はじめに
2019/4/12に公開されたMediumの記事 ![]() 「Bias Detection in IBM Watson OpenScale」の翻訳です。
「Bias Detection in IBM Watson OpenScale」の翻訳です。
WOSにおけるフェアネスやバイアスの概念・考え方をシンプルに説明した良記事だと思ったので自分なりに翻訳しました。(翻訳作業については著者了承済み)
IBM Watson OpenScaleにおけるバイアス検知
April 12, 2019 by Manish Bhide
フェアネス(公平性)またはバイアスは、企業のAI採用を躊躇させる大きな問題の1つです。ここで、ある保険会社が保険金請求の承認/拒否の判断にAIモデルを使おうとしているとしましょう。ビジネス部門のオーナーはモデルが偏った決定をしないことを確信できる必要があります。しかしトレーニング中にモデルが偏りのない方法で振舞うすることが確認できていたしても、本番環境に展開された後も引き続き、偏らない振る舞いをすることが保証されているわけではありません。IBM Watson OpenScaleは、実際の本番環境のAIモデルの動作をモニターし、それらが偏った振る舞いをしているかどうかを確認できるので、この問題に対処するのに役立ちます。
バイアスとは何ですか?
「バイアス」の意味を理解する前に、いくつかの重要な概念を明確にしておきましょう。
フェアネス(公平性)の属性(Fairness Attribute):バイアスまたはフェアネス(公平性)は通常、性別、人種、年齢などの何らかの「フェアネス属性」を使って測定されます。また、「サービスの加入年数」など、非ソーシャルな属性を使用して測定することもできます。
監視対象(Monitored)/参照(Reference)グループ:監視対象(Monitored)グループは、バイアスを測定したいグループのフェアネス属性の「実際の値」です。フェアネス属性のもう一方の値は、参照(Reference)グループと呼ばれます。 フェアネス属性が「性別」の場合で、女性に対するバイアスを測定しようとするなら、監視対象グループは「女性」、参照グループは「男性」になります。
好ましい/好ましくない結果(Favourable/Unfavourable outcome):モデルの「好ましい結果」と「好ましくない結果」はバイアス検出での重要な概念です。例えば、請求が承認されることは「好ましい結果」、請求が拒否されることは「好ましくない結果」と見なすことができます。
異なる影響(Disparate Impact):これは偏りを測定するために使用され、「参照グループの好ましい結果の割合」に対する「監視対象グループの好ましい結果の割合」の「割合」として計算されます。異なる影響値(Disparate Impact)が所定の「しきい値」を下回った場合、バイアスが存在していると判断します。
たとえば、男性による請求だと80%が承認されているのに対し、女性による請求だと60%しか承認されていない場合、異なる影響(Disparate Impact)は60/80 = 0.75になります。通常のしきい値は0.8であり、このケースでは異なる影響(Disparate Impact)が0.8未満であるため、モデルは偏っていると見なされます。
バイアスしきい値(Bias Threshold):バイアスしきい値を「1」と設定したなら、それは男性と比較して女性が同じ、またはそれ以上の請求の承認率を得ることを期待している、ということになります。しかしながら、いくつかのシナリオでは、監視されたグループの好ましい結果が参照グループよりもすこし下回る程度は許容できる場合もあるでしょう。このような状況を処理するために、お客様は各モデルのしきい値を1未満の値に設定できます。通常、この値は0.8に設定されています。
Watson OpenScaleでのバイアス検出
IBM Watson OpenScaleを使えば実行時のバイアスを検出することができます。IBM Watson OpenScaleは、モデルに送信されたデータとモデルの予測結果をモニターします(このデータはペイロード・データと呼ばれます)。次にバイアスの有無を判定し、利用者に判定結果を通知します。バイアスのダッシュボードは以下のようなものです。
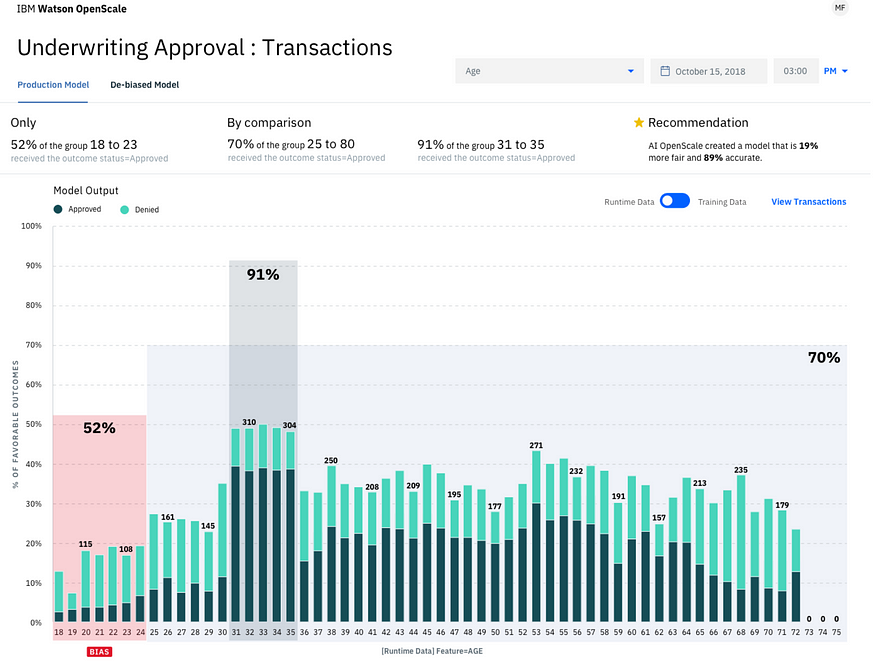
上の例でのフェアネス属性は「年齢」であり、モデルが年齢層18〜24歳の人々(監視対象グループ)に対して偏った行動をしていることを示しています。 18〜24歳の人々の好ましい結果の割合は52%であるのに対し、25〜75歳の人々(参照グループ)の好ましい結果の割合は70%です。したがって、異なる影響(Disparate Impact)は0.52 / 0.7 = 0.74であり、0.8のしきい値を下回っているため、このモデルにはバイアスがかかっていると見なされます。
データの摂動(Data Perturbation)
100件の保険金請求のペイロード・データがある(すなわち、モデルが100個の請求に対する決定を下すために使用された)シナリオを考えてみましょう。ここで、18歳-24歳の人々から60件の請求があり、24歳以上の人々からは40件の請求があったとします。さらに過去の実績として、18歳-24歳の人々からの請求は不正な請求が多く、24歳以上の人々による40件の請求はすべて正当な請求であったと仮定しましょう。このような実績データからモデルが作られたならば、結果としてモデルは18〜24歳の顧客による60件の請求はすべて拒否するでしょうし、24歳以上の人々による40件の請求はすべて正当な請求として承認するでしょう。ここで異なる影響(Disparate Impact)影響を測定すると、0/1 = 0になります。したがって、モデルの振る舞いにはバイアスがあると判断されます。しかし実際は、モデルは提供されたデータに基づいて正しい決定を下しているだけであって、偏った方法で動いているわけではありません。つまり、「モデルに偏りがある」とレポートされた場合でも、ビジネス・オーナーはその偏りの「是正」を望まないかもしれないのです。なぜなら、この場合の「是正」とは、明らかに詐欺である申請を承認することにもなるからです。
この問題に対処するために、フェアネス(公平性)を計算しながらデータ摂動(Data Perturbation)を行います。データの摂動のしくみですが、例えば20歳の顧客からの請求がモデルによって拒否されたなら、年齢を20歳から参照グループ内のランダムな値(例えば40歳)に反転させたうえで、改めてこの反転したレコードを予測モデルに送信します。年齢以外のレコードの値はすべて同じです。年齢の値を変えた結果としてモデルが申請を「承認」と予測したなら、それはモデルが顧客の年齢に基づいて決定を下すことで偏った振る舞いをしていることを意味します。このように、バイアスを計算しながら、このデータの摂動(Perturbation)を同時に行い、ペイロード+摂動データを使用して異なる影響(Disparate Impact)を計算します。これにより、モデルが元のデータと摂動を加えたデータの両方を加味して、なお偏った動作を示している十分な数のデータポイントがある場合にのみ、バイアスを報告します。この方法を使えばモデルに本当に偏りがあるのかどうかを検出でき、モデルが受け取るデータの種類による影響を受けずに済みます。
上記のスクリーンショットでは、棒グラフはペイロード+摂動データ全体の統計を示しています。好ましい結果の割合(52%、70%など)も、ペイロード+摂動データの組み合わせを使用して計算されています。
サマリー
IBM Watson OpenScaleは、モデルが本番業務の実行時に偏った振る舞いをしているかどうかを監視するためのメカニズムをエンタープライズに提供します。バイアスの計算は誤検知(False Positive)につながらないような方法で行います。言い換えれば、IBM Watson OpenScaleがバイアスの存在をレポートしたならば、それはお客様が修正したい内容なはずであり、実際にそうすべきでしょう。これはAIに対する信頼を築くのに役立つ重要な要因です。
記事はここまで↑
ご参考
当記事の内容を自分なりに一枚にまとめたので、貼っておきます。

記事翻訳のみならず、過去、自分でもWatson OpenScaleをご紹介した記事をQiitaに書いておりますので、ご興味あればご高覧ください。
![]() 「AIへの信頼」や「説明可能なAI」に絡み、一部で話題の「IBM Watson OpenScale」をザクッとご紹介します
「AIへの信頼」や「説明可能なAI」に絡み、一部で話題の「IBM Watson OpenScale」をザクッとご紹介します
![]() Watson OpenScaleをもう少し「キチッ」とご紹介します(A.K.A.「麗しき誤解」を解く)
Watson OpenScaleをもう少し「キチッ」とご紹介します(A.K.A.「麗しき誤解」を解く)
![]() Watson OpenScaleを触る前に知っておきたかったこと(技術Tipsなど)
Watson OpenScaleを触る前に知っておきたかったこと(技術Tipsなど)
以上です。