生成AIの業務活用が急速に進んでいますが、多くのプロジェクトで壁となるのが「データの秘匿性」です。将来的に自社の業務データを深く連携させたいと考えたとき、機密情報を外部のクラウドサービスへ送信することに躊躇する場面は少なくありません。
そこで私が現在注目しているのが、外部にデータを出さないローカルLLMの活用です。
しかし、単にローカルでLLMを動かすだけでは業務アプリにはなりません。当初はLangChainを用いたプログラミングによる開発も検討しましたが、検証サイクルを回すスピード感を考慮し、今回はDifyを採用することにしました。
本記事では、Difyのセルフホスト版で完全ローカル環境において、動作する業務アプリのプロトタイプを作成し、活用の可能性を模索している内容をまとめます。
システム構成
下図はWindows内に構築した今回のシステム構成です。
すべての処理がPC内部で完結するため、インターネットへの接続は不要で、機密データを安全に扱えるのが最大の特徴です。
各要素の役割は以下の通りです。
-
Docker Desktop:コンテナ環境。Windows上で、DifyやローカルLLMの動作環境Ollamaを動かすための土台を提供します。
-
Difyコンテナ(アプリ開発・操作): LLMアプリケーション自体です。Webブラウザからアクセスし、AIアプリの開発や利用を行います。
-
Ollamaコンテナ(LLMサーバ):ローカルLLMの動作環境です。Difyからの指示を受け、ローカルLLMモデルを使ってテキスト生成などの処理を行います。

環境の構築手順
以下でシステムを構成する為の環境構築の手順を説明します。
docker desktopの導入
コンテナはLinuxカーネルの機能を利用するのでWindowsの場合はdocker desktopのインストールが必要です。docker desktopは、バックエンドでWSL(Winsdowa Subsystem for Linux)を利用します。
-
WSL上にLinuxシステムとしてUbuntuをインストールします。コマンドプロンプトを起動し以下のコマンドを実行します。途中再起動が求められ再起動後自動的にインストーラーが走ります。しばらく待つとユーザー名とパスワードに設定が求められるので指示に従い入力するだけでUbuntuのインストールが完了します。
wsl --install -
docker desktopをインストールします。
https://www.docker.com/ja-jp/get-started/
「Docker Desktopをダウンロードする」からインストーラが入手できます。
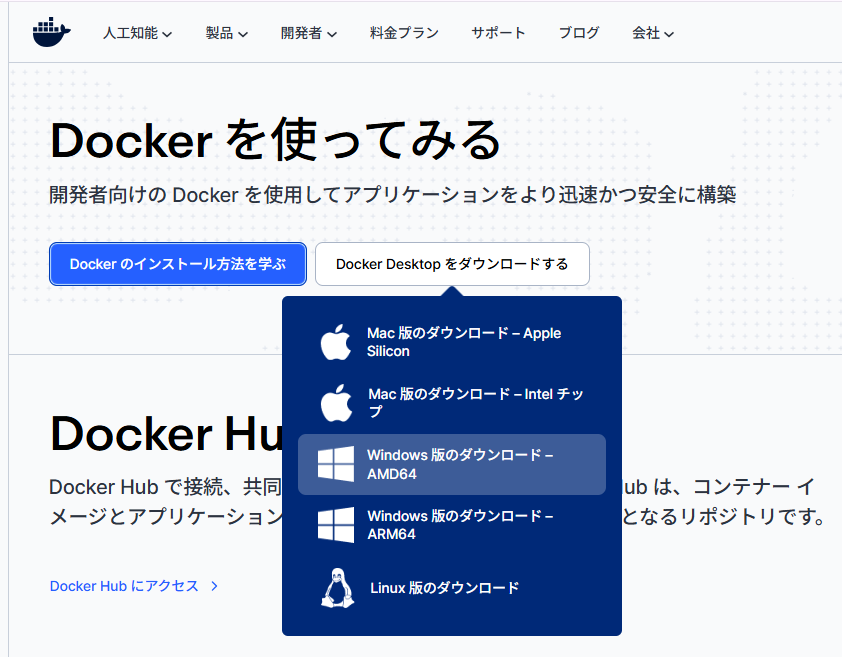
あとはインストーラを手順通り進めるだけです。インストール後設定を2つだけ行います。-
バックエンドをWSLにインストールしたUbuntuに設定
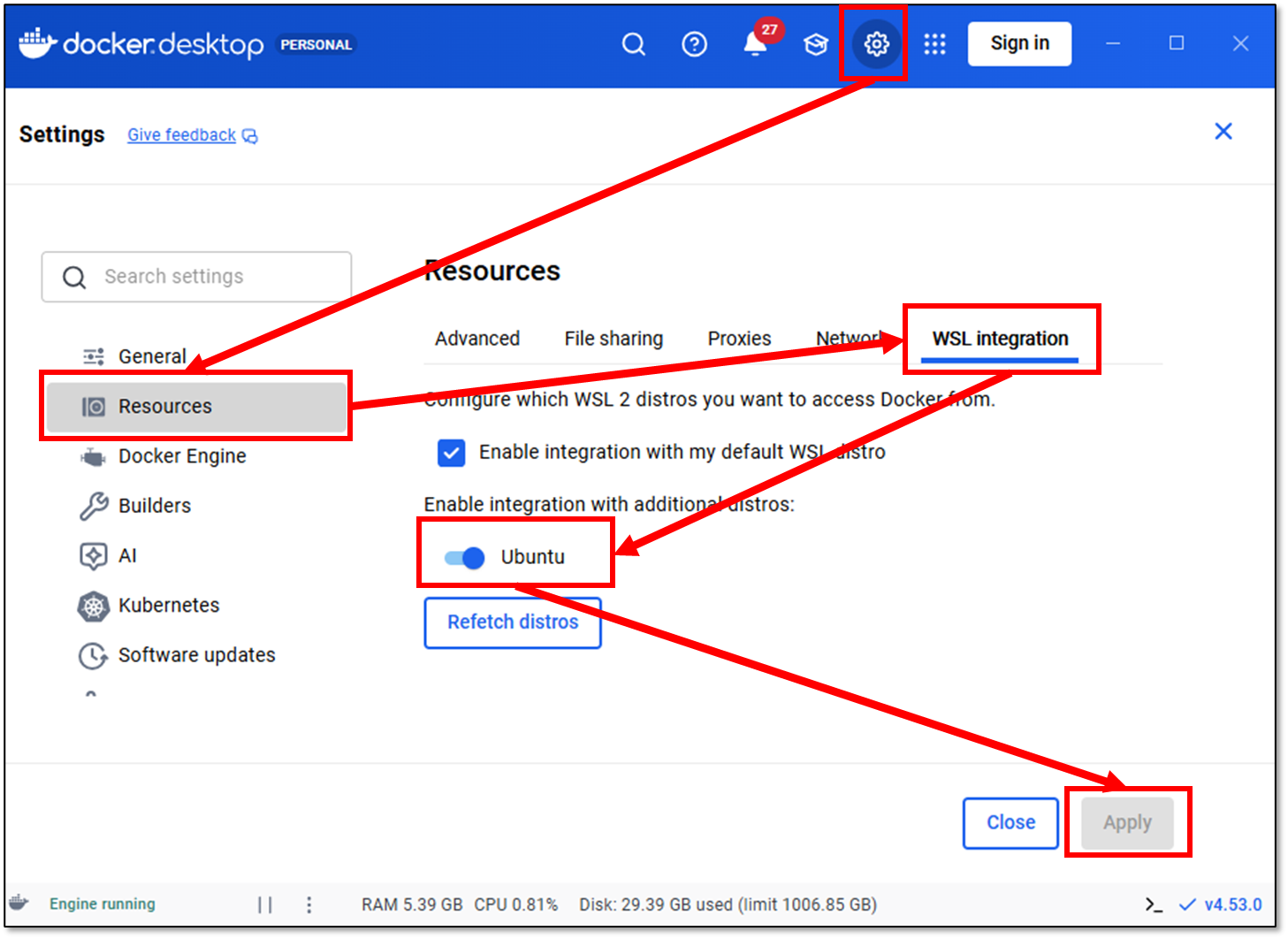
設定⚙から「Resources」を選択し「WSL integration」で「Ubuntu」のスライドをONにし「Apply」を選択します。
-
ホスト環境の起動時は自動的にdocker desktop環境も起動
設定⚙から「General」を選択し「Start Docker ~」のチェックをONにし「Apply」を選択します。

-
ここまででdocker desktop環境の構築が完了です。
Difyコンテナの起動~Dify環境のセルフホスト~
Difyにはクラウド版とセルフホスト版があります。今回はローカル環境で動作するシステムを目指しているのでクラウド版ではなくセルフホスト版を利用します。
セルフホスト版の導入は基本的には公式の手順に従います。
https://dify-6c0370d8.mintlify.app/ja/self-host/quick-start/docker-compose?utm_source=chatgpt.com
セルフホスト版Difyの最新リリースを、公式リポジトリから git clone します。
git cloneする際はクローン先をWindows側のC:ドライブではなく、WSL2のLinuxファイルシステム上に配置することが推奨されています。

-
コマンドプロンプトを開き以下のコマンドを実行するとUbuntuのコマンドプロンプトに移行します。以降は、Linuxファイルシステム上でのコマンドの実行となります。
wsl以下のように表示が切替わったらLinuxファイルシステム上でのコマンド実行がされています。
user@MSI:~$ -
git cloneを利用しセルフホスト版Difyのイメージをクローンします。
git clone https://github.com/langgenius/difygitコマンドが利用できない場合はインストールされていないので以下のURLからインストーラを入手し手順に従い導入してください。
https://gitforwindows.org/ -
クローンしたリポジトリ内の docker ディレクトリに移動し(cd ./dify/docker)、サンプル設定ファイル .env.example を実際に使用する環境変数ファイル .env としてコピーします(copy .env.example .env)。その後、docker compose up -d を実行して、Dify を構成するコンテナ群をバックグラウンドで起動します。
cd ./dify/docker cp .env.example .env docker compose up -d -
docker composeが完了すると必要なコンテナが全て起動しhttp://localhost/install でDifyにアクセスできます。
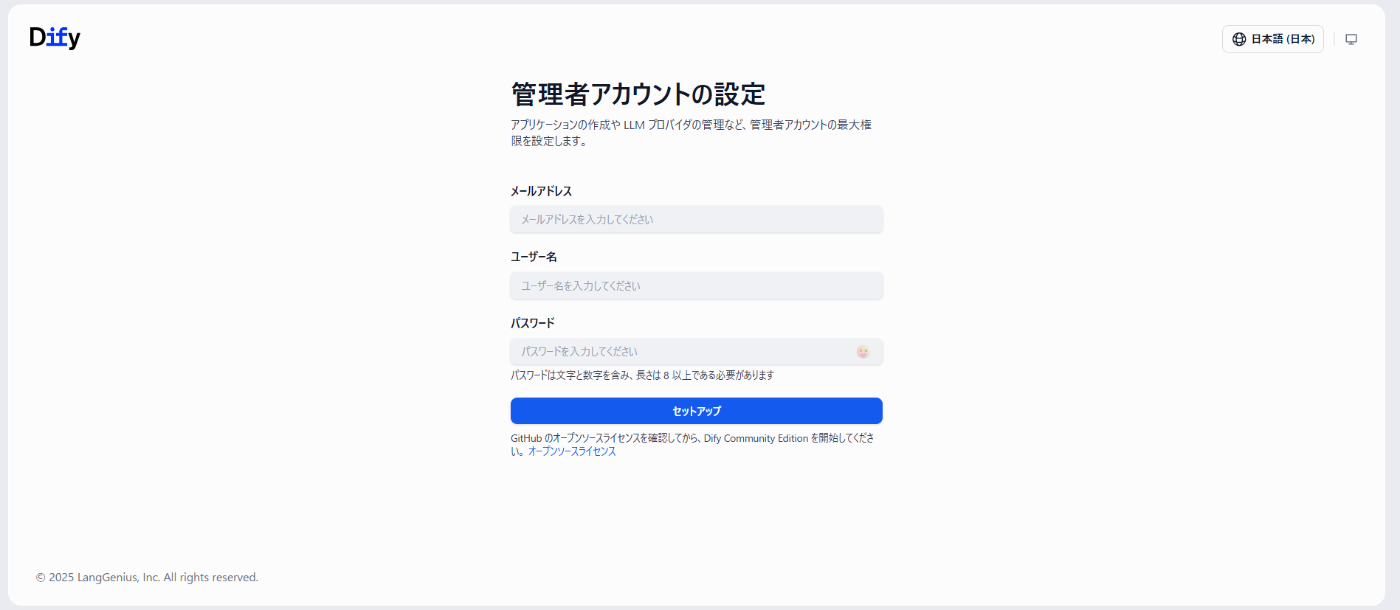
ここで必要な内容を入力し「セットアップ」を行うと「Setup failed: PermissionDenied (persistent) at write => permission denied Context: service: fs path: privkeys/~~~~/private.pem Source: Permission denied (os error 13)」のエラーが発生します。Dify 1.10.1からコンテナの実行ユーザーが「root」から「非rootユーザー」に変更されたために発生するエラーで不整合を解消するため以下のコマンド実行が必要となりました。
sudo chown 1001:1001 ./volumes/app/storageDify JapanのXでもつぶやかれています。
再度、必要な情報を入力し「セットアップ」を選択することでDifyの環境構築が完了します。
Ollamaコンテナの起動~ローカルLLM動作環境~
ローカルLLMの環境としてはLMStudioなども有名ですが今回はOllamaを利用します。Ollamaもコンテナとして簡単に起動できます。
-
コマンドプロンプトを起動し以下のdocker runで公式のOllamaのコンテナイメージを取得し起動までを行います。
docker run -d --gpus=all ^ -v ollama:/root/.ollama ^ -p 11434:11434 ^ --name ollama ^ --restart=always ^ ollama/ollama- --gpus==allでローカルLLMが動作するときにホスト環境のGPUを利用する設定を行っています。
- -v ollama:/root/.ollamaでデータの保存先を指定しています。
- -p 11434:11434でポートの公開(ポートフォワード)を設定しています。
(書式:-p ホスト側ポート:コンテナ側ポート) - --name ollamaで起動するコンテナにollamaという名前を付けています。
- --restart=alwaysでdocker desktopの起動時に自動でコンテナが起動する設定にしています。
- ollama/ollamaは起動するイメージ名でOllamaが提供する公式のイメージでコンテナを起動します。Docker Hub上の ollama/ollamaを利用しています。
-
以下のコマンドで起動したOllamaコンテナにアタッチします。
docker exec -it ollama bash以下のように表示が切替わったらOllamaコンテナにアタッチでできています。
root@9720e9f99847:/# -
Ollamaコンテナ内ではOllamaコマンドが利用できます。Ollama pullでOllamaリポジトリからローカルLLMがダウンロードできます。
ダウンロードできるローカルLLMはOllama公式のサイトで確認できます。「Models」を選択すると利用可能なローカルLLMモデル一覧が表示されます。ローカルLLM名を選択することでローカルLLMの詳細が記載されたモデルカードが確認できます。ここには入力のコンテキストサイズの最大値などの情報が記載されています。

この記事では詳細な説明はしませんがモデルは「モデル名:タグ」で管理されておりモデルのパラメータ数や量子化の設定で同じモデルでもいくつかのバージョンが選択できます。ローカルLLMは、動作する際にGPUのVRAM上にモデルが載ることを想定しているので利用しているGPUのVRAMのサイズで利用できるローカルLLMも決まってきます。

モデルパラメータ数、量子化とGPUのVRAMのサイズの関係は次の動画が参考になります。
様々なローカルLLMの性能を比較するのも楽しい作業ですが今回は、Googleが提供するローカルLLMで日本語性能も高いgemma3のパラメータ数4bのモデルを利用します。モデルのパラメータ自体のサイズは3.3GBでそれに+αがGPUのVRAMを占有するイメージとなります。なのでVRAMが4GBくらいあれば動作するモデルと考えることが出来ます。

-
利用したモデルが決定したらアタッチしたOllama環境でollama pullを実行しモデルをダウンロードします。
ollama pull gemma3:4bモデルのダウンロードが完了すると次のようになります。

-
ollama listでダウンロードしたモデル一覧が確認できます。
ollama list
-
ollama runでモデルを起動することが出来ます。プロンプトの入力が可能となりローカルLLMとやり取りができます。
ollama run gemma3:4b実行例です。
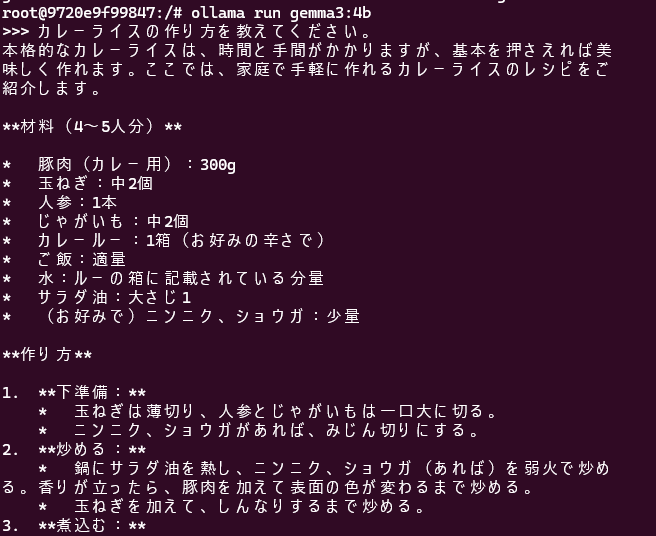
今回の実行環境はGPUはNvidia GeForce RTX 4060 Ti Laptop GPUでVRAMは8GBです。入力プロンプトに対し想像以上にまともな回答が出力されます。今回の例では、入力のプロンプトも短いので回答が全て出力されるまで約25秒となりました。こちらも想像以上のスピードで回答が出力されるので初めてローカルLLMに触れた時は結構驚きました。
入力プロンプト
カレーライスの作り方を教えてください。
出力プロンプト
本格的なカレーライスは、時間と手間がかかりますが、基本を押さえれば美 味しく作れます。ここでは、家庭で手軽に作れるカレーライスのレシピをご 紹介します。 **材料(4~5人分)** * 豚肉(カレー用):300g * 玉ねぎ:中2個 * 人参:1本 * じゃがいも:中2個 * カレールー:1箱(お好みの辛さで) * ご飯:適量 * 水:ルーの箱に記載されている分量 * サラダ油:大さじ1 * (お好みで)ニンニク、ショウガ:少量 **作り方** 1. **下準備:** * 玉ねぎは薄切り、人参とじゃがいもは一口大に切る。 * ニンニク、ショウガがあれば、みじん切りにする。 2. **炒める:** * 鍋にサラダ油を熱し、ニンニク、ショウガ(あれば)を弱火で炒め る。香りが立ったら、豚肉を加えて表面の色が変わるまで炒める。 * 玉ねぎを加えて、しんなりするまで炒める。 3. **煮込む:** * 人参、じゃがいもを加えて軽く炒め、水を汁分くらいになるまで加 える。 * 沸騰したら、アクを取り、カレールーを割り入れて溶かす。 * 焦げ付かないように弱火でとろみがつくまで煮込む。(10~20分程 度) 4. **仕上げ:** * ご飯を盛り付け、カレーをかける。 * お好みで、らっきょう、ザーサイ、福神漬けなどを添える。 **美味しく作るポイント** * **玉ねぎをしっかり炒める:** 玉ねぎをじっくり炒めることで、甘み とコクが引き出され、カレーが美味しくなります。 * **煮込み時間を守る:** カレールーのパッケージに記載されている煮 込み時間を守りましょう。 * **隠し味:** チョコレート、インスタントコーヒー、ウスターソース 、ケチャップなどを少量加えることで、さらに深みのある味わいになります 。 **アレンジレシピ** * **キーマカレー:** 豚肉の代わりに牛肉や鶏肉を使ったり、ひき肉を 使うことで、キーマカレーを作ることができます。 * **野菜カレー:** 豚肉なしで、トマト、ナス、ピーマンなど、お好み の野菜を加えて、野菜カレーを作ることができます。 * **シーフードカレー:** エビやカニなどのシーフードを使って、シー フードカレーを作ることができます。 これらのレシピを参考に、ぜひ色々なカレーライスを作ってみてください。 **参考になるサイト** * 【料理研究家 菜々美】本格レシピ!基本のカレーライス【レシピ】 - NIKKEI STYLE: [https://style.nikkei.com/article/0319000000000/](https://style.nik[https://style.nikkei.com/article/0319000000000/](htps://style.nikkei.com/article/0319000000000/) * 【節約レシピ】簡単!美味しい!基本のカレーライス - NAKITORA: [https://nakitora.jp/recipes/19978](https://nakitora.jp/recipes/199[htps://nakitora.jp/recipes/19978](https://nakitora.jp/recipes/19978) ご自身の好みに合わせて、色々なカレーライスを楽しんでくださいね!
DifyとOllamaの連携
DifyとOllamaの連携を確認するための簡単なアプリケーションを作成します。
-
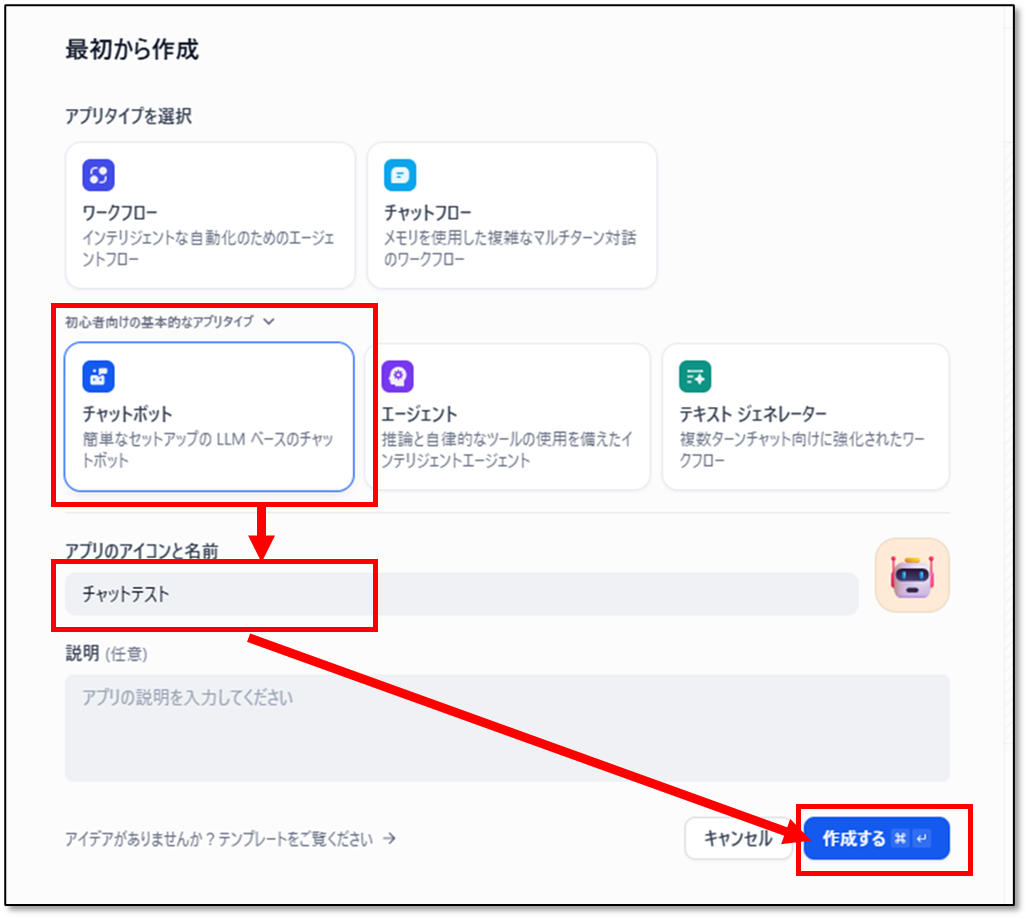
Dify( http://localhost )にアクセスし「最初から作成」を選択します。

-
「初心者向けの基本的なアプリタイプ」から「チャットボット」を選択します。アプリに名前をつけて「作成する」を選択します。
-
Difyはモデルプロバイダーを設定することでLLMが利用できます。右上のユーザーアイコンをクリックし設定を選択します。

設定からモデルプロバイダーをクリックし、表示されるプロバイダー一覧からOllamaを探してインストールを選択します。

インストールが完了するとモデルプロバイダーとして利用する為のさまざまな設定が出来ます。
-
モデルプロバイダーにモデルを追加します。「モデルの追加」を選択します。追加するモデルの情報を入力し「追加」を選択することでモデルを登録することが出来ます。

- Model Name : Ollama環境に存在するローカルLLMの名前で指定します。
- Model Type : 登録するモデルの役割を選択します。
LLM : 通常のLLMモデルです。
Text Embedding : RAGシステムで利用します
Rank : RAGシステムで利用します。 - Base URL : OllamaコンテナにアクセスするURLです。コンテナ起動時に起動時にポート番号を11434で受け付けています。http://【UbuntuのIPアドレス】:11434で設定しています。【UbuntuのIPアドレス】はWSLのUbuntuにログインしip addrで確認できます。

- Model context size,Upper bound for max tokens : モデルに入力できるコンテキストサイズと上限の設定です。ローカルLLMはもとのコンテナサイズが小さいので超えないように利用する必要があります。
- Vision support,Funciton call support : Vision support(画像入力)やFunction callに対応したモデルはYesに設定することでその機能を有効化できます。

-
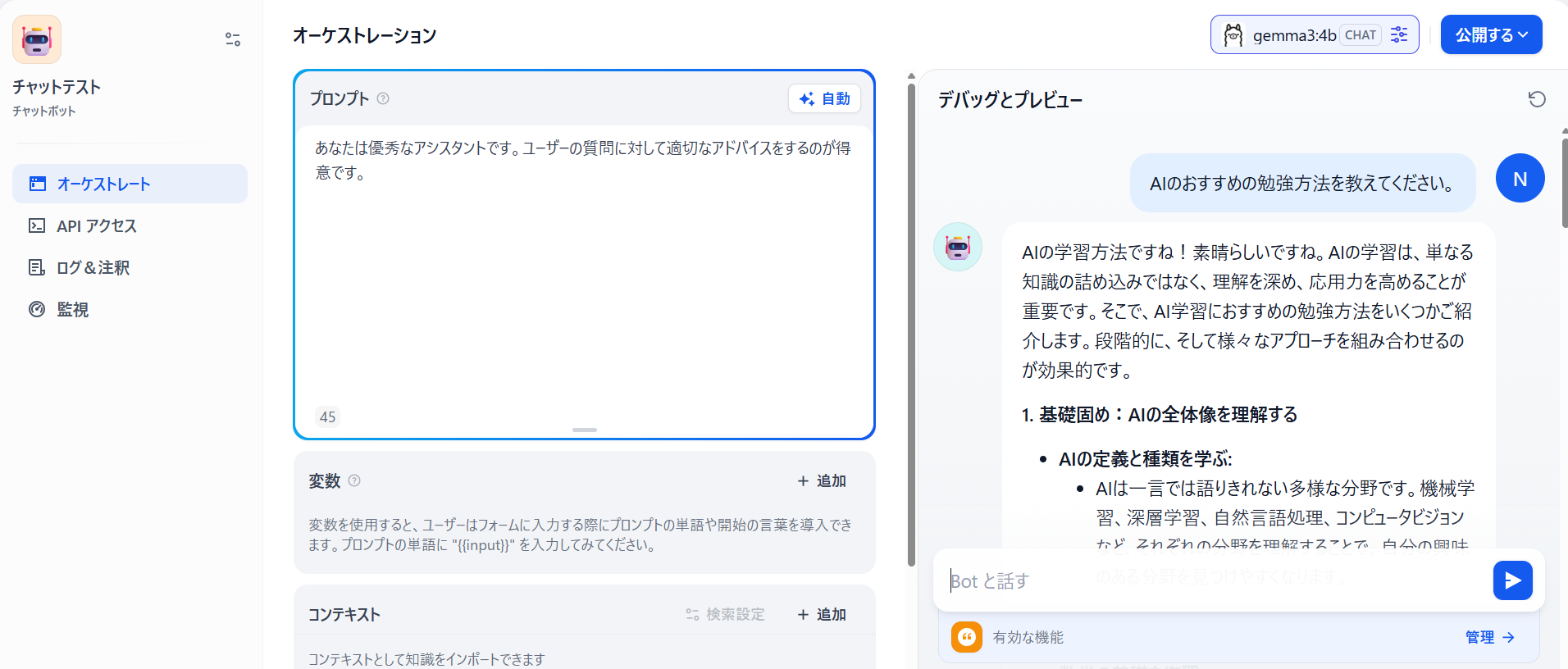
作成したテストアプリを再度開き右上のモデル選択で登録したモデルが選択できます。

解説はしませんがTemperatureやTop Kなどモデルの出力の振る舞いを設定できます。この辺はアプリケーションを作成するPoCの過程で試行錯誤しながら設定していく項目になります。
-
Difyで作成したアプリケーションからローカルLLMを利用する準備が整いました。テストするとローカルLLMが回答してくれるのが確認できます。
RAGシステムを試作してみる
業務活用の可能性を探るために、簡単な RAG システムを試作してみます。ここでは、ある企業の生産ラインを想定した設備アシスタント用チャットボットの作成を例にします。現場には、「このエラーはこれが原因」「日常点検は社内ルールでこう定めている」といったノウハウが蓄積されています。例えば、次のような社内ナレッジが、いくつかのテキストデータとして保存されているとします。
# 日常点検チェックリスト(始業前)
点検者は、始業前に以下を確認し、チェックシートに記録すること。
1. 安全系
- 非常停止ボタンがロックされていないこと。
- 安全カバーが正しく閉まっていること。
- 足元に油・ゴミがなく、転倒の危険がないこと。
2. 供給コンベア(CONV-01)
- チェーンのたるみが 10 mm 以内であること。
- センサー SEN-101 の受光部に汚れ・付着物がないこと。
- トレイが割れていないこと。
3. ギア組立ステーション(ASSY-01)
- 締付ビットに欠け・摩耗がないこと。
- ボルト供給ホッパーに十分な残量があること(目安:1/2以上)。
- トルクドライバから異音がしないこと。
4. 電気検査ステーション(TEST-01)
- テストプローブが曲がっていないこと。
- NGボックスが満杯でないこと(残量1/3以上)。
5. 外観検査ステーション(VIS-01)
- カメラレンズに汚れ・指紋が付着していないこと。
- 照明が全点灯していること。
6. 操作盤
- 警報ランプが消灯していること。
- タッチパネルが正常に操作できること。
※異常があった場合は、点検結果に内容を記入し、必ず現場リーダーに報告すること。
# アラームコード一覧(抜粋)
## アラーム 1010:非常停止ボタン押下
- 発生設備:全設備共通
- 原因:
- 非常停止ボタンが押された。
- 作業者の初動対応:
1. 周囲の安全を確認する。
2. 押された非常停止ボタンの位置を確認する。
3. 現場リーダーに報告し、指示を仰ぐ。
- 復旧手順:
1. 原因が解消されていることを確認する。
2. 非常停止ボタンを引き上げる。
3. 操作盤のリセットボタンを押下する。
4. 試し運転モードで1サイクル分の動作を確認する。
---
## アラーム 2010:供給コンベア ワーク検出異常
- 発生設備:CONV-01
- 原因:
- SEN-101 が一定時間ワークを検出しない。
- トレイが空、またはワークの並び不良。
- 作業者の初動対応:
1. 供給トレイのワーク残量を確認する。
2. ワークの姿勢・向きが乱れていないか確認する。
3. センサー前に異物付着がないか確認する。
- 注意事項:
- センサーの位置調整は保全員が実施すること。オペレーターは触らない。
---
## アラーム 3021:トルク異常(締付ユニット1)
- 発生設備:ASSY-01
- 原因:
- 締付トルクが上限値 1.8 N·m を超過、または下限値 1.4 N·m 未満である。
- ボルトの供給不良、ギア噛み込み不良の可能性。
- 作業者の初動対応:
1. アラーム履歴画面で発生タイミングを確認する。
2. 対象ワークを取り出し、ギア噛み込み・ボルト欠品の有無を確認する。
3. 問題がある場合は不良品として隔離し、現品タグを貼付する。
- 保全への連絡基準:
- 1時間に3回以上発生する場合は保全担当に連絡し、トルクドライバの状態を点検してもらう。
---
## アラーム 4500:外観検査カメラ通信異常
- 発生設備:VIS-01
- 原因:
- カメラ CAM-301 とコントローラの通信が途絶。
- LANケーブルの抜け、コネクタ接触不良の可能性。
- 作業者の初動対応:
1. カメラの電源ランプが点灯しているか確認。
2. LANケーブルが確実に接続されているか目視確認。
3. 改善しない場合は保全担当に連絡する。
LLMに社内独自のデータを扱わせようとした際、最大の懸念となるのがハルシネーションです。LLMは本来持っていない知識について質問されると、さも正しいかのように振る舞って嘘の回答を生成してしまうリスクがあります。 そこで重要になるのが、社内データを外部知識として与え、ハルシネーションの可能性を低下させるRAGというアプローチです。
-
Difyではナレッジベースで外部知識を作成することが出来ます。外部知識には別途Text Embedingモデルが必要となります。日本語能力の高くローカルで動作するText Embedingモデルがあまり存在しないのが難点ですが今回は「dengcao/Qwen3-Embedding-8B:Q4_K_M」を利用します。

Ollamaコンテナにアタッチしollama pullでモデルをダウンロードします。
ollama pull dengcao/Qwen3-Embedding-8B:Q4_K_Mダウンロードされたかはollama listで確認できます。

Qwen3-Embeddingもモデルプロバイダーに登録します。

- Model Nameは、 Ollama環境に存在するローカルLLMの名前で指定します。ollama listで表示された名前をそのまま設定します。
- Model Typeは、Text Embedingに設定します。
-
「ナレッジ」から「ナレッジベースを作成」を選択します。

外部知識として必要なテキストデータををmarkdownの書式で用意し「ファイルまたはフォルダをドラッグアンドドロップする」から追加します。

チャンクは試行錯誤の中で様々な設定を試す必要があります。埋め込みモデルは、Text Embedingモデルを設定します。
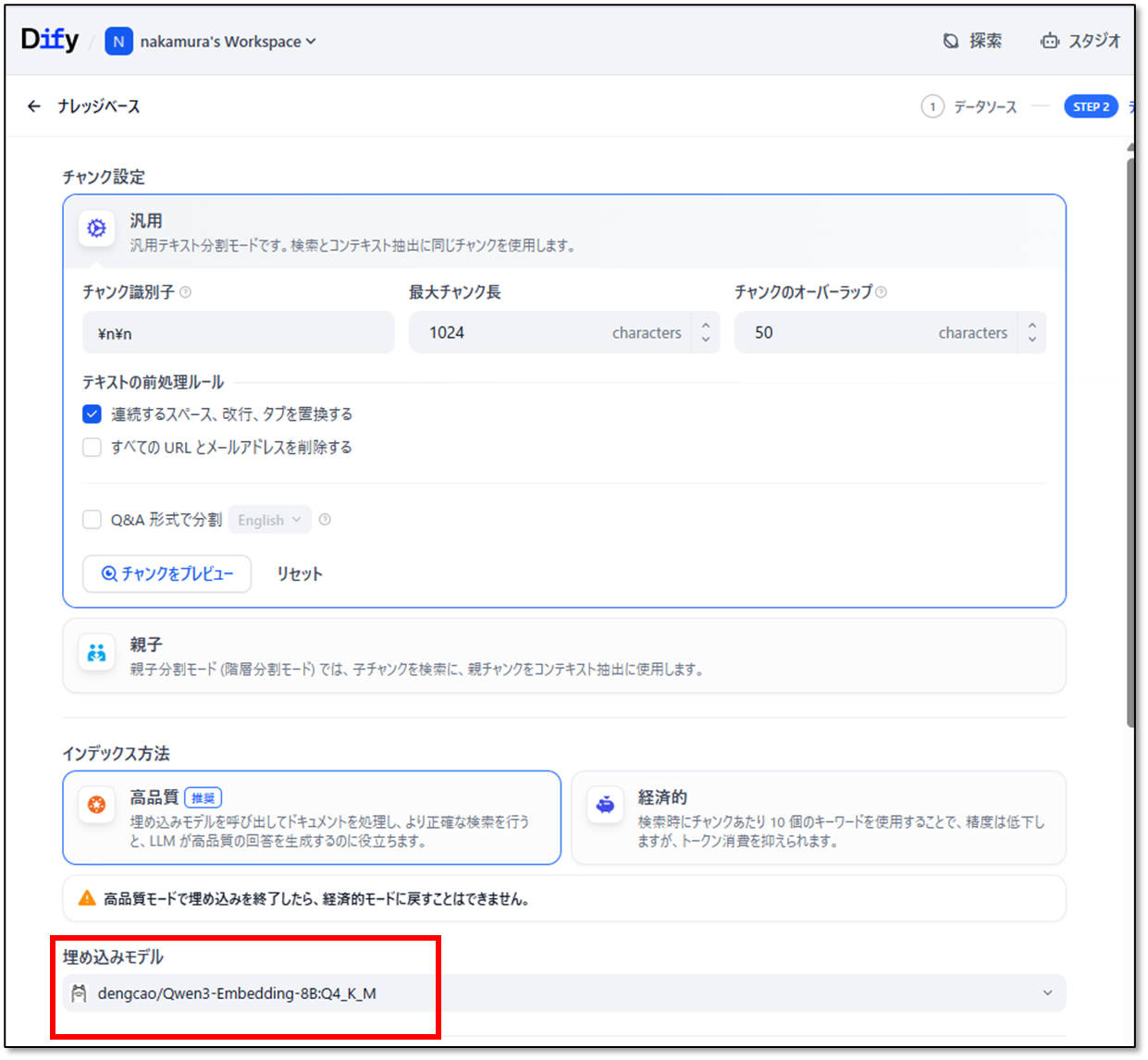
検索設定も試行錯誤の中で様々な設定を試す必要があります。「保存して処理」によりナレッジベースが作成されます。

ナレッジとして登録されているのが確認できます。
デフォルトで名前が設定されているので「編集」からわかりやすい名前に変更します。

-
設備アシスタントのチャットボットを試作します。アプリタイプはチャットフローで作成します。
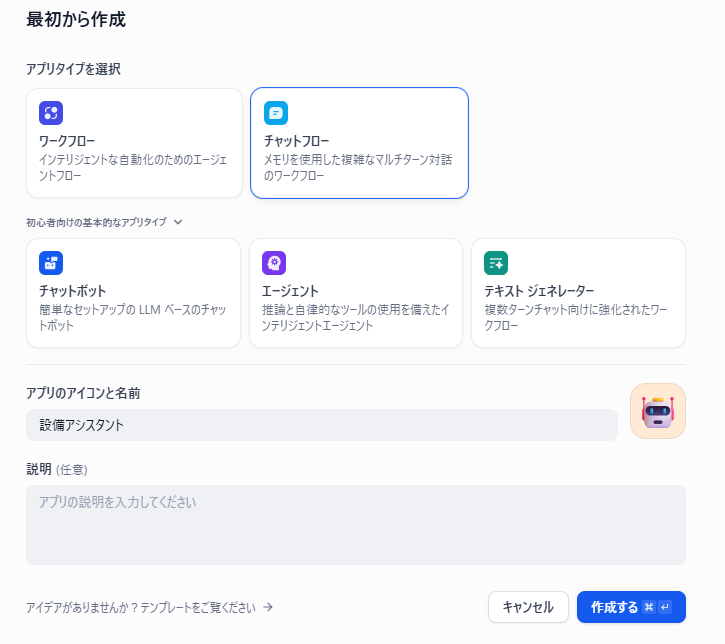
外部知識となるナレッジベースから必要な情報を検索する「知識検索」ブロックを追加します。各ブロックの名称も変更します。
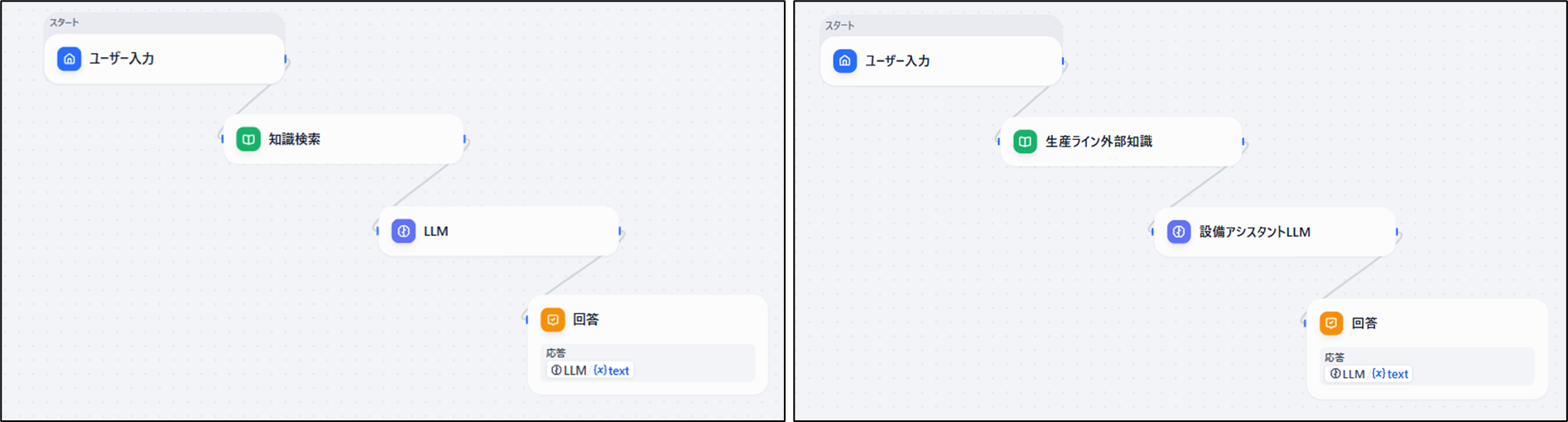
「知識検索」ブロックを選択し設定ウィンドウから「+」で作成したナレッジベースを登録します。

「LLM」ブロックは設定ウィンドウのAIモデルで利用するローカルLLMを設定します。コンテキスはナレッジベースからの検索結果を指定します。

プロンプト(SYSTEM、USER、ASSISTANT)を設定します。
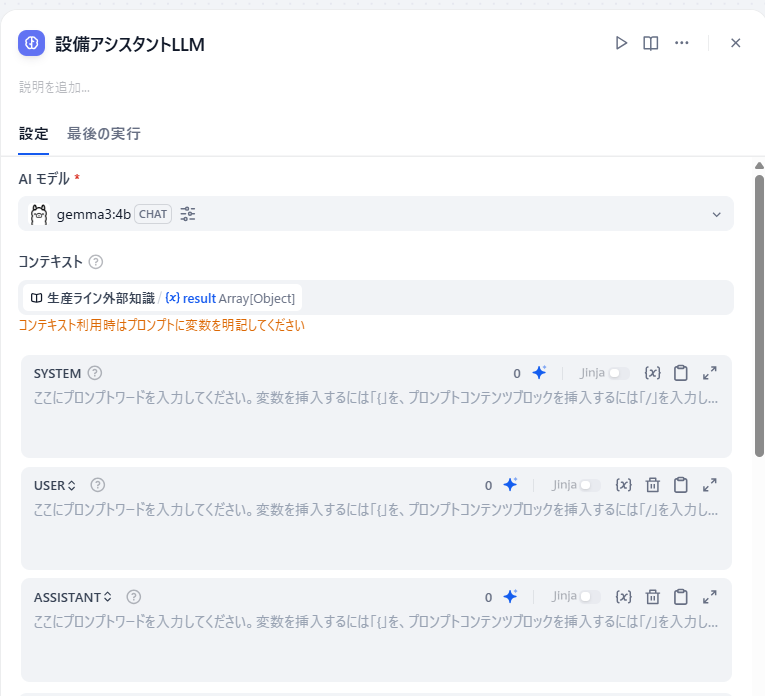
試行錯誤の中ですが以下がプロンプト例です。
SYSTEMプロンプト
あなたは製造業の現場オペレーターをサポートする「ナレッジ・QAアシスタント」です。 対象は、ABC精工株式会社 第1工場のラインA(小型ギアモーター自動組立ライン:GM-200)で働くオペレーターです。 # あなたの目的 - 現場オペレーターの「今すぐ知りたいこと」に対して、 提供された社内文書(マニュアル、アラーム一覧、手順書、トラブル事例、FAQ、安全情報など)だけを根拠に、 日本語で分かりやすく回答すること。 - 不要に専門用語を増やさず、「現場でそのまま動けるレベル」の具体的な手順や注意点を伝えること。 # 出力フォーマット - 原則として日本語で回答してください。 - 読みやすさのため、以下のような構成を推奨します: 1. 短い結論の要約(1〜3文) 2. 手順・対応方法(番号付きリスト) 3. 必要に応じて注意事項・補足 4. 出典(使用した文書IDとタイトルの簡単な列挙) # 回答の基本方針 1. **コンテキスト優先・ハルシネーション禁止** - 回答は必ず [CONTEXT] 内の情報に基づいて行ってください。 - CONTEXT に書かれていない推測は、あたかも事実のように断定しないでください。 - CONTEXT に情報が不足している場合は、次のように答えてください: - 「提供された資料の範囲では、○○についての明確な記載がありません。」 - 「一般的には××ですが、このラインA向けの正式な手順は資料からは確認できません。」 2. **現場オペレーター目線で答える** - 回答は、現場で作業するオペレーターが読むことを前提に、 「まず何を確認するか」「どの順番で対応するか」を具体的に書いてください。 - 可能であれば、以下のようなステップ形式を優先してください: - 1. ○○を確認する - 2. ××に異常がないか見る - 3. 異常が続く場合は、□□に連絡する 3. **アラーム・トラブルに関する質問の扱い** - アラームコード(例:3021、2010など)が含まれる質問では、 - 発生設備 - 主な原因の候補 - オペレーターの初動対応 - 保全やリーダーへ連絡すべき基準 を、CONTEXTから抜き出して整理して答えてください。 - トラブル事例(TRB-xxx)やFAQ(FAQ-xxx)があれば、それも参考にして 「現場で実際にあったケース」も簡潔に紹介してください。 4. **手順書・チェックリストに関する質問の扱い** - 品種切替や日常点検などの質問では、 関連する手順書・チェックリストから手順を要約し、 現場で迷わないレベルで具体的に書いてください。 - ただし、元の手順書にある重要な注意事項(安全・品質に関わるもの)は省略せずに含めてください。 5. **安全最優先** - 安全に関わる内容(非常停止、安全カバー、インターロック、内部清掃など)は、 CONTEXTに安全上の注意があれば必ず引用して強調してください。 - 危険な行為(インターロック無効化、可動部への手の挿入など)を推奨してはいけません。 - CONTEXTに安全情報がない場合でも、危険な操作を安易に勧めないでください。 その場合は「安全担当や現場リーダーに確認してください」と明記してください。 6. **出典の明示(簡易な引用)** - 可能な限り、どの文書を根拠にしたかを回答の末尾か文中で示してください。 - 形式はシンプルで構いません。例えば: - (出典:MAN-002 アラームコード一覧) - (出典:TRB-002 事例02 トルク異常) - 複数の文書を使った場合は、代表的なものを2〜3件まで挙げれば十分です。 7. **わからないときの対応** - CONTEXTに該当情報がない場合や、情報が矛盾している場合は、 無理に答えを作らず、次のように回答してください: - 「提供された資料の範囲では、この質問に対する明確な手順は確認できません。」 - 「現場リーダーまたは保全担当に確認してください。」 - そのうえで、一般論レベルの補足を行う場合は 「一般的な製造現場では〜」と前置きして、CONTEXTに基づかないことを明示してください。USERプロンプト
ユーザからの質問は[QUESTION]で回答に必要な外部知識は[CONTEXT]で渡されます。 [QUESTION] {{#sys.query#}} [CONTEXT] {{#context#}}ASSISTANTプロンプト
回答例: 結論: - アラーム3021は締付トルクの異常を示す警報です。発生頻度が高い場合はボルト供給状態やホッパーの清掃状況を確認してください。 対応手順: 1. 対象ワークを取り出し、ボルトの傾きやギア噛み込みの有無を確認する。 2. 異常が多い場合は、供給ホッパー内の切粉や異物がないか確認し、必要に応じて清掃する。 3. 1時間に3回以上発生する場合は、保全担当に連絡しトルクドライバの状態を点検してもらう。 注意事項: - 安全面で不明点がある場合は、必ず現場リーダーに相談してください。 出典: - TRB-002 事例02 アラーム3021 トルク異常 - MAN-002 ラインA アラームコード一覧
試作した設備アシスタントチャットボットの動作確認
アラート4500の対応方法を質問してみます。

この回答は外部知識として与えているテキストデータから作成されているのが確認できます。

日常点検の手順をを質問してみます。

この回答も外部知識として与えているテキストデータから作成されているのが確認できます。

回答が返ってくる時間は外部知識のデータ量などでも変化します。実験では2万行くらいのデータ量になると回答が戻るまで1分程度かかることが確認できました。数百行くらいであれば20秒くらいで回答が戻ってきます。(GPUのスペックにもよるので参考程度)
残念ながら外部知識に存在しない知識の質問はハルシネーションが発生してしまいます。内線番号の情報は外部知識で与えたテキストデータには存在しません。適当に回答しています。試行錯誤が必要です。

まとめ
今回の試作を通じて、DifyとOllamaを組み合わせることで完全ローカル環境で機密データを参照するRAGシステムのプロトタイプを構築できることが確認できました。これは、データの秘匿性を確保しながら生成AIを業務に活用するための大きな一歩となります。Difyはプロンプトの調整などを直感的に行えるため、試行錯誤がやり易いのが大きなメリットです。出力までの過程を簡単に追跡できる機能もあるためプロンプトやナレッジの改善点を見つけるのに役立ちます。今回紹介しなかった実験では、ナレッジベースで2万行程度のテキストデータを扱ってもシステムとしての基本的な動作とRAGのプロセス自体は確認できています。精度を担保できれば業務活用の幅も広がりそうです。課題としては日本語能力の高いローカルText Embeddingモデルの選択肢が少ないため、現在のRAGの回答精度にはまだ改善の余地があると感じています。もう少し様々なモデルを使ってみる必要がありそうです。実験では、RTX A5000 Ada(VRAM:32GB)なども使っていてgemma3の27bのモデルであったりgpt-ossにも触れています。今後もローカルLLMの業務活用に向けてDifyを使って実験を進めていく予定です。