やっと 8.0 を触れる時間と気力が整ったので、 8.0 目玉機能の外部モデルを利用した NLP で日本語のセンチメント分析を試してみました。
公式ドキュメントの Natural Language Processing に記載されている手順に従って進めました。
大まかな手順:
- eland をインストールして
eland_import_hub_modelコマンドを使えるようにする -
eland_import_hub_modelで Hugging Face からモデルを Elasticsearch にインポートする - モデルを使って文章を分析する
まず公式ドキュメントの手順で試して、その後に日本語のセンチメント分析を行うモデルを試してみました。
詳細をメモしておきます。
eland をインストールする
私の環境では以前に古いバージョンの eland ver 7.14.1b1 をインストールしていたみたいで (全く記憶にない。。。) upgrade オプションを付けて pip を実行する必要がありました。
python3 -m pip install --upgrade eland
urllib3 のバージョン互換性がおかしいで、というエラーが出たので、メッセージに従い、関連モジュールもアップグレードしました。
python3 -m pip install --upgrade requests
python3 -m pip install --upgrade urllib3
これで、 eland_import_hub_model が使えるようになるはず。しかし、実行すると必要なモジュールがいくつか足りない模様です。こちらもエラーメッセージに従い、必要なモジュールをインストールしました。きっと BERT とかすでに試している方はもうインストール済みなんだろうな、とか思いつつ。。
python3 -m pip install tqdm
python3 -m pip install torch
python3 -m pip install transformers
python3 -m pip install sentence_transformers
eland_import_hub_model を実行してエラーなく usage が出力されればインストール完了でしょう。
eland_import_hub_model
usage: upload_hub_model [-h] --url URL --hub-model-id HUB_MODEL_ID [--elasticsearch-model-id ELASTICSEARCH_MODEL_ID] --task-type
{text_classification,fill_mask,text_embedding,ner,zero_shot_classification} [--quantize] [--start]
[--clear-previous]
upload_hub_model: error: the following arguments are required: --url, --hub-model-id, --task-type
Hugging Face からモデルを Elasticsearch にインポートする
今回はクラウドの Elasticsearch Service を使いました。ちなみに 7.16.2 -> 7.17.0 -> 8.0 とアップグレード無事完了しました。
まずは公式ドキュメントに記載のサンプルを試します。クラウドの管理画面から Elasticsearch のエンドポイントをコピーして、以下のように Elastic が Hugging Face で公開している事前学習済みのモデルをインポートします:
eland_import_hub_model --url https://elastic:password@xxxx.cloud.es.io:9243 --hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english --task-type ner --start
ML ノードの RAM 容量に注意しましょう
モデルのインポート自体は成功しましたが、モデルを --start する際にエラーが出ました:
elasticsearch.ApiError: ApiError(429, 'status_exception', 'Could not start deployment because no ML nodes with sufficient capacity were found')
Kibana ではインポートされたモデルが表示されていたので、 Kibana からも start を試してみると、より詳細なエラーメッセージが確認できました:
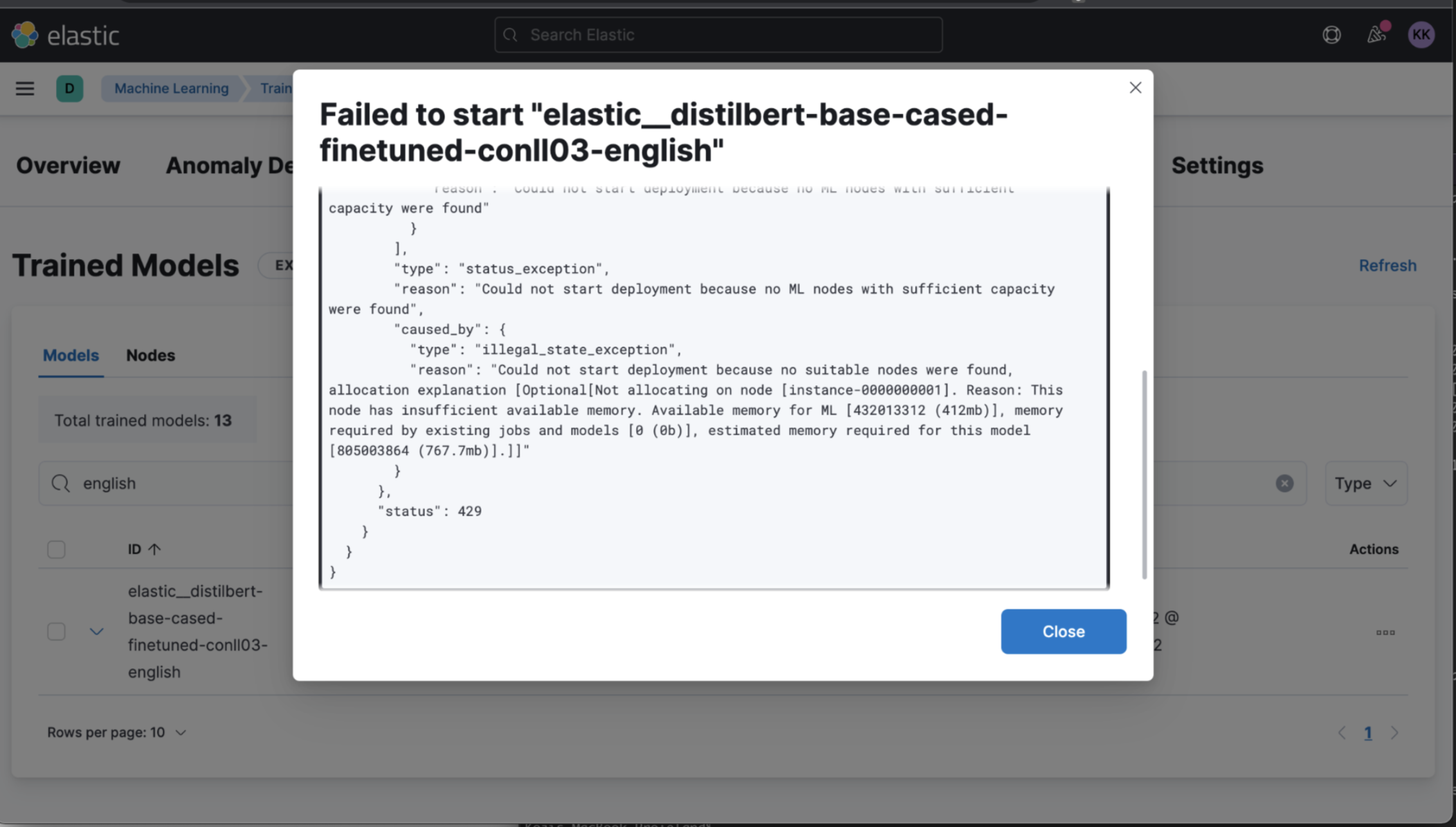
Could not start deployment because no suitable nodes were found, allocation explanation [Optional[Not allocating on node [instance-0000000001]. Reason: This node has insufficient available memory. Available memory for ML [432013312 (412mb)], memory required by existing jobs and models [0 (0b)], estimated memory required for this model [805003864 (767.7mb)].]]
とあります。私のクラウドのデプロイメントでは ML ノードの RAM は 1GB しかありませんでした。 xpack.ml.max_machine_memory_percent というクラスタ設定、デフォルトで 30% なので、このモデルをデプロイするには足りないようですね。
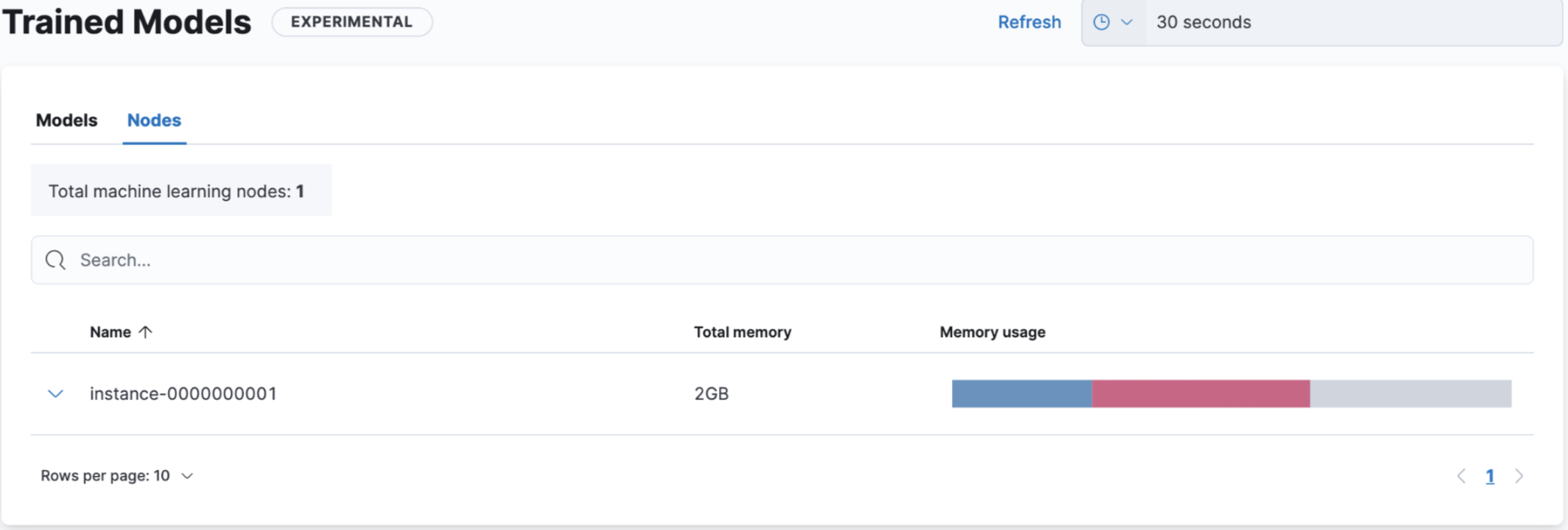
ML ノードの RAM を 2GB に変更しました。
Kibana の Trained Models の Nodes タブでは、 ML ノードの RAM 利用状況が確認できます。
モデルを使って文章を分析する
モデルがインポート、スタートできたら、モデルを使った分析が可能です。公式ドキュメントのサンプルは NER (Named Entity Recognition) という固有名詞を抽出するタスクです。
以下の API を使って簡単に試すことができます。
POST /_ml/trained_models/elastic__distilbert-base-cased-finetuned-conll03-english/deployment/_infer
{
"docs": {
"text_field": "Sasha bought 300 shares of Acme Corp in 2022."
}
}
実行結果:
{
"predicted_value" : "[Sasha](PER&Sasha) bought 300 shares of [Acme Corp](ORG&Acme+Corp) in 2022.",
"entities" : [
{
"entity" : "Sasha",
"class_name" : "PER",
"class_probability" : 0.9953193611298665,
"start_pos" : 0,
"end_pos" : 5
},
{
"entity" : "Acme Corp",
"class_name" : "ORG",
"class_probability" : 0.9996392201598554,
"start_pos" : 27,
"end_pos" : 36
}
]
}
Ingest pipeline から実行する
実際のシステムで利用する場合にはドキュメントを保存する時に Ingest pipeline を使って、分析結果をドキュメントに付け加えます。 inference プロセッサを使います。
パイプラインを作成する前に _simulate エンドポイントを使ってテストすると良いですね。
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english"
}
}
]
},
"docs": [
{
"_source": {
"text_field": "Sasha bought 300 shares of Acme Corp in 2022."
}
}
]
}
正しく実行できたら、正式に Ingest node pipeline として登録します。
PUT _ingest/pipeline/ner-english
{
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english"
}
}
]
}
ドキュメント保存時に作成したパイプラインを指定してみましょう。
PUT nlp-test/_doc/1?pipeline=ner-english
{
"text_field": "Sasha bought 300 shares of Acme Corp in 2022."
}
保存されたドキュメントを確認すると、次のようになっています:
GET nlp-test/_doc/1
レスポンスの _source 部分のみ記載:
{
"text_field" : "Sasha bought 300 shares of Acme Corp in 2022.",
"ml" : {
"inference" : {
"predicted_value" : "[Sasha](PER&Sasha) bought 300 shares of [Acme Corp](ORG&Acme+Corp) in 2022.",
"entities" : [
{
"entity" : "Sasha",
"class_name" : "PER",
"class_probability" : 0.9953193611298665,
"start_pos" : 0,
"end_pos" : 5
},
{
"entity" : "Acme Corp",
"class_name" : "ORG",
"class_probability" : 0.9996392201598554,
"start_pos" : 27,
"end_pos" : 36
}
],
"model_id" : "elastic__distilbert-base-cased-finetuned-conll03-english"
}
}
}
ちゃんと動きました!では、続いて、日本語のモデルも試してみます。
日本語のセンチメント分析を試す
Hugging Face では ja の言語タグや、 Text Classification といったタスクの種類でモデルを検索できます。日本語のテキスト分類タスクで探してみると daigo/bert-base-japanese-sentiment というモデルがありました。作者の方の情報はほぼ記載されていなかったのでお礼のコメントなどは伝えられていないのですが、心の中で「ありがとう!」と叫びながら like させていただきました。
eland_import_hub_model コマンドでモデルをインポートします。
eland_import_hub_model --url https://elastic:password@xxxx.cloud.es.io:9243 --hub-model-id daigo/bert-base-japanese-sentiment --task-type text_classification
エラーが出たので落ち着いて必要なモジュールをインストールし、再びインポートを実行します。ipadic は 2007年から更新が止まっているので、 Github のプロジェクトには "You Shouldn't Use This" と大きく記載があります。代わりに UniDic を使ってね、と書いてあります。今回はお試しなので ipadic で進めます。
python3 -m pip install fugashi
python3 -m pip install ipadic
私の非力な 2GB ML ノードでは最初に試した NER モデルと同時にデプロイは危険なので、 Kibana から NER のモデルは停止して、から bert-base-japanese-sentiment モデルをスタートしました。
しかし、モデルが Starting のまま止まってしまい、ログにエラーが出ていたので結局 RAM を 4GB まで上げて対応しました。
早速試してみましょう!
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"inference": {
"model_id": "daigo__bert-base-japanese-sentiment"
}
}
]
},
"docs": [
{
"_source": {
"text_field": "あちきの ML ノードは非力すぎ"
}
},
{
"_source": {
"text_field": "Elastic Stack 8.0 で格段に NLP が簡単になった!"
}
}
]
}
結果はこのようになりました:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_id" : "_id",
"_source" : {
"text_field" : "あちきの ML ノードは非力すぎ",
"ml" : {
"inference" : {
"model_id" : "daigo__bert-base-japanese-sentiment",
"prediction_probability" : 0.9478574249832916,
"predicted_value" : "ネガティブ"
}
}
},
"_ingest" : {
"timestamp" : "2022-02-23T09:47:07.206830982Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_id" : "_id",
"_source" : {
"text_field" : "Elastic Stack 8.0 で格段に NLP が簡単になった!",
"ml" : {
"inference" : {
"model_id" : "daigo__bert-base-japanese-sentiment",
"prediction_probability" : 0.9141719328662291,
"predicted_value" : "ポジティブ"
}
}
},
"_ingest" : {
"timestamp" : "2022-02-23T09:47:07.206835532Z"
}
}
}
]
}
まとめ
Elastic Stack 8.0 から Hugging Face で公開されている外部モデルを利用した NLP が非常に簡単に実行できるようになりました。私自身機械学習は SVM や Naive Bayes とか KNN とかを数年前にかじりましたが、 Deep Learning や BERT はなかなか重い腰を上げられず触れる機会がなかったので、今回非常にお手軽に試すことができて一気に現代人になった気がしました。学習済みのモデルが公開されていて、再利用できるというのは素晴らしいですね。
2022-03-04 追記: この記事では調査しきれなかった Tokenizer 部分を後編に書きました。