初心者に向けるTiDBの学習メニュー
[初心者に向けるTiDBの学習 ~ストレージ編 第1回~] (https://qiita.com/it2911/items/a676bb6a63b07e865558)
初心者に向けるTiDBの学習 ~ストレージ編 第2回~
初心者に向けるTiDBの学習 ~ストレージ編 第3回~
初心者に向けるTiDBの学習 ~コンピューティング編 第1回~
初心者に向けるTiDBの学習 ~コンピューティング編 第2回~ <- 今ここ
初心者に向けるTiDBの学習 ~スケジューリング編~

前回初心者に向けるTiDBの学習 ~コンピューティング編 第1回~でリレーショナルモデルとKey-Valueモデルのマッピングを説明いたしました。今回はメタデータ管理及びSQLの実現方法を紹介させていただきます。
メタデータ管理
前節ではテーブルのデータやインデックスがKey-Valueにマッピングされる方法を説明しました。ここではメタデータの保存方法を紹介します。
データベースもテーブルも、その定義や様々な属性を示すメタデータを持っています。これらの情報はすべてTiKVに保存される必要があります。データベースやテーブルにはそれぞれ固有のIDが設定されており、このIDが固有の識別情報となります。Key-Valueにエンコードする際には、このIDをキーに、接頭辞としてm_をつけてエンコードします。このようにして、キーが生成され、対応するValueにはシリアル化されたメタデータが格納されます。
これとは別に、特殊なKey-Valueは、現在のスキーマ情報のバージョンが格納されています。TiDBは、Google F1のOnline Schema change algorithmを採用しています。バックグラウンドのスレッドが、TiKVに格納されているスキーマのバージョンが変更されたかどうかを常にチェックしています。変更があった場合は、一定期間内に更新情報を取得するように管理しています。
Key-Value型SQLのアーキテクチャ
以下の図は、TiDBの全体のアーキテクチャを示しています。
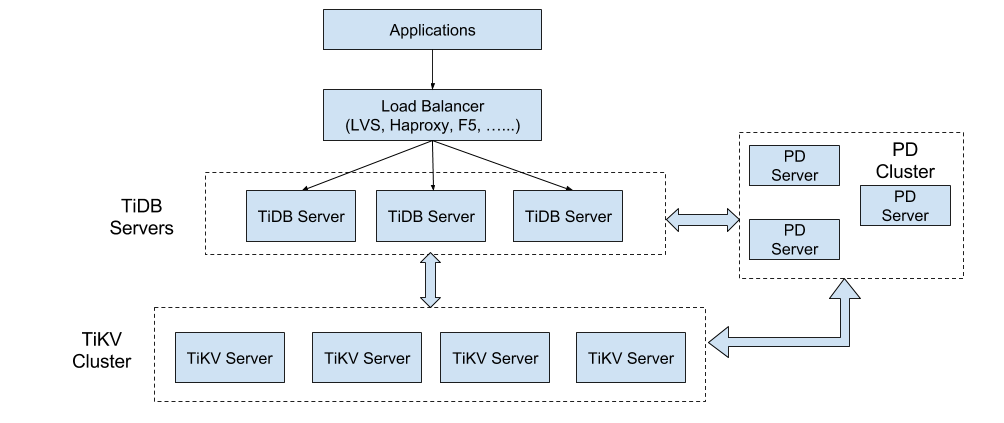
TiKVクラスタの主な機能は、データを保存するためのKey-Valueエンジンです。(これについては前回のコラムで紹介しました。)ここでは、SQL層、すなわちTiDBサーバーに焦点を当てます。この層のノードはデータを保存しないステートレスであり、それぞれが完全に等価です。TiDBサーバーはユーザーのリクエストを処理し、SQL操作ロジックを実行する役割を担っています。
SQLコンピューティング
SQLからKey-Valueへのマッピングソリューションは、リレーショナルデータをどのように格納するかを示しています。次に、これらのデータをどのように使用してクエリ要求を満たすかを理解する必要があります。これは言い換えれば、クエリステートメントが最下層に格納されたデータにどのようにアクセスするかのプロセスです。
最も簡単な方法は、前節で紹介したマッピングソリューションを使ってSQLクエリをKey-Valueクエリにマッピングし、何らかの操作を実行する前にKey-Valueインターフェースを使って対応するデータを取得することです。
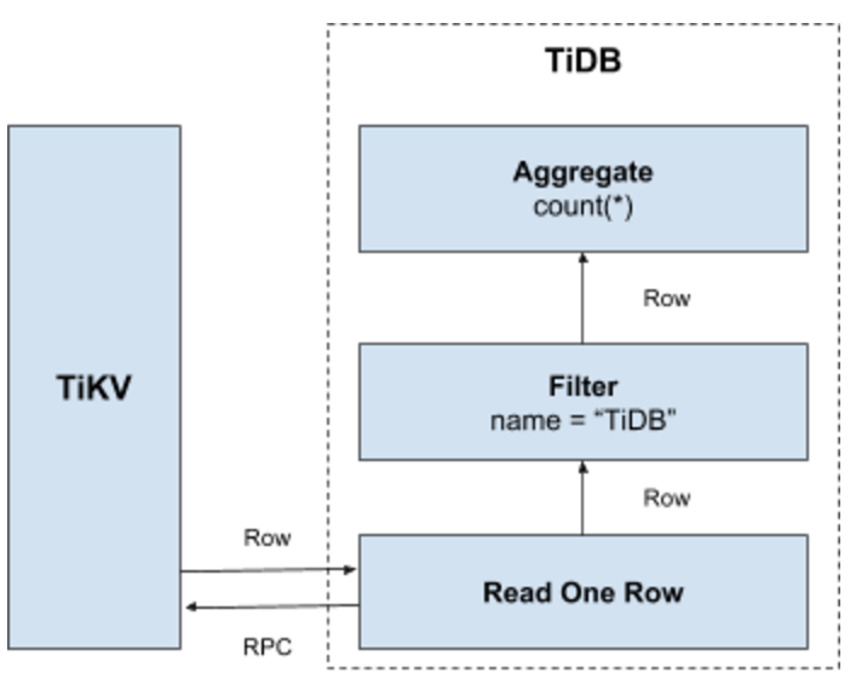
Select count(*) from user where name="TiDB"; という文については、テーブル内のすべてのデータを読み込んでから、NameフィールドがTiDBであるかどうかを確認する必要があります。そうであれば、この行を返します。この操作は、次のKey-Value操作プロセスに移行します。
- キーの範囲の作成: テーブル内のすべてのRowIDは
[0, MaxInt64]の範囲にあるので、0とMaxInt64、および行のキーエンコーディングルールを使用して、[StartKey, EndKey]という左-クローズ-右-オープンの区間を作成します。 - キーの範囲のスキャン: あらかじめ作成しておいたキーの範囲にしたがって、TiKVのデータを読み込みます。
- データのフィルタリング: データの各行を読み込む際に、
name="TiDB"の表現を評価します。その結果が真であれば、この行に戻ります。そうでない場合は、この行をスキップします。 - Countの評価: 要件を満たしている各行について、Count値に加算します。
プロセスは以下の図を参照してください。
この解決策は有効ですが、以下のような欠点があります。
- データをスキャンする際には、各行をTiKVからKey-Value操作で読み込む必要があります。そのため、最低でも1つのRPCオーバーヘッドが発生します。このオーバーヘッドは、スキャンするデータが大量にある場合には膨大なものになります。
- すべての行に適用されるわけではありません。条件を満たしていないデータは読み込む必要がありません。
- 条件を満たした行の値は関係ありません。ここで必要なのは行数のみです。
分散SQL操作
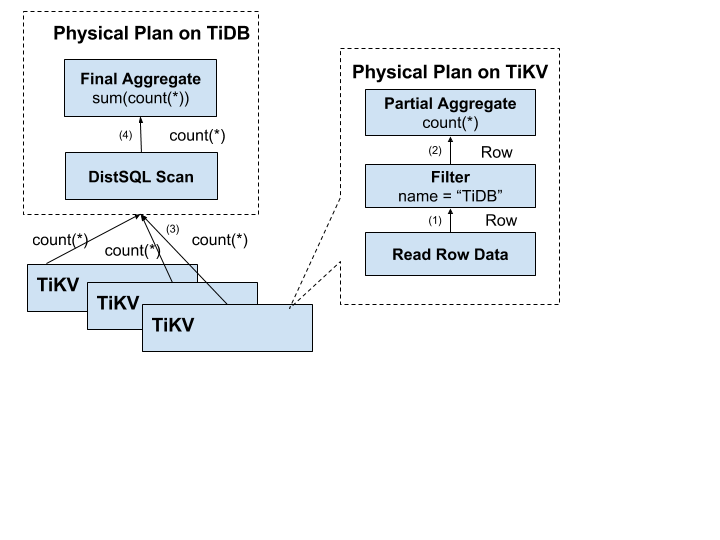
上記の欠点は簡単に回避することができます。
- まず、大量のRPC呼び出しを止めるために、ストレージノードの近くで操作する必要があります。
- そして、Filterをストレージノードにもプッシュダウンする必要があります。この場合、有効な行のみが返され、無意味なネットワーク転送は避けられます。
- 最後に、Aggregate関数とGroupByを押し下げて事前集計を行います。各ノードは1つのCount値を返すだけでよく、その後tidb-serverはすべての値を合計します。
次の図は、データが層ごとに戻ってくる様子を示しています。
SQL層のアーキテクチャ
前節まででSQL層のいくつかの機能を紹介しましたので、SQL文の処理方法についての基本的な概念を理解いただけたことと思います。実際には、TiDBのSQLレイヤーは非常に複雑で、多くのモジュールとレイヤーがあります。次の図は、すべての重要なモジュールと呼び出しの関係を示しています。
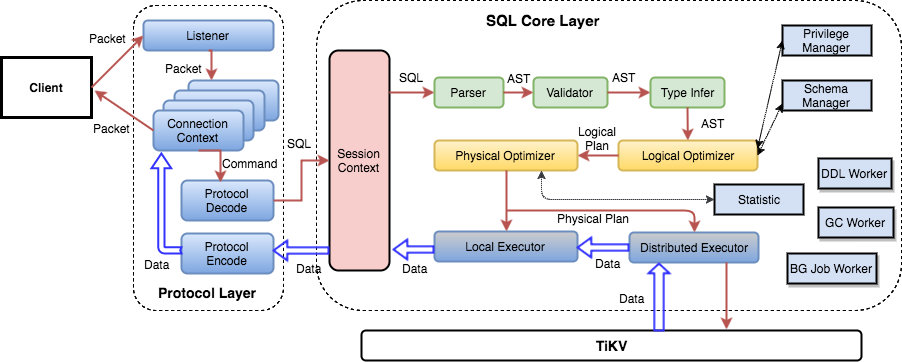
SQLリクエストは直接またはロードバランサーを経由してtidb-serverに送られ、tidb-serverはMySQLプロトコルパケットを解析してリクエスト内容を確認します。その後、構文解析を行い、クエリプランの作成と最適化を行い、そのプランを実行してデータへのアクセスと処理を行います。すべてのデータはTiKVクラスタに保存されているため、tidb-serverは処理中にデータにアクセスするためにtikv-serverと対話する必要があります。最後に、tidb-server はユーザーにクエリ結果を返す必要があります。
まとめ
この記事では、データがどのように保存され、どのように操作に使われるかをSQLの観点から紹介してきました。今後は、最適化の原理や分散実行フレームワークの詳細など、SQL層に関する情報を紹介していきます。次回の記事では、PD、特にクラスタ管理とスケジュールに関する情報を紹介します。