この記事の目的
正月でちょっと時間ができたので、Kaggleを使って自然言語処理で遊んでみた記録です。
自然言語処理をやってみたいけど、ローカル環境やデータの準備はちょっと大変そう、、、という人向けに、参考になれば幸いです。
Kaggleの使い方の参考
ひとまず次を読めば動かせるようになる。
Kaggle にはkernel notebookというものが存在して、ブラウザ上でそこそこの性能のjupyter Notebookを動かすことができる。しかも、機械学習向きのパッケージはだいたい導入済みという非常に助かる作りになっている。
Kaggle関係の記事を見ると、次の順番で既存モデルの改善に取り組むことが効率が良いらしい。
- 先行者の手法の確認
- train dataでのvalidation手法の確立
- データの前処理、水増し
- 特徴量の選定と処理
- 学習と比較
- アンサンブル学習
今回の記事ではこのあたりをざっと取り組む。
今回参加したコンペ
Natural Language Processing with Disaster Tweets
コンペの目的は、災害に関連したツイートを学習して、ツイート内容から災害予測がしたい、というもの。
データとして、分類済みのtrainツイート約7000件と提出用のtestツイート約3000件が与えられている。
結果は災害ツイート(target =1)か無関連ツイート(target =0)の2値で提出して、F1スコアを競う。
F1スコアは次のように定義される。二値分類の場合の結果について、陽/陰性(positive/negative)の真/偽(true/false)で4通りの結果が存在する。それぞれの回数を(TP,TN,FP,FN)で表記したとき、F1スコアは次で決まる。
{\rm Accuracy} = \frac{TP+TN}{TP+TN+FP+FN}
\\
{\rm Precision(TPR)} = \frac{TP}{TP+FP}
\\
{\rm Recall(Sencitivity)} = \frac{TP}{TP+FN}
\\
{\rm F_1} = 2\left( ({\rm Recall})^{-1} + ({\rm Precision})^{-1} \right)= \frac{2TP}{2TP+FP+FN}
要は、間違った結果を少なくしつつ、TPの数を増やせばいい。
公式で"quick tutorial"のnotebookがついていて非常に親切。quick tutorialでは以下の処理を行う。
- データの取り込み、確認
- 単語のベクトル化をscikit-learnの
CountVectorizerによって行う。 - scikit-learnのRidge回帰によって文を分類する。
単語のベクトル化とは、機械学習ではそのままの単語は扱えないので、何らかの手法で数値のベクトルにする必要がある。ここでは、one hot方式という単語ごとに1成分ずつ配列を作る方式が使われた。
前処理もなしの単純な手法だが、F1〜0.78とそこそこの値が出ている。
先行手法の理解
先行手法として参考にしたのは、Basic EDA,Cleaning and GloVe(Shahules)というNotebook。
探索的データ解析(EDA)と前処理、それを踏まえたGloVeのpre-trained data setを用いた単語のベクトル化、kerasのLSTM(Long Short Term Memory)を使った学習という、tutorialから一歩踏み込んだ内容になっている。
Notebook自体に解説が丁寧についているので改めてreviewはしないが、以下で簡単に使われている手法を紹介する。
GloVeについて
こちらの記事が参考になります。高速かつ高性能な分散表現Gloveについて(PyTorch実装)
GloVe(Global Vectors for Word Representation)とは単語のベクトル化の手法であり、以下のサイトで学習済みのデータが提供されている。https://nlp.stanford.edu/projects/glove/
自然言語処理では文を構成する単語をベクトルに直す必要がある。"One Hot"という手法では、辞書に登録した単語の数の次元を持つベクトルを作り、各成分が単語に対応する。
もう少し工夫すると、文脈によって単語の意味が変わる効果を取り入れたい。このとき、文脈として前後の単語も取り込む方法がある。単純にやるとN=(単語数)に対してN^2のベクトルが必要になるので次元縮約が必要になる。skip-gramモデルやCBOW(continuous bag-of-words)では、M(<N)の中間層を挟むことで、ニューラルネットの手法で学習を行い、単語のベクトル表現(分散表現)としては入力層-中間層の間の結合N×Mの各ベクトルが単語を表現する。
ベクトルとしての距離を定義できるので、ある単語と類似した別の単語の候補を提示することができる。
特にGloVeは共起行列などの情報を加えて学習を行っており、優秀な表現能力を持つことが知られている。
LSTMによる文章学習
LongShortTermMemoryネットワークモデルとは、主に時系列データを処理する際に使われるニューラルネットの構造のことである。
時系列に限らず、自然言語処理では文中の単語の並びを時系列として取り扱うことで、先の単語の入力予測ができたり、前後の単語の文脈を考慮した翻訳ができるようになる。今回のタスクでも、組み合わさることで意味を持つ単語("wild fire"など)の解析で力を発揮すると期待できる。
validation 手法の確立
Kaggleはコンペティションの形式を取るので、答えを".csv"で提出するとスコアを算出してくれる。ただし、一日の提出上限が5回までなど、制約があるので手元のデータで学習度合いを評価できたほうが望ましい。
kerasなどを使う場合は、学習中のメトリクスとしてmetrics=['accuracy']などを指定することで学習度合いを評価できる。
今回は愚直に、cross validationで学習させたあとに、改めてtrainデータ全体でのF1スコアを計算することで手法を評価した。
データの前処理、水増し、特徴量の選定
ここが今回主に取り組んだ内容になっている。
自然言語処理では、文章を機械で処理できる形に直す仮定でいくつものロスが生じうる。
このロスを以下に減らすかがスコア向上の鍵になる。
主に次の方法を試した。
- punctuationの取り扱い
- 大文字の取り扱い
- その他
前処理の改善: punctuationの改良
punctuationとは、英語での"!"や"?"などの文字である。元々の解析では、punctuationを一括で消去していた。しかし、"!"や"?"などは文意を表す特徴量なのでは?という推測ができる。
そのため、"!","?"を残して解析を行えるようにコードを変更した。
更にツイッターという媒体では予約語も存在するので、以下のように処理を行った。
メンション(@から始まる単語)は会話を意味している。メンション対象は、ユーザー名が入るので災害とは関係ないため、単語ごと除去する。
具体的には、108759単語の中に、2750個のMention、 86個のMention打ち間違えが存在した。
この手のSNSで重要な要素として、いわゆるハッシュタグ(#から始まる単語)が挙げられる。特に災害では、特徴的なタグ付がされていると予想。タグが付いた単語は、特に災害関連の用語が入っていたりするので、"#"のみ除去する。
108759単語の中に、3384個のタグ、 44個のタグ打ち間違えが存在した。
F1スコアは数%良くなった。これは上の単語数の推定からもそれなりに納得できる結果である。
実装方法
def remove_punct(text):
#!,?はスペースを開けて独立に解釈
table = str.maketrans({'!': ' ! ', '?': ' ? '})
text = text.translate(table)
# @を含む単語ごと消す。
for i in text.split():
if "@" in i:
text = text.replace(i, " ")
# 残りの記号はそこだけ削る。
table=str.maketrans('','','"#$%&\'()*+,-./:;<=>[\\]^_`{|}~', )
text = text.translate(table)
return text
前処理の改善: 大文字の取り扱い
元のモデルでは、単語をベクトル化する際に全部小文字に直していた。単語をベクトル化するときに参照するPre-trained dataがそうなっているので仕方ない。
勝手な印象として、英語では強調する内容は大文字になっている気がする。なので、文中に強調された単語が存在する場合は、災害ツイートの可能性が高いのではないかと予想した。
実際、大文字のみで表記された単語は6007/154917個あったので、こちらも1%程度の改善が見込まれる、と予想した。
実装方法としては、大文字で表記された単語が存在する場合、その文の前に強調語 "very"を置くことで意味を強調する。文法としては正しくないが、学習には役立つ可能性がある。
結果として、F1スコアは微減といったところだった。災害以外でも日常的に大文字ツイートしてるのかもしれない。
実装方法
def MoveLargerCase(text):
for i in text.split():
if len(re.findall('[A-Z]', i))> 2 :
text = text.lower()
text = "very "+text
break
return text
その他
GloVeの公式サイトを見ると、ツイッターから学習したpre-trained dataがあったので、そっちを適用して再解析を行う。
元のコードでは、Wikipediaなどを利用したdataだったので、今回の課題に対してはより良い結果を出すと期待できる。
F1スコアは期待通り、良くなった。
また再翻訳や類義語によるデータ水増し、などをやると精度は上がりそう。
再翻訳による水増しなどがあるが今回は採用しなかった。(googletransが更新に伴ってエラー発生中で使用不能だった)
学習と比較
ここまでにtutorialとbasic modelという2つのNotebookでそれぞれ予測を行った。どちらも前処理を改善してから評価してみたところ、次の結果が出た。
| Model | F1(train) | F1(submittion) |
|---|---|---|
| NLP Getting Started Tutorial | 0.993878 | 0.78118 |
| Basic EDA,Cleaning and GloVe by Shahules |
0.77374 | 0.78302 |
tutorialの方は、単純に頻出単語で重み付けをしているため、local dataに過学習していると思われる。ここの改良も必要になる。逆にGloVeを使ったBasicModelの方がそこまでうまく行っていない理由は、単語のベクトル化の仮定で少なくないワードを落としているからだと考えられる。できるだけdataをコーパスに寄せていく前処理が必要となる。
新モデルの開発
以上を踏まえて、自力で簡単な推論モデルの実装を行った。
結局、この手のモデルは、災害を示すワードをどれだけきれいに拾えるかが重要だと考えられる。希少単語について、災害を表す複合語(wildfire,,,)などをきれいに拾える場合に精度が上がる。これをやるなら、ニューラルネットはそこまで重要ではない、と期待できる。
むしろ、災害複合語のコーパス作成が大切になる。大まかな方針は以下の通り。
- train dataから災害関連語、未関連の場合の頻度を比較する。
- 辞書を元に災害語のコーパスを作る。
- 辞書を更に再翻訳やGloVeの関連語を利用して増幅する。
- 辞書に単語が含まれる場合に災害関連として扱う。
- 結果をアンサンブル学習に使う。
実装については冗長なのでここでは割愛。
特に重要な部分として、災害語のコーパスの説明をしたい。train dataから災害関連ツイート、無関連ツイートそれぞれに出てくる単語の頻度を調べる。単語ごとに、(出現数,災害関連)/(出現数,無関連)のような比を調べたのが次の図である。
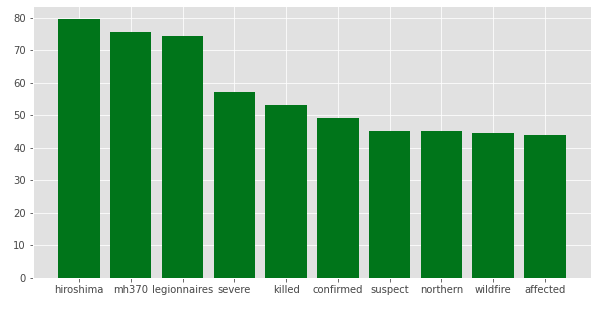
横軸は災害関連語である可能性が大きい順にソートした。物騒な単語が上位に上がっているとわかる。"hiroshima"が上がっている理由は謎。mh370はググってみるとマレーシア航空の事故に関連するらしい…。これを元に、災害との関連性が高い単語のリストを作成する。単語をGloVeのpre-trained dataを使ってベクトル化する。これにより、リストに上がってなくても似たような意味の言葉もサーチできると期待される。
与えられた単語ベクトルを使って、よく使われるfrom sklearn.linear_model import LinearRegressionを使って学習させる。このモデルの選択理由は、計算コストが軽いからである。
以上の結果として得られたF1スコアは期待していたほど高くはなかった。原因としては、pre-trained dataでのベクトル化を行う際に、コーパスに対応していない単語ベクトルが多かったことが挙げられる。単語をよりよく補足するためには、Word correction&未定義語の除去を行うことが考えられる。単純なベクトル化がうまく行っていた理由はこのあたりのハッシュタグなどを拾えていたからかもしれない。
アンサンブル学習
最後に、ここまでで改良した3つのモデルの結果をアンサンブル学習として取り込んで見る。適当に重みを付けて結果を組み合わせることで、最終的なF1スコアはF1=0.796となり、最初の解析からわずかに向上させることができた。
まとめ
Kaggleで自然言語処理というと敷居が高く感じるかもしれないが、たくさん先駆者が記録を残してくれているので案外簡単に取り組むことができた。KaggleのKernel notebookも学習を進める上で十分なスペックがあり、環境を用意しなくてもいい点もフレンドリー。
scoreを更に向上させるためには、Discussionを読んだり、良いスコアを出しているNotebookを参考に他の手法も試すことが必要になる。長くなってきたので、これ以上の改良は別の記事でまとめる。