要であるため、1つずつ説明いたします。
最初のタスクでは、キーに基づいてデータが多数のリージョンに分割され、各リージョンのすべてのデータが1つのノードに格納されます。すべてのクラスタノードへのリージョンの均等分散は、当社システム内の1つのコンポーネントが担います。この結果、ストレージ容量の水平方向の拡張性が実現されます(新しいノードが追加されるときにシステムによって自動的に他のノード上にリージョンがスケジュールされる)。一方で、負荷分散も達成されます(つまり、1つのノードに多くのデータが配置され、他のノードにはわずかしか配置されないという状況が起きない)。同時に、上位のクライアントが必要データにアクセスできるようにするために、別のコンポーネントが複数ノードにわたるリージョンの分散を記録します。つまり、ユーザーはキーの正確なリージョンと、キーを介して配置されたそのリージョンのノードを照会できます。この2つのコンポーネントについては、後でさらに詳しく説明します。
2つ目のタスクに移りましょう。TiKVはリージョン内のデータを複製します。つまり、1つのリージョン内のデータには「Replica」という名前が付いた複数のレプリカが存在します。レプリカ間のデータの一貫性の達成にはRaftが使用されます。1つのリージョンの複数のレプリカが複数の異なるノードに保存され、それらがRaftグループを構成します。1つのレプリカがグループのリーダーとして機能し、他のレプリカがフォロワーになります。読み取りと書き込みはすべてリーダーを介して行われ、リーダーがフォロワーに複製します。
次の図は、リージョンとRaftグループの全体像を示しています。
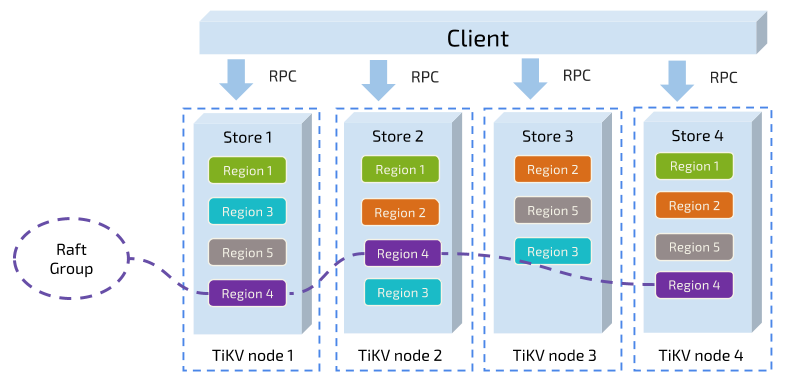
リージョンでデータの分散と複製を行うときには、ある程度のディザスタリカバリ能力を持つ分散型のキーバリューシステムを利用できます。今や、ユーザーは容量や、ディスク障害に起因するデータ消失問題に悩む必要はありません。これはすばらしいことですが、完璧ではありません。必要な機能が他にもあります。
今回はRocksDB、Raftとリージョンの概念を説明しました。次回は初心者に向けるTiDBの学習 ~ストレージ編 第3回~でMVCCとトランザクションを説明します。