はじめに
機械学習のお勉強として、Kaggleのチュートリアルである「Titanic: Machine Learning from Disaster」にチャレンジしてみました。
【Kaggle初心者入門編】タイタニック号で生き残るのは誰? という素晴らしい記事を参考にさせていただき、Pythonを使ってデータを読み込むところから、機械学習のモデルを作成・予測してKaggleへデータを投稿するところまで実施しました。
ただし、この参考記事では、決定木を使って、とりあえず動かしてみるところに主眼が置いてあるので、正解率は76%程度です。
そこからは、自分で試行錯誤して**正解率80%**を超えることを目標に設定しました。
1.環境構築
環境、フレームワーク、ライブラリなどは以下の通りです。
- MacOSHighSierra(10.13.4)
- Pycharm Community Edition 2018.1.4
- python 3.6.5
- conda 4.5.4
- Pandas
- Numpy
- scikit-learn
2.事前準備
(1)Kaggle登録
Kaggleのアカウントを持っていなかったので、新規登録しました。
https://www.kaggle.com
(2)データ取得
次に、以下2つのデータファイルをダウンロードします。
https://www.kaggle.com/c/titanic/data
- train.csv(学習用データ)
- test.csv(検証用データ)
*「gender_submission.csv」は、アップロードする結果のデータ形式を確認するためのサンプルファイルです。学習、評価には用いません。
3.データ整備
(1)データの中身を確認
【Kaggle初心者入門編】タイタニック号で生き残るのは誰? に従い、一通り実施しました。
(2)欠損値を補強
- 「Age」を中央値、「Embarked」を最頻値で補強
- カテゴリカルデータの数値化
- Sexは「male」=0、「female」=1
- Embarkedは「S」「C」「Q」をそれぞれ 1、2、3 に変換
4.モデル(決定木)を作成して投稿
参考記事の「予測モデル その2 「決定木 + 7つの説明変数」」に従って、モデルを作成し投稿しました。
結果のスコアは、予定通り「0.76076」(約76%) でした。
5.追加試行
(1)データを加工
データ分析のスキルがないので、まずはググって、先行者の知見を探しました。
以下を参考に家族の人数を訓練データに加えました。
これまでは、乗客の生死を左右するの属性は、 客室の等級"Pclass",性別"Sex",年齢"Age",運賃"Fare"だけであると 考えてきました。 しかし、他にも重要な属性があるかもしれません。 例えば、一緒に乗船している家族の人数もまた生死を左右していたと考えられます ^11 。 というのは、家族で一緒に旅をしていた人は、救命ボートに乗る順番が回ってきたとしても、 家族全員が揃っていなければ、ボートで脱出せずにタイタニック号に留まっていたのではないかと想像できるからです。 この仮説が正しければ、 大家族であればあるほど救命ボート乗り場に集合するまでに時間がかかるので、 それだけ生存確率が下がるはずです。
(引用元)データ分析入門としてのKaggleコンペ「タイタニック乗客の生存予測」
(2)アルゴリズムを「勾配ブースティング」へ変更
勾配ブースティングって精度がでるらしい、という情報だけ持っていたので、モデル作成のアルゴリズムを変更することに。
*勾配ブースティングは以下記事が参考になります。
pythonでランダムフォレストとアンサンブル学習まとめ
もちろん、実装したことはないので、サンプルコードやパラメータ値に関しては、
ひたすらググりつつ、試行錯誤しながら、以下のようにしました。
from sklearn.ensemble import GradientBoostingClassifier
features = train_two[["Pclass", "Age", "Sex", "Fare", "family_size", "Embarked"]].values
target = train["Survived"].values
forest = GradientBoostingClassifier(n_estimators=55, random_state=9)
forest = forest.fit(features, target)
初め、パラメーターを「n_estimators=60, random_state=10」としていたのですが、そのときは、79%。
最終的に、「n_estimators=55, random_state=9」としたら、「0.80382」と、無事に目標である80%超えを達成しました。
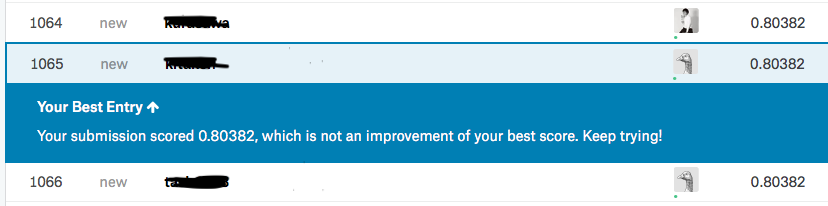
環境構築を除き、所要時間は大体2時間くらいでした。
6.まとめ
さて、今回、はじめて機械学習のプログラムを実装して、Kaggleのチュートリアルにチャレンジしたのですが、いくつか感じることがあったので、備忘録代わりにメモをします。
(1)データの前処理が大事
機械学習には、データの前処理が大事で、現場ではこうしたタスクに多くの時間を費やす。というのは聞いたことがありましたが、実際にチュートリアルを試してみて、欠損値の補完やデータ形式の変更などデータ加工の重要さを実感できました。
プログラムを書くこと自体は数十行で済みます。そもそもデータにどういう特性があるか、事前に分析すること、そうした分析スキルがとても重要なんだなと思いました。
(2)世の中の知見を使うと素人でもなんとかなる
便利なライブラリ、試行錯誤の結果をまとめたブログ、サンプルコードなど、機械学習素人の私でも2時間程度で何かしら動くものが出来上がるという、とても便利な世の中になったものだと実感しました。
(3)そう甘くない、まだまだこれから
とはいうものの、高精度を出すのはそう簡単ではないと思いました。今回は、79%くらいからなかなか精度が上がらない時期がありました。
とにかく動かすことを優先していたため、データをきちんと解釈することを放棄していましたし、アルゴリズムも十分理解していないため、苦肉の策として、モデル作成時のパラメーターを適当に変更してみることにしました。
結果、たまたまうまくいって、80%を超えることができたわけですが、何の価値もないことは重々承知しています。今後は、データ分析のスキル向上、モデルのチューニングスキルの向上に努め、根拠をもって精度を高めていけるようにしていこうと思いました。
おわりに
最近は、パワーポイントとエクセルばかりいじっていて、それに忙殺されていたので、今回久しぶりに実装&新しい分野にトライしましたが、やはり楽しいですね。継続していきたいと思いました。
為ご参考までに、ソースコードを貼り付けておきます。
import pandas as pd
import numpy as np
train = pd.read_csv("./train.csv")
test = pd.read_csv("./test.csv")
# 欠損データ前処理 代理データを中央値や最頻値で置き換える
train["Age"] = train["Age"].fillna(train["Age"].median())
train["Embarked"] = train["Embarked"].fillna("S")
# 前処理 カテゴリカルデータの数値化 Sexは「male」「female」、Embarkedは「S」「C」「Q」の3つ。これらを数字に変換
train["Sex"][train["Sex"] == "male"] = 0
train["Sex"][train["Sex"] == "female"] = 1
train["Embarked"][train["Embarked"] == "S"] = 0
train["Embarked"][train["Embarked"] == "C"] = 1
train["Embarked"][train["Embarked"] == "Q"] = 2
# test も同様に前処理
test["Age"] = test["Age"].fillna(test["Age"].median())
test["Sex"][test["Sex"] == "male"] = 0
test["Sex"][test["Sex"] == "female"] = 1
test["Embarked"][test["Embarked"] == "S"] = 0
test["Embarked"][test["Embarked"] == "C"] = 1
test["Embarked"][test["Embarked"] == "Q"] = 2
test.Fare[152] = test.Fare.median()
# 家族数を追加
train_two = train.copy()
train_two["family_size"] = train_two["SibSp"] + train_two["Parch"] + 1
test_two = test.copy()
test_two["family_size"] = test_two["SibSp"] + test_two["Parch"] + 1
# scikit-learnのインポート
from sklearn.ensemble import GradientBoostingClassifier
# 「train」の目的変数と説明変数の値を取得
target = train["Survived"].values
features = train_two[["Pclass", "Age", "Sex", "Fare", "family_size", "Embarked"]].values
# モデルは勾配ブースティング
forest = GradientBoostingClassifier(n_estimators=55, random_state=9)
forest = forest.fit(features, target)
# testから使う項目の値を取り出す
test_features = test_two[["Pclass", "Age", "Sex", "Fare", "family_size", "Embarked"]].values
# 予測をしてCSVへ書き出す
my_prediction_forest = forest.predict(test_features)
PassengerId = np.array(test["PassengerId"]).astype(int)
my_solution_forest = pd.DataFrame(my_prediction_forest, PassengerId, columns=["Survived"])
my_solution_forest.to_csv("forest3.csv", index_label=["PassengerId"])