PFRLでスーパーマリオ1-1をクリアするまでの続きです。
前回はエージェントをスーパーマリオブラザーズ1-1をクリアできるところまで学習させることができました。クリアはできるようになったものの、エージェントが画面のどこに注目してプレイしているのかを可視化したくなったのでGrad-CAMによる可視化を試しました。
Grad-CAM

Grad-CAM(論文:Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization)はニューラルネットワークの判断根拠の可視化に用いられる手法です。出力に対する寄与の大きな領域が画像中のどこであるかを示してくれます。
Grad-CAMの具体的な内容については下記の記事が詳しいです。他にも良い記事はあったのですが、PyTorchでGrad-CAMを用いたい場合の実装例まで書かれていて参考になりました。
PyTorchを使ってCNNの判断根拠を可視化するGrad-CAMを実装してみた
Grad-CAMによる可視化
PFRLでスーパーマリオ1-1をクリアするまでに記載したプレイ動画を出力するためのコードを元に改変を行っています。
PyTorchのtorch.nn.Moduleにはforward時やbackward時に動作するhook関数を仕込むことができます。以下のように2つのhook用の関数を用意しておきます。
def forward_hook(module, inputs, outputs):
global feature
feature = outputs[0]
def backward_hook(module, grad_inputs, grad_outputs):
global feature_grad
feature_grad = grad_outputs[0]
ネットワーク構造は以下のようになっていました。
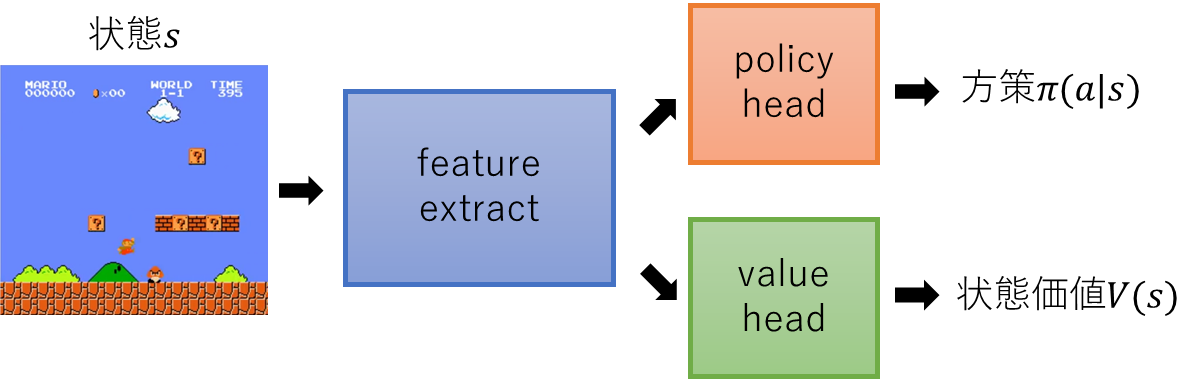
画面から特徴抽出を行うfeature_extractモジュールにhookを設定します。
# forward時に動作するhookを設定する
network.feature_extract.register_forward_hook(forward_hook)
# backward時に動作するhookを設定する
network.feature_extract.register_backward_hook(backward_hook)
状態価値への影響の可視化
Grad-CAMで状態価値の推定値への影響の大きい領域を可視化してみます。このネットワークは状態価値と方策を出力します。下記のコード中ではそれぞれvalueとaction_probとしています。
while True:
image = env.render(mode="rgb_array").copy() # ゲーム画面を取得
state = torch.FloatTensor(state[np.newaxis, :, :, :])
action_prob, value = network.forward(state)
action = action_prob.sample().item()
# Grad-CAMの計算
value.backward() # valueについてのbackward計算
feature_vec = feature_grad.view(HIDDEN_DIM, 240)
alpha = torch.mean(feature_vec, axis=1)
feature = feature.squeeze(0)
L = F.relu(torch.sum(feature*alpha.view(-1, 1, 1), 0))
L = L.detach().numpy()
# Grad-CAMの可視化結果を画面に重ねて表示
L_min = np.min(L)
L_max = np.max(L - L_min)
L = (L - L_min) / (L_max + 1e-8)
L = cv2.resize(L, (256, 240))
image = cv2.resize(image, (256, 240))
heatmap = toHeatmap(L)
heatmap = (255 * heatmap)
alpha = 0.5
image = (image * alpha + heatmap * (1 - alpha)).astype(np.uint8)
frames.append(image)
state, rewards, done, info = env.step(action)
if done:
frames.append(env.render(mode='rgb_array').copy())
break
なんとなくブロックや穴のある位置が赤くなる傾向にあることから、地形についてはある程度見ていそうです。一方でマリオやクリボーといったキャラクター部分はあまり状態価値に影響を与えていなさそうです。
方策への影響の可視化
backwardを方策の側で行えば行動確率への影響が大きい領域が可視化されます。以下では各ステップで実際に選択された行動の選択確率についての影響を可視化してみています。
# value.backward()
action_prob.logits[0][action].backward()