Titanic: Machine Learning from Disaster
タイタニック号の乗客名簿的なものから、生存者のデータを分析するチュートリアル的なやつです。
https://www.kaggle.com/c/titanic
データ初見でやりながら記事を書いてるので、支離滅裂です。
素敵な解説
自分の好みに合わせて、つまみ食いします。
https://qiita.com/suzumi/items/8ce18bc90c942663d1e6
https://www.codexa.net/kaggle-titanic-beginner/
https://qiita.com/k2me14/items/ab9d71960d2b9d422c16
https://www.codexa.net/kaggle-titanic-beginner/
道具
Python 3
Jupyter notebook
Pandas
XGBOOST
Google colaboratory
前処理
データ読みます。 male(男)を0 female(女)を1に入れ替えます。
df_train = pd.read_csv('./train.csv').replace("male",0).replace("female",1)
df_test = pd.read_csv('./test.csv').replace("male",0).replace("female",1)
display(df_train.head(50))
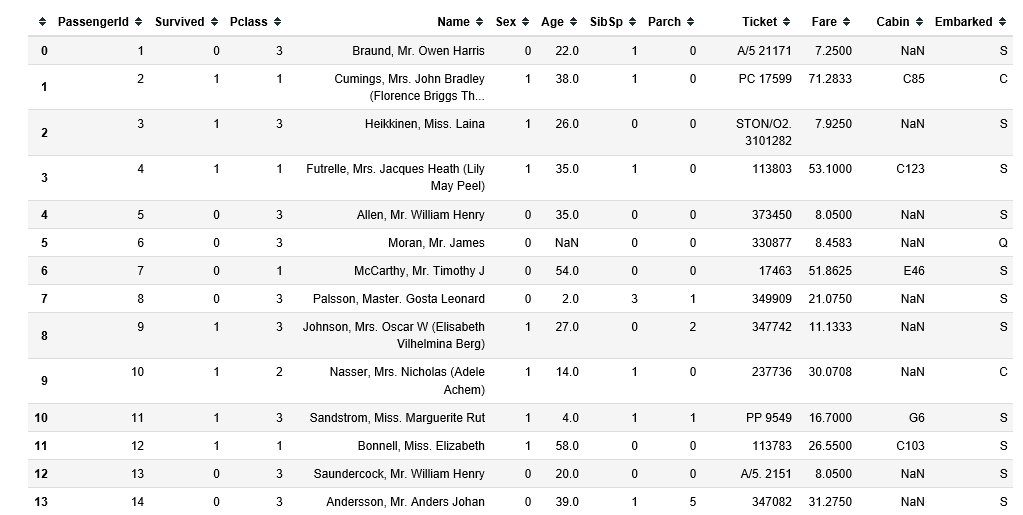
欠損値の確認
このデータにはAgeに欠損値があるそうです。
年齢ってとっても大事そうな要素なのに、値の欠損が20%あるらしいです。参考
上図のPassengerID 6の人の年齢が既に欠損してます。
というわけで、欠損値してる人ってどういうデータかマニアックに確認しようと思います。
とおもってたけど、方針転換して地位、仕事を調べることになりました。
敬称 Mr Mrs Dr Camp などなど
まずは名前を見ます。 欧米人の名前の書き方は意味不明なのですが、Mr, Mrs, Doc, など敬称があるので、そこから推察しようと思います。
だって子供のドクター(Dr:医師 or 博士号持ち) とか居ないでしょ?
sep_forward = df_train["Name"].str.split(",",expand=True)
sep_backward = sep_forward[1].str.split(".",expand=True)
job = sep_backward[0].str.replace(" ","")
df_train["job"] = job
display(df_train["job"].unique())
# array([' Mr', ' Mrs', ' Miss', ' Master', ' Don', ' Rev', ' Dr', ' Mme',
# ' Ms', ' Major', ' Lady', ' Sir', ' Mlle', ' Col', ' Capt',
# ' the Countess', ' Jonkheer'], dtype=object)
display(df_train["job"].())
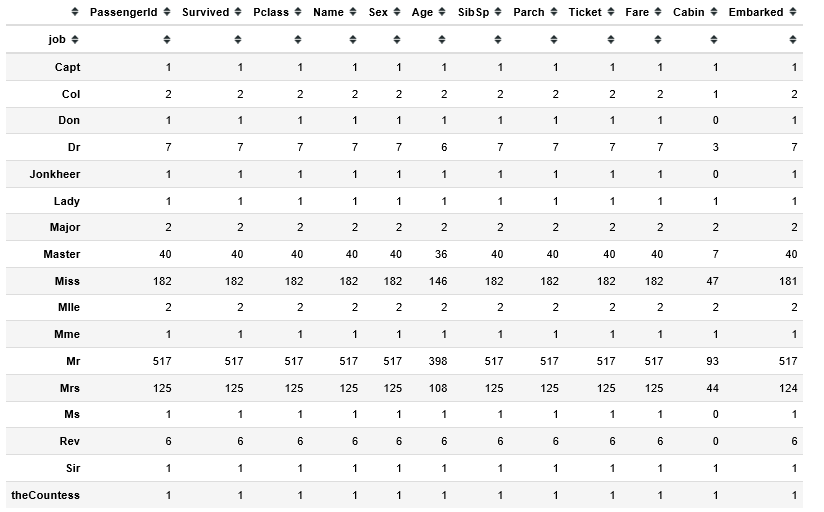
display(df_train.groupby(by=["job"]).count())
display(df_train[df_train["job"]=="Dr"])
プログラムを一行でやりきる能力がなくてさーせん。
Mr, Mrs, Miss, Ms はたぶん一般人です。
Donって何ぞや? → イギリス英語では大学教授らしいです。 一人しかいませんでした。
Revって何ぞや? →牧師だそうです。6人いました。全員お亡くなられてました。
Col? →大佐(軍人)?
Master → 修士?とか思ってたら、子供らしいです。
display(df_train.groupby(by=["job"])["Survived"].agg(["mean","count"]))
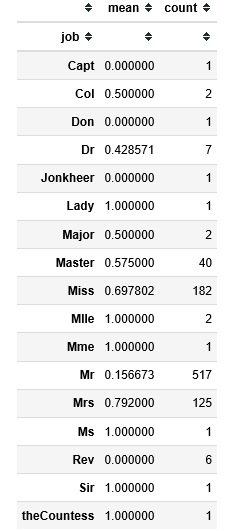
Jobっぽいものごとの生還率を出しました。明らかに男が死んで女性が生きてます。
Rev(牧師)の死亡率は高いので、この方々は問答無用で死亡にしてもよさそうです。
Sir(さー),countess(伯爵),Mme(まだむ),Mlle(まどもあぜる),Ladyとかいう、偉そうな、地位が高そうな、特に女性の敬称がついてる人はかなり生き残っていたことがわかります。
同じことをtestにも行ったところ、出てきた職業が少ないことを発見しました。
display(df_test.groupby(by=["job"]).agg(["count"]))
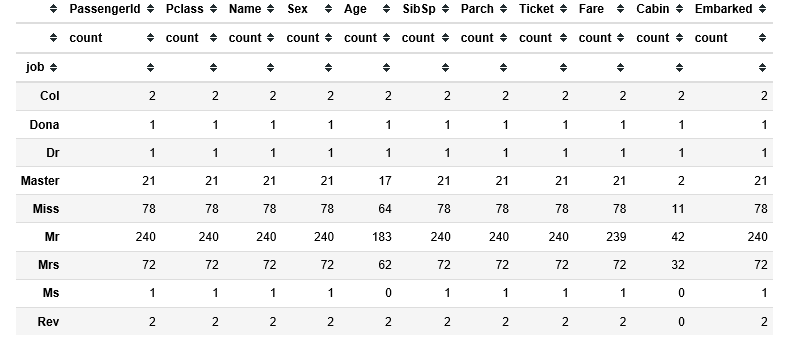
というわけで、Miss Mr Mrs Msについては、自動的にやってくれる何かに頼るとして、Master(子供)に注目します。
子供
子供の生存に相関がありそうなデータが、唯一、SibSpっぽいです(人間コンピュータの結果)
SibSpは「兄弟、配偶者の数」らしいので、緊急時には、多数が集まると正常性バイアスが働いてしまったと考えられます。ということは、同じファミリーネームを持つ人は全員死んだ可能性が高いことも示されました。
というわけで、ファミリーネームの項目を作ります、
この記事を書いてる時点で、このデータに含まれる名前のどの部分がファミリーネームかわかってません。いろいろ確かめた結果、敬称の左側がファミリーネームっぽいです。
参考 に文字列含む検索があったので検索して確かめました。
sep_forward = df_train["Name"].str.split(",",expand=True)
sep_backward = sep_forward[1].str.split(".",expand=True)
fname = sep_forward[0].str.replace(" ","")
job = sep_backward[0].str.replace(" ","")
df_train["job"] = job
df_train["fname"] = fname
trainとtestにどれだけの共通ファミリーネームがあるか調べます。
積集合?を使いました。Qiita参考
きっとpandasだけで実現する方法はあると思いますが、わからないのでこうやってます。
display(len(set(df_train["fname"].unique().tolist()) & set(df_test["fname"].unique().tolist())))
# 144
おそらく、144家族くらい共通してます。最優先の子供を死なすような家族はたぶん、全滅してます。間違いなく男は死んでるでしょう(ひどい)
というわけで、JobがMasterでSurviveが1の家族を抽出してみます。
suv_fname = df_train[(df_train["job"]=="Master") & (df_train["Survived"]==1)]["fname"].tolist()
for ifname in suv_fname:
display(df_train[df_train["fname"]==ifname])
suv_fname = df_train[(df_train["job"]=="Master") & (df_train["Survived"]==1)]["fname"].tolist()
for ifname in suv_fname:
display(df_train[df_train["fname"]==ifname])
この結果、Survived == 0 の家族の全滅は確実っぽいです。生存については、そこそこまばらです。
そしていろいろみてると、9才の女性にMissが使われてて、オイ!ってつっこみました。
というわけで、15才以下については全員、childってJobにしようと決意しました。
というわけで、上記の解析がほぼ吹っ飛んでしまったので、その1終了です。orz 英語わかんねーよ!