YOLOに並んで話題のSSD(Single Shot Multibox Detector)の論文を読んでみました。
論文・参考
論文
https://arxiv.org/abs/1512.02325
以下の記事、スライドにとてもお世話になりました。
- Qiita 記事
- 参考になるスライド(上記Qiita記事より)
モデル
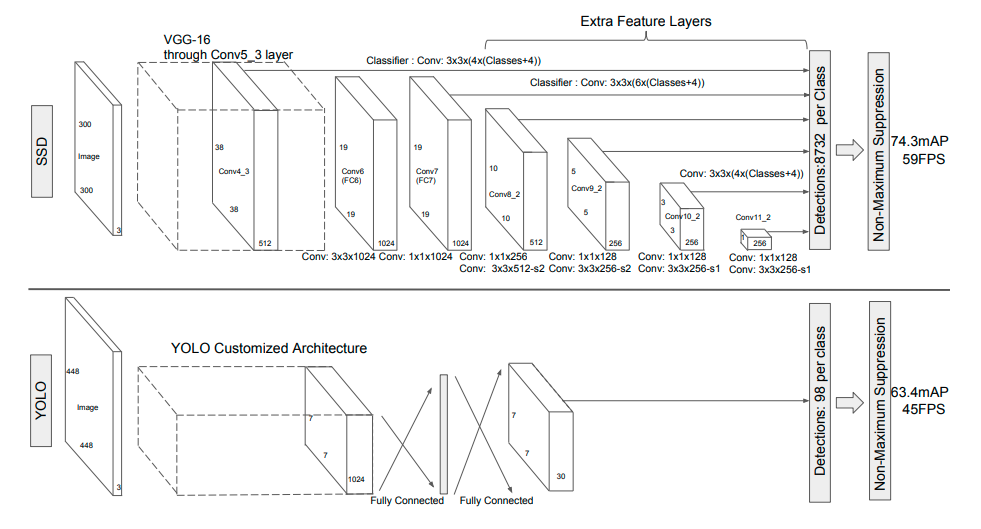
こちらの図の方がイメージしやすい。
https://qiita.com/IshitaTakeshi/items/915de731d8081e711ae5#ssd
- CNN(VGG26)などで得られたFeature mapを、Multiboxに入力して物体を検出。同時にクラスも推定
- CNNの特徴マップのサイズは様々なので、多様なサイズのオブジェクトを検出できる
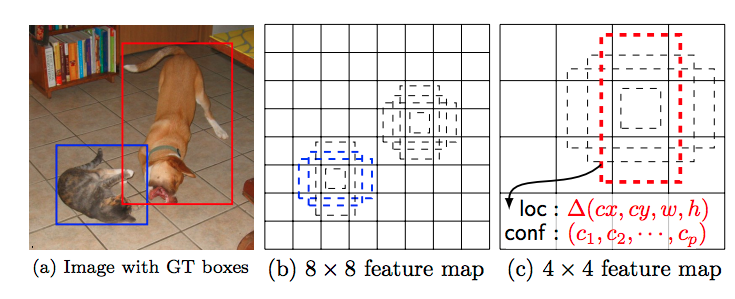
- SSDは、入力に以下が必要
- 画像
- Ground truth box(学習に使う)
- それぞれのfeature mapに対応した、defaultがある
- 複数のアスペクト比が定義されている(後述)
- ネットワークは以下を推論する
- 中心座標(cx, cy)
- width/height(w, h)
- カテゴリ([$c_1$, $c_2$,,,,$c_p$])
こちらのP40, 41が分かりやすい
目的関数
数式の一部は、Scalable High Quality Object Detection(2015)を参照した方が分かりやすい。
x_{ij}^p = \{1, 0\}
Scalable High Quality Object Detection(2015)では、$x_{ij}$ = 1をi番目の、prediction が、j番目の grand truthと一致した事を示すとされている。$x_{ij}$ = 0 はそれ以外の場合を示す。
本論文では、複数のカテゴリに対応させるため、category(class) p の j番目の grand truth box に一致したかどうかを示すため、x_{ij}^p と定義した。
- $x$ : input
- $c$ : confidence (class)
- $l$ : predict box
- $g$ : ground truth box
L(x,c,l,g) = \frac{1}{N}(L_{conf}(x, c) + \alpha L_{loc}(x,l,g))
$L_{loc}(x,l,g)$ は、Scalable High Quality Object Detection(2015)では では以下の通り定義されていた。
F_{loc}(x, l, g) = \frac{1}{2}\sum_{i, j}x_{ij}||l_i - g_i||^2_2
※ $||x||_2$は、L2ノルム
本論文では以下の通り
L_{loc}(x,l,g) = \sum^N_{i \in Pos}\sum_{m \in {cx, cy, w, h}} x^k_{ij} {\rm smooth_{L1}}(l^m_i-\hat{g}^m_j)
Smooth L1 Loss
短形回帰(box regression)
smooth_{L1}(x) = \left\{
\begin{array}{ll}
0.5x^2 & if (|x| < 1) \\
|x| - 0.5 &otherwise
\end{array}
\right.
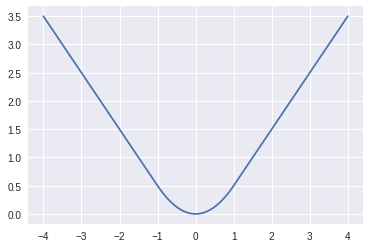
Note: plot したコード
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-4, 4, 100)
y = [smoothL1(i) for i in x]
plt.plot(x, y)
正規化
- $l$ : predict box
- $g$ : ground truth box
- $(cx, cy)$ : offset for the center
- $d$ : default bounding box
- $w$, $h$ : width/height of default bounding box
\hat{g}^{cx}_j = (g^{cx}_j - d^{cx}_i) / d^{w}_i
\hat{g}^{cy}_j = (g^{cy}_j - d^{cy}_i) / d^{h}_i
\hat{g}^{w}_j = \log(g^{w}_j / d^{w}_i)
\hat{g}^{h}_j = \log(g^{h}_j / d^{h}_i)
クラスの損失関数
L_{conf}(x, c) = -\sum^N_{i \in Pos}x^p_{ij}\log(\hat{c}^p_i) -\sum^N_{i \in Neg}x^p_{ij}\log(\hat{c}^0_i)
\hat{c}^p_i = \frac{\exp(c^p_i)}{\sum_p{\exp(c^p_i)}}
Choosing scales and aspect ratios for default boxes
-
異なるオブジェクトサイズのものに対応するため、複数のFeature mapを使う
-
$m$ はレイヤ数に対応
- 大きいほど、小さいオブジェクトを扱える
-
$s_k$ は、$k \in [1, m]$ でオブジェクトサイズ。
s_k = s_{min} + \frac{s_{max} - s_{min}}{m-1}(k-1)
-
例えば、$s_{min}$ = 0.2、$s_{max}$ = 0.9 の場合、一番小さいスケールが0.2 で、大きいのが0.9。その間は等間隔となる。
-
異なるアスペクト比として、以下を容易。
- $a_r$=1,2,3,1/2,1/3
-
それぞれの幅、高さを計算して、バウンディングボックスを用意
w^a_k = s_k \sqrt{a_r} , h^a_k = s_k / \sqrt{a_r}
アスペクト比が1の時は、以下のスケールのバウンディングボックスを追加
s_k = s_{min} + \frac{s_{max} - s_{min}}{m-1}(k-1)
合計6つのバウンディングボックスを使う
Hard negative mining
- ほとんどのバウンディングボックスは、negative となる
- 信頼度の高い順にソートし、それぞれのDefault boxでトップのものをピックアップし、Negative:Positiveが、3:1 になるようにする
- これにより、最適化が早く・安定する
Data augumentation
以下の方法でサンプリング
-
そのまま
-
切り抜いたサンプルのオブジェクトとの重なり度(jaccard)が、0.1, 0.3, 0.5, 0.7, 0.9
-
ランダムに切り抜き
-
切り抜きは、オリジナルサイズの[0.1, 1]の範囲
-
アスペクト比は、1/2 - 2の範囲
-
ground truth box の一致部が重なり合っていて、それが切り抜いたサンプルの中央にある場合は、それを維持
-
上記のサンプリングを行った後、固定サイズにリサイズ
-
その後0.5 の確率でランダムFlip
-
さらに、phot-metric な歪みを加える(色を変える)
Experimental result
- base network として VGG16を使う
- ILSVRC CLS-LOC dataset(imagenet の Object recognition版)でpretrained
- fcレイヤーをコンバートし、finetuning (詳細略)
- pool5 を 2x2-s2 から、3x3-s1 に変え、atrousアルゴリズム を使い、穴を埋める
- Dilated畳み込みとも言われる。Poolingは解像度を下げるため。
* https://arxiv.org/abs/1606.00915
- Dilated畳み込みとも言われる。Poolingは解像度を下げるため。
以下、SSD300は、300x300の画像を入力として使う。
SSD512は、512x512。
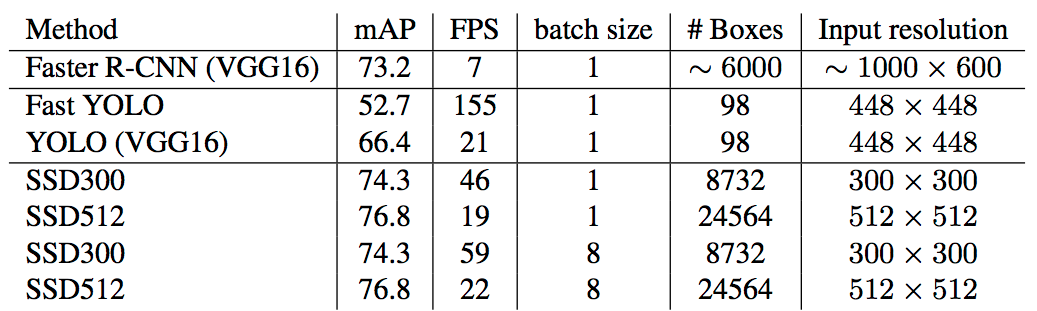
Pascal VOC 2007
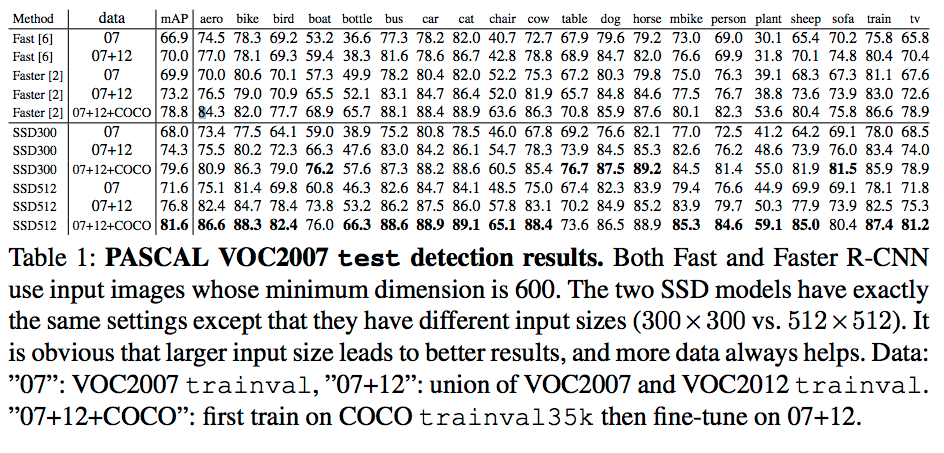
Table.1
Fast とFaster R-CNNは、入力画像として、600pixを使う。
SSDは、サイズが異なるが同じ設定。
- 上記から、
- 入力画像は大きい方が良い
- データは多い方が良い
- SSD300は、常に、Faster R-CNNより良い
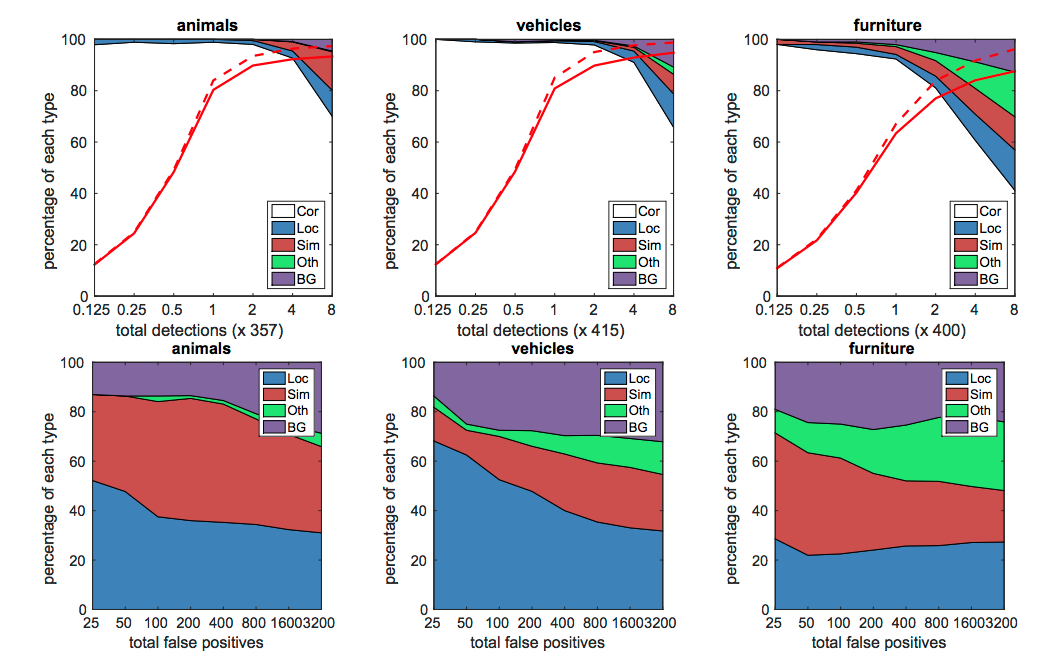
Fig.3
-
Cor : Correct
-
Loc : 誤った位置(poor localization)
-
Sim : 誤った、似たようなカテゴリー (similar category)
-
Oth : その他
-
BG : 背景
-
赤い実線: 0.5 jaccard overlap(重なり率) での recall(再現率)
-
赤い点線: 0.1 jaccard overlap
-
1段目のグラフ
- 積み上げグラフ(累積割合グラフ)
- 横軸はディテクション数
- 認識を繰り返したときの制度変化を見ている
-
2段目のグラフ
- false positive の分布
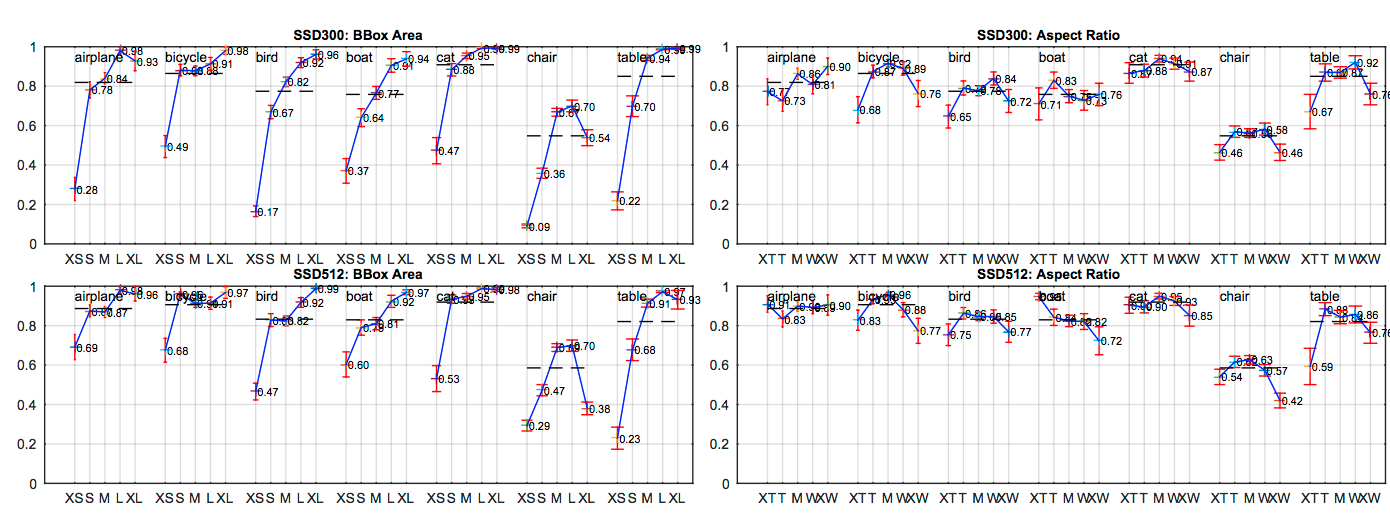
Fig4.
- VOC2007における、異なるオブジェクトの特長が、Sensitivityとインパクトに与える影響
- 左側:Bounding box の大きさによるカテゴリ毎のAccuracy
- 右側:Aspect ratio による、カテゴリ毎のAccuracy
- 大きさ
- XS: extra-small
- S=small
- M=medium
- L=large
- XL=extra-large
- アスペクト比
- XT = extra-tall/narrow
- T=tall
- M=medium
- W=wide
- XW=extra-wide
Model analysis

Table 2.
- data augmentation 重要
- デフォルトボックスは多い方が良い
- atrous は速い

Table 3
- 複数の解像度の複数レイヤーを用いた方が良い
Data Augmentation for Small Object Accuracy
- 小さなオブジェクトのAccuracyを高めるためのData augmentation
- (本論文中には書いていないが)YOLOの弱いところと言われる
- zoom-in、zoom-outの操作をData augmentationに加える
- クリップして拡大縮小
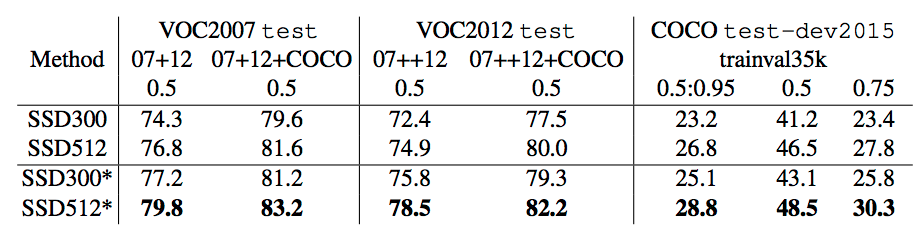
Table 6
"*" が、上記の data augmentation をしたもの

COCO test-dev でのサンプル。
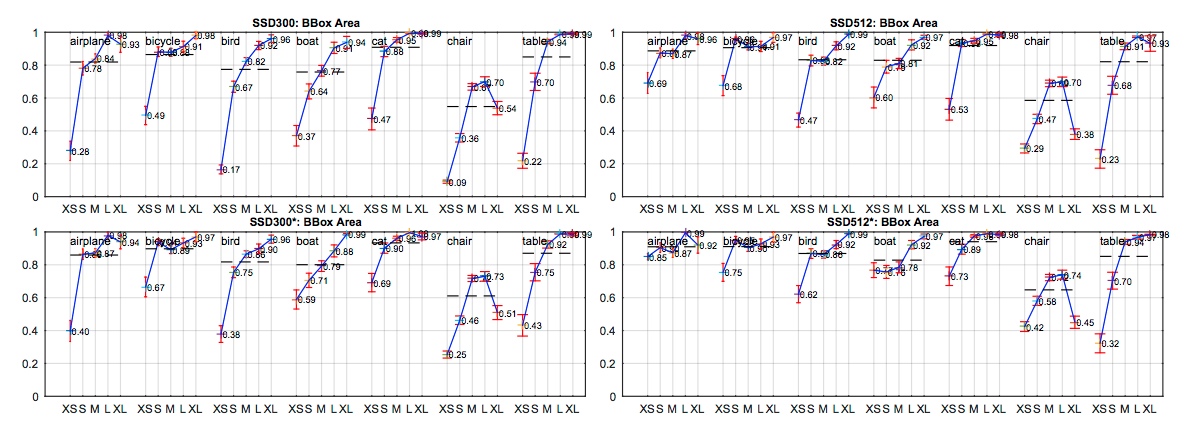
Fig 6
こちらも、* がdata augmentation を使ったもの。小さい画像で改善が見られる。
Inference time
- 2.4 msec per image
- SSD300
- 20 classes
- batch size 8
- Titan X, cuDNN4, Intel Xeon E5-2667v3@3.2GHz
Conclusion
- SSD は高速に複数カテゴリのObject detectionができる
- 重要なのは、Multi-scaleのConvolutionでBounding boxを出力すること
- 今回、VGG-16ベースのモデルでState-of-the-artである事を示せた
補足
以下、著者のポエムです
- YOLOよりもSSDの方が速いですが、YOLOv2 の方が速いです。
- Multibox が何なのかは(当然ながら)この論文では分かりません。こちらを読まないと。。