この記事は alibabacloud Advent Calendar 2019 3 日目のエントリとなります。
昨日は n_watanabe さんでした。
そして、以下の記事の続きでもあります。
- Alibaba Cloud の POLARDB を試してみる(1)MySQL 8.0 互換版起動編
- Alibaba Cloud の POLARDB を試してみる(2)MySQL 8.0 互換版のバッファプールまわりを中心に
- Alibaba Cloud の POLARDB を試してみる(3)MySQL 8.0 互換版でパラレルクエリを試す
※(3)は本日の同日エントリです。
Alibaba Cloud の ApsaraDB for POLARDB には MySQL 5.6 / 8.0 互換版のほかに、PostgreSQL 11 互換版もあります(さらに、Oracle 互換版もあります)。
というわけで、こちらも試してみました。
起動してみる
2019/12/01 現在、POLARDB PostgreSQL 互換版は一部の機能がプレビューもしくは未提供となっています。そのため、今後使える機能や設定画面が変更になる可能性が高い点にご注意ください。
以降、MySQL 8.0 互換版と異なる部分を中心にピックアップしていきます。
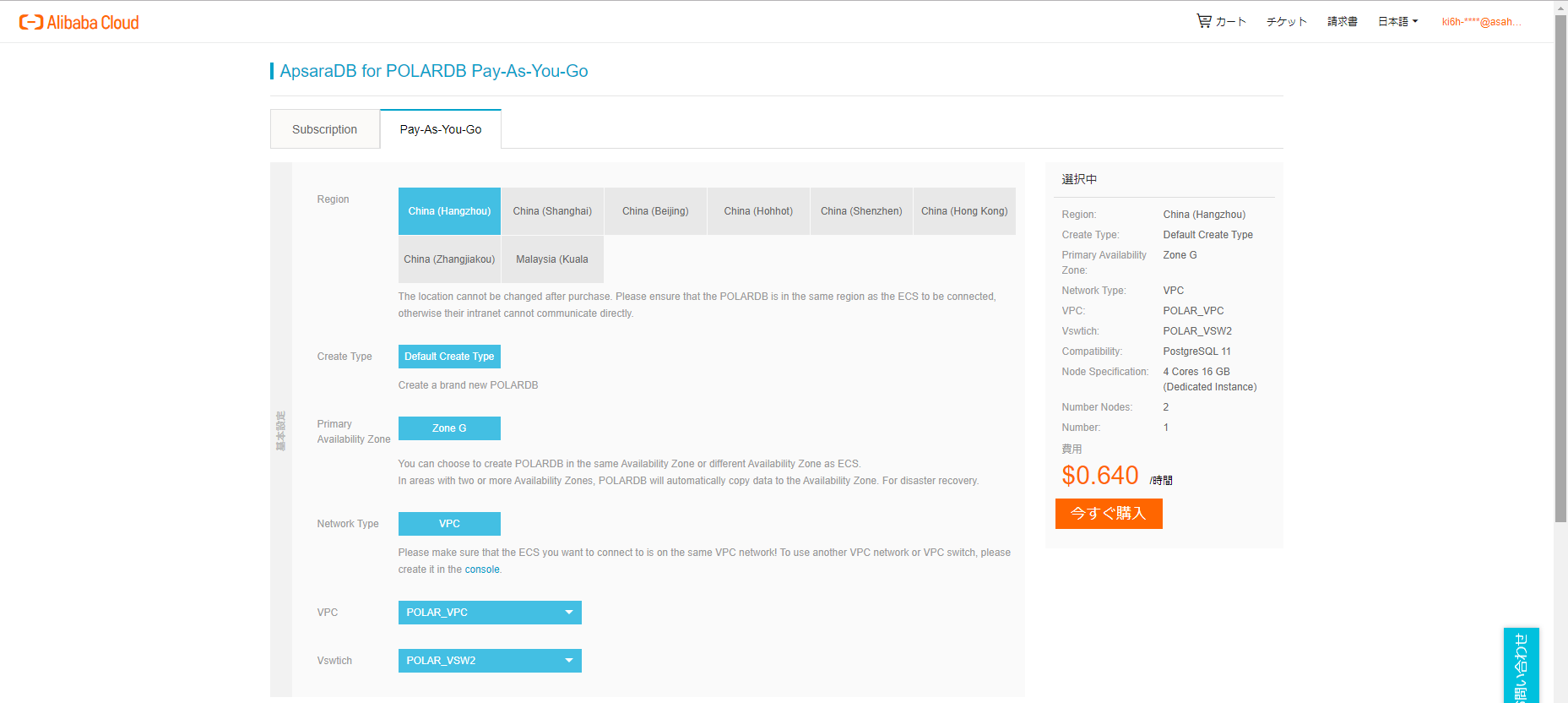
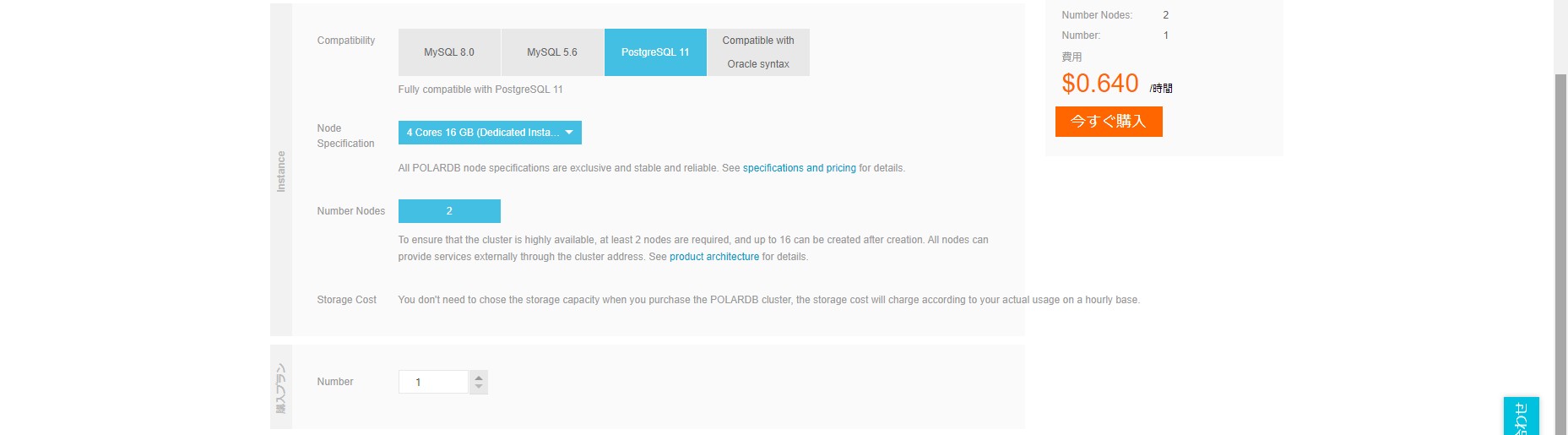
クラスタの作成
MySQL 8.0 互換版と同様、今回も国際版アカウントの杭州リージョンに作成します(日本版アカウントでは使えません)。
MySQL 8.0 互換版とは違い、Zone I が選択できませんので Zone G に作成します。
作成後、エンドポイントを見てみます。
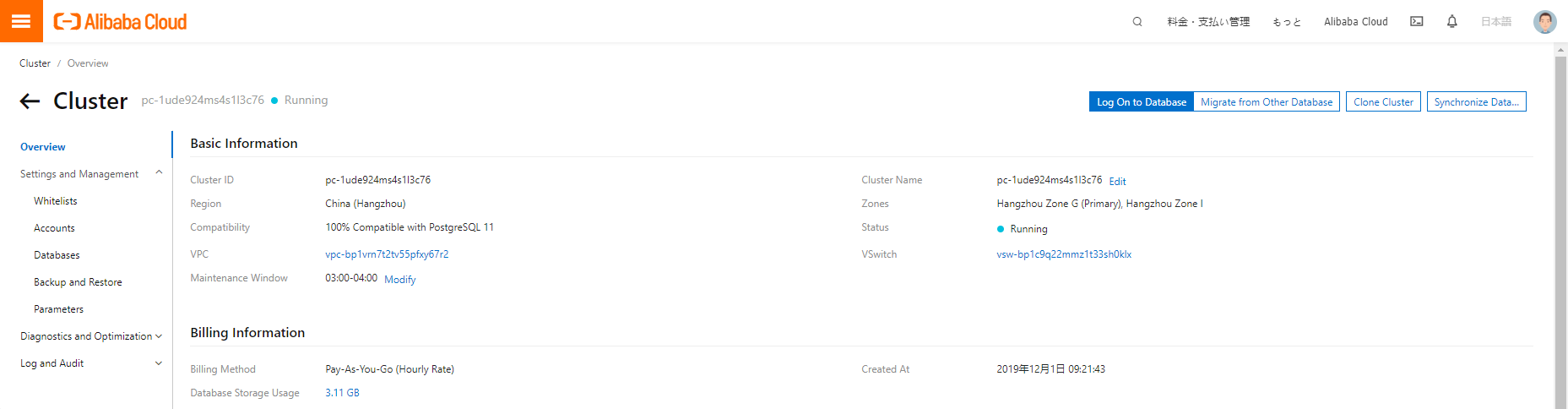
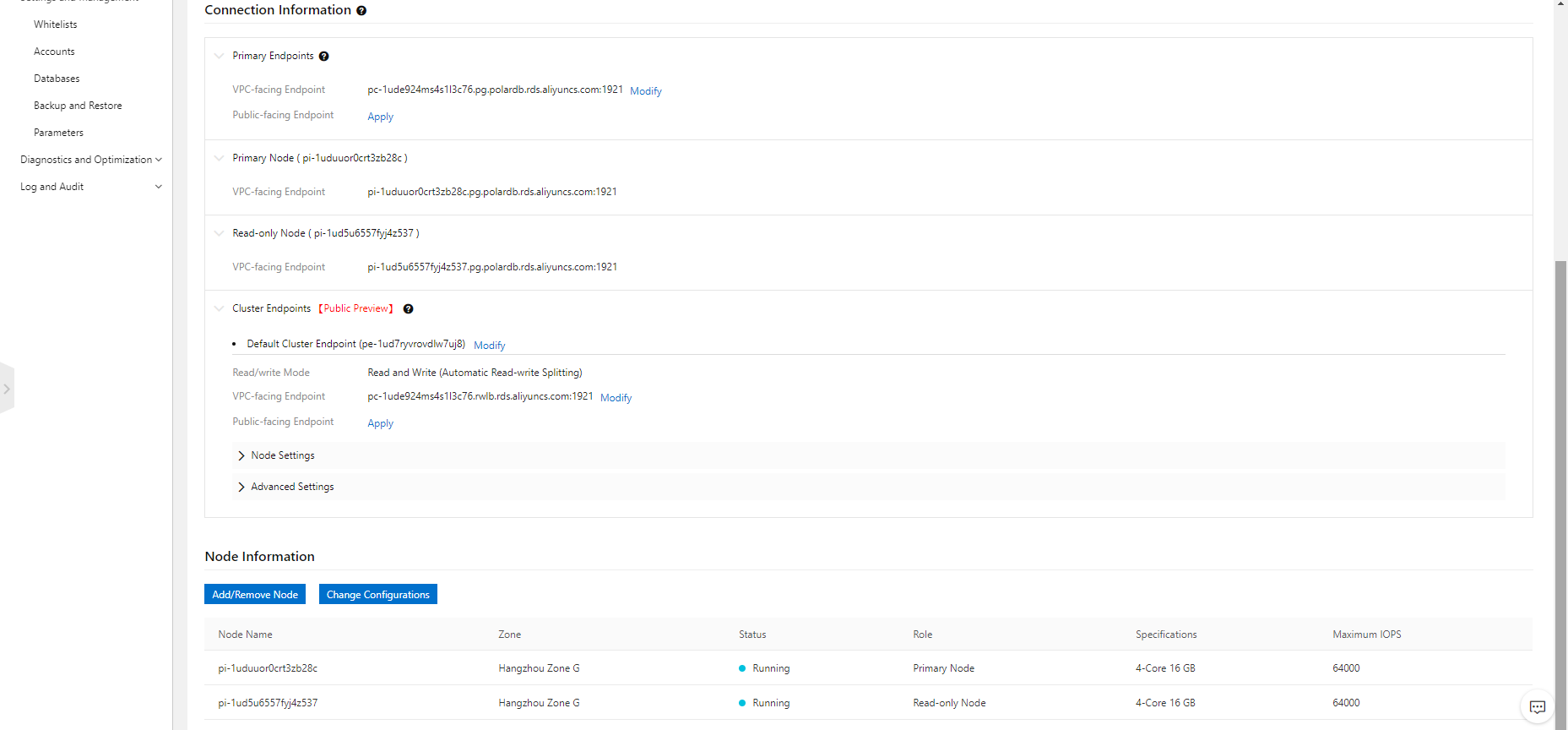
プライマリエンドポイントとデフォルトクラスタエンドポイントの名前を変更してみます。
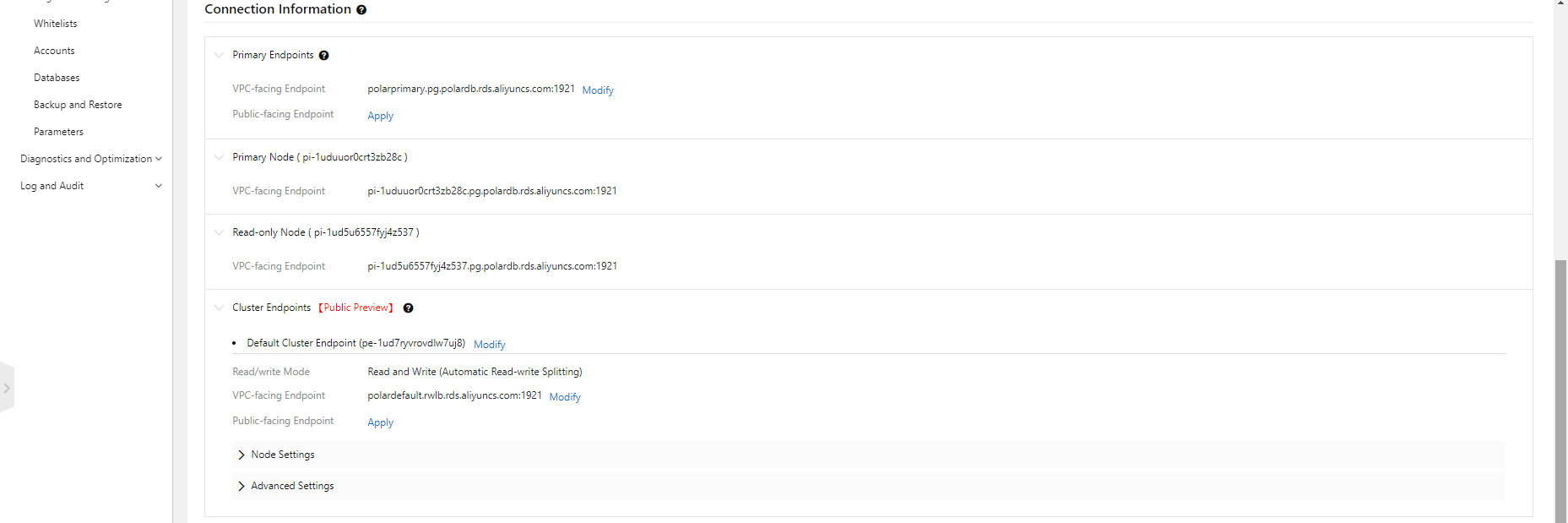
2019/12/01 現在、MySQL 8.0 互換版との(エンドポイントの)主な違いは、以下のとおりです。
- Public アクセス可能なエンドポイントは作成できない
- ノード別のエンドポイントが存在する(但し使用は非推奨)
- カスタムエンドポイントの作成はできない
また、ノードの手動再起動や Switch Primary Node ができません。
…困りました。あとでテストするときに、再起動で共有バッファの消去をしようと思ったのですが。
ホワイトリストの指定
2019/12/01 現在のマニュアルには「PostgreSQL 互換版ではホワイトリストの設定ができない」(同じ VPC 内からのアクセスを受け付ける)と記されていますが、実際はホワイトリストを指定しないと同一 VPC 内からのアクセスも受け付けてくれません。
というわけで、指定を追加します。

管理アカウントの作成
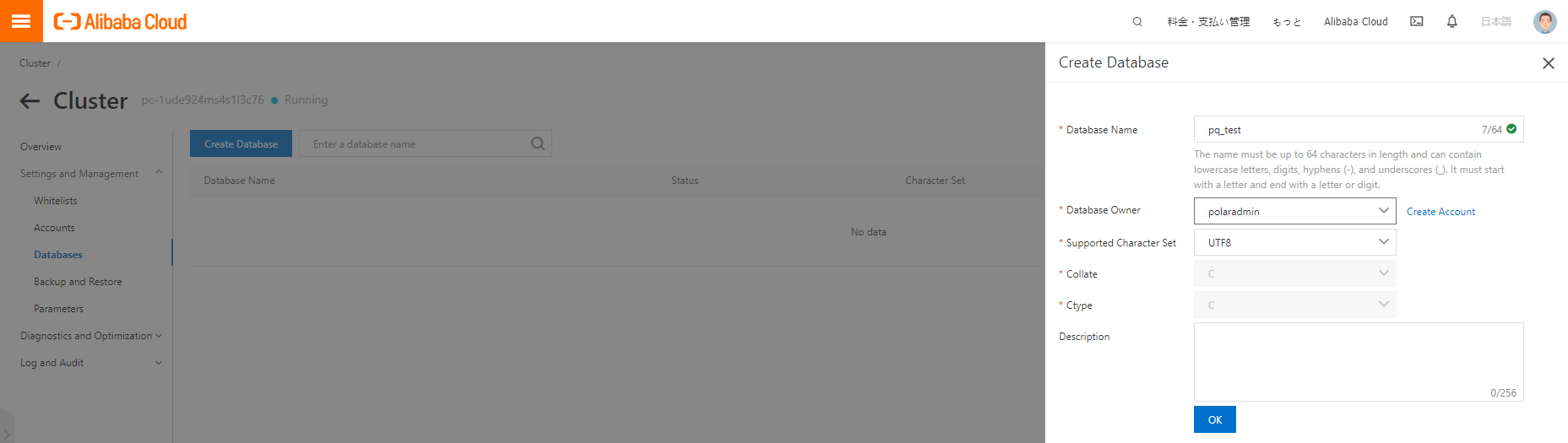
データベースの作成
MySQL 8.0 互換版のときは MySQL クライアントから接続して作成しましたが、今回は管理コンソールから作成してみます(MySQL 8.0 互換版でも管理コンソールから作成できます)。
パラメータの設定
MySQL 8.0 互換版と比べて設定変更できる項目は少ないようです。
接続してみる
同じ VPC にある ECS インスタンスから接続してみます。
通常の PostgreSQL とは違い、デフォルトポート番号は1921です。
[root@polartest ~]# psql -h polarprimary.pg.polardb.rds.aliyuncs.com -p 1921 -U polaradmin -d pq_test
Password for user polaradmin:
psql (9.2.24, server 11.2)
WARNING: psql version 9.2, server version 11.0.
Some psql features might not work.
Type "help" for help.
pq_test=>
2019/12/01 現在、バージョンは 11.2 でした。
パラレルスキャンを試してみる
昨年、Amazon Aurora PostgreSQL 10.5 互換版で試してみたとおりにやってみます。
デフォルトの設定で試しました。1 つの SQL に対して起動される Worker プロセスは 2 つです。
**テーブル定義とテストデータ生成**
pq_test=> CREATE TABLE table_i (number SERIAL PRIMARY KEY, id INT, value INT);
CREATE TABLE
pq_test=> CREATE INDEX idx_id ON table_i (id);
CREATE INDEX
pq_test=> CREATE FUNCTION gen_data () RETURNS INTEGER AS '
pq_test'> BEGIN
pq_test'> FOR i IN 1..10000000 LOOP
pq_test'> EXECUTE ''INSERT INTO table_i (id, value) VALUES((random() * 10000)::int % 100, (random() * 100000000)::int % 10000)'';
pq_test'> END LOOP;
pq_test'> RETURN 1;
pq_test'> END;
pq_test'> ' LANGUAGE 'plpgsql';
CREATE FUNCTION
pq_test=> SELECT gen_data();
gen_data
----------
1
(1 row)
**パラレルスキャンでシーケンシャルスキャンをテスト**
pq_test=> EXPLAIN ANALYZE SELECT id, avg(value) FROM table_i GROUP BY id;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=117766.99..117792.57 rows=100 width=36) (actual time=5377.518..5377.690 rows=100 loops=1)
Group Key: id
-> Gather Merge (cost=117766.99..117790.32 rows=200 width=36) (actual time=5377.503..5379.514 rows=300 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=116766.97..116767.22 rows=100 width=36) (actual time=5369.624..5369.630 rows=100 loops=3)
Sort Key: id
Sort Method: quicksort Memory: 32kB
Worker 0: Sort Method: quicksort Memory: 32kB
Worker 1: Sort Method: quicksort Memory: 32kB
-> Partial HashAggregate (cost=116762.64..116763.64 rows=100 width=36) (actual time=5369.539..5369.560 rows=100 loops=3)
Group Key: id
-> Parallel Seq Scan on table_i (cost=0.00..95932.43 rows=4166043 width=8) (actual time=0.475..4684.437 rows=3333333 loops=3)
Planning Time: 6.559 ms
Execution Time: 5381.806 ms
(15 rows)
pq_test=> EXPLAIN ANALYZE SELECT id, avg(value) FROM table_i GROUP BY id;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=117766.99..117792.57 rows=100 width=36) (actual time=965.491..965.681 rows=100 loops=1)
Group Key: id
-> Gather Merge (cost=117766.99..117790.32 rows=200 width=36) (actual time=965.475..967.271 rows=300 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=116766.97..116767.22 rows=100 width=36) (actual time=959.930..959.936 rows=100 loops=3)
Sort Key: id
Sort Method: quicksort Memory: 32kB
Worker 0: Sort Method: quicksort Memory: 32kB
Worker 1: Sort Method: quicksort Memory: 32kB
-> Partial HashAggregate (cost=116762.64..116763.64 rows=100 width=36) (actual time=959.860..959.878 rows=100 loops=3)
Group Key: id
-> Parallel Seq Scan on table_i (cost=0.00..95932.43 rows=4166043 width=8) (actual time=0.007..290.931 rows=3333333 loops=3)
Planning Time: 0.542 ms
Execution Time: 967.469 ms
(15 rows)
※共有バッファにテストデータが載っていない状態で試すために、読み取り専用ノードのエンドポイントに接続して実行。
**パラレルスキャンでインデックススキャンをテスト**
pq_test=> EXPLAIN ANALYZE SELECT id, avg(value) FROM table_i WHERE id < 10 GROUP BY id;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------
--
Finalize GroupAggregate (cost=73984.89..74010.48 rows=100 width=36) (actual time=6080.839..6080.855 rows=10 loops=1)
Group Key: id
-> Gather Merge (cost=73984.89..74008.23 rows=200 width=36) (actual time=6080.824..6083.854 rows=30 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=72984.87..72985.12 rows=100 width=36) (actual time=6071.200..6071.201 rows=10 loops=3)
Sort Key: id
Sort Method: quicksort Memory: 25kB
Worker 0: Sort Method: quicksort Memory: 25kB
Worker 1: Sort Method: quicksort Memory: 25kB
-> Partial HashAggregate (cost=72980.55..72981.55 rows=100 width=36) (actual time=6071.166..6071.169 rows=10 loops=3)
Group Key: id
-> Parallel Bitmap Heap Scan on table_i (cost=11473.87..70913.50 rows=413410 width=8) (actual time=1042.277..6002.542 rows=333411 loops=3)
Recheck Cond: (id < 10)
Heap Blocks: exact=18017
-> Bitmap Index Scan on idx_id (cost=0.00..11225.82 rows=992185 width=0) (actual time=1038.419..1038.419 rows=1000232 loops=1)
Index Cond: (id < 10)
Planning Time: 6.908 ms
Execution Time: 6084.243 ms
(19 rows)
pq_test=> EXPLAIN ANALYZE SELECT id, avg(value) FROM table_i WHERE id < 10 GROUP BY id;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------
Finalize GroupAggregate (cost=73984.89..74010.48 rows=100 width=36) (actual ti
me=259.526..259.550 rows=10 loops=1)
Group Key: id
-> Gather Merge (cost=73984.89..74008.23 rows=200 width=36) (actual time=259.515..263.065 rows=30 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=72984.87..72985.12 rows=100 width=36) (actual time=253.699..253.700 rows=10 loops=3)
Sort Key: id
Sort Method: quicksort Memory: 25kB
Worker 0: Sort Method: quicksort Memory: 25kB
Worker 1: Sort Method: quicksort Memory: 25kB
-> Partial HashAggregate (cost=72980.55..72981.55 rows=100 width=36) (actual time=253.669..253.673 rows=10 loops=3)
Group Key: id
-> Parallel Bitmap Heap Scan on table_i (cost=11473.87..70913.50 rows=413410 width=8) (actual time=73.858..191.934 rows=333411 loops=3)
Recheck Cond: (id < 10)
Heap Blocks: exact=18016
-> Bitmap Index Scan on idx_id (cost=0.00..11225.82 rows=992185 width=0) (actual time=66.715..66.715 rows=1000232 loops=1)
Index Cond: (id < 10)
Planning Time: 0.938 ms
Execution Time: 263.316 ms
(19 rows)
※共有バッファにテストデータが載っていない状態で試すために、読み取り専用ノードを 1 つ追加し、そのエンドポイントに接続して実行。
| バージョン/パラレルスキャン有効・無効 | シーケンシャル 1 回目 | シーケンシャル 2 回目 | インデックス 1 回目 | インデックス 2 回目 |
|---|---|---|---|---|
| 【過去】Aurora 9.6/無効 | 6,764.665 | 2,718.139 | - | - |
| 【過去】Aurora 9.6/有効 | 6,303.016 | 2,936.115 | 185,450.502 | 923.486 |
| 【過去】Aurora 10.5/有効 | 5,707.766 | 2,921.991 | 42,457.903 | 493.760 |
| 【今回】POLARDB 11.2/有効 | 5,388.365 | 968.011 | 6,091.151 | 264.254 |
過去の Aurora の数値は db.r4.large で実行した結果です。
ハードウェアスペックやアーキテクチャの差のほかに、ベースの PostgreSQL のバージョンアップによる性能向上の影響もありそうです。
次回、MySQL 8.0 互換版のパラレルクエリの続きを挟んで、PostgreSQL 11 互換版の Ganos を試す予定です。
alibabacloud Advent Calendar 2019 の明日(4 日目)は bigy さんです。
参考:その他の画面
Performance Insight
モニタリング
スロークエリ