はじめに
SSD(Single Shot Multibox Detector)で道路の損傷を検出しました.
作業環境等に関しては株式会社パソナテックさんにご協力いただきました.
なお成果物は学習済みモデルとともにGitHubに公開されています.
不具合もまだ複数あると思いますので,気軽にissueを立てていただければと思います.
やったことを最初から文章で説明するより,まずは成果物を見ていただいたほうが早いと思うので,デモをお見せします.




このように,横断歩道やセンターラインのかすれ,陥没,ひび割れなどを検出することができます.
道路の損傷を検出する方法はいろいろありますが,画像認識を用いるならば,車で移動しながらスマホや車載カメラでリアルタイムに検出できると便利です.
このような認識手法を採用するのであれば,デバイスの制約により,計算量が小さいモデルが求められます.
道路の損傷を物体認識によって検出する手法はすでに論文1になっており,さらにtutorialやデータ,学習済みモデルも公開されています.
今回は,VGG16ベースのSSDによる上記論文の追試を行い,アーキテクチャの変更による精度向上を目指しました.
また,この記事では,結果としてVGG16ベースのSSDでは比較的安定した精度が得られたことと,ResNet-101ではデータ不足によりVGG16での精度に達しなかったこと,またその要因を報告します.
さらに,VGG16ベースのSSDとResNet-101ベースのSSDで実行速度の比較を行い,GPUで上は互角であるもののCPU上ではResNet-101ベースのもののほうが高速に検出を行えたことを示します.
データ
道路検出に用いられるデータセット(RoadDamageDataset)には7つの地区で撮影された道路画像が含まれています.
各画像には損傷箇所を示すbounding boxと,損傷の種類を表すラベルがつけられています(表1)(図1).
データのフォーマットは,物体認識などのデータセットとして名高いPascal VOCと同じものが採用されていたため,Pascal VOCのデータセットローダをそのまま流用することができました.
 表1 損傷の種類とそのラベル (Maeda, Hiroya, et al. (2018))
表1 損傷の種類とそのラベル (Maeda, Hiroya, et al. (2018))
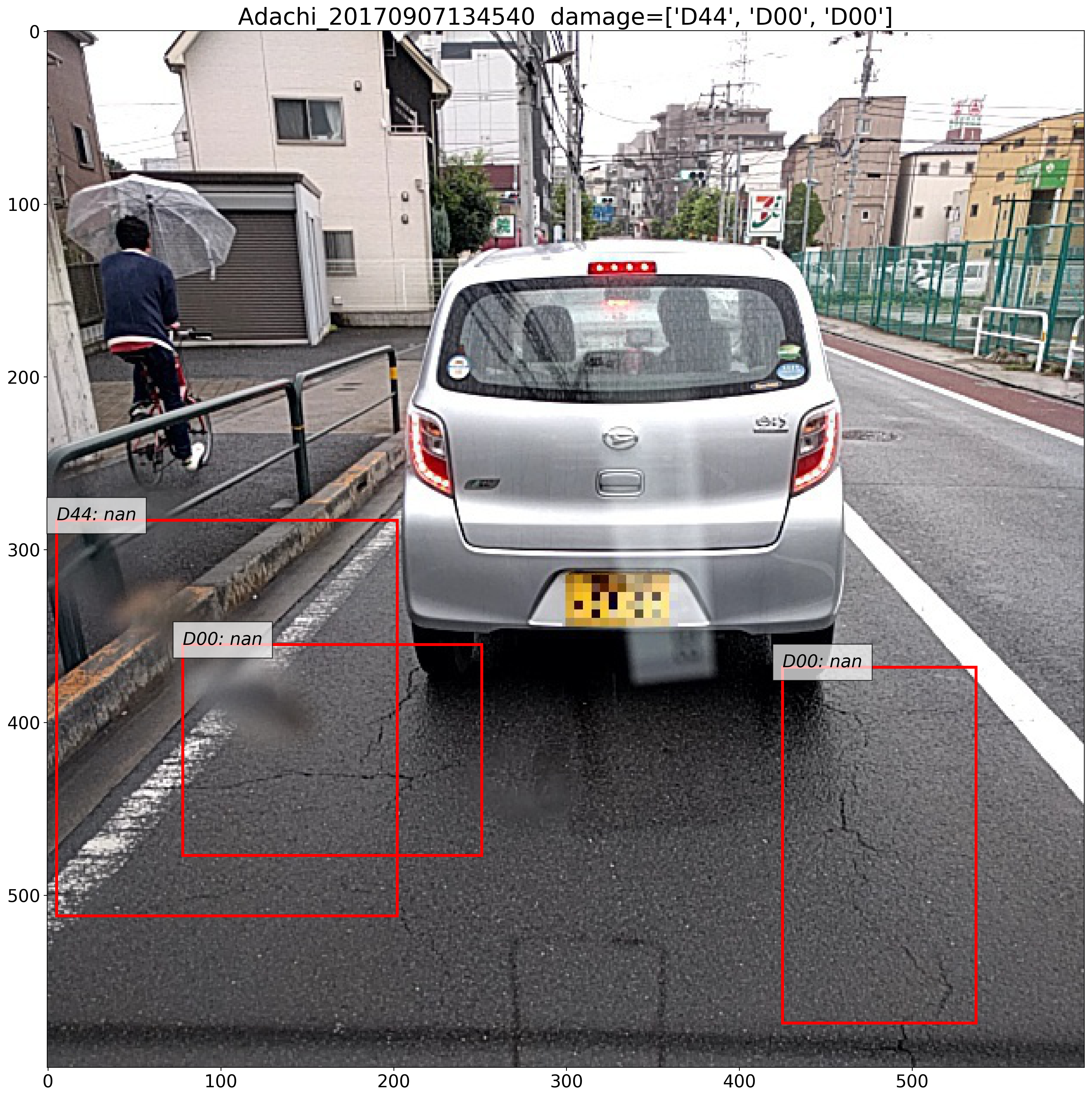

データはtrain用とvalidation用に分けられており,test用のサンプルは含まれていません. 今回はtrain用のサンプルで学習を行い,学習中にvalidation用データセットで評価を行いました.
SSD
今回は,非常に高速な物体検出のモデルとして知られているSSD (Single Shot Multibox Detector)をベースとして損傷の検出を行いました.
仕組みはざっくり言うと,CNN(VGG16など)に画像を入力して得られた特徴マップを,物体を検出するためのネットワーク(Multibox)に入力して物体を検出しています(図2).
また,物体のクラスを推定するためのネットワークを用意することで,物体のラベルも同時に推定しています.
CNNから得られる特徴マップのサイズはさまざまなので,多様なサイズの物体を画像から検出することができるようになっています.
 図2 SSDのアーキテクチャ
図2 SSDのアーキテクチャ
SSD(VGG16)での損傷検出
SSDの実装はChainerCVのものを用いました.
ChainerCVのSSDは特徴マップ抽出用のCNNとしてVGG16を改良したものを用いています.
詰まった箇所
RoadDamageDatasetには損傷が全く写りこんでいない(bounding boxが含まれていない)データサンプルがいくつか含まれていました.
一方でChainerCVのSSDのサンプルコードはこういったデータサンプルに対応できていなかったため,損傷が写りこんでいないサンプルに対して場合分けを行う必要がありました.
この問題についてChainerCVのリポジトリにissueを建てたところ,すでにより低いレイヤで対応中との返答をいただきました.
学習
設定
最適化手法などはChainerCVのサンプルのものをそのまま適用しました(表2).
表2 最適化手法とハイパーパラメータ
| label | configuration |
|---|---|
| architecture | SSD300 (based on VGG16) |
| iteration | 120000 |
| optimizer | MomentumSGD |
| batchsize | 32 |
learning rate
初期値は5e-04としました.ExponentialShiftにより80000 iterationと100000 iterationにおいて学習レートが変化します(表3).
表3 Learning rateの変化
| iteration | learning rate |
|---|---|
| 0~ | 5e-04 |
| 80000~ | 5e-05 |
| 100000~ | 5e-06 |
結果
図3に学習の経過を示します.
図上部が位置誤差(location loss)とクラス分類誤差(confidence loss),そしてその合計(overall)を表しています.
図下部はvalidationデータサンプルに対するクラスごとのAverage Precision (AP)と,全クラスに対するmean Average Precision (mAP)です.
 図3 SSD(VGG16)での学習経過
図3 SSD(VGG16)での学習経過
Exponential shiftによりlearning rateが小さくなった点(80000 iteration)において,lossが一気に下がっているのがわかります.100000 iteration以降は精度も飽和しています.
最終的なmAPは0.561を記録しました.
デフォルトのパラメータで学習した割には安定して精度が出たので,これをベースラインとしてアーキテクチャを変更し,性能向上を目指しました.
改良方法
今回扱った物体検出モデルの改良の方向性は主に3つあります.
- 検出精度の向上
- 検出速度の向上
- モデルサイズの削減
モデルサイズの削減についてはとりあえず後回しでもよさそうだったので,まずは検出精度と検出速度の向上を目指しました.
速度と精度のトレードオフ
物体検出においてはあまり検出速度を上げようとすると検出精度が下がってしまい,検出精度を上げようとすると検出速度が下がってしまう傾向があります.
アーキテクチャによって検出速度と精度にどのような傾向が現れるのかを調査した論文が Huang, Jonathan, et al. (2017) です.
この中にCOCOデータセットに対する実行速度と検出精度のトレードオフを示した図があります(図4).
 図4 実行速度と精度のトレードオフ (Huang, Jonathan, et al. (2017))
図4 実行速度と精度のトレードオフ (Huang, Jonathan, et al. (2017))
図4に示されているのはGPUにおける実行時間なので実際に動かす環境での速度とは違いますが,参考にはなるでしょう.
今回は実装期間の都合上アーキテクチャをSSDに限っていますが,いずれにしてもResNet-101を特徴抽出器として採用すると,高速かつほどほど高精度に検出が行えそうだということがわかりました.
ResNet-101は層がかなり多いので,実行速度が速いという結果が出ていることは意外でした.
ResNet-101への置き換え
特徴マップ抽出用CNNをVGG16からResNet-101に置き換えます.
この特徴マップは物体の位置とそのクラスを推定するのに十分な情報を持っている必要があるため,ResNet-101にimagenetの重みを適用しました.
物体検出を行うためには,ResNet-101からサイズの違う特徴マップを複数取り出してきて,検出用のネットワーク(Multibox)に渡す必要があります.
ResNet-101にはbuilding blockという大きなネットワークのかたまりが4つ含まれているので,それぞれのブロックの最終層から特徴マップを取り出してMultiboxに入力しました.
また,ResNetは画像を入力する前に専用の正規化を行う必要があるため,これを適用しています.
ChainerCVの設計
ChainerCVのSSDは非常に良く出来ていて,特徴抽出器をさっと取り外して別のものに簡単に付け替えられるようになっています.このおかげでアーキテクチャ改変の工数を抑え,ハイパーパラメータチューニングに専念することができました.
学習
最適化におけるハイパーパラメータは,learning rateを3e-4に変更した点(表4)以外はVGG16のときと全く同じです.
一方で特徴マップ抽出用のCNNを付け替えたため,default box(認識時に物体が写り込んでいるかどうかを判断する基準となる区画)に関するハイパーパラメータは調整し直す必要がありました.
表4 Learning rateの変化
| iteration | learning rate |
|---|---|
| 0~ | 3e-04 |
| 80000~ | 3e-05 |
| 100000~ | 3e-06 |
結果
いくらハイパーパラメータを調整しても精度が上がらず,おかしいと思ってデータを見なおしてみたところ,精度の出ないクラスはデータ数が少なすぎることに気が付きました(図4).
 図4 クラスごとのデータ数
図4 クラスごとのデータ数
実はクラスごとのデータ数や精度はRoadDamageDetectorの論文に記載されており,さらにD43がデータ数に対して高い精度が出ていることについても考察されているのですが,これはだいぶ後になってから気が付きました.
図5にSSD(ResNet-101)における学習の経過を示します.
 図5 SSD(ResNet-101)での学習の経過
図5 SSD(ResNet-101)での学習の経過
最終的な精度は残念ながらVGG16を上回ることはできませんでした.モデルの大きさに対して明らかにデータが少なすぎました.
なお,最終的なmAPは0.379でした.
速度比較
ResNet-101とVGG16のそれぞれをベースとしたSSDについて,実行時間の比較を行いました.
入力画像のサイズは全て600x600とし,SSD.predictionの実行時間を計測しました.実行環境は表5のとおりです.
表5 実行環境
| label | value |
|---|---|
| CPU | Intel Core i7-6700 CPU @ 3.40GHz |
| Memory size | 64GB |
| GPU | TITAN X (Pascal) |
| GPU memory size | 12GB |
| GPU driver version | NVIDIA 390.25 |
| OS | x86_64 GNU/Linux |
| CUDA version | 9.0 |
| cuDNN version | 7 |
入力サイズについて
なおSSDのネットワークの入力サイズはSSD(VGG16)の場合300x300,SSD(ResNet-101)の場合224x224となっており,入力画像のサイズと異なっています.このため,
- 推論時に画像のリサイズの処理が入ってしまい,SSDそのものの実行時間とは異なる
- 入力サイズがVGG16とResNet-101で異なるため,フェアな速度比較になっていない
という問題点がありますが,
- 画像のリサイズの処理はChainerCV本体のレイヤーの低い部分で行われている (SSD本体との結合性が高い)
- 実際に利用する際にはSSDの入力サイズより大きなサイズの画像が入力され,リサイズも実行時に行われる
という点から,今回は入力画像のサイズはSSD(VGG16)とSSD(ResNet-101)で共通としました.
計測内容
画像数を10枚から50枚の間を10枚ごとに変化させ,それらに対して推論を行いました.
GPUにおける推論ではこれを100回,CPUにおける推論では10回繰り返したときの実行時間を表示しています.
GPU
GPUにおける実行時間を比較しました.結果を図6に示します.
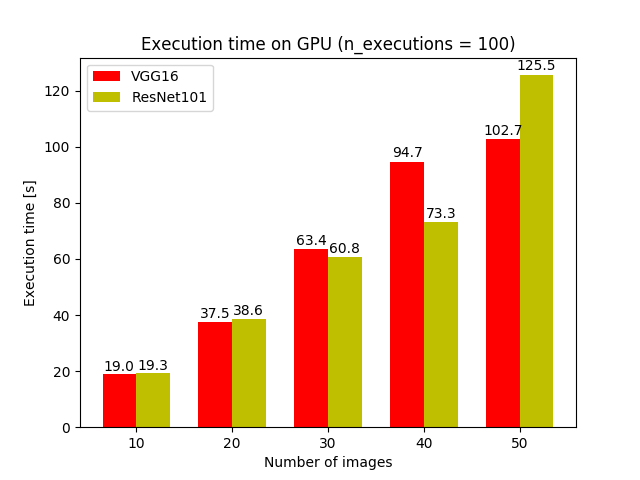
複数枚の画像に対する推論を100回繰り返すのにかかった時間を表示している
画像の枚数によってVGG16のほうが速かったりResNet-101のほうが速かったりしており,今回の実験では決定的な差は見られませんでした.
30枚に対する推論を100回繰り返すのに60秒ほどかかっているので,だいたい50FPSほどの速度が出ています.
CPU
CPUにおける実行時間を比較しました.結果を図7に示します.
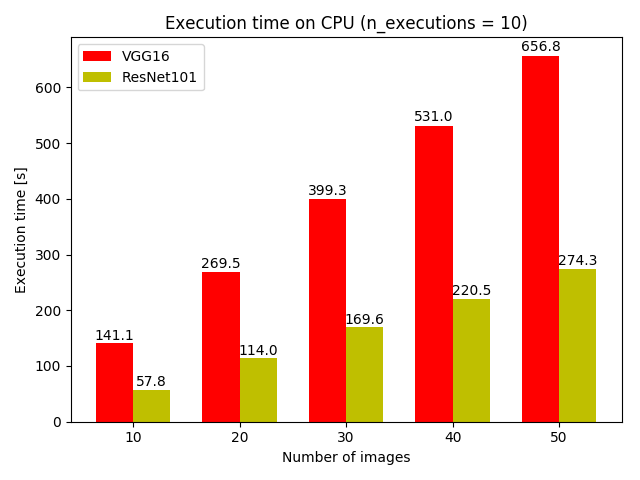
複数枚の画像に対する推論を10回繰り返すのにかかった時間を表示している
CPUではResNet-101のほうが圧倒的に高速でした.VGG16では0.75FPS,ResNet-101では1.8FPSほど出ています. モバイルなどではGPUの利用にある程度制約があるでしょうし,CUDAなどがインストールできるものはかなり限られてくると考えられるので,CPUでResNet-101のほうが圧倒的に高速であるという実験結果には大きな価値があります.
まとめ
データが少なすぎてResNet-101ではあまり精度が出ませんでしたが,データが十分にあればモバイルでも高速かつ高精度に動く物体認識モデルを作れるだろうということがわかりました.
得られたこと
- どんなに優れたモデルであっても,データの量と質が十分に確保されていなければうまくいかない.結局はデータが大事
- Deep Learningは学習時間が長いので,今まで以上にモデル選択の重要性が高くなっている.Deep Learningの普及と発展により特徴量選択の必要性は薄れてきているが,一方でデータの量や質,傾向をよく見てからモデルを選ぶことが今まで以上に重要になっていると感じた
- ベースラインでの結果が出た時点で,データとモデルの性能の関連をよく調べておくべきだった
- ResNet-101は層の数が多いにもかかわらず実行速度がかなり速い
- ChainerとChainerCVの設計は素晴らしいのでいろいろな場面で参考になりそう
謝辞
アドバイスやサポートをしていただいた株式会社パソナテックの夏谷実様に感謝いたします.
-
Maeda, Hiroya, et al. "Road Damage Detection Using Deep Neural Networks with Images Captured Through a Smartphone." arXiv preprint arXiv:1801.09454 (2018). ↩