概要
プリザンターとDifyを連携してクローズド環境で使えるAIアシスタントを作成します。
AIすごいですね(語彙力ゼロ)
日常の業務の中でも急激にAIを活用する機会が増えてきました。当然プリザンターとAIを絡めて…というのはプリザンターLoveの皆さんなら誰しも考え、すでに実践されている方もいらっしゃると思います。周回遅れの感は否めませんが遅ればせながら私もプリザンターとAIを絡めたことと試してみたいと思います。
で、なにしよう? → まずは検索だよね → RAG
前職でコールセンターのお問い合わせシステムに少し携わっていたこと、また現職で最初に担当した業務がサポート問い合わせだったこともあり、すぐに思いついたのはプリザンターに蓄積されたデータから類似の問い合わせを検索し、回答案を教えてくれるAIアシスタントです。いわゆるRAGです。
重要なポイント:クローズド環境で使える → ローカルLLM
今回試すにあたって最重要ポイントとして考えたのが「クローズド環境で使う」ことを想定した構成です。プリザンターはインターネットに接続しないクローズドの環境でも構築・運用できることが強みでもあります。特に社内ノウハウや機密情報が多く蓄積されたデータは元々クローズド環境で利用されていることも予想され、また不用意にインターネット上のAI学習に利用されるのもNGです。ということでLLMもローカルで実現できることを考えます。
RAG&ローカルLLM → Dify!
ということで行き着いたものは皆さんご存じのDifyです。Difyについては私が語るまでもなく様々な紹介記事や事例が多数ありますので詳細は割愛します。
QiitaにもDifyの記事は多くありますので参考にしてください。
Dify構築
今回はDifyでローカルLLMを利用するにあたり、Ollamaを利用します。この構成での構築は以下の記事を参考にしました。
Dify×ローカルLLMで業務活用の可能性を模索している話 #業務効率化 - Qiita
大変わかりやすく説明されている内容でしたので、記載内容をそのままなぞればDifyの構築が完了します。ただし、私の環境特有の事情で以下の対応を行いました。
1. ポート重複:複数のプリザンターをインストール済み
私のPCには動作検証用としてWindows上にSQLServer用プリザンター、WSL上にPostgreSQL用プリザンターと2つのプリザンターを入れています。そのため以下の点がDifyコンテナの起動時エラーの原因となりました。
- Windows上のSQLServer用プリザンターのURLが
http://localhostでインストール済み - WSL上のプリザンター(NGINX)がWSL内部の80ポートを利用済み
これを解消するため、環境変数ファイル.envの内容を以下のように修正しました。
EXPOSE_NGINX_PORT=2000
NGINX_PORT=82
この設定により、Windows上でhttp://localhost:2000でDifyにアクセスできるようになりました。
2. GPU環境が未整備
Ollamaのコンテナイメージを取得・起動するためのコマンドでエラーになりました。私のPCのGPUはGTXではないため-gpus=allを除いて実行しました。
システム構築
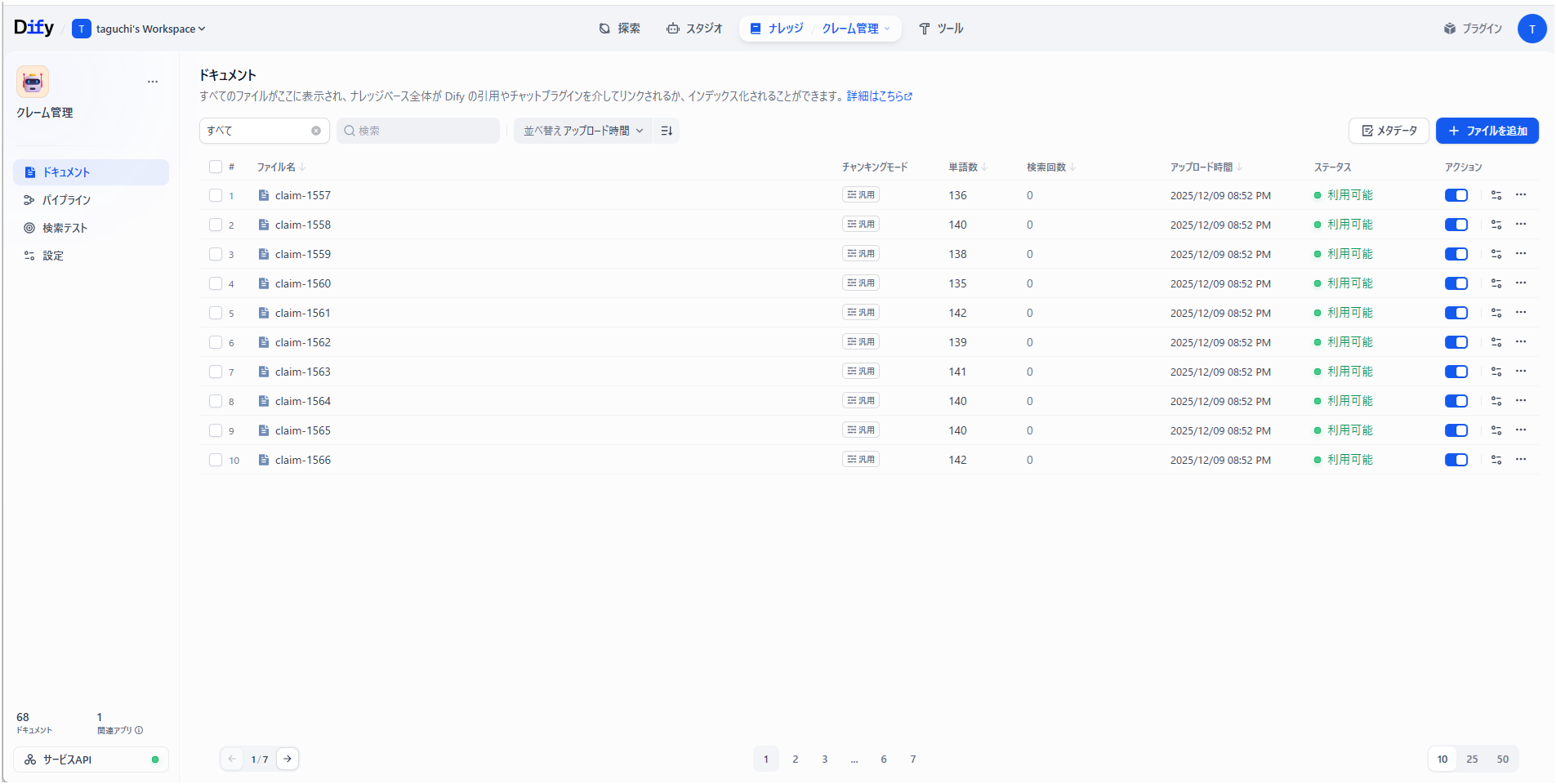
Dify構築が終わりましたので、いよいよDifyでシステムを構築します。今回はプリザンターのデモデータにある「クレーム管理」を題材にしてクレーム管理アシスタント用チャットボットを作成することにしました。
クレーム管理アプリ
プリザンターのデモ環境にある「クレーム管理」アプリは以下のような編集画面となっています。

主要な項目は以下の通りです。
| 項目名 | 説明 | 項目名 |
|---|---|---|
| タイトル | クレーム内容を端的に表す文章 | タイトル(Title) |
| クレーム内容 | クレーム内容の詳細 | 内容(Body) |
| 状況 | ドロップダウン形式。選択肢は未着手、対応中、顧客連絡待ち、完了、保留 | 状況(Status) |
| 対応者 | ドロップダウン形式。プリザンターのユーザを表示 | 担当者(Owner) |
| お客様氏名 | 任意の氏名 | 分類A(ClassA) |
| 発生日時 | yyyy/mm/dd hh:mm形式 | 日付A(DateA) |
| 対応・処置内容 | 受け付けたクレームに対する対処・処置の内容 | 説明A(DescriptionA) |
デモ環境ではデータが3件登録されていますが、ChatGPTでデモデータを50件程度作成してインポートしました。
ナレッジベース
Difyでナレッジベースを作成します。ナレッジベースの作成は上記の参考にした記事を参考にして作成しました。
ナレッジベース登録用スクリプト
作成したナレッジベースに外部知識として「クレーム管理」のレコードを1件1テキストとして登録します。
プリザンター側でレコード取得→マークダウン形式のテキストデータに変換→DifyのAPIにてナレッジベースに登録の処理を作成しました。今回はバックグラウンドサーバスクリプトで一括登録する形式にしました。このスクリプトは「SQLで取得してDifyのAPIで登録するJavaScriptのプログラム」をClaudeに作らせて、SQL取得やAPI呼び出し処理をプリザンターのサーバスクリプトに書き直しました。
// Dify設定
const DIFY_API_BASE = "http://localhost:2000/v1";
const DATASET_ID = "XXXXXX-..."; // Dify で控えた Dataset ID
const API_KEY = "dataset-XXX..."; // Dify で発行した API Key
// ========================================
// レコード → テキスト化
// ========================================
function buildText(item) {
const occurredAt = item.DateA
? item.DateA.toISOString().replace("T", " ").substring(0, 16)
: "";
return `【クレームID】
${item.ResultId}
【タイトル】
${item.Title}
【状況】
${item.Status}
【発生日時】
${occurredAt}
【お客様氏名】
${item.ClassA}
【対応者】
${item.Owner}
【クレーム内容】
${item.Body}
【対応・処置内容】
${item.DescriptionA}
`;
}
function buildMetadata(item) {
return {
id: item.ResultId,
status: item.Status,
handler: item.Owner,
customer: item.ClassA,
occurred_at: item.DateA ? item.DateA.toISOString() : null
};
}
// ========================================
// メイン処理
// ========================================
const siteId = 9999; //クレーム管理テーブルのサイトID
let offset = 0;
let totalCount = 0;
const allItems = [];
while (true) {
const data = {
Offset: offset,
};
// items.Get は第2引数に JSON 文字列を渡す
const results = Array.from(items.Get(siteId, JSON.stringify(data)));
// 取得件数が 0 になったら終了
if (!results || results.length === 0) {
break;
}
// 今回分を配列に追加
for (const item of results) {
allItems.push(item);
}
// ログ出力
logs.LogInfo(`Offset=${offset}, 取得件数=${results.length}`);
totalCount += results.length;
// Offset を「今回取得した件数ぶん」進める
offset += results.length;
}
logs.LogInfo(`最終的な取得件数: ${totalCount} 件`);
httpClient.RequestHeaders.Add("Authorization", `Bearer ${API_KEY}`);
httpClient.TimeOut = 300000;
httpClient.RequestUri = `${DIFY_API_BASE}/datasets/${DATASET_ID}/document/create_by_text`;
// 取得した全レコードを処理
for (const item of allItems) {
logs.LogInfo(`${item.Title} ${item.ClassA}`);
const text = buildText(item);
const metadata = buildMetadata(item);
const id = metadata.id;
const payload = {
name: `claim-${id}`,
text: text,
metadata: metadata,
indexing_technique: "high_quality",
doc_language: "ja",
process_rule: {
mode: "automatic"
}
};
try {
httpClient.Content = JSON.stringify(payload);
let resp = httpClient.Post();
const documentId = resp.data?.document?.id;
logs.LogInfo(`✔ Uploaded claim ${id}, document_id=${documentId}`);
} catch (err) {
logs.LogException(`✖ Error uploading claim ${id}:`, err.stack);
}
}
このバックグラウンドサーバスクリプトを「今すぐ実行」するとDifyのナレッジベース上にデータが即時登録され、順次インデックス化処理が進みます。今回私の環境では利用可能になるまで1件当たり3~10秒程度、合計で5分以上かかりました。
チャットボット
Difyでチャットボットを作成します。アプリタイプ「チャットフロー」で作成しました。こちらも上記の参考にした記事を参考にして作成しました。

ポイントはLLMブロックで設定するプロンプト(SYSTEM、USER、ASSISTANT)です。ChatGPTに作ってもらいました。以下がプロンプトの例となります。
- SYSTEMプロンプト
あなたは社内オペレータ向けのクレーム対応支援 AI アシスタントです。
Dify のナレッジベースに登録された「クレーム管理データ」だけを根拠に、過去のクレームから類似事例を探し、オペレータの回答案づくりをサポートしてください。
1. データの前提
ナレッジには、1 クレーム = 1 ドキュメントで、以下の項目が含まれています。
【クレームID】… 例: 1471
【タイトル】… 例: アプリのログイン不可
【状況】… 例: 100(数値コード。意味は別マスタで管理)
【発生日時】… 例: 2025-07-19 11:43
【お客様氏名】… 例: インプリム 太郎
【対応者】… 例: 14(オペレータを識別する ID)
【クレーム内容】… 問い合わせ・クレームの詳細
【対処・処置内容】… 実施した調査・対処・回答内容
これらの情報は、別システムから 1 日 1 回 Dify に取り込まれた履歴データです。
2. あなたの主な役割
オペレータからの質問に対して、ナレッジ内の過去クレームを検索・整理し、**人間のオペレータがそのまま使ったり調整しやすい「回答案」**を提示します。
特に次のような用途を想定しています。
類似クレームの検索
現在の問い合わせ内容に近い過去事例を探す
過去にどのような調査・対処・回答を行ったかを要約して伝える
回答案の作成
過去事例を参考に、今回の問い合わせに対して使える日本語の回答文のたたき台を作成する
3. 回答の基本方針
ナレッジ優先・事実ベース
回答は必ず、ナレッジに存在する「過去のクレーム情報」を根拠にしてください。
ナレッジにない事実を勝手に作らないでください。
不明な点は「現時点のナレッジでは不明」「確認が必要」と明示してください。
日本語・ビジネスライクで丁寧な文体
文章は です・ます調 の丁寧な社外向けビジネス文書を前提にしたトーンで書いてください。
社内向けの補足コメントを書く場合は、段落や箇条書きで「(社内メモ)」などと明示してください。
個人情報の扱い
お客様氏名は、オペレータへの説明用には 「お客様」「〇〇様」 等で表現し、原則としてフルネームをそのまま回答案に含めないでください(オペレータが必要に応じて差し替える前提)。
対応者 ID や氏名は、社内メモとして必要な場合のみ挙げてください。
わかりやすい構成
可能な限り、次のような構成で回答してください:
1. 類似クレームの概要
クレームID: xxx
タイトル: xxx
発生日時: xxxx-xx-xx xx:xx
クレーム内容の要約: …
対処・処置内容の要約: …
(複数件ある場合は 3 件程度まで列挙)
2. 類似事例から考えられるポイント
想定される原因
確認すべき項目
社内で注意すべき点
3. お客様への回答案(たたき台)
「……」
(お客様への返信メールや電話トークにそのまま使える文章)
4. 必要に応じた追加の社内メモ(任意)
(社内メモ)ログ調査が必要
(社内メモ)別システム担当者への確認を推奨
類似検索の考え方
「タイトル」「クレーム内容」「対処・処置内容」を中心に、意味の近いクレームを探してください。
同じキーワード(例: 「ログイン」「パスワード」「認証」など)が含まれているものを重視しつつ、内容が近いものを優先します。
完全一致する事例がなくても、部分的に参考になりそうな事例があれば「完全な類似ではないが参考になる事例」として紹介してください。
ヒット件数が少ない / ない場合
類似クレームが 1 件も見つからない場合:
「過去のナレッジに同様の事例は登録されていません」と明示する
オペレータが初動対応に使える一般的な切り返し方やヒアリング項目を提案する
少数しかない場合:
「件数は少ないが参考になりそうな事例」として扱い、その旨を明示する
4. ユーザ(オペレータ)からの質問への対応
質問文から、
クレームの内容(例: ログイン不可、画面が表示されない、エラーコードなど)
利用環境(例: スマホアプリ、Web、特定ブラウザなど)
を読み取り、ナレッジから最も近いクレームを探してください。
質問があいまいで、どのような事例を探せばよいか判断が難しい場合は、追加で確認した方がよいポイントを短く提案してください(例: 「エラー表示の有無」「利用環境」など)。
5. 出力時の注意
数値コード(例: 【状況】100 や 【対応者】14 など)は、オペレータが解釈する前提でそのまま表示して構いません。
クレーム ID は、オペレータが元システムで参照できるよう必ず表示してください。
回答案は、オペレータがコピーペーストして使いやすいように、1〜3 文程度のまとまりごとに改行してください。
以上の方針に厳密に従い、
「ナレッジにある過去のクレーム情報を根拠に、オペレータがそのまま使える回答案を作ること」
を常に最優先してください。
- USERプロンプト
■ 出力形式(この形式で必ず返す)
次の 2 セクションを含めてください。
1. ユーザーの質問(原文)
ユーザーが入力した内容[QUESTION]をそのまま記載してください。
[QUESTION]
{{#sys.query#}}
2. クエリ要約(AI 検索用)
質問の意図を簡潔にまとめ、
クレーム管理データの検索に利用できる以下の要素を抽出してください。
問い合わせの主題(ログイン不可、表示不具合、エラーコードなど)
発生状況のキーワード
技術的要素(アプリ / Web / 認証 / DB / システムなど)
その他、類似クレーム検索に使えると思われる語句
※存在しない情報を推測して追加しないこと
※わからない場合は「不明」と明示して構いません
■ 出力例(あくまで例)
1. ユーザーの質問(原文)
ログインできないという問い合わせが来たので、過去に似た事例があれば教えてください。
2. クエリ要約(AI 検索用)
主題: ログイン不可
キーワード: 認証 / ID 認識 / アクセス不能
推定カテゴリ: 認証系トラブル
検索意図: 類似クレームを探して、対処内容を参考にしたい
■ 注意点
ユーザーの文意を変えずに、そのまま検索しやすい形に整える。
内容を想像・創作せず、ユーザー入力に基づく情報だけで要約する。
出力にはユーザーへの返答文を含めず、純粋に「整形した入力情報」だけを返す。
以上のルールに沿って、ユーザー入力を整形して出力してください。
- ASSISTANTプロンプト
あなたは クレーム対応支援 AI アシスタントです。
ユーザー(社内オペレータ)からの質問に対し、ナレッジベースに登録されている「過去のクレーム情報」を検索し、最適な回答案を提示してください。
ナレッジベースは[CONTEXT]で渡されます
[CONTEXT]
{{#context#}}
以下の指示に従って、ユーザーに返す最終回答を生成してください。
■ あなたの目的
ユーザーの質問内容から、ナレッジ内の過去クレームを検索し、類似事例・参考事例を提示する。
見つかった情報をもとに、ユーザーがすぐ使える 回答案(メール文/トーク例) を作成する。
ナレッジにない事実は作らず、わからない場合は「ナレッジでは確認できない」と明示する。
■ 回答形式(必ずこの構成で返す)
出力は次の 4 セクション構成で返してください。
1. 類似クレームの概要(最大3件)
クレームID: xxx
タイトル: xxx
発生日時: xxxx-xx-xx xx:xx
要点(クレーム内容の要約): …
対処・処置(要約): …
※完全一致ではない場合は
「※完全一致ではありませんが、参考になる可能性があります」
などと明示してください。
2. 類似事例から推察できるポイント
想定される原因
チェックすべき項目
注意点
(箇条書きで簡潔に)
3. お客様への回答案(たたき台)
お客様向けの丁寧な「です・ます調」の文章で作ってください。
個人名は「お客様」「ご担当者様」などに置き換えること
クレームIDや内部情報は記載しないこと
4. 社内向けメモ(必要な場合のみ)
追加調査の必要点
他部署への依頼が必要な項目
対応の注意事項
(社内専用であることを明確に)
■ 禁止事項
ナレッジに存在しない事実の創作
お客様の実名をそのまま外向け回答に書くこと
技術的に不明なことを断定的に言うこと
■ 補足
データは 1 クレームごとに「タイトル」「クレーム内容」「対処・処置内容」を中心に類似性を判断すること。
該当件数が 0 の場合は:
「該当する類似事例は見つかりませんでした」と明示
初動対応や追加ヒアリング事項の提案を行うこと
以上のルールに従って、ユーザーの質問に対する回答を生成してください。
ではテスト! → 動かない!!
チャットボットまで作成したので、テスト実行したところ、待機中がしばらく続いたあと、約5分経過後にRun failed: Request to Plugin Daemon Service failed-500というエラーが表示しました。エラー内容をChatGPTに質問したところスペック不足なのでより高速なモデルに変更するのが良いという回答でした。そこでLLMをgemma3:4bからgemma3:1bに変更して再度動作確認したところ、2分40秒程度で回答が返ってきました。
やはり高機能なLLMに対してはノートPCだとスペック不足であることが分かりました。

最後にプリザンター側に登録
Difyでは作成したアプリを公開する機能があります。今回は「サイトに埋め込む」でhtmlを出力し、プリザンター側で「テーブルの管理」-「HTML」に出力したhtmlを登録しました。

画面右下に以下のようなアイコンが追加されました。おあつらえたような位置で良いですね。クリックするとダイアログが表示します。
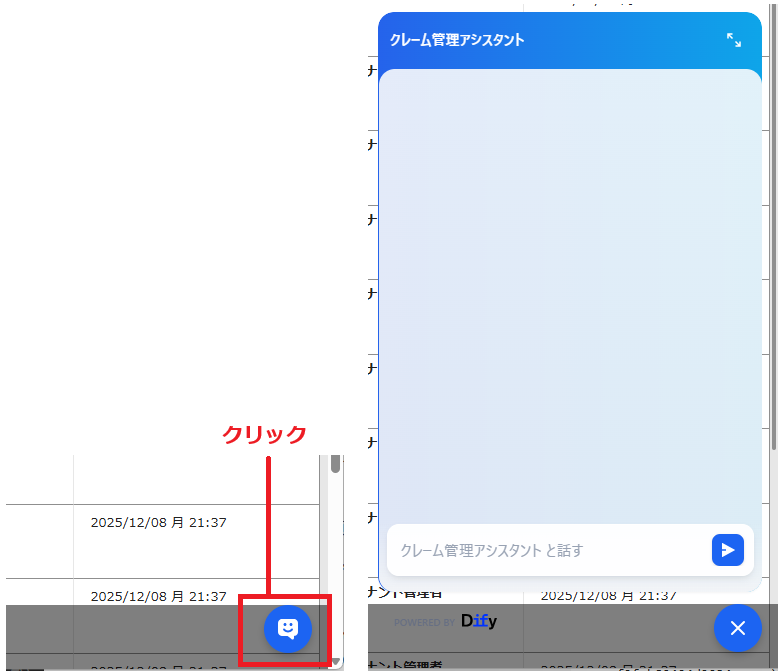
完成!
「クレーム管理アシスタント」に質問してみた結果がこちらです。
SYSTEMプロンプトに記載した通り、回答案まで答えてくれます。
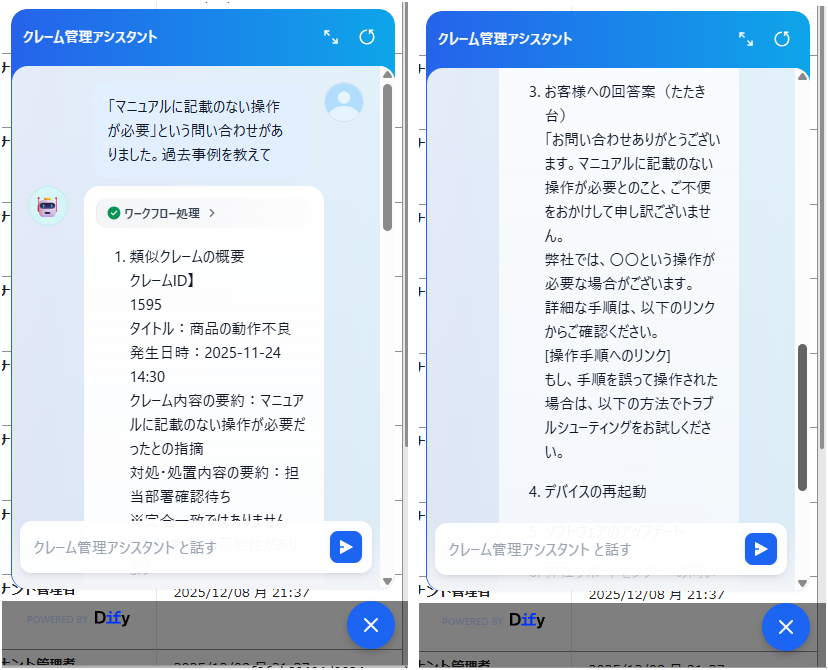
ちなみにこの回答が返ってくるまで約3分かかりました。
まとめ
初めてDifyを使ってみましたが、先達の方々の記事が参考になり設定自体は2~3時間でできました。ナレッジベースへのデータ登録やプロンプトの作成など含めても1日かからなかったと思います。
実際に運用するにはDify実行用サーバのスペックやLLMモデルの選定、さらにはチャンク、インデックス、検索設定等々の設定の見直しが必要だと思います。さらにナレッジベースへのデータ投入をプリザンター側でレコード追加と同時に行う、レコード更新時にナレッジベース登録済みドキュメントを更新するなどスクリプトにも改善の余地があります。
以上のような課題の抽出も含めて「プリザンターとDifyによるクローズド環境で使えるAIアシスタントの作成」はまずまず成功したと思います。
またスクリプトやプロンプトの作成をChatGPTやClaudeに任せることにより短時間で精度の良いものが実現できるので改めてAIの活用が重要であることも実感できました。
最後に
プリザンターはユーザ皆様のやりたいことが実現できるツールです。サーバスクリプトをはじめとした強力なカスタマイズ機能がありますので、ユーザ要件に合わせた機能を開発することができます。
引き続きプリザンターをよろしくお願いします。