文章作成やってみた2
はじめに
Seq2Seqで文章生成をやってみたのですが、前回は同じ単語を繰り返すモンスターを生み出してしまったので、その失敗を踏まえて、いろいろやってみました。
前回はこちら(https://qiita.com/iss-f/items/bbd3456b1a82b5d56e7c)
今回の戦略
前回同様、kerasを用いてSeq2Seqモデルを作り、文章生成を行なってみます。
今回は、前回に以下の修正を加えます。
- 訓練データのノイズを除去
- baketに分ける
- モデルを単純にする
訓練データのノイズを除去
mecabの分割を見直す
学習精度の向上には訓練データの整形が重要だそうです。実際にニューラルネットワークに与えた訓練データの確認をしてみます。訓練データは、青空文章から文章を取得し、mecabによって文章を単語ごとに分割したものを利用しています。まず、mecabの分割を見直してみます。
実行
$echo "人々は怪物のほうにむちゅうになっていたのと" | mecab -Owakati
結果
人々 は 怪物 の ほう に むちゅうになっていたのと
"むちゅうになっていたのと"がひとつの単語として認識されています。他にも確認してみると、なぜか漢字表記されていない表現が多く出現していました。これらの単語を分割できるようにします。
そこで、mecabに最近の単語にも対応しているという辞書(mecab-ipadic-NEologd)を入れてみました。(https://github.com/neologd/mecab-ipadic-neologd/blob/master/README.ja.md)
上記のリンクにインストール方法が書いてあるので、その通りにインストールしていきます。
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ ./bin/install-mecab-ipadic-neologd -n
なぜかpyenvでハマった.....
pyenv globalでバージョンを複数指定する必要があるらしい
以下のサイトを参考にさせていただきました。
http://ton-up.net/technote/2013/11/09/pyenv-versions/
http://kimiaki.hatenadiary.jp/
無事インストール完了です。
最新というか、昔の言葉に対応してほしいのですが、大丈夫でしょうか....。
実行
$echo "人々は怪物のほうにむちゅうになっていたのと" | mecab -Owakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd
結果
人々 は 怪物 の ほう に むちゅう に なっ て い た の と
できてる!!
別の例では、
befor : 小林 少年 は 、 ピッ ポ ちゃん の はいっ て いる カバン を 、 だい じ そう に だい て 、
after : 小林少年 は 、 ピッポ ちゃん の はいっ て いる カバン を 、 だいじ そう に だい て
[小林少年]や[ピッポちゃん]というひとつの固有名詞として、認識できてます。
[だいじそうに]というひらがな表記も[だいじ]という単語を認識できるようになっています。
しかし、
おれ は 、 あ けち の にせもの だって 、 ちゃんと 作る から ね 。
ぼく は ただ 、 有名 な 二 十 面相 君 と 、 ちょっと 話 を し て み たかっ た だけ さ 。
などは、[あけち]や[二十面相]がひとつの単語として認識できませんでした。
前よりは、精度は向上しているということなので、これを使って、再度文章を単語ごとに分割してみます。
かっこを取り除く
小説なのでかっこ(「」)が入ってるのですが、こいつらを取り除きます。
EOSの判定として[。]を使用していました。すると、かっこ(「」)が入っている場合の、文章を1文とする判定がめんどくさかったからです。
例えば、
「彼が犯人です。その証拠は......。」と明智探偵が言いました。
という文章の場合、
1文目:「彼が犯人です。
2文目:ひとりづつその.....。
3文目:」と明智探偵が言いました。
となり、1文目と3文目では、かっこ(「」)が変に入ってしまいます。
そこで、今回はかっこ(「」)を取り除き、
「彼が犯人です。その証拠は......。」と明智探偵が言いました。
という文章は
1文目:彼が犯人です。
2文目:ひとりづつその.....。
3文目:と明智探偵が言いました。
のように3つの文章に分かれる様にしました。
個人的に、整形前のデータは目にすることは多かったのですが、実際に訓練データとして与える整形後のデータをじっくり確認することはあまりありませんでした。予期しない入力を行なっていることに気づくためにも、整形後のデータを根気よく確認するのは重要だと思います。
bucketに分ける
入力文章とそれに対応する出力文章の長さに応じてモデルを使い分けると効率的だそう。tensorflowのドキュメントに書いてありました。
http://tensorflow.classcat.com/2016/03/16/tensorflow-cc-sequence-to-sequence-models/
実際、選択した文章と次に続く文章の長さが違いすぎる場合、学習がEOSの記号にだいぶ引っ張られるということがありました。そのため、文章長が大きく異なりすぎない文章の組みを選択し、モデルに与えるのは有効な手段かと思います。
今回は、テストのため(5、10)のbucketのみを使ってみます。したがって、全文章中から、入力文章の単語数が5かつ次に続く文章の単語数が10である文章の組みを取得、文章長をそれぞれ5、10にパディングし、ニューラルネットワークに与えることになります。
tensorflowのドキュメントにbucketに分ける手法と一緒にパディングについても書かれていました。パディングには、パディング用の特殊文字[PAD]を作り、これでパディングすれば良いそうです。
しかし、今回は単語をベクトル表現するためにword2vecを使用したため、特殊文字[PAD]が作れず、[。]でパディングすることにしました。
モデルを単純にする
学習データに対して、モデルが複雑になると、パラメタ数が増え、過学習を起こしやすくなります。前回まで使用していたモデルのパラメタ数は9,006,000でした。多すぎたようです。
現在使用しているのは、以下の図の様な、attentionのない単純なSeq2Seqです。

前回のモデルでは、
word2vecによりベクトル化される単語ベクトル:500次元
エンコードされるベクトル長:1000次元
ecnoder、decoder長:40次元
と設定していました。以下の図のようになります。
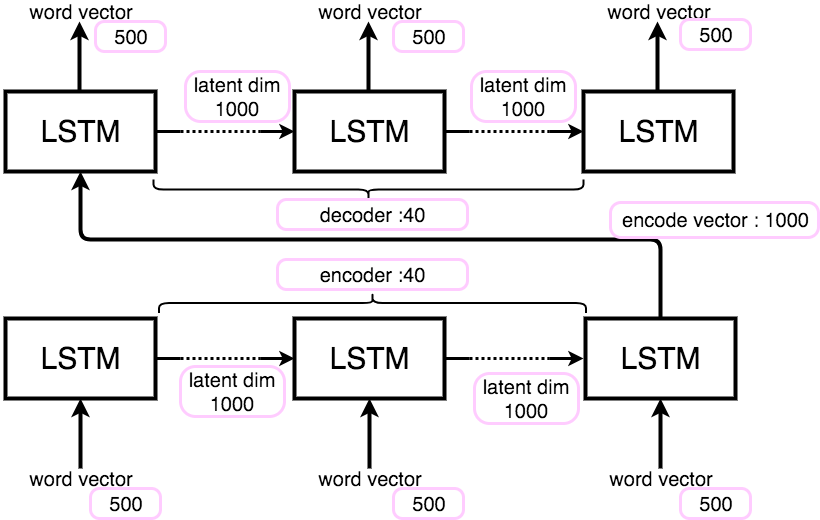
このモデルを次の様に変更します。
word2vecによりベクトル化される単語ベクトル:20次元
エンコードされるベクトル長:30次元
encoder:5
decoder:10
図で表すと以下の様になります。
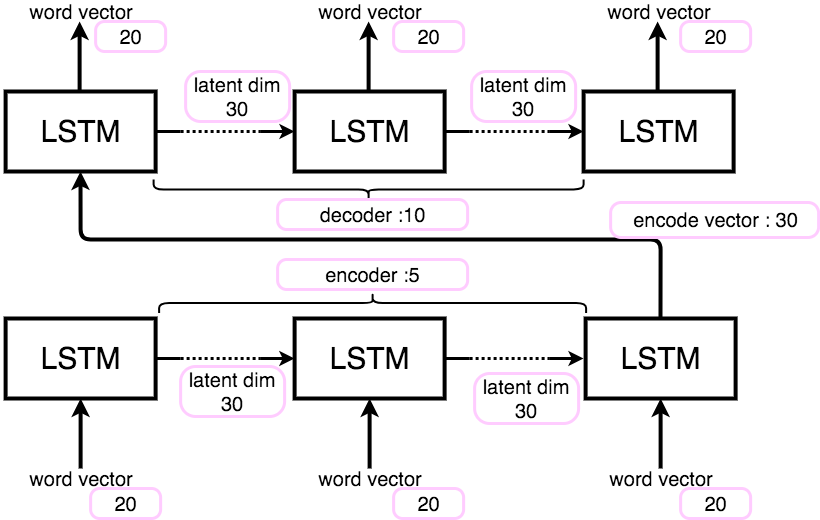
これにより、パラメタ数は9,006,000から10,200となり、随分と減らすことができました。
これで、学習を行わせてみます。
学習させてみる
学習データ
学習に使用するデータは前回と同様に青空文庫からとってきた江戸川乱歩の小説です。
ファイル容量 8.5M
文章数: 32615
非ユニーク単語数: 1571358
ユニーク単語数: 33589
モデル
損失関数、最適化アルゴリズムは前回と同様で、次の様になります。
損失関数 : 平均自乗誤差
最適化アルゴリズム : Adam
学習結果
batch_sizeを100、epoch数を10000回としています。これを1stepとし、100step学習を行います。ただし、過学習を防ぐため、kerasのcallbackである、EarlyStoppingを使用しており、1stepあたり実質100エポックほどの学習しか行なっていません。
では、学習結果です。
loss: 1.6211 - acc: 0.1511 - val_loss: 2.2437 - val_acc: 0.1000
これ以上学習を繰り返しても、変化しなかったので、これを最終的な学習結果とします。lossとval_lossの差が開いているので、過学習している可能性が考えられます。また、精度(acc)も高いとは言えません。
ひとまず、文章を生成してみます。>>が全文章からランダムに選択した文章、なにもついていない方が出力となります。
>> これでよしと。
姉さん姉さん、、。
>> 透明怪人だッ。
おじさん姉さん姉さん、。
>> わかりました。
やっぱり。
>> とらです。
アン姉さん。
>> ウン、ちょうどいい。
うん姉さんなぜ。
>> いいところです。
なるほどよくよくよくちゃんと。
>> すると、そのとき。
誰だ村松。
>> うそなもんか。
ナニなるほどなるほど。
>> ウォーッ、ウォーッ。
村松。
>> おや、おかしいぞ。
誰だあいつだ。
前回の様に、同じ単語を繰り返すことはなくなってます。[姉さん]と[松村]が好きな様です。前回はモデルが複雑だったため、勾配ゼロ問題が生じていた可能性があります。今回は、モデルを単純化したことで、各ニューロンの重みが全体的に更新されたため、様々な種類の単語ベクトルを出力できたのではないかと考えられます。また、bucketを(5,10)に絞り学習を行なったため、EOSである[。]に学習がひきづられなかったのも様々な種類の単語を出力できた原因ではないかと考えられます。
しかし、与えた文章に対して、意味のある文章を出力できているとは言えません。
batch sizeを増やす
batch sizeが100では、過学習の可能性があるため、少しづつbatch sizeを増やしてみます。また、batch sizeを増やすことで精度の向上を目指します。
結果です。
batch size:100 loss: 1.6211 - acc: 0.1511 - val_loss: 2.2437 - val_acc: 0.1000
batch size:200 loss: 1.8227 - acc: 0.1544 - val_loss: 1.7571 - val_acc: 0.1550
batch size:300 loss: 1.7596 - acc: 0.1978 - val_loss: 1.6531 - val_acc: 0.2833
batch size:400 loss: 1.7525 - acc: 0.1444 - val_loss: 2.3349 - val_acc: 0.1475
batch size:600 loss: 1.8024 - acc: 0.0861 - val_loss: 1.9533 - val_acc: 0.0550
batch size:800 loss: 1.8128 - acc: 0.1146 - val_loss: 1.7924 - val_acc: 0.1262
batch size:1000 loss: 1.7880 - acc: 0.2341 - val_loss: 2.0851 - val_acc: 0.2260
batch size:1200 loss: 1.8293 - acc: 0.1081 - val_loss: 1.8986 - val_acc: 0.0
batch size:5000 loss: 1.8950 - acc: 0.1642 - val_loss: 1.7115 - val_acc: 0.1404
batch sizeが200の時点でlossとval_lossの差は小さくなっています。しかし、batch sizeが400の時には、その差は大きくなっています。batch sizeを増やせば良いわけでもなく、モデルにあったbatch sizeを選択する必要があると考えられます。
また、精度(acc)が高い順に並べると、
batch size:1000 acc:0.231
batch size:300 acc:0.1978
batch size:5000 acc:0.1642
batch size:200 acc:0.1544
batch size:400 acc:0.1444
batch size:800 acc:0.1146
batch size:1200 acc:0.1081
batch size:600 acc:0.0861
となります。こちらもbatch sizeを増やせば良いというものではないようです。もっとも精度が高くなったものでも0.231で、高いとは言えません。
様々な種類の単語を出力できる様になったことから、重みもうまい具合に更新できていると考えられますが、loss、acc共に思い通りの値とはなりませんでした。少しモデルを単純にしすぎたかもしれません。
まとめ
今回は、学習精度向上のため、以下の3つを試してみました。
- 訓練データのノイズを除去 → 意外と想定外の入力をしてることがあるので、確認は重要
- baketに分ける → EOSの記号に学習がひきづられることが少なくなった
- モデルを単純にする → 前回のモデルは複雑すぎた、しかしもう少し層を増やしても良いかもしれない。
前回のように同じ単語を繰り返すだけではなくなったが、意味のある文章を生成できているとは言えないものとなりました。次回は、少し層を増やし、それぞれの結果を比較していきたいと思います。