はじめに
これは、ZOZOテクノロジーズ #4 Advent Calendar 2019 13日目のエントリーです。
前回の前編記事に引き続き、Airbnbのエンジニアたちが経験したクラスターでのやらかしをあれこれご紹介します。
6. Where's my Custom Resource?(ワイのカスタムリソースはどこに?)
AirbnbではKubernetesのCustom Resourceをよく使用しています。
特に、Kubernetesクラスターの外部にあるが、ストレージ、ダッシュボード、アラート、IAMロールなどのAWSリソースなどのサービスに関連付けられているリソースを追跡するために使っています。
こうしたCustom Resourceを使う上で大変なのが、「そのリソースがいつ利用可能になったか」や、「そのリソースに関する変更がいつ反映されたか」を検知することです。
最初のうちは、以下のようにシンプルなstatusフィールドを使ってリソースの状態を管理していました。
kubectl applyのタイミングではPendingのステータスでリソースをセットし、コントローラーによって完了が検知された時にリソースのステータスを変更するようなアプローチです。

こうすると、コントローラーは「Pending」の時に発火すればよく、非常にシンプルにリソースを管理することができます。kubectl getしたときも、このステータスに応じた結果が返ってきます。
ただし、今のバージョンではもうこれは動きません。

Kubernetesの1.12以降では、statusの反映はコントローラー経由でしか行えなくなってしまいました。kubectl applyを実行してもStatusフィールドが変更できないので、リソースの作成時や変更時にstatusをPendingにセットできなくなってしまったのです。
これによって、リソースの更新作業が一切行えなくなってしまいます。
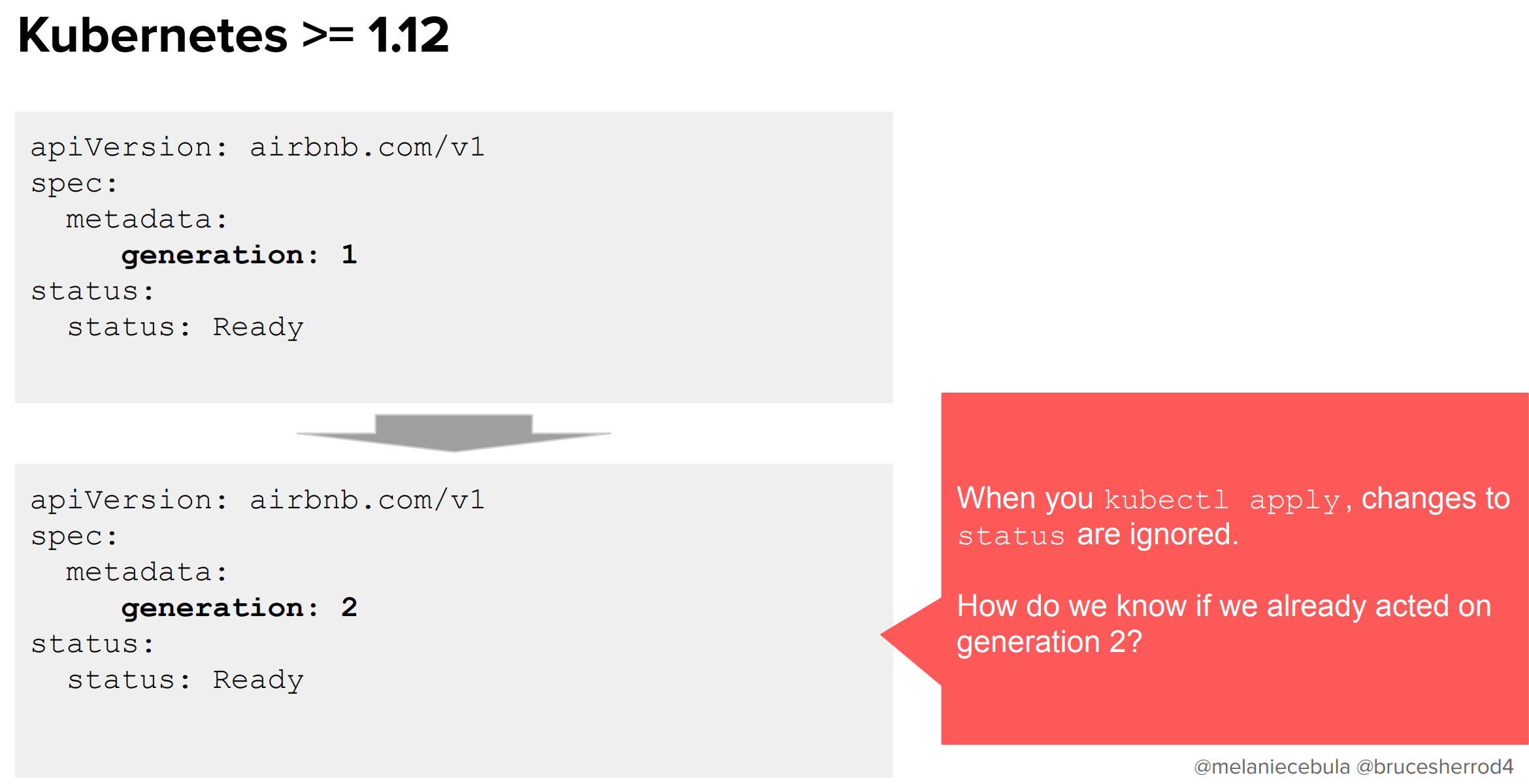
Kubernetesには自動インクリメントする整数型のgenerationというフィールドがあり、これによってリソースの世代が管理できます。これをどうにか使って改善できないか考えました。しかし、kubectl applyした時点でステータスを変えることはできないので、相変わらず「その世代で変更作業はできたのか」を検知することはできないままです。さてどうしたものでしょうか。

AirbnbではステータスにobservedGenerationというフィールドを追加しました。これによって、「変更が適用されたgeneration」と、そうでないgenerationを察知できるようになりました!
こうすることで無事にカスタムリソースのステータスを管理できます。やったね!
ここでのまとめは以下のとおりです。
リソースのデプロイがいつ終わったか、それが成功したのかどうかを察知するのは難しいです。
7. I can't believe I have all the node's resources(まさかノードのリソース全部持ってくなんて信じられんわ)
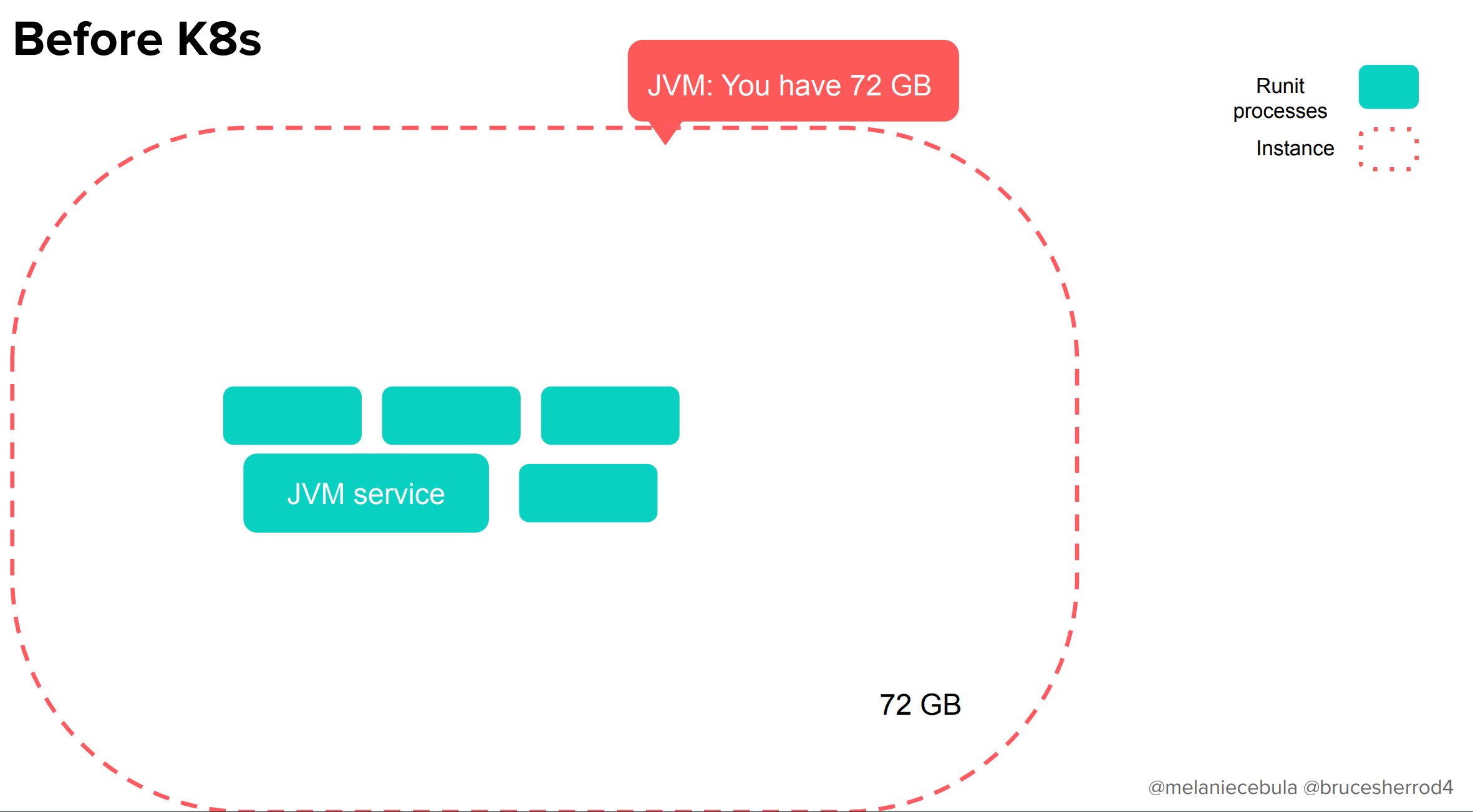
Kubernetesを導入する前のAirbnbでは、インスタンスに対して1つのJVMがある、とてもシンプルな世界がありました。
Kubernetesを導入したあとはどうでしょうか。ノードの上にJVMを持つPodが複数あると・・・
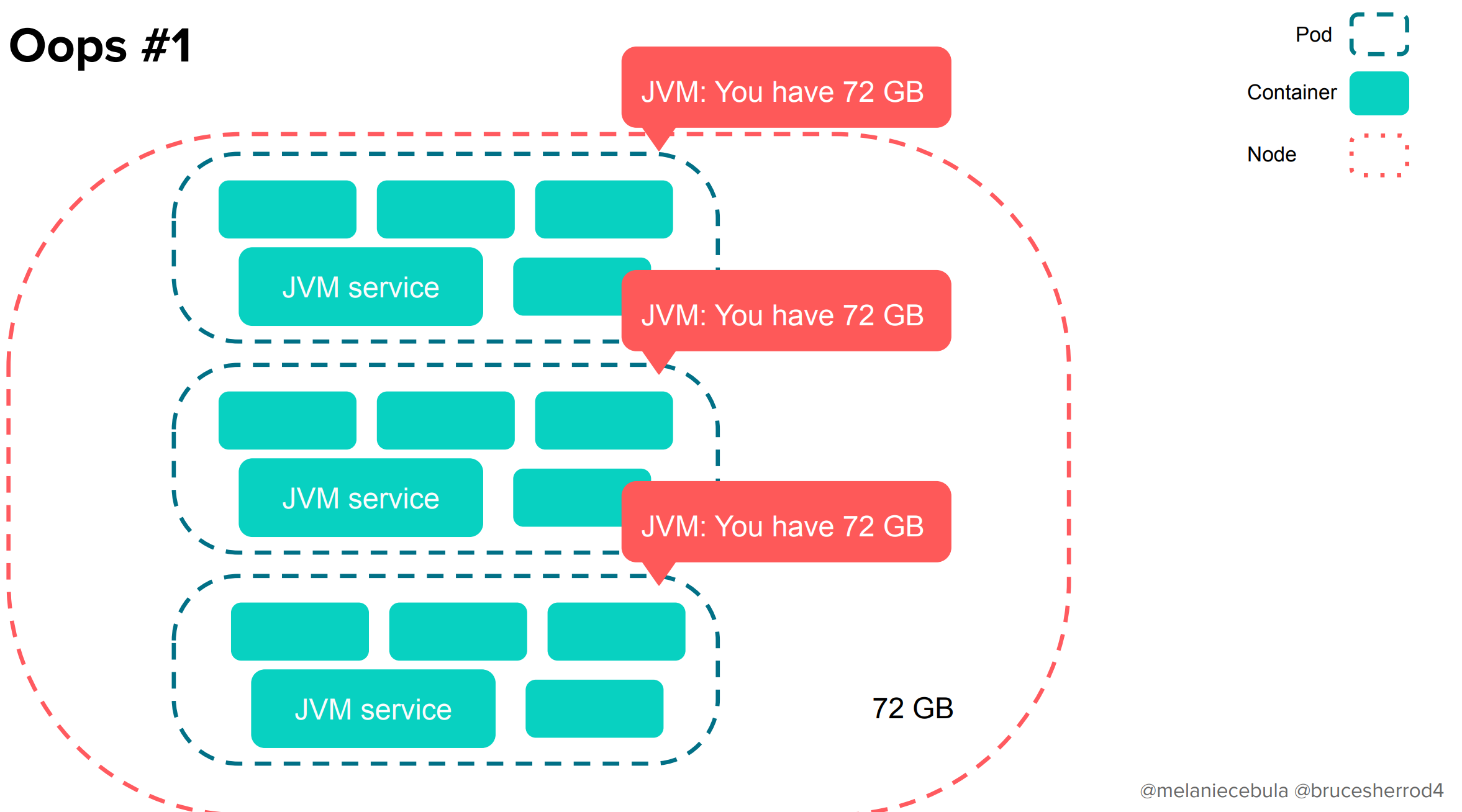
各JVMが自分がほしいメモリを確保するだけしてしまうので、OOMが発生します。
これはCPUの場合でも同様です。

この問題の原因は、古いJDKではコンテナがリソースの隔離につかうLinuxのcgroupを考慮できていなかったためで、新しいバージョンでは修正されています。そこでJavaのバージョンを上げてみましょう!という話になりました。
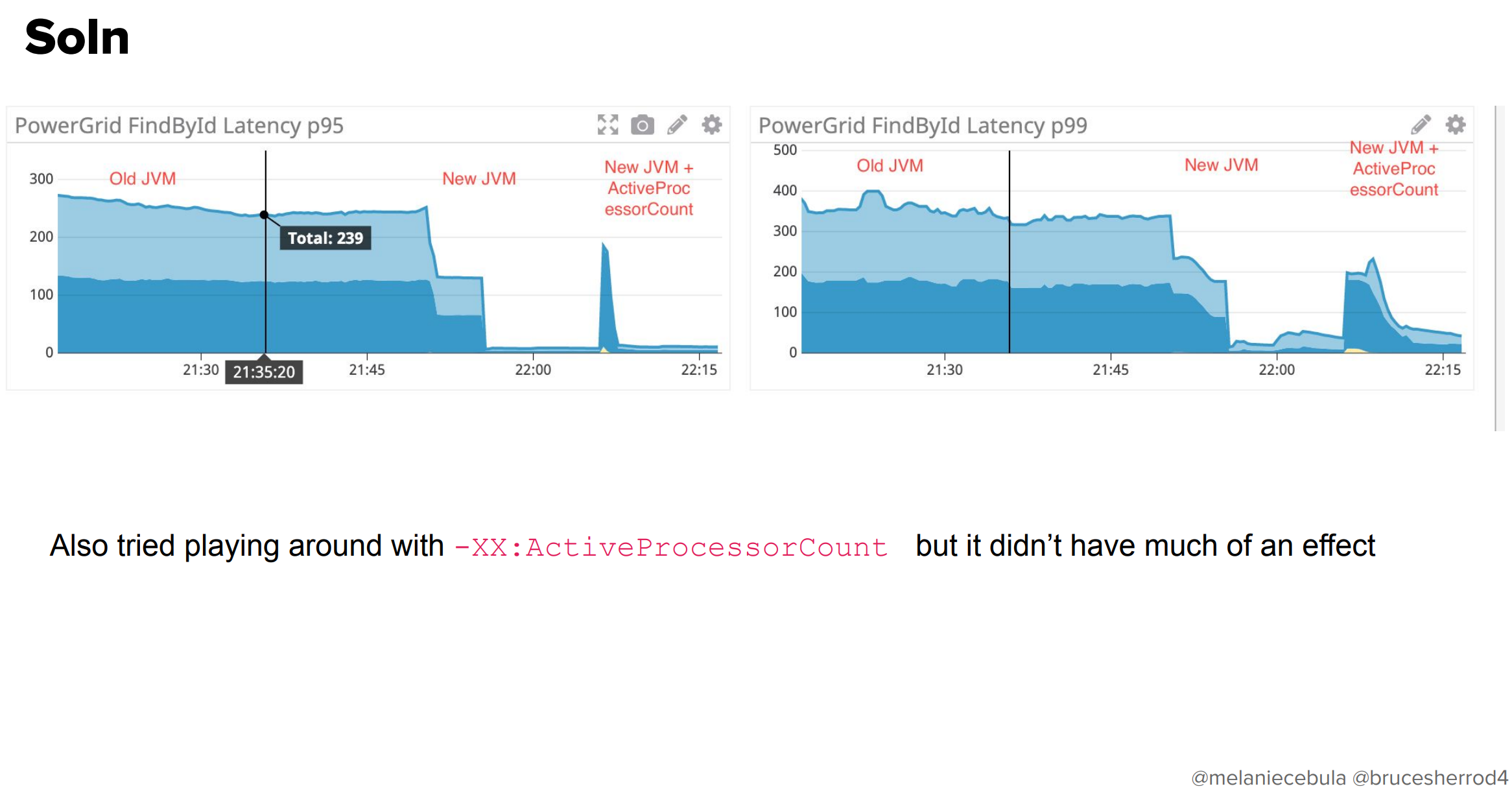
実際に上げてみたところ、95パーセンタイルベースでのリソース利用率がぐっと下がっていることがわかります。念のために-XX:ActiveProcessCountも効果があるか試してみましたがそちらはそんなに効果はありませんでした。
なんにしても、これでリソースが適切に隔離できるようになりました。
さて、ここでもう1つ別の問題が露呈しました。
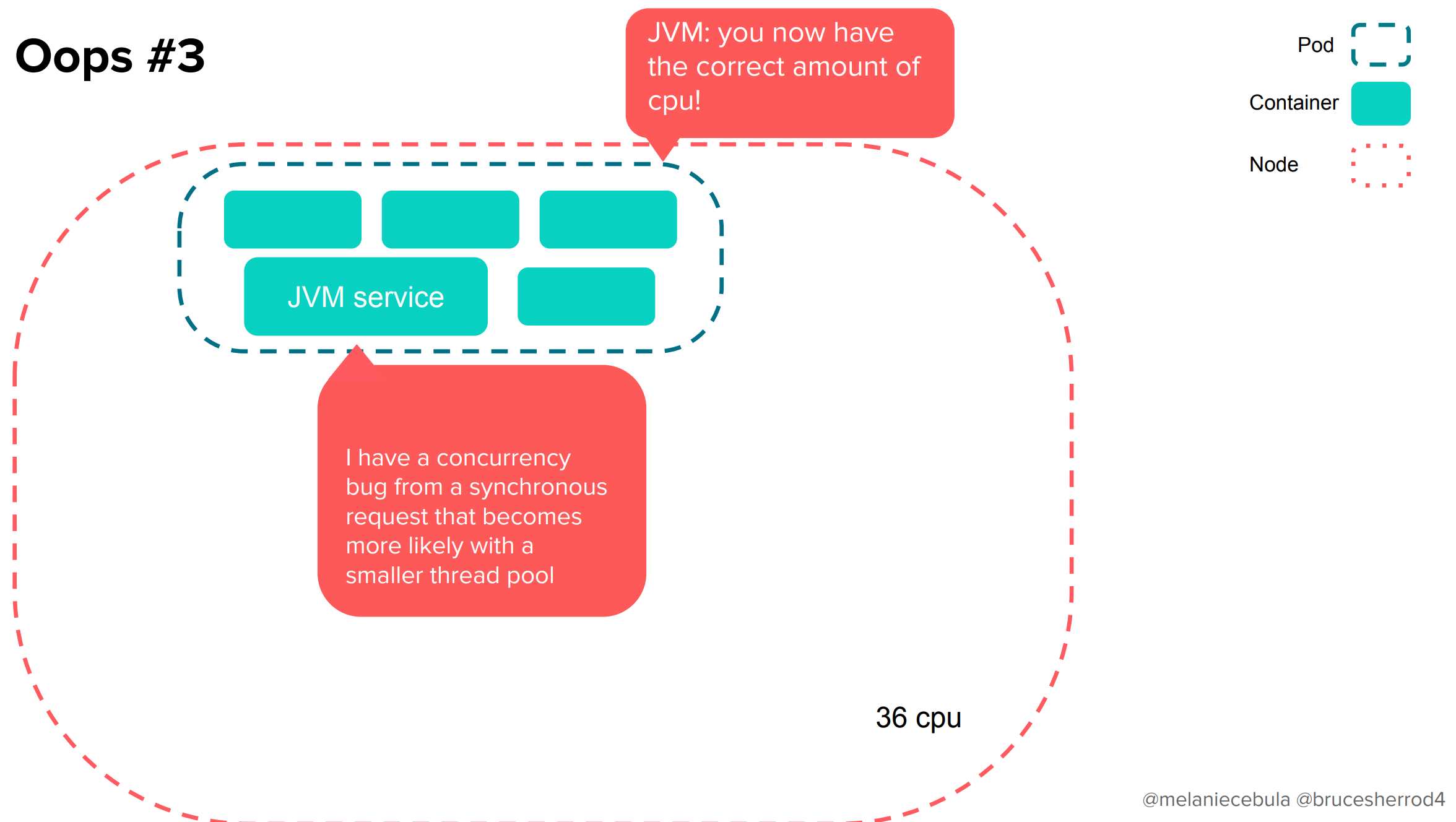
Pod「サービス君、これが新しく割り当てられた”適切な”CPUリソースだよ」
サービス「ぼく、同期処理リクエストに起因する並列実行の箇所にバグがあって、特にスレッドプールが小さい時に露呈しやすいんだ」
Pod「アッハイ」
適切なリソースに設定したはずが、かえってアプリケーションの競合を引き起こしてしまいました!!
実際のグラフが↓です。処理に時間の掛かったリクエストが急激に増えていることがわかりますね!

解決策としては、JDKを上げるときにはマルチスレッドなプログラムにおいて適切なスレッドプールを利用しているか、スレッドブロッキングな同期呼び出しがないか、その他並列実行に関するバグがないかを確認するほかにありません。

はいはい、わかってまーす、となりがちですが、これは非常に重要で、さらに言えばJavaに限った話でもありません!
「古いJVMがcgroupに対応してないからコンテナと相性が悪いのなんて当たり前の知識じゃん」なんて思っていると、他の言語やフレームワークに起因するパフォーマンスの問題にぶち当たる原因になります(例: Envoyの並列実行数はホストの持つCPU数分がデフォルト値になっているため、ホスト上で他のアプリケーションとリソースを食い合うことになりかねないといった話)。
ここでのまとめは以下のとおりです。
使っている言語フレームワークやサイドカーにおける、コンテナ周りの考慮漏れに注意しよう
8. Autoscale-ocalypse(オートスケール黙示録)
Kubernetesにおけるオートスケーリング(HPA)は素晴らしく、私達も多用しています。
HPAの簡単なしくみを振り返ると、デプロイメントリソースにおいてPodの平均CPU使用率が一定のしきい値を超えた場合に、新しくPodを作成してスケールしていくような動作をします(スケールダウンの場合はその逆)。そうすることで、ワークロードのリソース利用率を一定の範囲に抑えるように作用します。

さて、以下のような特性のアプリケーションがあった場合のことを考えてみます。
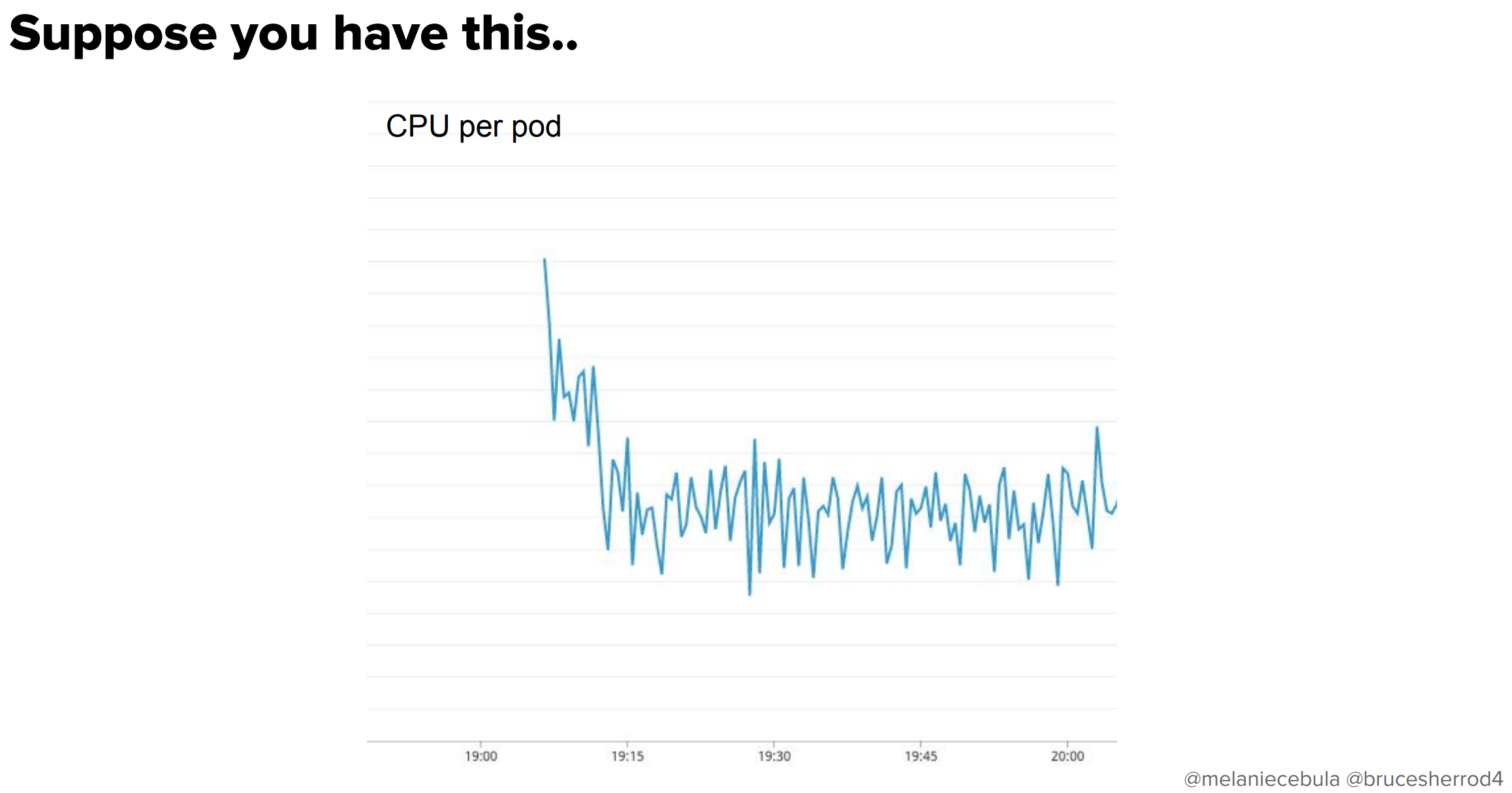
これはPodが起動した直後にCPUを大量に使う特性を示していますね。具体的な数字でいうと、およそ2分間の間CPUを100%消費して、初期化の処理を行っています。さて、このときHPAはどんな動きをするでしょうか。
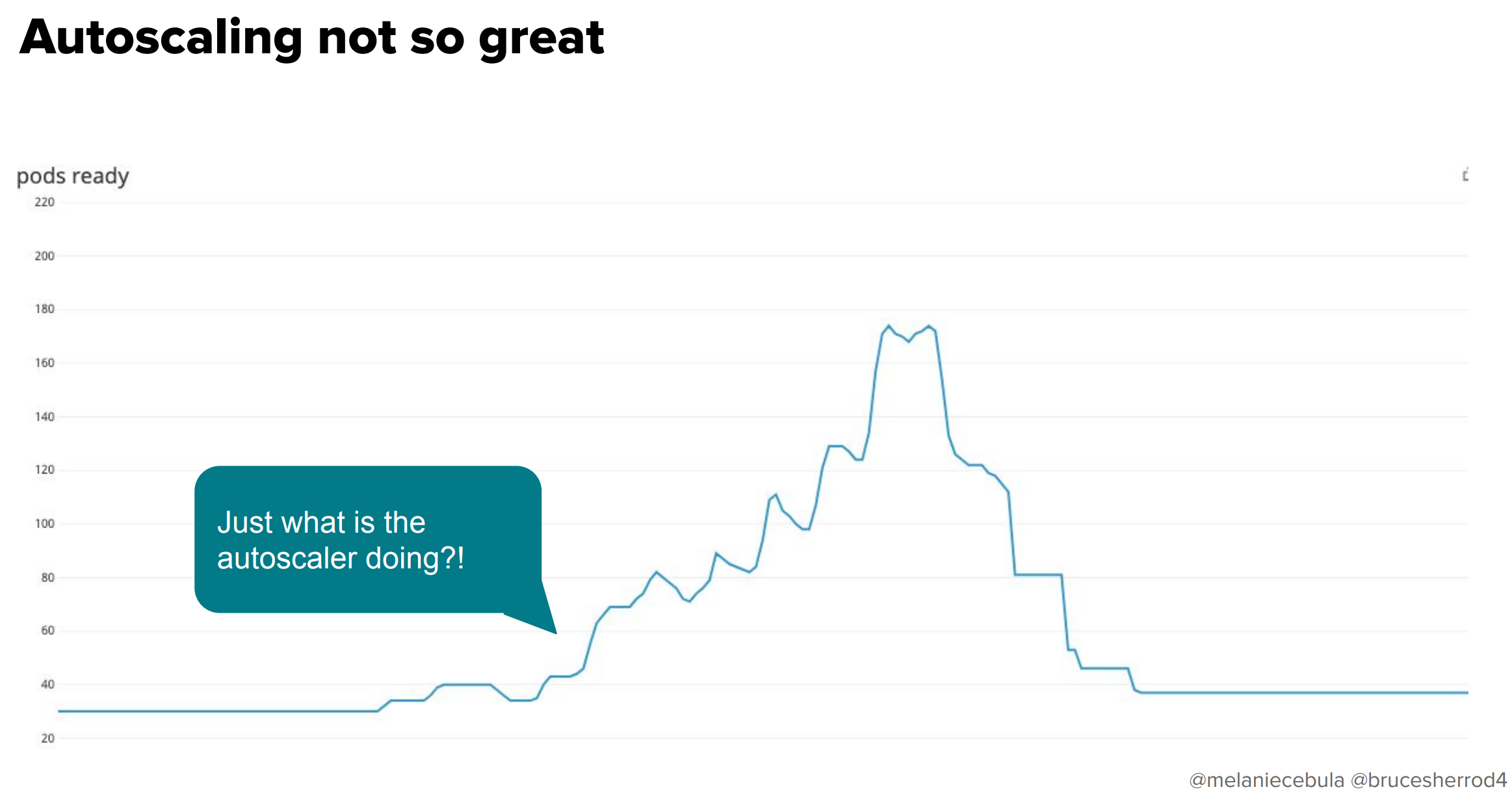
はい、あるPodが初期にCPUを大量に使うのを検知してPodが増え、さらにそれに起因してPodが増え・・・を繰り返すので、Podの数がとんでもないことになります。「オートスケーリングが素晴らしくない」パターンの典型です。通常30で展開しているPodが200近くまで増えてしまいました。
これはどうやったら直したらいいんでしょうか?
悲しいことに、1.12まではPodに対するクールダウン遅延の設定項目がHPAリソースにあったのですが、削除されてしまいました。
v1.12から、新しいアルゴリズムの更新により、アップスケール遅延の必要がなくなりました。
このケースにおいては強く反対したい記述ですよね。
- --horizontal-pod-autoscaler-initial-readiness-delay=300s
- --horizontal-pod-autoscaler-sync-period=300s
- --leader-elect=true
- --master=http://127.0.0.1:80
ここで私達が選択した「ちょっと恥ずかしいハック」がこちらです。もともと、--horizontal-pod-autoscaler-initial-readiness-delay=300sを設定すれば改善するのかと思っていたのですが実はこれでは効果がなく、最終的には--horizontal-pod-autoscaler-sync-period=300sを設定することでこの問題の改善が見られました。
この値が意味するのは、「オートスケーラーを5分に1回しか動かさない」ということです。これ以下に設定してしまうと先程のようなスパイクが発生してしまうので、仕方なくこの値にしたというような経緯があります。
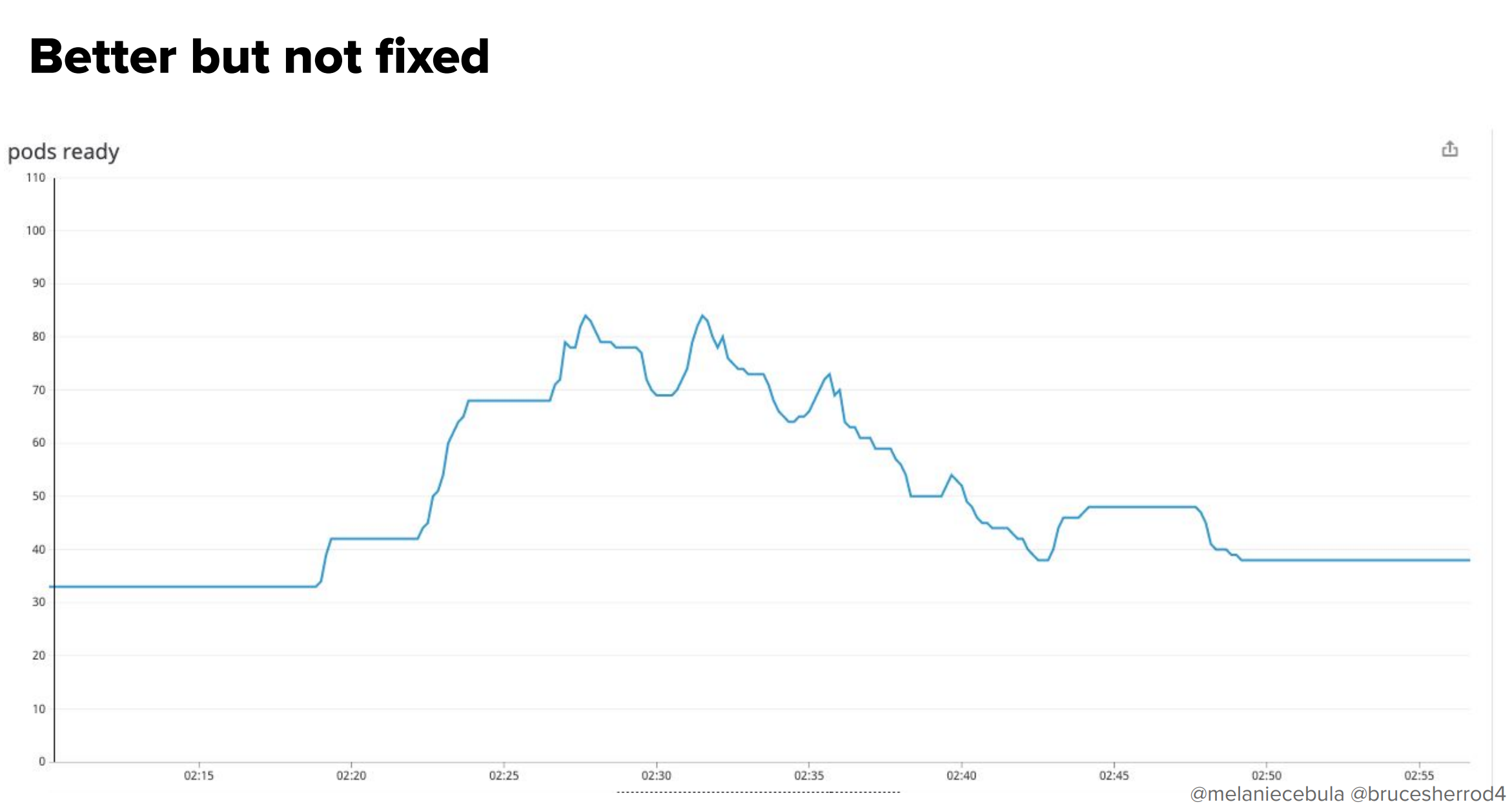
さらに言えば、問題は「軽減」されましたが、「修正」はされていません。図を見てもわかるように、まだスパイクが90近くまで発生しています。
ここでのまとめは以下のとおりです。
オートスケーリングは、CPUが初期に使い潰されるワークロードにはうまくフィットしません
9. Hey, my scheduled operation took down all services(ねえねえ、ワイのオペレーションで全部のサービス死んだよ)
次はこちらです。計画したアップデートにてKubernetesクラスター上でメトリクスを集約するのに使っているStatsdエージェントをアップグレードするために、数分間メトリクスが見られなくなるよという通知をしました。
しかし実際には、この作業中に「全部のKubernetesサービスがダウン」しました。
これを説明するために、そもそもKubernetesにおけるヘルスチェックがどのように動作しているかを説明します。
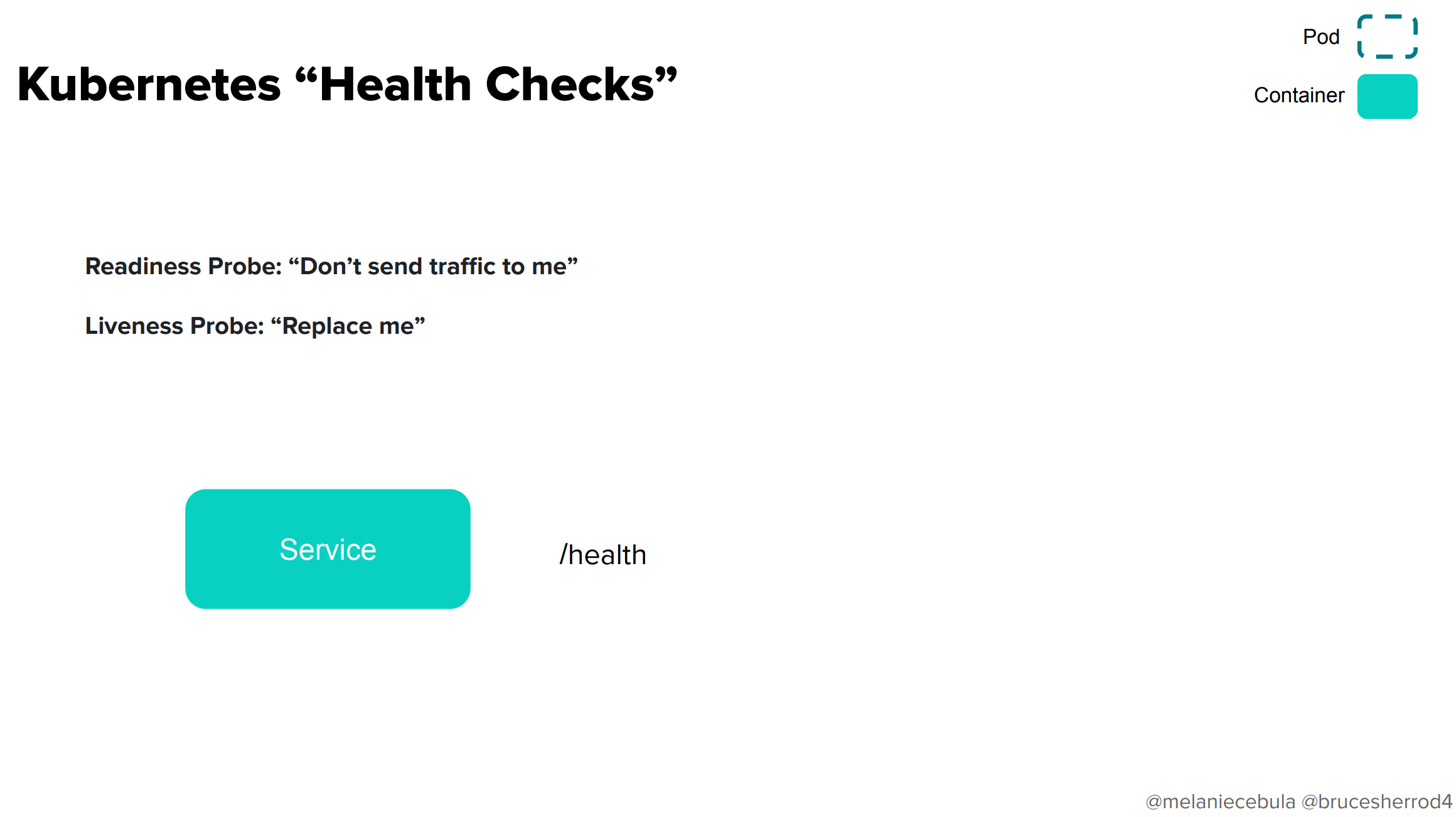
Kubernetesには大きく分けて2つのヘルスチェック用プローブがあります。それぞれ、アプリケーションのどこかにヘルスチェック用のエンドポイントを用意する必要があります(例では/health)。
- Readiness Probe「サービスが一時的に止まっているから僕にトラフィックを流さないで」
- Liveness Probe「僕は死んでるからコンテナの入れ替えをして」
ヘルスチェックエンドポイントは、Pod単位ではなくコンテナ単位で用意します。そこで、最初に以下のことを試してみました。
- Statsdエージェントのような、ミッションクリティカルではないコンテナはサービスの正常性の判断に影響すべきではない
- 簡単やん!そいつらのreadiness probeを外せばええんや!

残念ながらこれではうまくいきませんでした。
クラッシュするコンテナが存在している限り、そのコンテナのreadiness probeが設定されているかどうかに関わらず、PodのステータスがReadyにならないということを知りませんでした。
今回の場合、(サービスディスカバリ用のネットワークプロキシコンテナが起動していないという原因で)Statsdエージェントが起動に失敗しているので、PodのステータスもReadyになりませんでした。
私達が作っているサービスメッシュでは、Podの正常性を判断するロジックが以下のようになっていました。
isPodReady := true
for each containerStatus in pod:
if !containerStatus.Ready:
isPodReady = false
if isPodReady:
publishPodIsReady()
つまり、このロジックでは全てのコンテナステータスがReadyになっている場合はPodがReadyであるという判断がなされます。逆に言えば1つでもReadyでないコンテナがある場合はPublisherがコンテナの状態を正常として通知することはありません。

そこで、コンテナの種類をこのように2種類に分類してみることにしました。こうすることで。サービスの正常性を通知するのに必要でないものの正常性は判断に加えなくてよいというロジックが書けるようになります。
加えて、サービスメッシュのロジックにも以下のような条件を加えました。
isPodReady := true
for each containerStatus in pod:
continue if container.isNonCritical()
if !containerStatus.Ready:
isPodReady = false
if isPodReady:
publishPodIsReady()
クリティカルではないコンテナが評価されるときはそのステータスを無視しています。これによって、サービスに関係のないコンテナの状態に関わらず無事にサービスを提供できるようになりました。
ここでのまとめは以下のとおりです。
特に壊れやすいサイドカーがいるときには、Podのヘルスチェック設定に気をつけましょう。
10. Scheduling is easy and fun(スケジューリングは簡単でたのしいね)
これはとあるサービスにおけるAZごとのQPSです。見てわかるように、パフォーマンスがAZごとに偏っていることから、KubernetesのスケジューラーがうまくAZ間でバランシングしてくれていないことを示しています。

スケジューリングのコードを詳しく見ていないので詳しいことはよくわからないのですが、見立てに因ると、スケジューリングにおけるループの各ラウンドにおいて、作成しようとする全てのPodが単一のAZに偏るようです。
Srugeがかなり大きい場合、全Podが一度にSurgeされ、それらは単一のAZの上に展開されます。
一方で、私たちのサービスはAZに偏らないように負荷分散をかけようとするので、このようなスケジューリングのばらつきがあると、インフラにおいても様々な問題を招くことになります。
そういうわけで、はじめに「Deployment "Pruner" Controller」というカスタムコントローラーを作成しました。
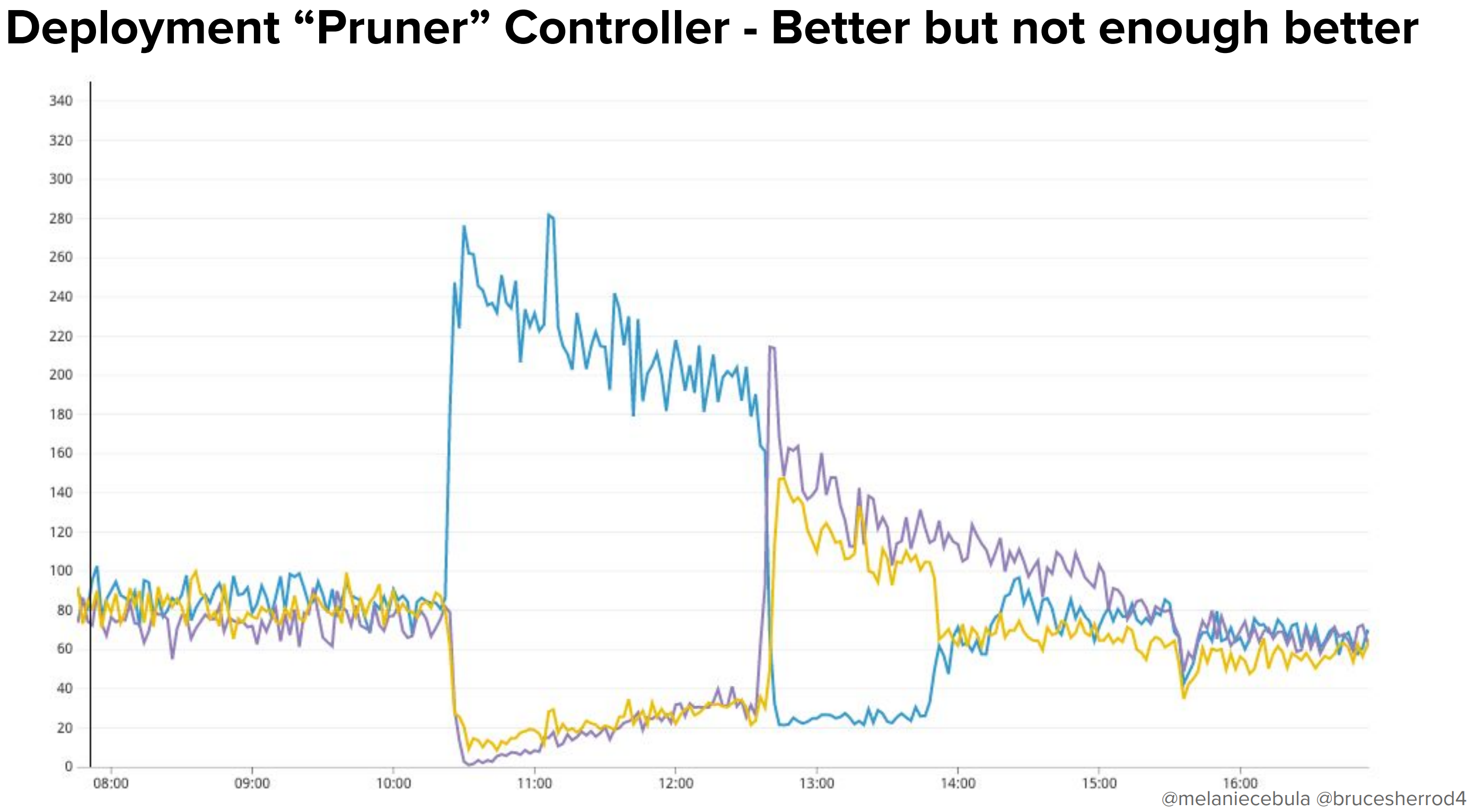
これによって改善はありましたが、最初に配置されるPodにはまだまだばらつきがあり、それを少しずつ収束させるような動きを示していますね。
基本的に私達がやっていることはスケジューラーに「戦いを挑む」ことなので、スケジューラーが配置したPodを削除して、それをスケジューラーがまた配置して、というのを繰り返すことになるのがこの方法では発生します。これでは本来やりたい「速やかな」バランシングが行われないのが悩みです。
前半の話にもありましたが、こうした問題を解決するためにはしばしば「Kubernetes本体に手を入れる」必要があります。
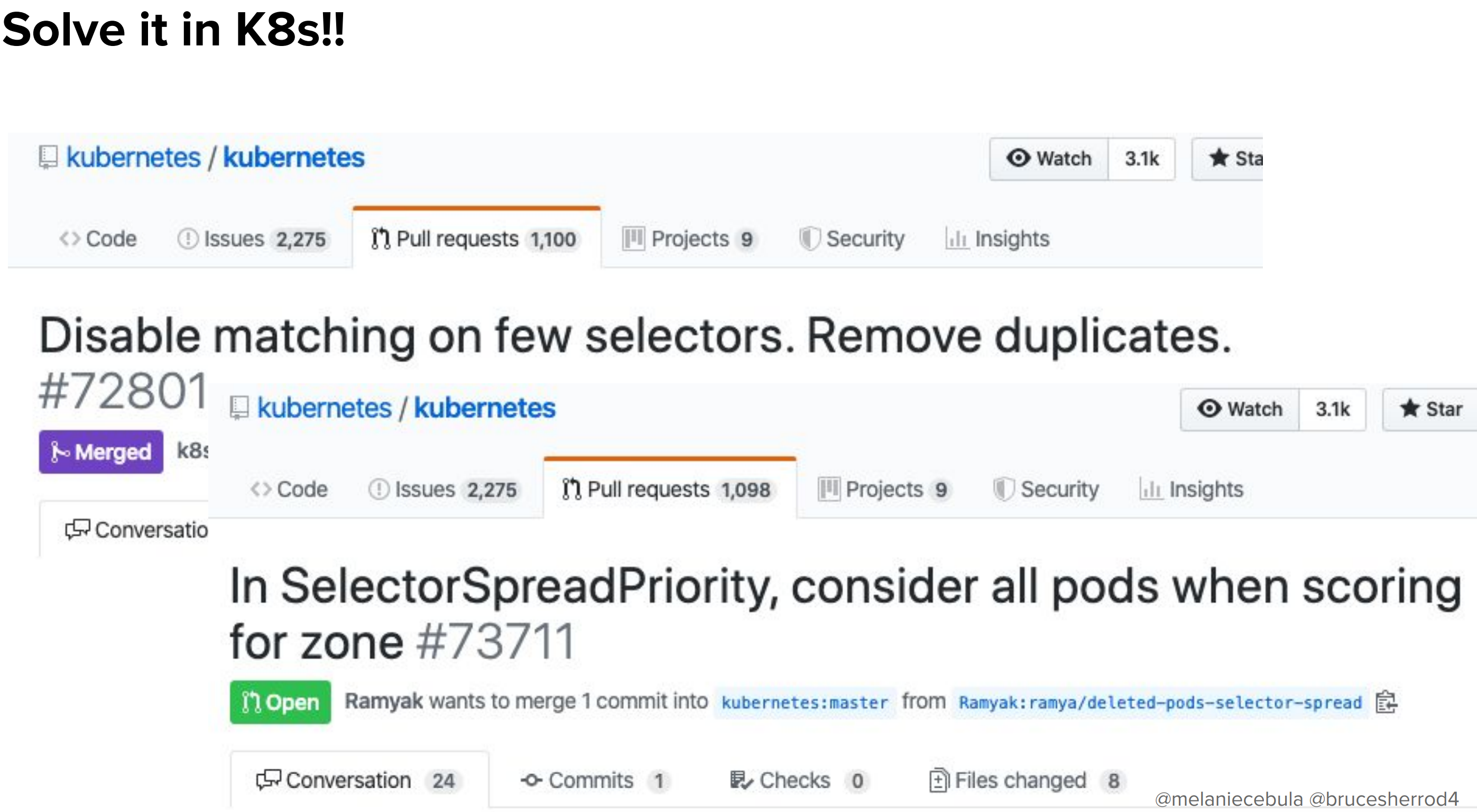
実際、今回はいくつかのパッチを本体に投げています。1つはマージされており、残りの1つは(発表時点では)まだオープンのままです。だれかここにいる人マージされるの手伝ってくれると嬉しいです。
ともかく、これによって以下のようなカスタマイズができるようになるので、今回も「フォーク」することなく解決ができました。
metadata:
name: kube-scheduler
namespace: kube-system
spec:
containers:
- name: kube-scheduler
image: our-custom-scheduler
ここでのまとめは以下のとおりです。
Kubernetesスケジューラを修正する必要があるかもしれませんが、カスタムイメージとして簡単にアップロードできます!
さいごに
Kubernetesのクラスターを自前で運用する上での知見の共有は国内外問わず決して多くはありません。
そんな中でこの規模の運用を赤裸々に紹介してくれたお二人に深く感謝しています。
記事の内容が楽しめたという方は、是非以下のセッション動画も合わせてご覧ください!現場の雰囲気もわかると思います。
セッションの動画: https://www.youtube.com/watch?v=FrQ8Lwm9_j8
スライド: https://static.sched.com/hosted_files/kccncna19/b9/kubecon%202019%20preso.pdf