概要
- O'Reilly Japan - PythonとJavaScriptではじめるデータビジュアライゼーション(PJDV)の勉強用です。
- 5.7~5.7.1章(BeautifulSoup)で記載通りにいかなかった箇所を補足+コメントしています。
- 5~5.2章のrequestsに関してはQiitaに@Amtkxaさんの記事があります。
- 6章(Scrapy)のサンプルコードは著者のGitHubにあります。
使い方
- サンプルコードを"pjdv_s5_7_s5_7_1.py"で保存
- ipythonでget_nobel_laureates()を実行。
- wikipediaにアクセスするので連続実行に注意。
In [70]: import pjdv_s5_7_s5_7_1
In [71]: get_nobel_laureates()
Out[71]:
[{'category': 'Physics',
'href': '/wiki/Wilhelm_R%C3%B6ntgen',
'name': 'Wilhelm Röntgen',
'year': 1901},
{'category': 'Chemistry',
'href': '/wiki/Jacobus_Henricus_van_%27t_Hoff',
'name': "Jacobus Henricus van 't Hoff",
'year': 1901},
サンプルコード
pjdv_s5_7_s5_7_1.py
# -*- coding: utf-8 -*-
# 概要
# [PJDV]s5.7, s5.7.1を理解するために作成したスクリプト
# 略語など
# [PJDV] : 「O'Reilly Japan - PythonとJavaScriptではじめるデータビジュアライゼーション」のこと
# [PJDV]s5.7: [PJDV]の5.7章のこと
# [PJDV]p124-p126 : [PJDV]の124ページからp126ページのこと。
# スクリプト内の補足への参照は、# [数値]
# スクリプト内の補足は、スクリプト末尾にまとめてある。
# 使い方
# ipythonでget_nobel_laureates()を実行。wikipediaにアクセスするので注意する。
# In [70]: import pjdv_s5_7_s5_7_1
# In [71]: get_nobel_laureates()
# Out[71]:
# [{'category': 'Physics',
# 'href': '/wiki/Wilhelm_R%C3%B6ntgen',
# 'name': 'Wilhelm Röntgen',
# 'year': 1901},
# {'category': 'Chemistry',
# 'href': '/wiki/Jacobus_Henricus_van_%27t_Hoff',
# 'name': "Jacobus Henricus van 't Hoff",
# 'year': 1901},
from bs4 import BeautifulSoup # https://www.crummy.com/software/BeautifulSoup/bs4/doc/
import requests
import requests_cache
import urllib
import re
requests_cache.install_cache()
def join_url(base_url, target):
""" urlを結合する """
return urllib.parse.urljoin(base_url, target)
def get_soup(url, parser="lxml", headers={'User-Agent': 'Mozilla/5.0'}):
""" urlに対応したsoup(タグツリー)を返す """
# print("requests.get(" + url + ")")
response = requests.get(
url, headers=headers
)
return BeautifulSoup(response.content, parser)
def get_column_titles(table):
""" 列ヘッダディクショナリリストを得る。[PJDV]s5.7 タグの選択, [PJDV]s5.7.1 図5-2参照
列ヘッダディクショナリ
- タイトル(name)
- リンク(href)
"""
# 解析するhtml構造 : <tr><th><a href=リンク>タイトル</a></th><th><a href=リンク>タイトル</a></th>...</tr>
th = table.select_one('tr').select('th') # [2]
titles=[] # [3]
# <th>を解析する
for t in th: # [5]
item = {
"name" : t.text.replace("\n", " ").strip(), # [4]
"href": None
}
# <a>を解析する
a = t.select_one("a")
if a:
item["href"]=a.attrs["href"]
titles.append(item)
return titles
def get_nobel_categories(table):
""" 受賞分野リスト (categories)を得る """
titles = get_column_titles(table)
categories = []
for t in titles[1:]: # Yearを除外する
item = {
"category" : t["name"],
"href": t["href"]
}
categories.append(item)
return categories
def get_nobel_winners(table, categories):
""" 受賞者ディクショナリリスト(nobel_winners)を得る。 [PJDV]s5.7.1 p128 get_Noble_winners()
受賞者ディクショナリ
- 受賞年 (year)
- 受賞分野 (category)
- 受賞した人物の名前 (name)
- 受賞した人物のリンク (href) -- 注釈へのリンクは除く
"""
# 解析するhtml構造 : [8]を参照
nobel_winners = []
for r in table.select('tr')[1:-1]: # [6]
year = int(re.sub(r'\[.+?\]', "", r.select('td')[0].text)) # [7]
for i, td in enumerate(r.select('td')[1:]):
for a in td.select('a'):
if a.attrs["href"].startswith("#endnote"):
pass
else:
# print(str(year) + " : " + str(i) + " " + categories[i]["category"] + " : " + a.text)
item = {
"year":year,
"category":categories[i]["category"],
"name":a.text,
"link":a.attrs["href"]
}
nobel_winners.append(item)
return nobel_winners
def get_nobel_laureates():
BASE = 'https://en.wikipedia.org'
TARGET= 'wiki/List_of_Nobel_laureates'
# ノーベル賞ページにリクエストを行う [0]
soup = get_soup(join_url(BASE,TARGET))
table = soup.select_one('.wikitable') # [1]
categories = get_nobel_categories(table)
nobel_winners = get_nobel_winners(table, categories)
return nobel_winners
def main():
print(get_nobel_laureates())
if __name__ == '__main__':
main()
# [0]
# データ取得対象となるアドレス
# List of Nobel laureates - Wikipedia.html
# https://en.wikipedia.org/wiki/List_of_Nobel_laureates
# [1]
# このケースだけかもしれないが、以下でも同じ
# tbl = soup.select('table.sortable.wikitable')
# tbl = soup.select_one('table.sortable.wikitable')
# tbl = soup.select('.wikitable')
# [2]
# List of laureatesの列見出しは、上下に同じものが記載されているため
# [PJDV]p125-p126の流れで実装していくと、同じものが二度登録されてしまう。
# [PJDV]p127のget_column_titles()は、これが考慮されているようで、先にselect_one('tr')で
# 下部の列見出しを排除している様子
# [3]
# 得られるデータの例。
# titles = [{'category': 'Year', 'href': None}, {'category': 'Physics', 'href': '/wiki/List_of_Nobel_laureates_in_Physics'},]
# [4]
# Physiology or Medicineだけ、タイトルのテキストに改行コード(\n)が入っている
# [PJDV]s.5.7.1 p128のget_Nobel_winnersの受賞者ディクショナリリストでは改行コードを取り除いてないデータが出ている。
# 個人的な好みで.replace("\n", " ")で取り除いている。また、'.wikitable'の内容なら、.strip()は無くてもいい。
# [5]
# [PJDV]s.5.7.1 p127のget_column_titles()では、
# "テーブルヘッダをループし、最初の年の列([1:])を無視する。"
# とコメントされている。(.select('th')[1:]として意図的にYearを取り除いている)
# 処理の意味はわかるが、最終的に何をしたくてこうなっているかはわからない。
# [PJDV]s5.7.1 p128 get_Noble_winners()でcategoryとしてtitlesを参照するからYearの列が邪魔なのであろう。
# このスクリプトでは、get_nobel_categories()で、ラップすることにした。
# [6]
# [PJDV]s.5.7.1 p128のget_Noble_winners()のコメントでは、
# "図5-2に対応する、2行目から始まる年の全行を取得する"となっているが、
# おそらく"上下の列ヘッダを除く全行"という意図だと思う。そうでないと[1:-1]の-1が説明できない。
# [7]
# テキスト通り、year = int(r.select_one('td').text)としたいところだが、
# "2016[11]"というデータがあったので"[11]"を除去したあとでint()する。
# 2015 ・・・ OK.int()が成功する
# 2016[11] ・・・ NG.int()が失敗する。[11]はページ内のReferencesへのリンク
# select_one('td')ではなく、select('td')[0]は次のループとの関係からこういうほうがいいかなという好み
# [8]
# <tr><td>受賞年</td>
# <td>
# <a href=受賞者1のリンク>受賞者名</a>
# </td>
# という構造を解析する(<span>もあるが気にしない)。[PJDV]s5.7.1 図5-2参照
# また、受賞した分野(category)については、categoriesリストから"順序的対応"で取得する。
# なお、複数の受賞者がいる場合、
# <tr><td>受賞年</td>
# <td>
# <a href=受賞者1のリンク>受賞者名1</a>;
# <a href=受賞者2のリンク>受賞者名2</a>
# </td>
# という構造になるので注意する。
# つまり、select_one('a')は利用できず、select('a')でループにより処理する必要がある。
補足の補足
[2]および[6]について
# [2]
# List of laureatesの列見出しは、上下に同じものが記載されているため
# ...
# [6]
# [PJDV]s.5.7.1 p128のget_Noble_winners()のコメントでは、
# "図5-2に対応する、2行目から始まる年の全行を取得する"となっているが、
# おそらく"上下の列ヘッダを除く全行"という意図だと思う。そうでないと[1:-1]の-1が説明できない。
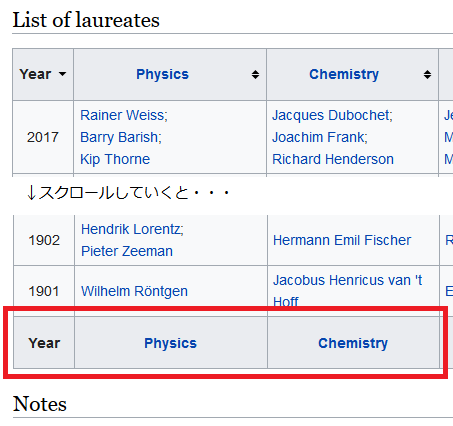
table.select('tr')[-1]が何者かしらべてみる。
In [95]: soup = _get_nobel_soup(parser="lxml")
...: table = soup.select_one('.wikitable')
...: table.select('tr')[-1]
Out[95]:
<tr>
<th>Year</th>
<th width="16%"><a href="/wiki/List_of_Nobel_laureates_in_Physics" title="List of Nobel laureates in Physics">Physics</a></th>
<th width="16%"><a href="/wiki/List_of_Nobel_laureates_in_Chemistry" title="List of Nobel laureates in Chemistry">Chemistry</a></th>
# 略
下段の列ヘッダだった
[4]について
# [4]
# Physiology or Medicineだけ、タイトルのテキストに改行コード(<br>, '\n')が入っている
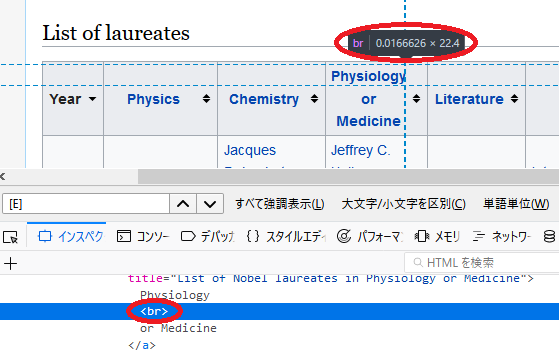
In [82]: soup = _get_nobel_soup(parser="lxml")
...: table = soup.select_one('.wikitable')
...: th = table.select_one('tr').select('th')
...: test=[]
...: for t in th:
...: test.append(t.text)
In [83]: test
Out[83]:
['Year',
'Physics',
'Chemistry',
'Physiology\nor Medicine', # <-- <br>が改行コード'\n'になっている
# 略
[7]について
# [7]
# テキスト通り、year = int(r.select_one('td').text)としたいところだが、
# "2016[11]"というデータがあったので"[11]"を除去したあとでint()する。
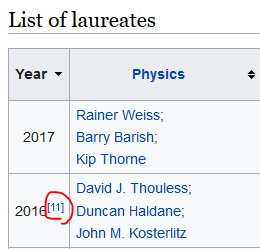
In [76]: soup = _get_nobel_soup(parser="lxml")
...: table = soup.select_one('.wikitable')
...: categories = _get_novel_categories(table)
In [77]: def _get_years(table, categories):
...: for r in table.select('tr')[1:-1]:
...: print(r.select('td')[0].text)
In [78]: _get_years(table, categories)
# 略
2015
2016[11] # <-- "[11]"により、int()が失敗する
2017
[9]について
# [9]
# 複数の受賞者がいる場合、
# <tr><td>受賞年</td>
# <td>
# <a href=受賞者1のリンク>受賞者名1</a>;
# <a href=受賞者2のリンク>受賞者名2</a>
# </td>
# という構造になるので注意する。
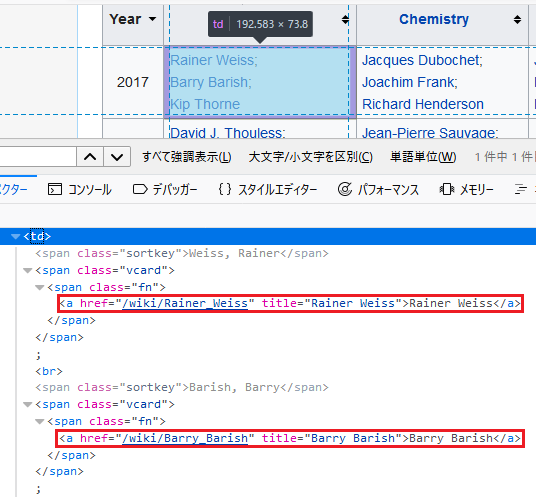
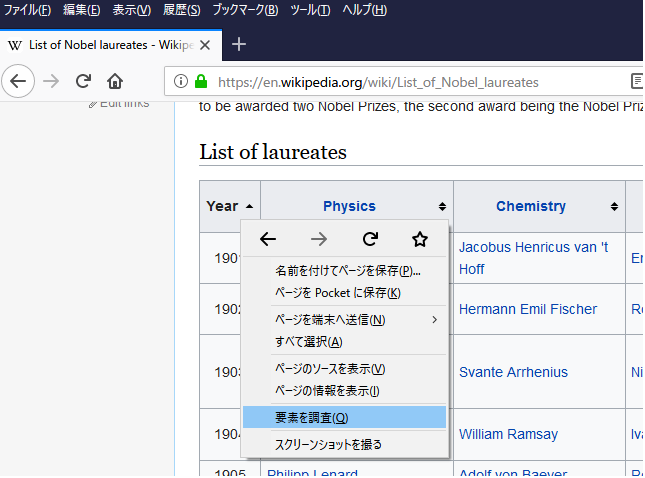
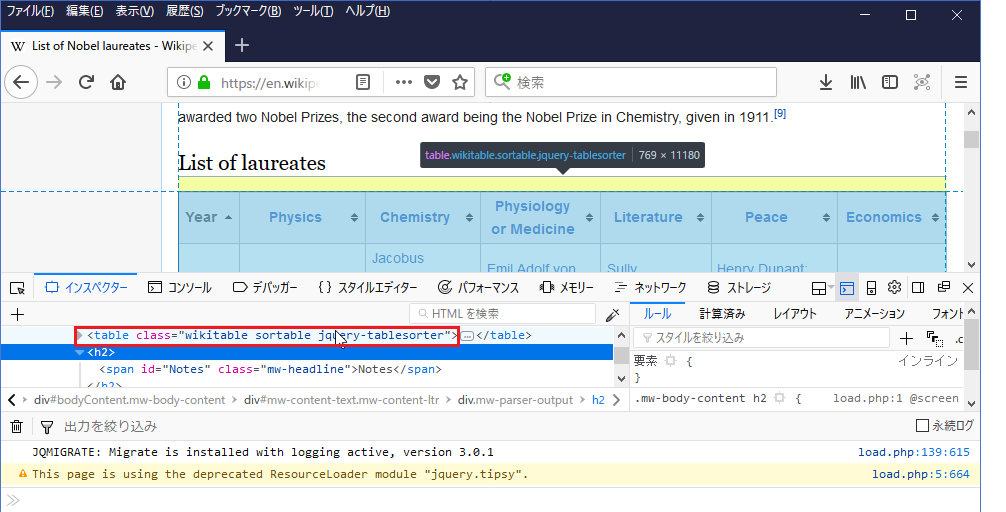
html要素調査 with Firefox
[PJDV]s.4.3.3 ではFirebugを挙げているが、今はFirefox本体に統合されている。
右クリック→要素を調査で実施できる。
List of Nobel laureates - Wikipedia