はじめに
scrapyにはshellモードがあり、インタラクティブにスクレイピングすることができます。chromeと合わせて使うと比較的簡単にWebページからスクレイピングできます。プログラムを書く前に、どういうxpathを書けばよいかなどを検討するのに便利です。
XPathの取得
scrapyは、Webページの中で取り出したいデータをXPathで指定します。HTMLの構造が分かっているページなら自分でXPathを書くのも難しいことではありませんが、自分が作ってないページで取り出したいデータのXPathを手で書くのは大変です。そこで、chromeが役に立ちます。
例えば、http://toyokeizai.net/category/diaryのページから各漫画のタイトルとリンクを抜き出したいとします。chromeでこのページを開き、一番上のタイトル「エンジニアはプレミアム金曜日も帰れない」を右クリックして、メニューの"inspect(検証)"を選択します。以下の図のようにDeveloper Toolsが開いて、該当するタグが選択された状態になります。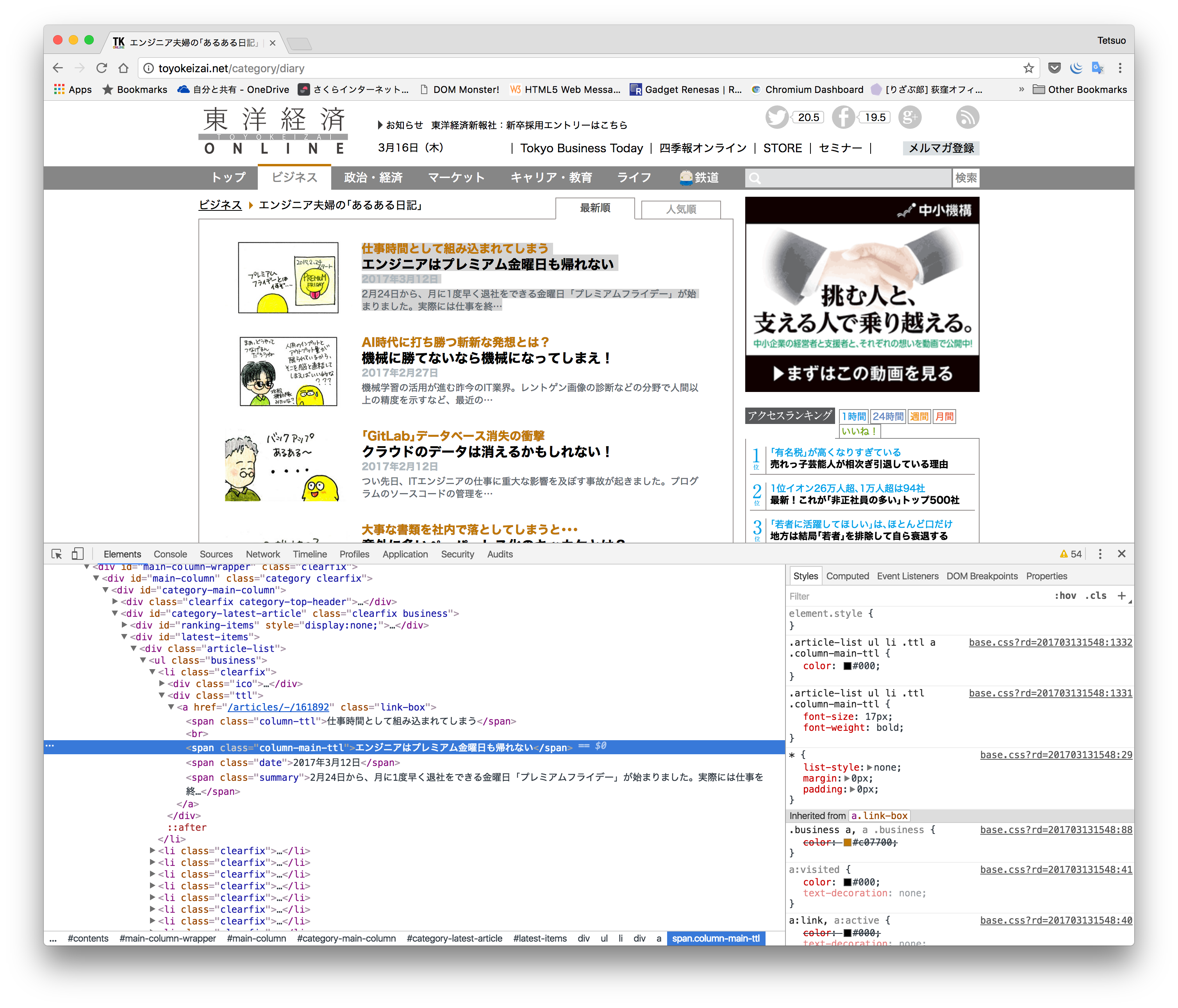
その<span>タグを右クリックして、メニューから"Copy"→"Copy XPath"を選ぶと、この<span>タグのxpathがクリップボードにコピーされます。この例では、XPathは
//*[@id="latest-items"]/div/ul/li[1]/div[2]/a/span[2]
です。このようにchromeだけで簡単にXPathを取得することができます。
XPathについては以下のサイトなどを参考にしてください。
TECHSCORE ロケーションパス
XMLパス言語 (XPath) Version 1.0
Scrapy Shellでスクレイピング
scrapyのインストールは、
Scrapy
python anaconda環境にscrapyをインストールする
などを参考にしてください。
scrapy shellでWebページを読み込む
まず、scrapy shellを起動します。
$ scrapy shell
2017-03-16 10:44:42 [scrapy] INFO: Scrapy 1.1.1 started (bot: scrapybot)
2017-03-16 10:44:42 [scrapy] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0}
2017-03-16 10:44:42 [scrapy] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2017-03-16 10:44:42 [scrapy] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.chunked.ChunkedTransferMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-03-16 10:44:42 [scrapy] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-03-16 10:44:42 [scrapy] INFO: Enabled item pipelines:
[]
2017-03-16 10:44:42 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6024
2017-03-16 10:44:43 [traitlets] DEBUG: Using default logger
2017-03-16 10:44:43 [traitlets] DEBUG: Using default logger
[s] Available Scrapy objects:
[s] crawler <scrapy.crawler.Crawler object at 0x1083d7668>
[s] item {}
[s] settings <scrapy.settings.Settings object at 0x108f2cb70>
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
In [1]:
次にfetch()コマンドでWebページを読み込みます。
In [1]: fetch('http://toyokeizai.net/category/diary')
2017-03-16 10:46:30 [scrapy] INFO: Spider opened
2017-03-16 10:46:31 [scrapy] DEBUG: Crawled (200) <GET http://toyokeizai.net/category/diary> (referer: None)
なお、scrapy shell起動時にURLも指定して、一気に読み込むこともできます。
$ scrapy shell http://toyokeizai.net/category/diary
読み込んだページはresponseオブジェクトに格納されています。
目的としたページが読み込めたかどうかは、
In [3]: view(response)
Out[3]: True
などのコマンドで確認できます。view()コマンドを使うとデフォルトブラウザで読み込んだWebページを表示します。
目的とするデータの取り出し
それでは目的とするデータを取り出してみましょう。XPathは上のものを使います。
In [4]: response.xpath('//*[@id="latest-items"]/div/ul/li[1]/div[2]/a/span[2]/text()').extract()
Out[4]: ['エンジニアはプレミアム金曜日も帰れない']
これでタイトルが取得できました。chromeでコピーしたXPathに追加したtext()は、選択したノードのすべての子テキストノードを取り出します。また、extract()はノードの中からテキストデータを抽出します。なお、結果は配列で返ります。
すべてのタイトルを取り出す
次に、ページ内にリストアップされている漫画の全タイトルを取得します。今まで使っているXPathに該当するHTMLは、
この部分のHTMLは
<div id="latest-items">
<div class="article-list">
<ul class="business">
<li class="clearfix">
<div class="ico">…</div>
<div class="ttl">
<a href="/articles/-/161892" class="link-box">
<span class="column-ttl">仕事時間として組み込まれてしまう</span><br>
<span class="column-main-ttl">エンジニアはプレミアム金曜日も帰れない</span>
<span class="date">2017年3月12日</span>
<span class="summary">2月24日から、月に1度早く退社をできる金曜日「プレミアムフライデー」が…</span>
</a>
</div>
</li>
<li class="clearfix">…</li>
<li class="clearfix">…</li>
<li class="clearfix">…</li>
<li class="clearfix">…</li>
<li class="clearfix">…</li>
</ul>
</div>
</div>
という構造になっており、<li class="clearfix">…</li>の中に1つの漫画の情報が入っています。
先ほど使ったXPath
//*[@id="latest-items"]/div/ul/li[1]/div[2]/a/span[2]
のli[1]は、最初の<li class="clearfix">…</li>を指すので、この順番の指定をなくせばすべての<li class="clearfix">…</li>を指定できます。つまり、XPathは
//*[@id="latest-items"]/div/ul/li/div[2]/a/span[2]
とするだけです。実際に試してみます。
In [5]: response.xpath('//*[@id="latest-items"]/div/ul/li/div[2]/a/span[2]/text()').extract()
Out[5]:
['エンジニアはプレミアム金曜日も帰れない',
'機械に勝てないなら機械になってしまえ!',
'クラウドのデータは消えるかもしれない!',
'意外に多いペーパーレス化のキッカケとは?',
'モテない男子エンジニアの残念な共通点',
'高度なプログラム作業に挑む際に必要なこと',
'2017年元旦は、いつもよりも1秒長い日だった',
'エンジニアのアドベントカレンダー最新事情',
'アマゾンのクラウドには「意外な敵」がいる',
'みずほ銀行のシステムは、いつ完成するのか',
'懐かしの「コナミコマンド」を覚えていますか',
'エンジニア界隈では「DV」に違う意味がある',
'ゲームが過去40年で遂げた驚くべき進化',
'秋の夜長のプログラミングに潜む「落とし穴」',
'元ソニーのエンジニアが職場で人気なワケ']
とすべてのタイトルが取れました。
なお、上のHTMLとXPathを見比べると、タイトルのタグ```…を直接指定するだけでも良いように思えますが、このページは
<div id="ranking-items" style="display:none;"> <!-- 人気順 -->
<div class="article-list ranking category">
<ul class="ranked business">
<li class="clearfix">
...
<div id="latest-items"> <!-- 最新順 -->
<div class="article-list">
<ul class="business">
<li class="clearfix">
という構造になっていて、人気順の下も最新順とほとんど同じ構造になっているので、注意しないと余分なデータが混じってしまいます。実際にやってみると、
In [6]: response.xpath('//span[@class="column-main-ttl"]/text()').extract()
Out[6]:
['エンジニアはポケモンGOで遊んでいません!',
'みずほ銀行のシステムは、いつ完成するのか',
'モテない男子エンジニアの残念な共通点',
'エンジニアはプレミアム金曜日も帰れない',
'もはやデスクトップPCを知らない学生が!',
'元ソニーのエンジニアが職場で人気なワケ',
'クラウドのデータは消えるかもしれない!',
'ヤフー週休3日が手放しに羨ましくないワケ',
'最初に買ったパソコンの記憶は鮮烈だ',
'もっとも稼げるプログラミング言語は何か',
'「ファミコンミニ」に惹かれるのは誰なのか',
'プログラミングが大人気の習い事になった!',
'「自動運転車」は自動で走ってはくれません',
'エンジニア女子「同じ服・お泊り疑惑」の真相',
'新入社員は「議事録作成」で基礎を学んでいく',
'エンジニアはプレミアム金曜日も帰れない',
'機械に勝てないなら機械になってしまえ!',
'クラウドのデータは消えるかもしれない!',
'意外に多いペーパーレス化のキッカケとは?',
'モテない男子エンジニアの残念な共通点',
'高度なプログラム作業に挑む際に必要なこと',
'2017年元旦は、いつもよりも1秒長い日だった',
'エンジニアのアドベントカレンダー最新事情',
'アマゾンのクラウドには「意外な敵」がいる',
'みずほ銀行のシステムは、いつ完成するのか',
'懐かしの「コナミコマンド」を覚えていますか',
'エンジニア界隈では「DV」に違う意味がある',
'ゲームが過去40年で遂げた驚くべき進化',
'秋の夜長のプログラミングに潜む「落とし穴」',
'元ソニーのエンジニアが職場で人気なワケ']
と同じデータが2回取れてしまいます。つまり、XPathは必要なデータを一意に指すようする必要があります。
リンクを取り出す
漫画の掲載ページへのリンクURLは、HTMLを見るとタイトルの<span>の親タグ<a>のhrefに書かれています。これを指すXPathは次のようになります。
//*[@id="latest-items"]/div/ul/li/div[2]/a/@href
最後の@hrefは、aタグのhref属性を指します。今回はaタグの子のテキストノードではなく、aタグの属性値を取り出したいので、上記のようにしています。これを実際に動かすと
In [7]: response.xpath('//*[@id="latest-items"]/div/ul/li/div[2]/a/@href').extract()
Out[7]:
['/articles/-/161892',
'/articles/-/159846',
'/articles/-/157777',
'/articles/-/153378',
'/articles/-/153367',
'/articles/-/152301',
'/articles/-/152167',
'/articles/-/149922',
'/articles/-/149911',
'/articles/-/146637',
'/articles/-/146559',
'/articles/-/144778',
'/articles/-/144756',
'/articles/-/142415',
'/articles/-/142342']
となります。
これで、各漫画のタイトルとリンクを取得するXPathができましたので、これを元にスクレピングのプログラムを作れば、必要な情報を取り出すことができます。
取得したデータを書き出す
1回しかスクレイピングしないのであれば、このまま必要なデータを出力することができます。まず、スクレイピングしたデータを変数に保存し、次にそれをファイルに出力します。
In [8]: titles = response.xpath('//*[@id="latest-items"]/div/ul/li/div[2]/a/span[2]/text()').extract()
In [9]: links = response.xpath('//*[@id="latest-items"]/div/ul/li/div[2]/a/@href').extract()
In [10]: f = open('bohebohe.txt', 'w')
In [11]: for title, link in zip(titles, links):
...: f.write(title + ', ' + link + '\n')
In [12]: f.close()
これでbohebohe.txtファイルにスクレイピングした結果が書き込まれました。
$ cat bohebohe.txt
エンジニアはプレミアム金曜日も帰れない, /articles/-/161892
機械に勝てないなら機械になってしまえ!, /articles/-/159846
クラウドのデータは消えるかもしれない!, /articles/-/157777
意外に多いペーパーレス化のキッカケとは?, /articles/-/153378
モテない男子エンジニアの残念な共通点, /articles/-/153367
高度なプログラム作業に挑む際に必要なこと, /articles/-/152301
2017年元旦は、いつもよりも1秒長い日だった, /articles/-/152167
エンジニアのアドベントカレンダー最新事情, /articles/-/149922
アマゾンのクラウドには「意外な敵」がいる, /articles/-/149911
みずほ銀行のシステムは、いつ完成するのか, /articles/-/146637
懐かしの「コナミコマンド」を覚えていますか, /articles/-/146559
エンジニア界隈では「DV」に違う意味がある, /articles/-/144778
ゲームが過去40年で遂げた驚くべき進化, /articles/-/144756
秋の夜長のプログラミングに潜む「落とし穴」, /articles/-/142415
元ソニーのエンジニアが職場で人気なワケ, /articles/-/142342
おわりに
プログラムを作りながらデータを指定するXPathをデバッグするのはちょっと手間ですし、一度しか使わないものにわざわざプログラムを書くのももったいないことがあります。そういう時、インタラクティブにいろいろと試せて、さらにそのままpythonスクリプトを動かせるscrapy shellはなかなか便利で、過去に作ったベージからちょっとしたデータを抜き出したいだけとか、いろいろ実験するとかに役立っています。
おまけ XPath
この記事て使用したXPathについて簡単に説明します。HTMLの例として
1: <div id="latest-items">
2: <div class="article-list">
3: <ul class="business">
4: <li class="clearfix">
5: <div class="ttl">
6: <a href="/articles/-/161892" class="link-box">
7: <span class="column-ttl">仕事時間として組み込まれてしまう</span><br>
8: <span class="column-main-ttl">エンジニアはプレミアム金曜日も帰れない</span>
9: <span class="date">2017年3月12日</span>
11: </a>
12: </div>
13: </li>
14: </ul>
15: </div>
16:</div>
を使います。
| XPath | 機能 |
|---|---|
| //e | タグeをルートとするパスにマッチするすべてのノード。//divとするとdivタグで始まるすべてのノード(1, 2, 5行目)を取り出します。 |
| //e1/e2 | タグe1とその子要素がタグe2にマッチするすべてのノード。//dev/ulとすると3行目のノードを指定します。//div/a/spanとすると7, 8, 9行目を取り出します。 |
| //e1/e2[1] | タグe1の子要素e2の1番目のノード。//li/div/a/span[1]は7行目を取り出します |
| //e[@name="value"] | 属性nameの値がvalueのタグeのノード。//div@[@class="article-list"]は2行目を取り出します |
| @name | 選択されたノードのname属性を取り出します。//div/a/@hrefは6行目のhrefの値を取り出します |
| text() | 選択されたノードのすべての子要素のテキストノードを取り出します |