はじめに
これは、ZOZOテクノロジーズ #4 Advent Calendar 2019 12日目のエントリーです。
今回はKubeConに参加して面白かったセッションの1つである「10 weird ways to blow up your Kubernetes(Kubernetesをぶち壊す10の奇妙な方法)」をご紹介します。
この他にも、「Airbnbの事例に学ぶKubernetesとマイクロサービスのあり方 @ KubeCon Seattle 2018」という記事も執筆しているので、合わせてご覧ください。
また、このセッションのスピーカーであるMelanie Cebulaは、CloudNative Days Tokyo 2019のキーノートスピーカーとしても来日し、登壇しています。
セッションの背景
セッションスピーカーであるMelanieとBruceは、Airbnbのソフトウェアエンジニアです。
Bruceはいい写真がなかったので、Melanieの写真を「お借り」しました。

AirbnbではKubernetesを動かすためにAmazon EC2で自前のクラスターを管理しています。
クラスター管理を行う上では様々な「学び」があり、このセッションではその中でも10個の課題と、それの解決策についてまとめています。
これらの中には黒魔術も含まれており、「もしもっといい方法があったらぜひ教えてほしい」ということでした。
1. Zombie Jobs(ゾンビと化したジョブ)
Kubernetes Jobs and Cronjobs are great!
KubernetesのJob、Cronjobは、単発のタスクを実行させるためのリソースで、バッチ処理などにとてもよく適しています。
しかし、Job処理のPodにサイドカーコンテナを使う場合はどうでしょうか。

この場合、Jobが終わっていたとしても、Pod上にあるサイドカーのLogger agentやNetwork Proxyが永遠に残り続けてしまうため、Jobリソースが終了したことを検知することができません。
KubernetesではcronJob.activeDeadlineSecondsを使って終わらないJobを殺すことができますが、これを使って終了したJobはFailure扱いになるため、バッチが成功したことを仕組み上フックするのが難しくなります。
シアトルのKubeConで「Lightning Talk: Kubernetes Jobs and the Sidecar Problem - James Wen, Spotify」という発表があり、Jobのステータスを示したfileを用意して、共通のVolumeでwatchするというワークアラウンドもありました。
これをベースに色々試してみたのですがうまく行かず、たくさんのうまく行かないbash scriptが量産されていきました。
bashの黒魔術を使ってもうまく行かなかったので、Kubernetes本体でうまく修正できないかを探っていきます。
サイドカーに関するIssueを見つけ、実装もされていたのですが、1.17になるまでリリースされない上に、バックポートしようにもAPIの互換性が崩れてしまうため現実的ではありません。

困り果ててTwitterで答えを聞くレベルの勢いでした。
リポジトリをフォークするとコードベースが大きく乖離してしまうため、基本的にはやりたくありません。そこでLyftがほしかった機能のパッチを当てている事に気づきました。
これは、Pod内のコンテナを「普通」と「サイドカー」にアノテーションで分類し、起動と終了の順番をそれによって制御するものです。
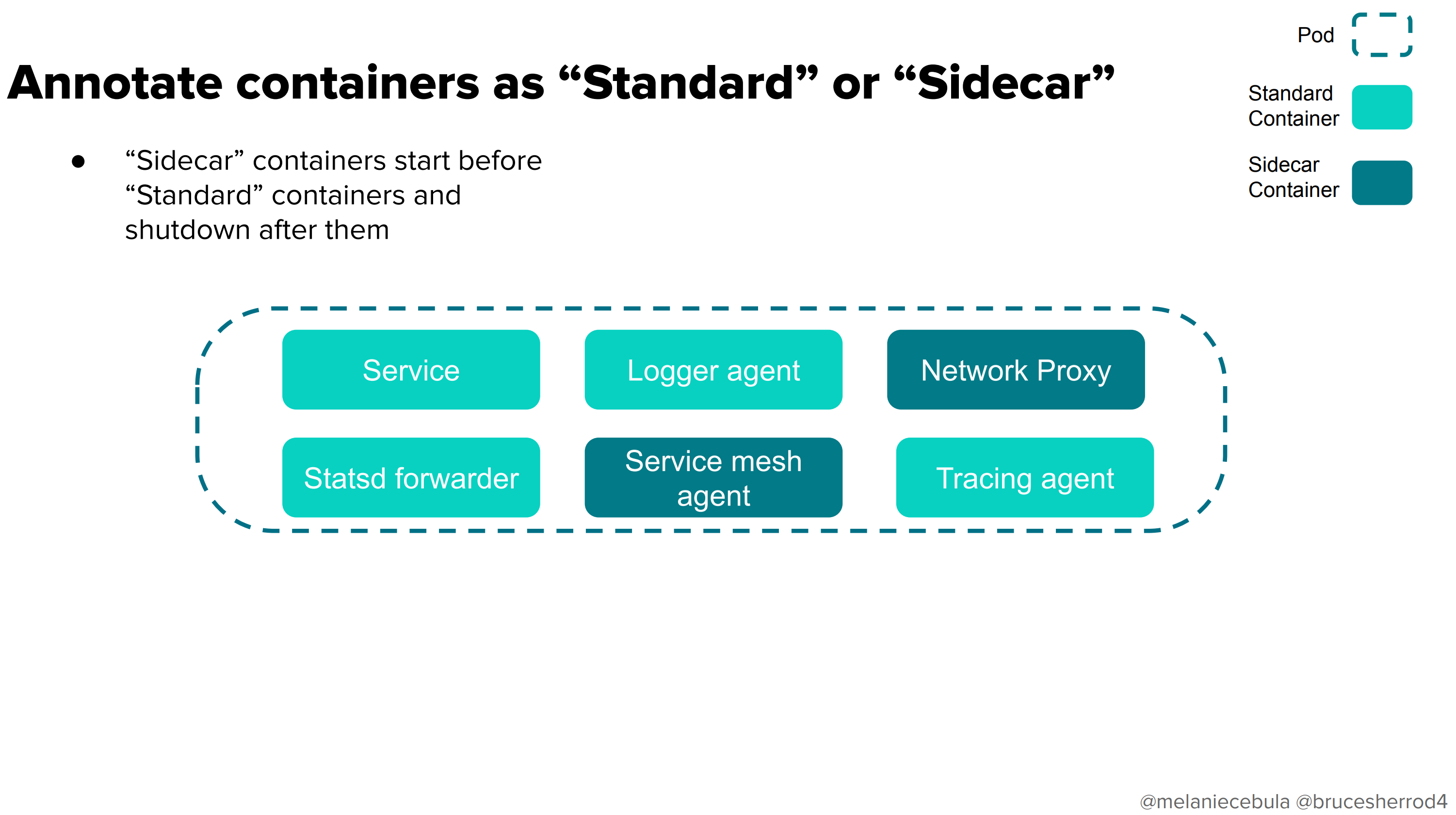
ここでのまとめは以下のとおりです。
適切な抽象化レベルで問題を解決しましょう。場合によっては、kubernetesそのものにパッチを当てる必要があるかもしれません!
2. Service Mesh Speeding Accidents(サービスメッシュの交通事故)
Airbnbのサービスでは、内製のOSS「SmartStack」を使ったサービスディスカバリを展開しています。
これは内部的にサイドカーでHAProxyを使っているのですが、HAProxyはプロセスの入れ替えに時間がかかる上にメモリの負荷が高いサービスです。
このため、Deployが複数回続くと、Nodeのメモリが枯渇してPodがOOMで殺される問題が発生します。

これを防ぐためにPodの入れ替えの際にわざと待ち時間を入れました。
lifectcle:
preStop:
exec:
command:
- /bin/sleep
- "120"
containers:
- name: main
terminationGracePeriodSeconds: 180
こうすることでメインのコンテナが停止しても、それをサービスディスカバリが検知するのを遅延させることができるようになります。
※これは最初にご紹介した黒魔術の1つです
ここでのまとめは以下のとおりです。
Kubernetesを使ったデプロイは、インフラの維持が可能かどうかに関わらず、Podを超高速で入れ替えます!
3. Monster DaemonSets(モンスター級デーモンセット)
DaemonSetはNodeに1つPodを展開するためのKubernetesリソースで、メトリクスの収集や、全てのPodに共通の処理を入れるときなどに使います。
一見便利なDaemonSetですが、DaemonSet自身が入れ替わろうとする時に他のPodがDaemonSetの動きに依存する場合や、そもそもDaemonSetが何らかの原因で落ちた場合、それに依存している他のPodたちはその影響を受けてしまいます。
そこで「DaemonSetを使うべきではないのでは?」と思い、podAffinityを使いDeploymentリソースとして展開してみることにしました。
# service that depends on deployment
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
Values:
- { DEPLOYMENT NAMESPACE }
topologyKey: “kubernetes.io/hostname”
namespaces:
- { DEPLOYMENT NAMESPACE }
しかしこの場合でも、requiredDuringSchedulingIgnoredDuringExecutionのポリシーをモノによって決めるのが面倒です。
そこで、DaemonSetをTaint/Tolerationと組み合わせて使うことも考えました。しかし、これも「どのノードにデプロイするか」などの複雑な条件を考えるのが大変です。結局、普通にDaemonSetを使うことにしました。
ところで、Airbnbでは最も古いクラスターに対して2000を超えるノードが属しています。このクラスターにDaemonSetをデプロイしたらどんな事が起こるでしょうか。
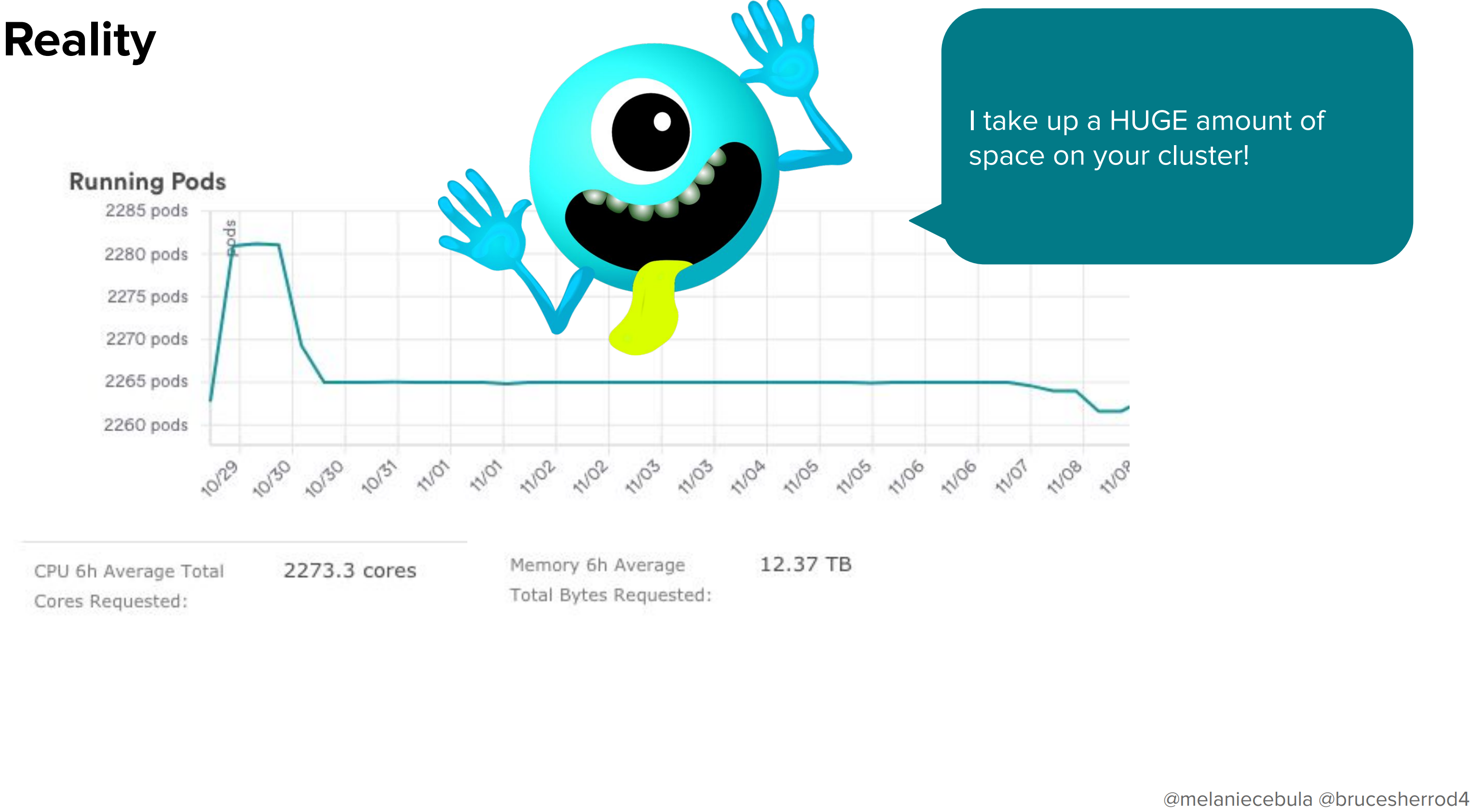
2000を超えるPodが展開されるため、CPUもメモリも消費量がとんでもないことになります。
SREチームから「DaemonSet2000個もデプロイしたせいで1000個以上のPodがOOMで死んだ」と連絡が来ました。さらにこのイベントがetcdに通知されたので、クラスター全体の負荷が高まってえらいことになってしまいました。
最終的にはこの形で落ち着きました。
- 諦めてサイドカーモデルにした
- DaemonSetをクラスター全体にデプロイするためには厳しいレビュー処理を経てからじゃないとできないようなアドミッションコントローラーを入れた
- DaemonSetや、その他特別なノードの動作を必要とするサービスのための専用クラスターを新しく作った
ここでのまとめは以下のとおりです。
DaemonSetは他のワークロードを巻き込む形でクラスターの停止に追い込んでしまうことがあります。
4. Where's my docker image!?(ワイのDockerイメージはどこに!?)
現在、Airbnbでは1日に2百万を超えるDockerイメージを作成しています。これにはAWSのECR(Elastic Container Registry)を使っています。
ECRは非常に素晴らしいのですが、リポジトリあたり10,000イメージまでの制限があるため、何らかの形でこれを超えないようにする必要があります。ECRにはライフサイクルポリシーがあり、これによって古いイメージのクリーンアップなどを行うことが出来るのですが、「現在使っているイメージの数」をカウントすることができないため、サービス上でそのイメージを使っている場合の考慮も必要です。
これを解決するために「ECR Cleaner」というシンプルなスクリプトを作りました。

うまく動いていました。しばらくの間までは。Dockerがエラーを出してCIがコケるようになりました。

なんと、驚くべきことに、Airbnbではリポジトリあたり10,000イメージまでの制限を超える数のイメージを一日で作成していました。そのため、この日時バッチでは削除のタイミングが追いつかなかったのです。
そこで、@dailyを@hourlyに変えることで解決しました(会場爆笑)
しかし、今度はKubernetesのノードを入れ替えるタイミングでサービスがダウンするようになりました。
find_all_images_in_use()
for repo in ecr_repos:
delete_old_images(except in use)
問題はfind_all_images_in_useで、この関数はそのクラスターで使われているイメージを全て削除する役割を持つのですが、このECRでは複数クラスターに跨ってDockerイメージを管理しています。
つまり、クラスターごとに全ての使われているイメージをいい感じに管理しないといけません。しかし、この場合、このクリーナーを複数クラスターにデプロイするため、セキュリティのアイソレーションなどが課題となります。
どうすればよいでしょうか。

新しくクラスターを作りました(会場爆笑)。

つまり、「イメージを管理するためのクラスター」を新しく作って、そいつが全てのクラスターの持つイメージを収集するようにしたのです。
ここでのまとめは以下のとおりです。
すべてのDockerイメージを保持できないのはなぜなのか、理由をしっかり追跡するようにしてください!
5. To Init or not to init... that is the question(初期化するかしないか、それが問題だ)
こんなPodがあったとします。

Serviceにはアプリケーションが、Runtime config agentには共通のConfigをサービスに仕込むサイドカーが、Network ProxyはEnvoyのようなサービスプロキシが置かれています。
Runtime config agentは、クラスター内にあるRuntime config serviceというサービスから定期的に設定を取得し、Podに設定を注入する役割を持っています。
このとき、PodがRunningになるためにはその動作が完了していなければなりません。そのため、Runtime config agentがサービスよりも前に起動して処理を完了させる必要があります。
そこで、initContainerにこの処理に依存する部分を移植してみます。しかしこれはうまくいきません。

理由としては、サービスディスカバリの観点から、Podの外を出る通信にはNetwork Proxyが必要だからです。
次に、initContainerに追加でNetwork Proxyを仕込む案もありますが、これは複雑すぎるのでやりたくありません。
今度はKubernetesでsidecar ordering(サイドカーの順位付け)がサポートされたらしいので試してみます。
が、これでも結局Network Proxyが、Runtine configの前に起動仕切ることが保証できないためうまくいきません。
最終的にはこうすることにしました。

Runtime config agentの起動スクリプトにNetwork Proxyに接続できるまで起動しないというスクリプトを仕込みました。
ここでのまとめは以下のとおりです。
コンテナの起動順はサイドカーでも必要な場合があります!
つづきます
明日はこれの後半戦をやっていきます。資料は以下にもありますので、よろしければ合わせて御覧ください!
セッションの動画: https://www.youtube.com/watch?v=FrQ8Lwm9_j8
スライド: https://static.sched.com/hosted_files/kccncna19/b9/kubecon%202019%20preso.pdf