概要
- PJDV 5.7~5.7.1、PJDV 5.7.3の続き。
- O'Reilly Japan - PythonとJavaScriptではじめるデータビジュアライゼーション(PJDV)の勉強用
- PJDV 6.4「最初のScrapyスパイダー」(nwinners_list_spider.py)のXPathをscrapy shellで具体的に見ていきます。
準備
webページの読み込み
以下のいずれかで読み込んでおきます。
-
scrapy shell http://en.wikipedia.org/wiki/List_of_Nobel_laureates_by_countryで起動- 参考 : PJDV 6.3.1章 or scrapy shellでスクレイピングする - Qiita
-
scrapy shell(引数のurlなし)で起動後、fetch("http://en.wikipedia.org/wiki/List_of_Nobel_laureates_by_country") - scrapy crawlからscrapy shellを起動する
- 後述
view(response) してブラウザを起動させておくと便利です。
XPath記述箇所
h2s = response.xpath('//h2')
説明
| 省略構文 | 完全な構文 | 意味 | 参考 |
|---|---|---|---|
| //h2 | /descendant-or-self::node()/child::h2 | 全h2要素 |
参考1 参考2 |
調査
何が受け取れているか確認してみます。
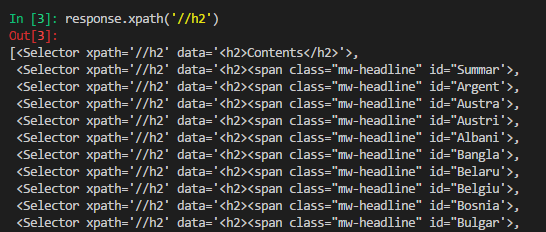

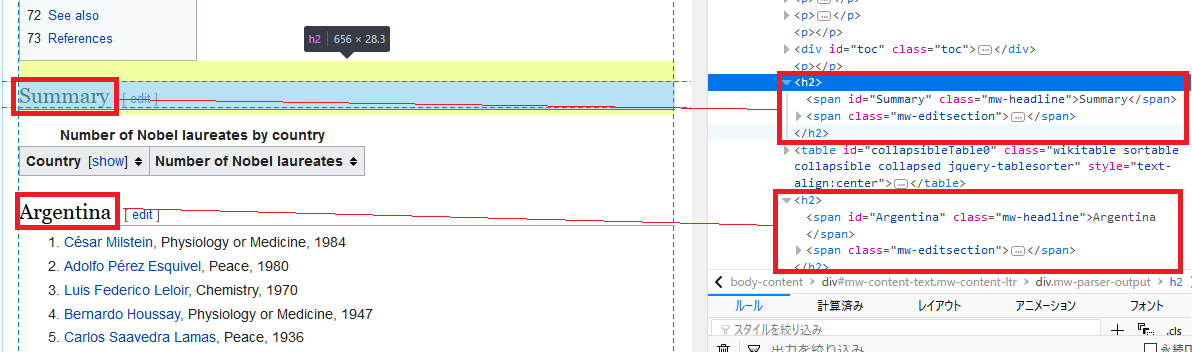
country = h2.xpath('span[@class="mw-headline"]/text()').extract()
winners = h2.xpath('following-sibling::ol[1]')
for w in winners.xpath('li'):
text = w.xpath('descendant-or-self::text()').extract()
tips
scrapy crawlからscrapy shellを起動する
nwinners_shell.py
# -*- coding: utf-8 -*-
import scrapy
class NWinnerShell(scrapy.Spider):
name = 'nwinner_shell'
allowed_domains = ['en.wikipedia.org']
start_urls = [
"http://en.wikipedia.org/wiki/List_of_Nobel_laureates_by_country"
]
def parse(self, response):
scrapy.shell.inspect_response(response, self)
参考
Scrapyの取得結果をブラウザで開く - Qiita
scrapyでよく使うxpath, cssのセレクタ-Python Snippets
Python Tips:リストから重複した要素を削除したい - Life with Python