はじめに
Seq2Seqで文章生成(前回、前々回)を行なってきましたが、kerasで構築したSeq2Seqモデルが違っていたことに気づきました。Seq2Seqはencoder-decoderモデルの一種なのですが、あくまで一種であり同じものではありません。これまでは、encoder-decoderモデルを使っていて、Seq2Seqモデルになっていませんでした。その違いをメモしておきます。
encoder-decoderモデル
ecoder-decoderモデルの前に、構築したいモデルであるSeq2Seqを見ておきます。
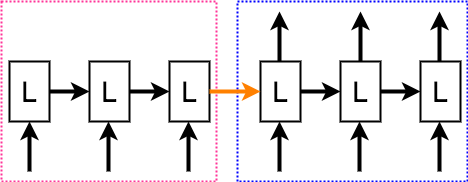
ここで、LはLSTMを表しており、左がエンコード部、右がデコード部となります。 エンコーダー部とデコーダー部にそれぞれ、[[I],[run],[.]]と[[start],[私は],[走る]]を入力し、[[私は],[走る],[end]]が出力されるように学習します。startとendはそれぞれ文章の開始と終わりを表す記号となります。
それでは、econder-decoderモデルを見ていきます。これまでは、以下のモデルで文章生成を行なっていました。
inputs = Input(shape=(self.encord_len, input_dim))
encoded = LSTM(latent_dim, return_sequences=False)(inputs)
decoded = RepeatVector(self.decord_len)(encoded)
decoded = LSTM(latent_dim, return_sequences=True)(encoded)
model = Model(inputs, decoded)
上記のコードを図にすると以下のようになります。
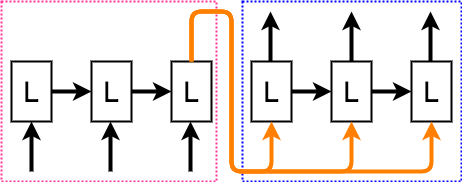
図と見比べながらコードを見てみます。1行目は入力シェイプを決めています。encode_lenはエンコーダー部の長さを表し、今回の図ではエンコーダー部の3つのLSTMに対応します。input_dimはそれぞれのLSTMに対する入力の次元を表しています。2行目で、encoder部のLSTMを定義してます。return_sequencesは、完全な出力を返すか、最後の出力のみを返すかを設定できます。ここでは、Falseとしているため、最後の出力のみを返すようになっています。図では、エンコーダー部の最後のLSTMの出力であるオレンジ色の線に対応します。
3行目から、デコーダ部です。RepatVectorで、エンコードした値をdecoderの長さ分、繰り返す処理を行います。図のオレンジ色の線がデコーダー部のそれぞれのLSTMの入力となっている部分に対応します。最後に、4行目でエンコーダー部のLSTMを定義しています。
Seq2Seqのモデルと若干異なっているのがわかると思います。
そこで、このencoder-decoderモデルをSeq2Seqにするには、次の修正を行う必要があります。
・エンコーダーの最後の隠れ層の状態を取得する
・取得した状態をデコーダーの中間層に入力する
・エンコーダーとデコーダーそれぞれに入力を行う
Seq2Seqモデル
ちゃんとドキュメントがありました。encode-decoderモデルに対して上記の修正が行えているか確認して行きます。
参考:https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
ドキュメントのコードをかいつまんで見ていくので、詳しい内容が知りたい方は、ドキュメントを直接見ることをオススメします。
コードです。
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder_outputs, state_h, state_c = LSTM(latent_dim, return_sequences=True, return_state=True)(encoder_inputs)
encoder_states = [state_h, state_c]
decoder_inputs = Input(shape=(None, num_decoder_tokens))
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
上記のモデルを図にすると次の様になります。
では、図をコードを見比べて行きましょう。
エンコーダーの最後の隠れ層の状態を取得する
encoder_outputs, state_h, state_c = LSTM(latent_dim, return_sequences=True, return_state=True)(encoder_inputs)
コードでは2行目になります。LSTMのインスタンス時の引数にreturn_state=Trueとすることで、LSTMの内部状態を受け取ることができます。このコードでは、内部状態cと隠れ層の出力hを受け取っています。これは、なぜか日本語のドキュメントに乗ってませんでした....。
取得した状態をデコーダーの中間層に入力する
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,initial_state=encoder_states)
コードでは5行目になります。initial_stateを指定することで、内部状態の初期値が設定できます。先ほど取得した状態をこのコードでは、state_h、state_cで受け取っているので、それを初期値とすることで、図のオレンジの線のようにエンコーダー部の最後の隠れ層の状態を、デコーダー部のLSTMの内部状態に渡せていることになります。
エンコーダーとデコーダーそれぞれに入力を行う
1行目と5行目でそれぞれ、エンコーダー部とデコーダー部に対しての入力シェイプを設定しています。ちなみに、エンコーダー長はNoneになっており、encoderの長さを指定していません。これ、指定せずにいけるの知りませんでした....。逆に、エンコーダーの長さを指定すると怒られるので、Noneにしておく必要があるみたいです。
最後の行で、
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
エンコーダー部とデコーダー部に入力を行えるようモデルを組み合わせています。
これで、enocoder-decoderモデルに対して行う3つの修正はクリアできました。しかし、このモデルでは、エンコードしたい文章とデコード後の文章を入力としているため、未知データに対して、デコードする際には、デコードしたいのにデコード後の文章が必要になるという、使い物にならないモデルになってしまいます。そこで、さらにデコード用のモデルを用意します。
デコーダーモデル
デコード用のモデルは次のようになります。
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
図で表すと次の様になります。
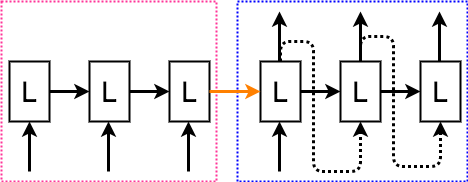
デコーダーモデルでは、まず、エンコーダー部にエンコードしたい文章を入力し、エンコーダー部最後のLSTMの内部状態を出力させます。コードでは、1行目で、エンコーダーしたい文章と内部状態を出力できるようモデルを設定しています。
デコーダー部では、初めのLSTMに対し、文章の始まりを表す記号を入力、さらに内部状態の初期値としてエンコーダーで出力されたものを利用します。先ほど学習した、デコーダー用のLSTMに、エンコーダーの隠れ層とデコードしたい文章を入力し、デコード後の文章を出力しています。kerasのfunctionAPI利用すると学習済みのモデルを再利用するのが簡単にできて良いですね。
まとめ
ようやくSeq2Seqのモデルを組むことができました。モデルはコピペではなく、論文などを見て自分でモデルを組んだ方が確実ですね。また、functionAPIを使うとKerasでも柔軟なモデルが組めるようになるので調べておくと良いかと思います。
それでは、次はこのモデルを参考に実際に文章生成を行なって見ます。