先日 Elastic Stack 8.0 の NLP で日本語センチメント分析を試してみた を書いたところ、「これ、ちゃんと日本語で処理できるのかな?中の動きが知りたい」とコメントいただきました。確かに、モデル側では fugashi などを使っているのに Elasticsearch 側では使ってないはずですね。
今回は Elastic Stack 8.0.1 を使って、 inference で判定させるテキストをどうやって tokenize しているかを調査してみました。
勿体ぶらずにまずは結論から。
結論: Elastic Stack 8.0.1 時点では、日本語は Unigram で扱われている
全体の処理の流れを Tokenizer を中心に整理してみました。
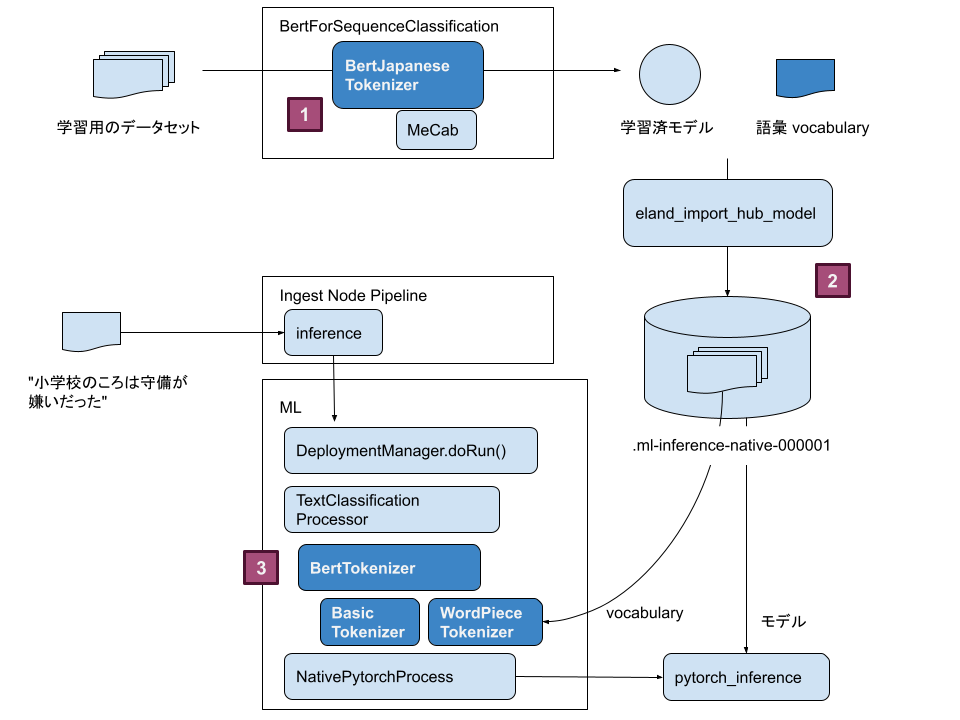
- 学習フェーズ 事前に学習する部分。 BertForSequenceClassification というアーキテクチャの一部で、入力文字列を機械学習で扱うために変換する Transformer 。学習の成果物として モデル と ボキャブラリ ができます。
- Eland を使って学習済みのモデルとボキャブラリを Hugging Face から Elasticsearch インデックスにインポートします。
- 判定フェーズ こちらが今回のテーマ、 Elastic Stack で分析対象の文字列をトークン分割している箇所です。分割した文字列とモデル ID を指定してネイティブな Pytorch プロセスを実行します。
学習フェーズと判定フェーズでどのようにトークン分割しているかみてみましょう。
学習フェーズ
日本語を扱う場合、 BertJapaneseTokenizer があり、Hugging Face の一部として利用可能です。これは、2019年12月、東北大学乾研究室からの成果。素晴らしいですね!
形態素解析の MeCab を利用していて、意味のある単語レベルで分割して学習を行うことができます。
例: "小学校のころは守備が嫌いだった"
=> "小学校", "ころ", "守備", "嫌い"
(注: あくまでイメージです)
学習の成果物として作成される vocabulary には 32,000 の語彙リストがあります。これで各語彙を数値に変換し、文章をベクトルとして扱えるものと思われます。
判定フェーズ
判定フェーズは Elastic Stack 側で実行される訳ですが、入力文字列を同じようにトークンに分割する必要があります。ver 8.0.1 時点では BertTokenizer しかありません。
BertTokenizer はまず BasicTokenizer で入力文字列を粗く分割したうえで、 WordPieceTokenizer で vocabulary の語彙でさらに分割します。
Vocabulary には 32,000 の語彙がある訳ですが、前編で利用したモデルでは次のような語彙がありました:
"[PAD]",
"[UNK]",
"[CLS]",
"[SEP]",
"[MASK]",
"の",
"、",
"に",
"。",
"は",
…(中略)
"##起こ",
"守備",
"小学",
"ころ",
"テン",
"イラスト",
"##if",
"規則",
"ページ",
"オル",
"上昇",
"境界",
"[",
"吸収",
"略称",
"##天皇",
"有力",
"##ながら",
"尽",
"滑",
"コレ",
"護衛",
"##ソード",
"チャート",
(など)
BasicTokenizer で分割されたトークンは、WordPieceTokenizer により、このリストとぶつけられて、語彙があればトークンの ID が付与され、なければ "[UNK]" (Unknown) となります。
WordPieceTokenizer ではすでにトークンに分割されていることが前提なので、重要なのはその前処理にあたる BasicTokenizer です。
BasicTokenizer の実装
BesicTokenizer は単純に入力文字をスペースや区切り文字で分割します。日本語はどう扱うかというと、 Unigram に分割 します。
例: "小学校のころは守備が嫌いだった"
=> "小", "学", "校", "の", "こ", "ろ", "は", "守", "備", "が", "嫌", "い", "だ", "っ", "た"
BertTokenizer のテスト
BasicTokenizer と WordPieceTokenizer の動きを踏まえて、簡単な BertTokenizer のテストを実行してみました。
public void testJapaneseTokens() {
BertTokenizer tokenizer = BertTokenizer.builder(List.of(
"[UNK]",
"[CLS]",
"[SEP]",
"[MASK]",
"守備",
"守",
"小学生"
), Tokenization.createDefault())
.setDoLowerCase(false)
.setWithSpecialTokens(true)
// これは今のところ API ではオンオフできない
.setDoTokenizeCjKChars(true)
.build();
TokenizationResult.Tokenization result = tokenizer.tokenize("小学校のころは守備が嫌いだった");
String[] tokens = result.getTokens();
System.out.println(List.of(tokens));
}
結果は次の通りです。 Vocabulary のリストには 守備 や 小学生 といった語彙がありますが、 BasicTokenizer では日本語を一文字に分割してしまうので、 守 しか残りません。
[[CLS], [UNK], [UNK], [UNK], [UNK], 守, [UNK], [UNK], [UNK], [UNK], [SEP]]
日本語でも使えると言えるのか?
前編の記事では二つの文章を判定させていました:
- "あちきの ML ノードは非力すぎ" 94% ネガティブ
- "Elastic Stack 8.0 で格段に NLP が簡単になった!" 91% ポジティブ
あくまで状況証拠による仮説ですが、利用したモデルの vocabulary には "非" や "力"、"簡" や "単" といった一文字が存在しました。このため、ある程度の精度でモデルを利用できていると思われます。
単純に Unigram としての判定ではなく、意味のあるトークンで判定できた方が精度は高まるでしょう。
今後の Tokenizer の動向に期待!
今回調査したのは ver 8.0.1 でした。 rg.elasticsearch.xpack.ml.inference.nlp.tokenizers パッケージはこんな感じです。

本日時点 (2022-03-04) の master ブランチを見ると:
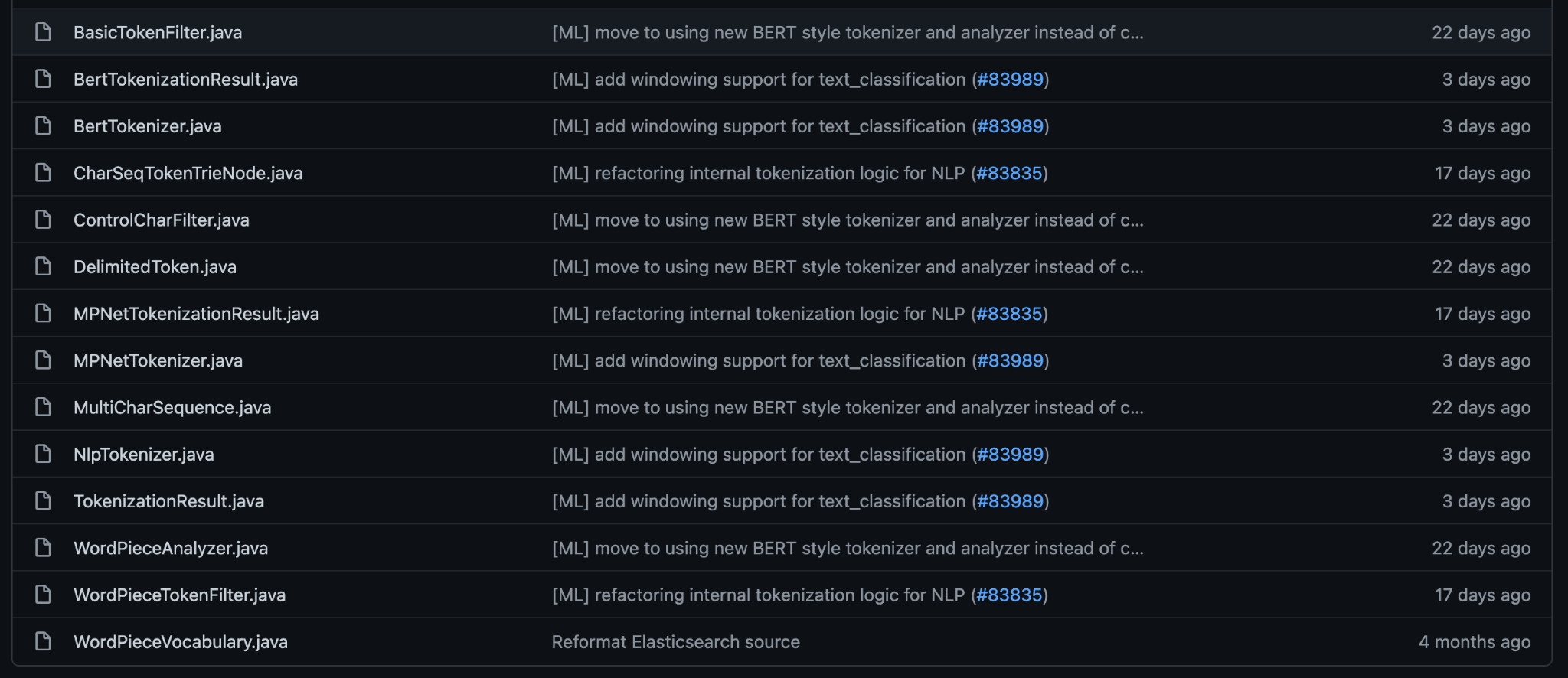
充実してきていますね。コミットの履歴を見ると、 Tokenizer の実装を Lucene のに切り替えていこう という動きも見られます。今は限定的ですが、今後 Kuromoji や Sudachi なども inference の流れの Tokenizer で使えるようになると良いですね!
どうやってモデル実行しているの?
Elasticsearch は Java で実装されている訳ですが、モデルを使って inference を実施するのは別のネイティブプロセスが動いています。冒頭に登場したフロー図の pytorch_inference がそれで、 CPP で実装されています。 pytorch_inference の入出力はこちらのテストプログラムがイメージしやすかったです。
{
"source_text": "The movie was awesome!!",
"input": {
"request_id": "two",
"tokens": [[101, 1996, 3185, 2001, 12476, 999, 999, 102]],
"arg_1": [[1, 1, 1, 1, 1, 1, 1, 1]]
},
"expected_output": {"request_id": "two", "inference": [[[-4.2720, 4.6515]]]}
}
source_text を input の tokens に変換するのを、本記事で紹介した BertTokenizer で Java 側で実施してから pytorch_inference に渡しているようです。
まとめ
今回は前編のブログ記事を見てくれた方からの質問に背中を押され、色々とソースコードを見たりして得られるものが多かったです。関連するソースコードへのリンクも要所要所で貼ったので、ご興味がある方はぜひ Elasticsearch のソースコードも見てみてください :)