この記事は ドワンゴ Advent calendar 2021 の20日目の記事です。
あなたはフォントが好きですか?
フォントは日陰ながらも縁の下の力持ちです。使うフォントでページの印象がガラッと変わりますね。リピーターになるかも、売り上げも変わります。フォントにこだわりたいところです。
モチベーション
私はフォントを作るのが趣味で、芸術的な(よく言えば)フォントをちまちまリリースしています。回転率、パディングなどの微調整に関してはこだわらずに適当に設定してしまっていますが、こちら機械学習により先人の叡智を拝借して、いい感じにできないかと。
事前準備
自作フォント(回転・パディングの調整なし)を作成する
元データは様々な文字が紙に書かれた状態です。
こちらから各文字(以下グリフ)を画像に別々に書き出します。

OpenCV で輪郭検出をして輪郭内を塗りつぶし、さらに輪郭検出をしてそれを切り抜きます。
上記の画像を見ての通り、元のサイズのまま輪郭検出を施すと細かな部品も検出されてしまうので、縮小・少しぼかして輪郭検出をし、拡大率をもとに元のサイズから画像を切り抜きます。
import cv2
import numpy as np
import math
import copy
def crop():
law_path = "./resource/law1.jpg"
img_origin = cv2.imread(law_path)
imgheight = img_origin.shape[0]
imgwidth = img_origin.shape[1]
ratio = 7
padding = 20
ret, img_binary = cv2.threshold(img_origin, 200, 255,cv2.THRESH_BINARY)
img_gray_highlight = cv2.cvtColor(img_binary, cv2.COLOR_BGR2GRAY)
# 縮小
resize_w = math.floor(imgwidth / ratio)
resize_h = math.floor(imgheight / ratio)
img_mini = cv2.resize(img_gray_highlight, (resize_w, resize_h))
# ガウスぼかし
img_blur = UnSharpMasking(img_mini, 5.0)
# 二値化で少しでもグレーなところを黒くする
r, img_binary_mini = cv2.threshold(img_blur, 254, 255, cv2.THRESH_BINARY)
img_gray_color_mini = cv2.cvtColor(img_binary_mini, cv2.COLOR_GRAY2BGR)
# 輪郭検出
contours, img_rinkaku_mini = cv2.findContours(img_binary_mini, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
i = 0
for point in contours:
img_gray_color_mini_work = copy.copy(img_gray_color_mini)
x, y, w, h = cv2.boundingRect(point)
crop_x = max(x * ratio - padding, 0)
crop_y = max(y * ratio - padding, 0)
crop_w = min(w * ratio + padding * 2, resize_w)
crop_h = min(h * ratio + padding * 2, resize_h)
cv2.fillConvexPoly(img_gray_color_mini_work, points =point, color=(0, 255, 0))
crop_image = img_gray_highlight[crop_y:crop_y+crop_h, crop_x:crop_x+crop_w]
cv2.imwrite("./resource/work/hoge"+str(i)+".jpg", crop_image)
i += 1
def UnSharpMasking(gray, tmp_k=3.0):
k = math.floor(tmp_k)
blur = cv2.blur(gray, (k, k))
return blur
crop()
ゴミの部分もファイルに出力されてしまったので、そのファイルは手で消しました。
文字を割り当て、フォントデータ化する
こちら OCR をかけて自動でできたら素敵なのですが、今回は目を使って文字を割り当て、ttf ファイルに変換しました。
機械学習の教師データ作成
サマリー
記事のタイトルは「回転、パディング」とあるのですが、今回は試しに「回転」について機械学習をかけていくことにします。
方法としては、フォントデータから ”正しい” 角度がわかるので、そこから回転率と、回転させた画像を読み込ませます。いろんなフォントファイルから生成します。そうすると、自作フォントのグリフの回転率が割り出せるんじゃないかと。
パディングも似たような感じで、フォントデータから生成した、パディングをなくしたグリフ画像と、上下左右のパディングの値(パディングゼロの画像の幅・高さを100%として)を機械学習に読み込ませて、目的のグリフのパディングが整うといいなといった感じです。こちらはおいおいのタスクです。
様々なフォントデータから、グリフの画像を作成する
こちら、Qiita の記事を参考に作成しました。
フォントデータの元データは、Windows10 にデフォルトで入っていたフォントですが、本当はライセンスを調べないといけません。(モリサワに問い合わせて、たくさん使わせてもらうか?)
機械学習の方々は、教師画像の著作権の扱いはどうしているんだろう。
import argparse
import defcon
import extractor
import glob
ttf_dir = "./dist/ttfs"
svg_path = "./dist/svgs"
png_path = "./dist/pngs"
def save_all_glyph_as_svg(font, glyph_name="A", i=0):
from textwrap import dedent
from fontTools.pens.svgPathPen import SVGPathPen
glyph_set = font.getGlyphSet()
try:
glyph = glyph_set[glyph_name]
except KeyError:
return
svg_path_pen = SVGPathPen(glyph_set)
glyph.draw(svg_path_pen)
ascender = font['OS/2'].sTypoAscender
descender = font['OS/2'].sTypoDescender
width = glyph.width
height = ascender - descender
content = dedent(f'''\
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 {-ascender} {width} {height}">
<g transform="scale(1, -1)">
<path d="{svg_path_pen.getCommands()}"/>
</g>
</svg>
''')
with open(svg_path + "/" + glyph_name + "_" + str(i) + ".svg", 'w') as f:
f.write(content)
def convert_all_svg_to_png():
from cairosvg import svg2png
import os
files = os.listdir(svg_path)
files_file = [f for f in files if os.path.isfile(os.path.join(svg_path, f))]
for file in files_file:
bname, ext = os.path.splitext(file)
try:
svg2png(url=svg_path + "/" + bname + '.svg', write_to=png_path + "/" + bname + '.png')
except:
print(file)
return
def ttf_to_png():
from fontTools.ttLib import TTFont
files = glob.glob(ttf_dir + "/*.ttf")
for i, file in enumerate(files):
font = TTFont(file)
save_all_glyph_as_svg(font, glyph_name="A",i=i)
convert_all_svg_to_png()
ttf_to_png()

グリフの画像から、教師データの画像を作成する
教師データはすべて同じ画像サイズではないといけないそうです。
さきほど作成した、さまざまなフォントのグリフ画像を-90°~90°に回転させて出力します。
最初は拡大縮小・グリフ画像の左右上下の余白もいろいろな値にして出力していたのですが、「過学習」というエラーが出てうまく動きませんでした。こちらは機械学習のエンジンが優秀なので不要です。
TensorFlow で学習データを作成する
知識ゼロから触り始めたのですが、ちょっと時間かけないと難しいです...
import os, glob
import numpy as np
import cv2
from sklearn import model_selection
import pandas as pd
increment = 5 # 最終的には1刻みにしたい
classes = range(0,180,increment)
num_classes = len(classes)
image_size = 28
# XとYはそれぞれ、画像データと、その画像の角度がどれなのかを示すラベル。
X = []
Y = []
def training_a_ratio(ratio):
glyphname = "A"
ret_X = []
ret_Y = []
photos_dir = "./resource/angle/" + glyphname + "/origin/" + str(ratio)
files = glob.glob(photos_dir + "/*.png")
for i, file in enumerate(files):
load_image = cv2.imread(file)
image = cv2.resize(load_image, (image_size, image_size))
h = image.shape[0]
w = image.shape[1]
arr2 = image[:, :, 0]
for y in range(h):
for x in range(w):
arr2[y, x] = float(image[y, x, 0] / 255)
data = np.array(arr2)
ret_X.append(data)
ret_Y.append(ratio)
return ret_X, ret_Y
for ratio in range(0, 180, increment):
tmp_X, tmp_Y = training_a_ratio(ratio=ratio)
X += tmp_X
Y += tmp_Y
print(len(X))
X = np.array(X)
Y = np.array(Y)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, Y)
xy = (X_train, X_test, y_train, y_test)
np.save("./dist/A_training_inc5.npy", xy)
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import os
image_size = 28
path = './a_training_inc5.npy'
data = np.load(path, allow_pickle=True)
# さきほど npy で読み込ませた順
# train_examples = data['x_train']
# test_examples = data['x_test']
# train_labels = data['y_train']
# test_labels = data['y_test']
train_examples = data[0]
test_examples = data[1]
train_labels = data[2]
test_labels = data[3]
train_dataset = tf.data.Dataset.from_tensor_slices((train_examples, train_labels))
test_dataset = tf.data.Dataset.from_tensor_slices((test_examples, test_labels))
# データセットのシャッフルとバッチ化
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 100
train_dataset = train_dataset.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
test_dataset = test_dataset.batch(BATCH_SIZE)
# モデルの構築と訓練
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(image_size, image_size), name='flatten_layer'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# モデルのコンパイル
model.compile(optimizer=tf.optimizers.Adam(),
loss='mean_squared_error', # サンプルのやつえらった
metrics=['accuracy'])
model.fit(train_dataset, epochs=5, steps_per_epoch=BATCH_SIZE)
model.save("./model_cnn.h5")
results = model.evaluate(test_examples, test_labels, verbose=2)
print("test loss, test acc:", results)
いざ、判定!
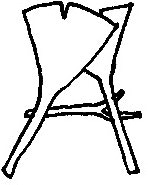
こちらの画像は何度傾きが最適と判定されるでしょうか!?
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import os
model = tf.keras.models.load_model('./model_cnn.h5')
model.summary()
path = './autumn_A.npy'
img = np.load(path, allow_pickle=True)
print(img.shape)
img = (np.expand_dims(img,0))
print(img.shape)
predictions_single = model.predict(img)
print(predictions_single)
print("予測角度(左90度を0としている): ")
predict = np.argmax(predictions_single[0])
print(predict)
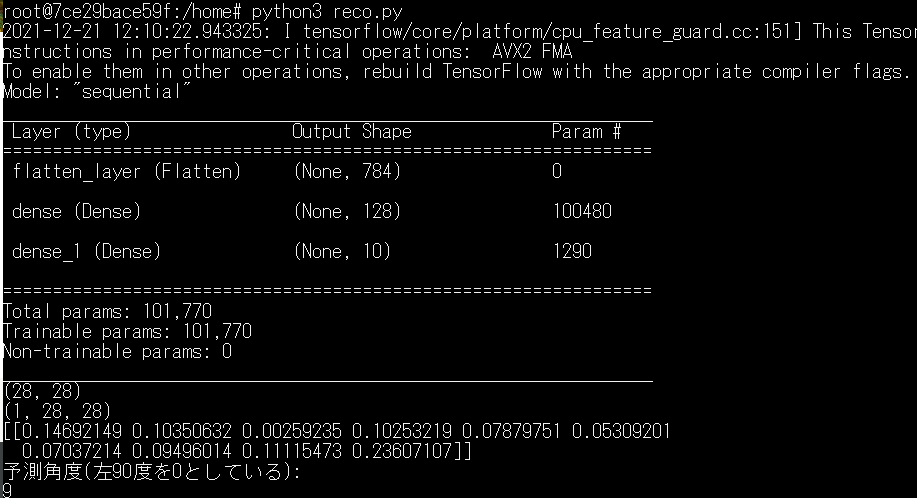
ほーん、9度か~。
いやまてよ...
ちょっと30度傾けてまたかけてみました。
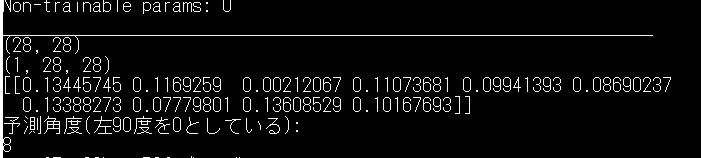
oh...
ごめんなさい、これ以上は体系的に学ばないとできないです。
物体判定のソースをもとに作っていましたが、調整用の数値を吐き出してくれるモデルを構築する手段があるはず。宿題にさせてください。。
追記 2021/01/07
こちらちゃんと読み込ませて試しました。具体的には
- 1度刻みで文字を回転させる(-90度~90度)いろいろなフォントで生成する
- 20度刻みでラベリングして、教師データを作る
- 創作フォントをジャッジさせる
ですが、ジャッジはうまくいきませんでした。「同じ文字を傾けて、角度を推測する」というのは現在の機械学習にはできないようです。
このへん改善を期待します(今時エンジニアリングの余地があるのね..!)
うまくできる方法を思いつかれた方は、ぜひ教えてください。
おわりに
フォントの仕様から読み始めて、なかなか骨の折れるプロジェクトでした。先人が作ったものを組み合わせればもう少し進んだのですが、さらっと見つかるかっていうのがネックです。
触ってみると機械学習のニューロンの仕組みがなんとなくイメージできて、できることのアイデアが広がります。
業務に乗る冷静なものだけではなく、会社のサービスの特性上、感情評価など感情と絡めたサービスに発展出来たら夢が広がります。脈拍などの生体データ、時間帯などを取ったらやりやすいのかな。
今回の話でいえば「フォントと感情」というので感情指数の数値化やフォント提案の自動化ができると、勘所がない方もフォントにとっつきやすいかもしれません。考えてみます。
こちらのプロジェクトのソースコードはこちらになります:
irimo@github:auto_font_margin