以前はStableBaselinesを使っていましたが、ニューラルネットワークの構造をいじりにくいことやアルゴリズムに手を加えにくいと思っていました。ネットワークにAttentionを加えるだけでも一苦労でした。
そもそもTensorFlow向けであった点も使いづらかったので、PyTorch向けの深層強化学習ライブラリを探していたところPFRLというライブラリを見つけました。
Hello World代わりにスーパーマリオブラザーズ1-1をクリアしてみようと思います。
まずネットワークを定義します。
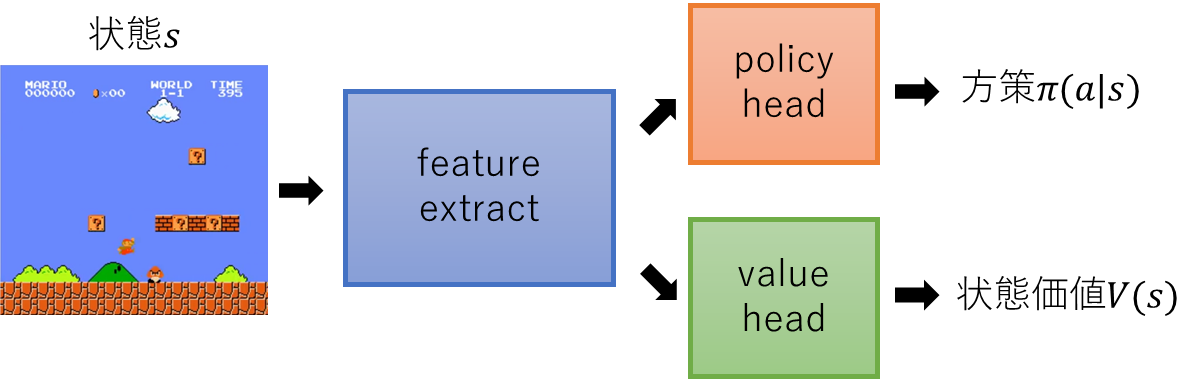
class Network(nn.Module):
def __init__(self, hidden_dim, space_shape, n_actions):
super(Network, self).__init__()
h, w, c = space_shape
self.hidden_dim = hidden_dim
self.feature_extract = nn.Sequential(
nn.Conv2d(c, hidden_dim, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(hidden_dim, hidden_dim, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(hidden_dim, hidden_dim, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(hidden_dim, hidden_dim, 3, 1, 1),
nn.ReLU()
)
flatten_dim = hidden_dim * (h // 8) * (w // 8)
self.flatten_dim = flatten_dim
self.head = pfrl.nn.Branched(
nn.Sequential(
nn.Linear(flatten_dim, n_actions),
SoftmaxCategoricalHead()
),
nn.Linear(flatten_dim, 1)
)
def forward(self, image):
b, _, _, _ = image.shape
feature = self.feature_extract(image)
feature = feature.view(b, -1)
actions, values = self.head(feature)
return actions, values
出力用のNNとOptimizerをagents.PPOに渡します。
agentsには様々な強化学習のアルゴリズムが用意されています。
ここではPPO(Proximal Policy Optimization)を使います。
opt = torch.optim.Adam(network.parameters(), lr=3e-4, eps=1e-8)
agent = agents.PPO(
network,
opt,
gamma=0.9,
gpu=0,
update_interval=update_interval,
minibatch_size=32,
epochs=10,
clip_eps=0.2,
clip_eps_vf=None,
standardize_advantages=True,
entropy_coef=0.01,
max_grad_norm=0.5,
)
experimentsにはagentとenvを渡します。
envについてはStable Baselinesのときと同じなので省略します
experiments.train_agent_batch_with_evaluation(
agent=agent,
env=env,
eval_env=env_eval,
steps=TOTAL_STEPS,
eval_n_steps=None,
eval_n_episodes=10,
eval_interval=100000,
outdir=output_dir,
save_best_so_far_agent=True,
)
10000ステップごとに16エピソードをプレイした平均報酬和を以下に示します。
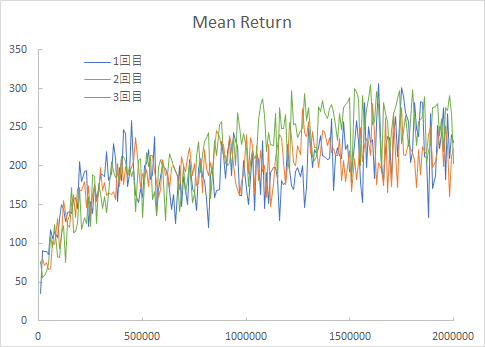
右に進むことができた距離の最大値を更新できた場合に報酬を与えており、報酬和の最大値は316となるようにしています。
2000000ステップでかなり学習できています。
プレイ動画はこんな感じ。
プレイ動画を出力するためのコードを付記しておきます。
from matplotlib import animation
def display_frames_as_movie(frames, fname):
plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0), dpi=72)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames), interval=66)
anim.save(fname, writer='ffmpeg')
env = make_env(ENV_NAME)
actions = env.action_space
n_actions = env.action_space.n
space_shape = env.observation_space.shape
network = Network(HIDDEN_DIM, space_shape, n_actions)
network.load_state_dict(torch.load(f"{model_dir}/5000000_finish/model.pt", map_location=torch.device('cpu'))) # 学習済みのweightを読み込む
frames = [] # 各時点でのゲーム画面を格納しておくためのリスト
state = env.reset()
while True:
image = env.render(mode="rgb_array").copy() # ゲーム画面を取得
state = torch.FloatTensor(state[np.newaxis, :, :, :])
action_prob, value = network.forward(state)
action = action_prob.sample().item()
frames.append(image)
state, rewards, done, info = env.step(action)
if done:
print(info["x_pos"])
frames.append(env.render(mode='rgb_array').copy())
break
display_frames_as_movie(max_frames, output_name)
env.close()