はじめに
この記事はGizumoエンジニア Advent Calendar 2015の24日目の記事です。
株式会社Gizumoというまだ出来て半年という若い会社でWebアプリエンジニアやってる@suzumiです。
アドベントカレンダー2回目の記事になります。
一回目の記事は「IoT - node.jsを使ってWebからエアコンを遠隔操作できるようにしてみた」です。
よければ合わせてご覧下さい。
お題
まずはじめにKaggleを知っておきましょう。
Kaggleとは
Kaggleは企業や研究者がデータを投稿し、世界中の統計家やデータ分析家がその最適モデルを競い合う、予測モデリング及び分析手法関連プラットフォーム及びその運営会社である。
-- WikiPediaより
引用にある通り、企業などがデータを投稿して、それに対して分析やモデリングをして最適なモデリングを競い合うサイトです。
データを投稿してコンペを開催する企業側などにとっては、優秀なデータサイエンティストのリクルーティングに使えること、
コンペに参加する人は自分の実力を図ったり勉強のためだったりと、双方にメリットがあるプラットフォームになっています。
またコンペによっては賞金が出たりするものもあり、300万ドル(3.5億円)の賞金が出るコンペもあったりするようです。
ユーザーランキングも公開しており、ここに載れば優秀なデータサイエンティストとして世界中から注目され引く手あまたとなります。
GitHubでのスター数がステータスとなるように、データサイエンティストにとってはランキングがステータスになるんだと思います。
リクルートが"Kaggle"と日本企業初の共催となるデータ予測コンペティション「RECRUIT Challenge - Coupon Purchase Prediction」開催を決定と夏にニュースで話題となり、日本でもKaggleの知名度がドンと増したと思います。
僕もこのニュースでKaggleの存在を知った口です(テヘ)
最近は歩けばどこもかしこも「データサイエンス」やら「機械学習」やら「人工知能」などの単語が聞こえてくるようになりました。
当然流行りもの好きな僕は黙っているわけにはいきません。
ということで今回はKaggleでチュートリアル的なコンペの1つである「タイタニック号の生存予測」に挑戦してみたいと思います。
ちなみに実行環境は以下の通りです。
数値計算系ライブラリを色々入れるのが面倒くさかったんでAnaconda入れました。
- Python3.5
- iPython notebook
データの用意
まずはデータを用意しましょう。まずはコンペページに飛びます。
左にあるダッシュボードの「data」からデータをダウンロードします。
とりあえずよくわからないのでそれっぽい以下のcsvをダウンロードしてきます。
- train.csv (59.76 kb)
- test.csv (27.96 kb)
中身を見てみるとtrain.csvには約900人分の乗客リスト(生存結果あり)、test.csvには約400人の乗客リスト(生存結果不明)になっていますね。
名前から察するにtrain.csvから予測モデルを作り、実際にtest.csvの乗客リストをテストして予測してみる…という流れでしょうか。。
7割くらいのデータから予測モデルを立てて残り3割くらいのデータでテストする、というのはどこかで聞いた覚えがあるのでまさにこれですね。
最初からデータが別れているのはありがたいです。
ランダムフォレスト
ランダムフォレストを使って予測してねとコンペタイトルにあるのでランダムフォレストを使えばいいんでしょうか。
そもそもランダムフォレストってなんぞや?ということでWikiで調べてみました。
2001年に Leo Breiman によって提案された[1]機械学習のアルゴリズムであり、分類、回帰、クラスタリングに用いられる。決定木を弱学習器とする集団学習アルゴリズムであり、この名称は、ランダムサンプリングされたトレーニングデータによって学習した多数の決定木を使用することによる。対象によっては、同じく集団学習を用いるブースティングよりも有効とされる。
-- WikiPediaより
そもそも決定木とは
決定木は学習アルゴリズムの1つで、質問してYes、Noで分岐していき、木構造を作成することで完成されます。「完全に答えが出るまで分岐させ、これ以上分岐できないのであれば、そこで終わり」 というアルゴリズムです。
-- こちらを引用
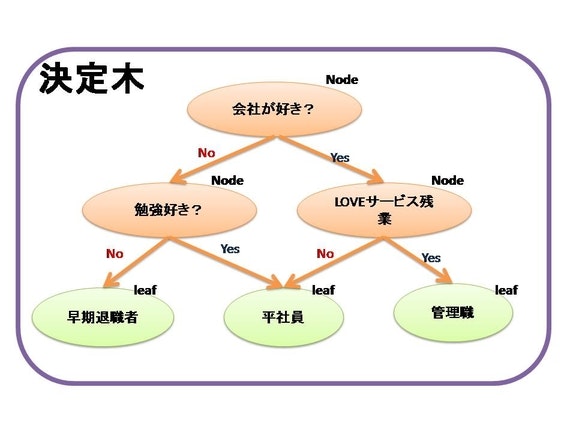
つまり多数の決定木で集団学習(アンサンブル学習)させることで精度を高める集団学習モデルのことらしいです。
そしていかにして決定木を作っていくことが学習モデルの肝になるようです。
データを見てみる
train.csvを開いて眺めてみます。

まずは変数の意味を調べてみました。
- PassengerID: 乗客ID
- Survived: 生存結果 (1: 生存, 2: 死亡)
- Pclass: 乗客の階級 1が一番位が高いそう
- Name: 乗客の名前
- Sex: 性別
- Age: 年齢
- SibSp 兄弟、配偶者の数。
- Parch 両親、子供の数。
- Ticket チケット番号。
- Fare 乗船料金。
- Cabin 部屋番号
- Embarked 乗船した港 Cherbourg、Queenstown、Southamptonの3種類があります
とりあえずcsvを読み込んでみましょう。
データ加工、集計が得意なpandasを使います。
性別がmale,femaleと扱いづらいので、
male:男性は0,female:女性は1として扱います。
import pandas as pd
import matplotlib.pyplot as plt
df= pd.read_csv("train.csv").replace("male",0).replace("female",1)
欠損値の扱い
Ageにはいくつか欠損してるレコードがありますね。
欠損しているところには何かしら値を埋める必要があるそうですが、とりあえず0とかで埋めると後の予測モデルに影響が出ます。
今回の場合はレンジがそんなに広くないので全乗客の年齢の平均値でもいいんですが、こういう場合は中央値を使うのが無難だと思うので欠損しているところは中央値を当てはめるようにします。
df["Age"].fillna(df.Age.median(), inplace=True)
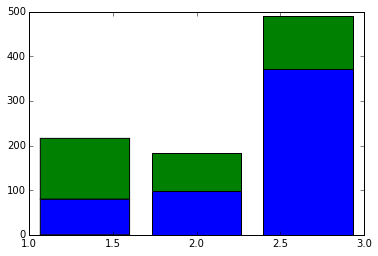
客室のグレードごとにヒストグラムを出力してみます。
split_data = []
for survived in [0,1]:
split_data.append(df[df.Survived==survived])
temp = [i["Pclass"].dropna() for i in split_data]
plt.hist(temp, histtype="barstacked", bins=3)
左から一等、二等、三等客室で、緑色が生存した人で青色が死亡した人です。
一等客室の乗客は半分以上が生き残っているようです。
一方で三等客室の乗客は1/5の人しか生き残らなかったようですね。
おそらく一等客室の乗客が優先されて救命ボートに乗ったのだと思います。
次に年齢ごとにヒストグラムを出してみます。
temp = [i["Age"].dropna() for i in split_data]
plt.hist(temp, histtype="barstacked", bins=16)
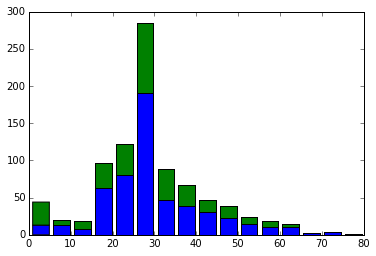
かなり真ん中だけ突出していますね。。
これは先程欠損値に中央値を代わりに入れてしまったのが原因でした。
年齢が欠損している人は省いてヒストグラムを出力し直してみます。
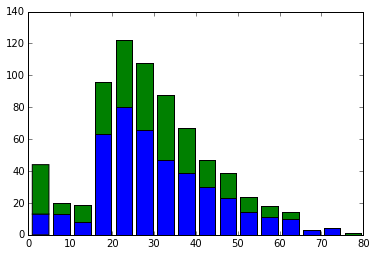
いい感じの形になりました。
見てみると意外とお年寄りが亡くなっています。
反対に幼児はかなり生存率が高いですね。
ここから察するに赤ちゃんを連れた人は優先して救命ボートに乗れたようです。
データ整形
データを見ていて思っていたのが、5人以上などの大家族は生存率が低いということです。
チケット番号を見るとユニークではないらしく番号が被る人たちもいるようです。同じ部屋だったのか、それともまとめて購入すると同じ番号になるのかはわかりません。
例えば「347082」のチケット番号の人たちはみんなファミリーネーム?が「Andersson」と共通です。年齢を見てみるとどうやら7人家族のようです。グレードは3なので下の階層の部屋だったのでしょうか、全員死亡しています。
「家族の人数」用の変数を追加します。そして不要な変数を削除します。
df["FamilySize"] = df["SibSp"] + df["Parch"] + 1
df2 = df.drop(["Name", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Embarked"], axis=1)
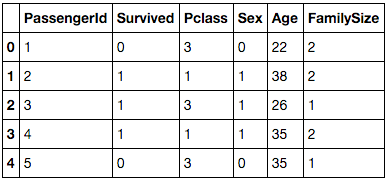
pandasのdataframeそのままではscikit-learnへ型の違いで渡すことができないそうなので型を確認してみます。
df2.dtypes
# 出力結果
PassengerId int64
Survived int64
Pclass int64
Sex int64
Age float64
FamilySize int64
dtype: object
問題なく渡せそうですね。
実際に学習させてみる
scikit-learnはpythonのための機械学習ライブラリです。
RandomForestClassifierを使って決定木を作成し予測します。
ただし学習データとして必要なのはPclass以降の変数なので分離します。
PassengerIdはkaggleが勝手に振ったIDなので要りません。
生存結果であるSurvivedは正解データとします。
train_data = df2.values
xs = train_data[:, 2:] # Pclass以降の変数
y = train_data[:, 1] # 正解データ
実際に学習させて予測モデルを作ります。
決定木の数は参考サイトをもとに100に設定しています。
そしてtest.csvの内容もtrain.csvと同様にデータの整形をします。
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators = 100)
# 学習
forest = forest.fit(xs, y)
test_df= pd.read_csv("test.csv").replace("male",0).replace("female",1)
# 欠損値の補完
test_df["Age"].fillna(df.Age.median(), inplace=True)
test_df["FamilySize"] = test_df["SibSp"] + test_df["Parch"] + 1
test_df2 = test_df.drop(["Name", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Embarked"], axis=1)
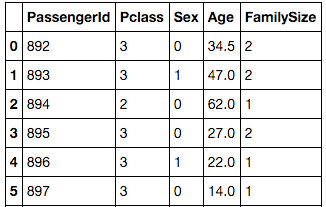
予測モデルをもとに実際に予測してもらいます。
test_data = test_df2.values
xs_test = test_data[:, 1:]
output = forest.predict(xs_test)
print(len(test_data[:,0]), len(output))
zip_data = zip(test_data[:,0].astype(int), output.astype(int))
predict_data = list(zip_data)
predict_dataの中身を見ると予測してくれた結果がリストになっています。

そして最後にリストをcsvに書き込みましょう。
カレントディレクトリにpredict_result_data.csvが出来ているはずです。
import csv
with open("predict_result_data.csv", "w") as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["PassengerId", "Survived"])
for pid, survived in zip(test_data[:,0].astype(int), output.astype(int)):
writer.writerow([pid, survived])
KaggleにSubmitする
予測モデルを立てて実際に生存予測をしたcsvができました。
これをKaggleに送りつけましょう。
タイタニックのコンペページにいって左カラムにある「My Submissions」→「Make a submission」からアップロードして送りつけます。
すると最終的にスコアが表示されてランキングにのります。
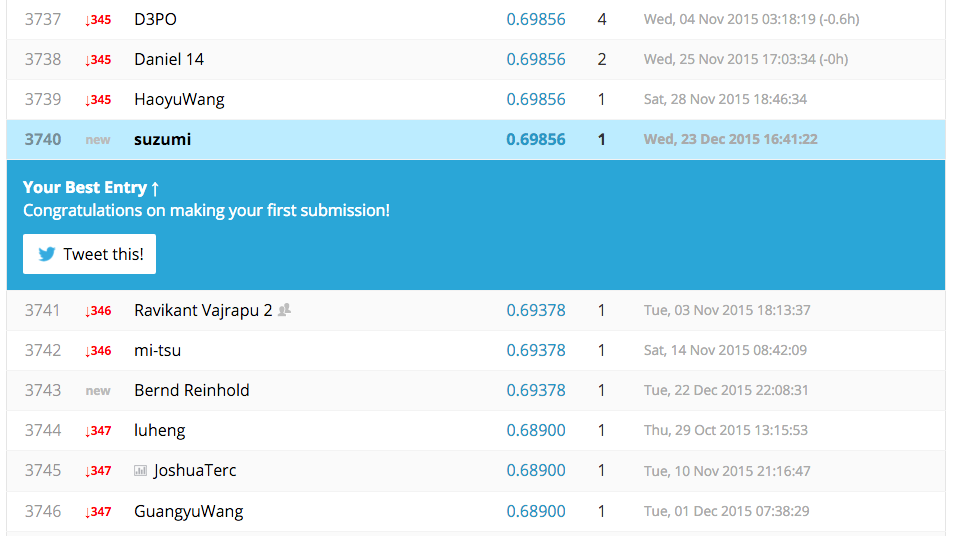
スコアが0.69856でした。
ベースラインのスコアが0.76555なので足りませんね。。笑
今回は予測モデルを立ててKaggleに送りつけるところまでがミッションだったので、まぁよしとしましょう。。
まとめ
僕は最初は機械学習系アルゴリズムの本を買って読んだりしていましたが、まずはライブラリを使って試してみることが一番いいのかなと感じました。
Kaggleという素敵なサイトがあるのでここで腕試しや、他人の書いたスクリプトを見て研究したりしてみるのもいいのかもしれませんね。
ぜひ機械学習ライフを始めてみてはいかがでしょうか。
参考サイト
kaggle2回目 タイタニック号の生存者予測
kaggle初挑戦: タイタニック乗客のプロフィールから生存率をランダムフォレストで予測してみた
機械学習によるタイタニック号の生存者予測 with Python