はじめに
「生成AI」「生成モデル」は学習データをもとに新たなデータを生成する技術で、世界的に注目を集めています。生成できるデータは、画像・点群・音声・動画・化合物など様々です。特に、生成モデルのうち「拡散モデル」 1の登場以降は、高品質なデータの生成が容易になりました。本記事では、特に画像に焦点を当てて、拡散モデルをなるべく分かりやすいように解説します。
拡散モデルの登場以降は、非常に高精細な画像の生成ができるようになりました。図1に拡散モデルによって生成した画像の例を示します。全て実際には存在しない画像ですが、驚くほどきれいだと感じられるかと思います。
また、拡散モデルの一種である「Stable Diffusion」 2の登場によって、テキストで生成内容を制御できるようになりました。これによって、所望の画像の生成が容易になり、さらに応用が進んだと言われています。例えば、業務支援(Microsoft社)、コンテンツの生成支援(Adobe社)、広告の生成支援(サイバーエージェント社)など、様々な分野でサービスが出始めています。
本記事では、まず拡散モデルの仕組みを説明し、GANやVAEのような他のモデルとの違いを説明します。また、拡散モデルの代表例であるStable Diffusionを紹介し、最後に動画を生成できる拡散モデルについて紹介します。

図1:拡散モデルによって生成した画像の例(文献2から引用)
拡散モデルの仕組み
本章では、拡散モデルの仕組みを説明します。図2に拡散モデルのアイデアを示します。拡散モデルでは、データに徐々にノイズを付加する拡散過程と、徐々にノイズを除去する逆拡散過程を考えます。拡散過程では、画像に徐々にノイズを加えていき、最終的に純粋なノイズを得ます。これは単純にノイズを加えていくだけなので簡単です。一方、逆拡散過程では、純粋なノイズから徐々にノイズを除去していき、最終的に鮮明な画像を得ます。こちらは拡散過程と異なり難しいため、逆拡散過程を深層学習モデルで表現します。深層学習モデルとしては、U-Net 3というモデルがよく使われます。モデルの学習時は拡散過程と逆拡散過程の両方を利用しますが、実際に画像を生成する際は逆拡散過程のみを利用します。
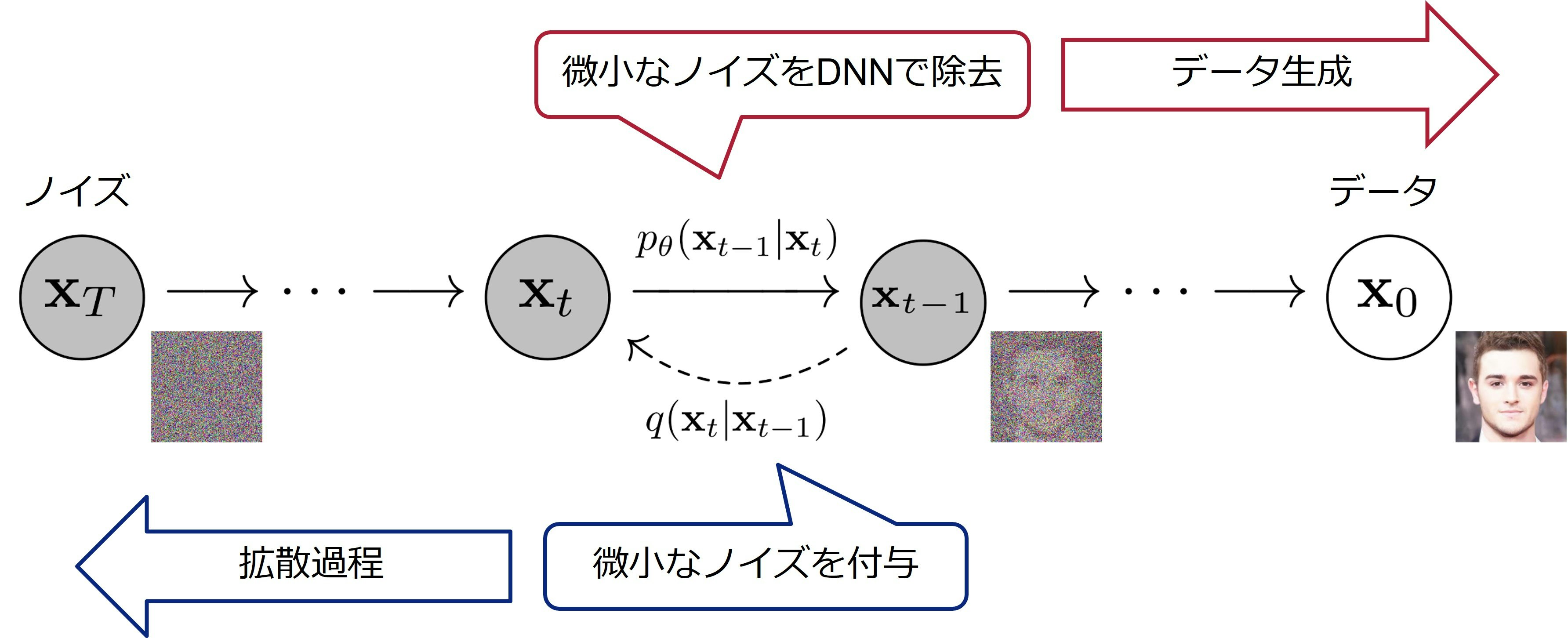
図2:拡散モデルのアイデア(文献1をもとに作成)
拡散モデルと他モデルとの違い
生成モデルには、拡散モデルの他にもGAN(Generative Adversarial Networks) 4やVAE(Variational Autoencoder) 5などがあります。本章では、拡散モデルとGAN・VAEとの違いを説明します。
図3に、拡散モデルとGAN・VAEのアーキテクチャの違いを示します。GANは、生成器と識別器の2つのネットワークが競い合うことでデータを生成します。VAEは、エンコーダで潜在空間にマッピングし、デコーダで元のデータを再構築します。GANは高品質な画像を生成できる一方で、多様性に欠けたり、学習が不安定だと言われています。VAEは多様性があり、学習も安定している一方で、品質は高くないと言われています。拡散モデルは、多様性や学習の安定性が高く、非常に高品質です。しかし、長所だけではなく、計算量が大きいといった問題があります。
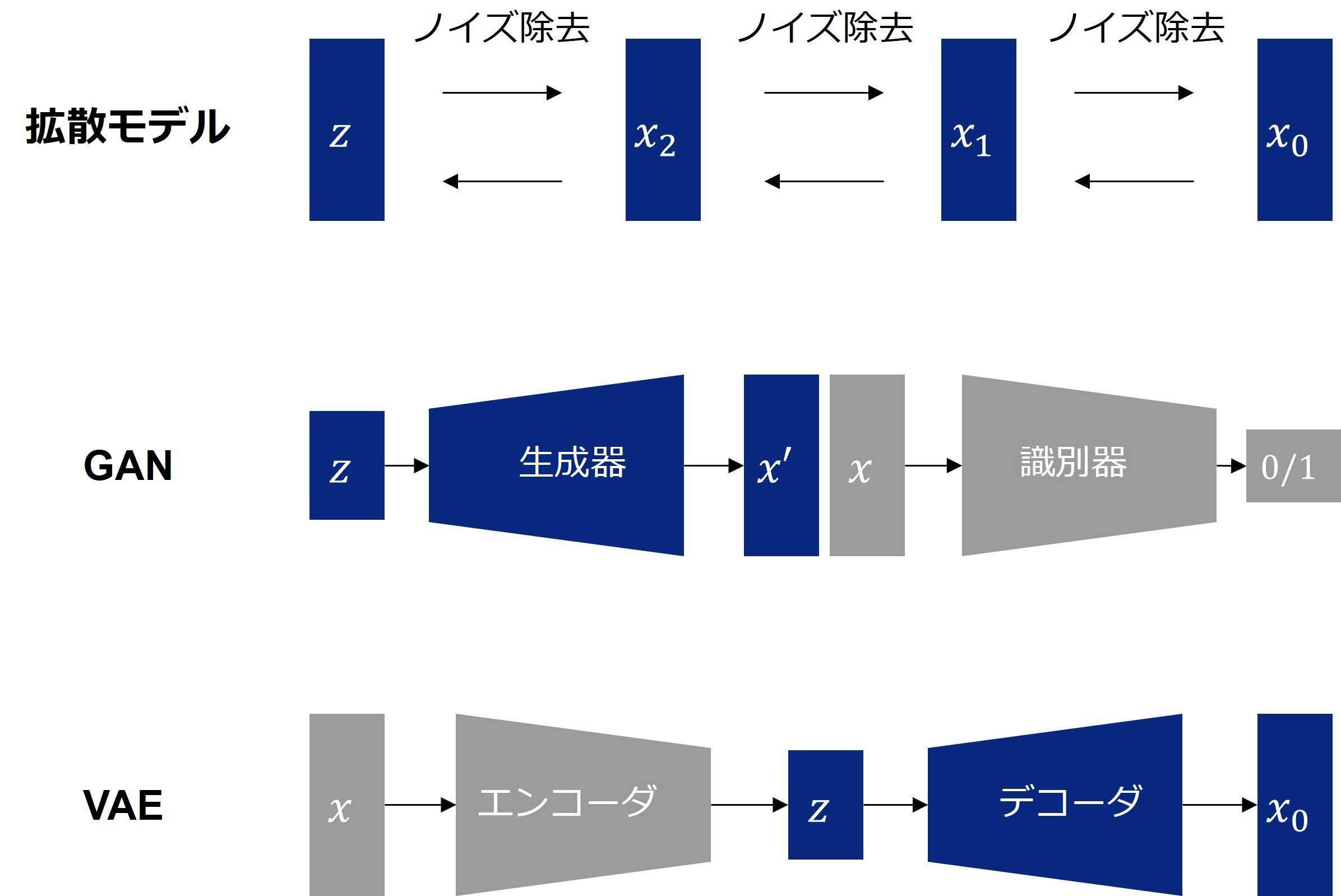
図3:拡散モデルとGAN・VAEのアーキテクチャの違い
拡散モデルの代表例
拡散モデルの代表例として、Stable Diffusion(Stability AI社) 2、DALL E2(OpenAI社) 6、Imagen(Google社) 7などがあります。本章では、最も代表的な例であるStable Diffusionを紹介します。Stable Diffusionの特徴は、低次元の潜在空間上で拡散モデルを構築し、学習及び生成の計算量を削減できる点です。
図4に、Stable Diffusionの仕組みを示します。Stable Diffusionは、大きく分けると3つの要素で構成されています。
- 画像エンコーダ・デコーダ:画像を低次元の潜在表現に変換します。具体的にはVAEを使います。VAE自体は画像生成に使うこともできますが、ここでは潜在表現抽出に使います。
- 拡散モデル:潜在空間上で拡散モデルを動作させます。
- テキストエンコーダ:テキストを拡散モデルで使えるような潜在表現に変換します。具体的にはCLIP 8というモデルを使います。
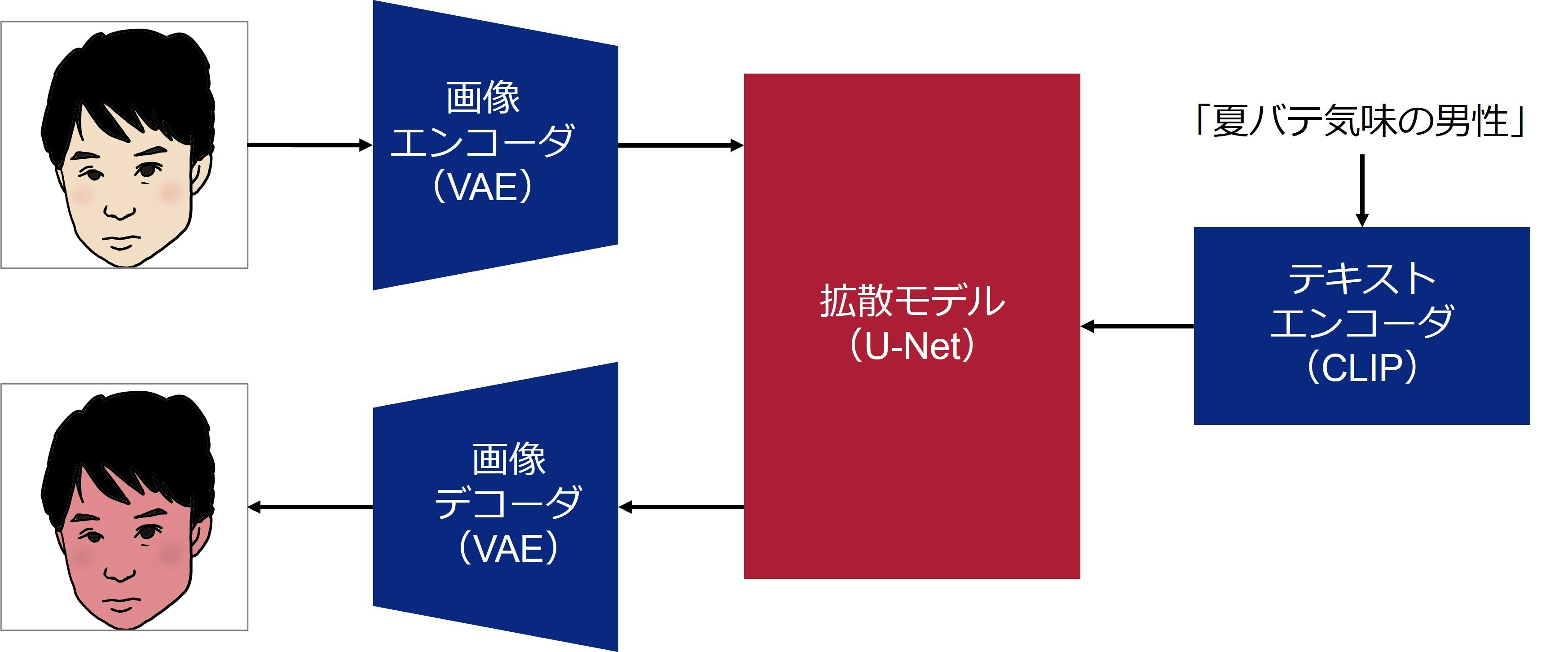
図4:Stable Diffusionの仕組み
動画を生成できる拡散モデル
前章までは静止画を対象とした拡散モデルについて説明してきましたが、本章では最近開発が進んでいる動画を対象とした拡散モデルを紹介します。
代表的な例として、Video Diffusion Models (VDM) 9は、空間方向だけでなく時間方向でもアテンションを算出することによって、時間的な一貫性を保持した動画を生成することを可能にしました。図5に、VDMによる空間方向と時間方向のアテンション算出を示します。
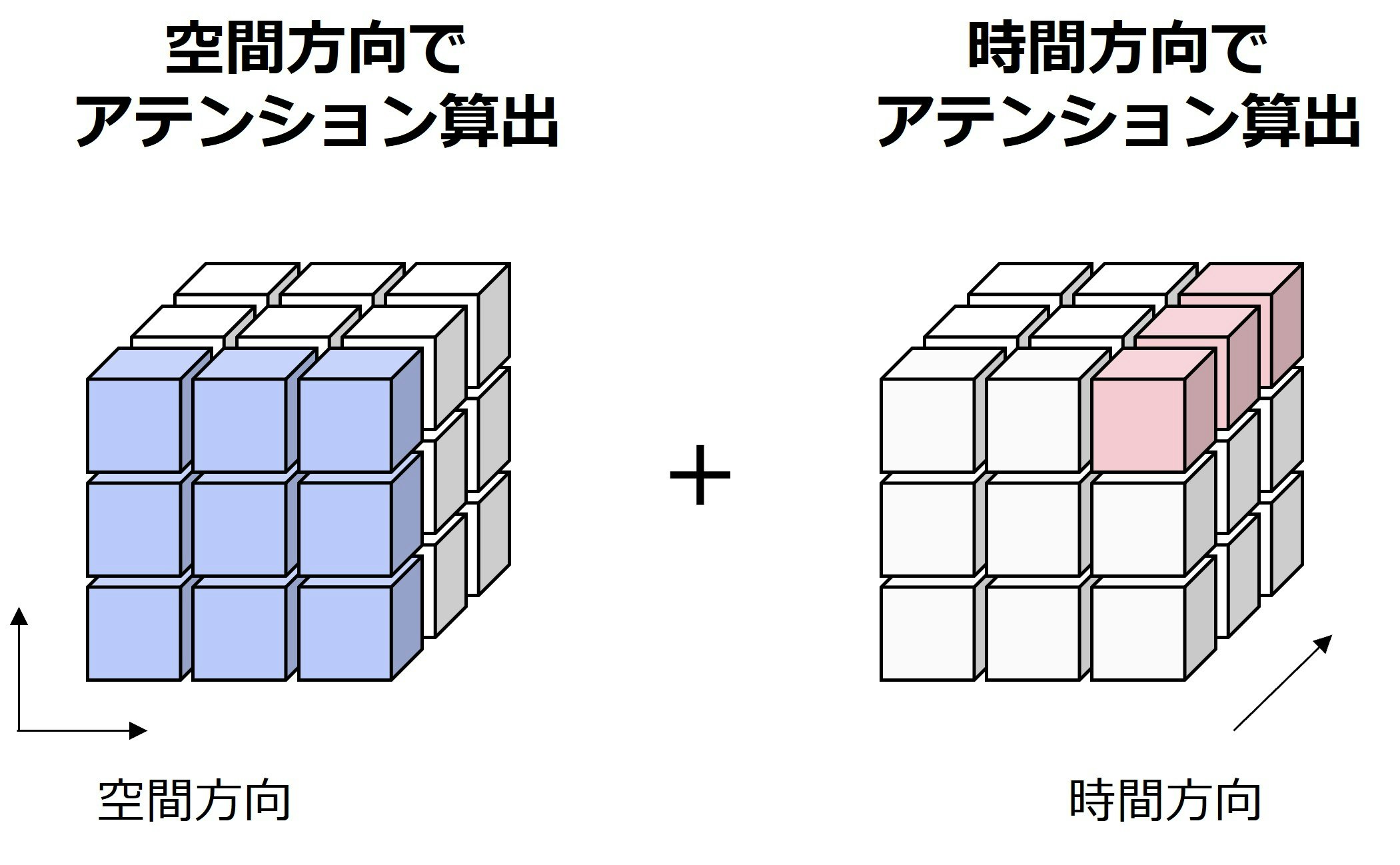
図5:VDMによる空間方向と時間方向のアテンション算出
しかし、モデルの学習のためには、テキストが付与されている大量の動画が必要になるといった問題ありました。そこで、Make-A-Video(Meta社) 10は、テキストが付与されていない大量の動画を用いて、学習済みの静止画拡散モデルをファインチューニングすることを可能にしました。図6に、Make-A-Videoによって生成した動画の例を示します。入力したテキストの意味を表現し、かつスムーズな動きを生成できていることが分かると思います。このような静止画向けの拡散モデルを動画向けに拡張するアプローチは、その後も主流となっています。

図6:Make-A-Videoによって生成した動画の例(文献8から引用)
まとめ
本記事では、拡散モデルの概要を解説しました。今回は入門編ということで、深い理論や多くの改良版、また実装や応用・サービスなど、まだまだ紹介できていないことがたくさんあります。本記事が、拡散モデルに興味を持っていただくきっかけになれば幸いです。なお本記事の執筆には、1~10以外にも1112131415161718を参考にしました。
参考文献
-
Denoising Diffusion Probabilistic Models
https://arxiv.org/abs/2006.11239 ↩ ↩2 ↩3 -
Stable Diffusion
https://ja.stability.ai/stable-diffusion ↩ ↩2 ↩3 -
U-Net: Convolutional Networks for Biomedical Image Segmentation
https://arxiv.org/abs/1505.04597 ↩ -
Generative Adversarial Networks
https://arxiv.org/abs/1406.2661 ↩ -
Auto-Encoding Variational Bayes
https://arxiv.org/abs/1312.6114 ↩ -
DALL E2
https://openai.com/dall-e-2/ ↩ -
Imagen
https://imagen.research.google/ ↩ -
Contrastive Language-Image Pre-Training
https://github.com/openai/CLIP ↩ ↩2 -
Video Diffusion Models
https://video-diffusion.github.io/ ↩ -
Make-A-Video
https://makeavideo.studio/ ↩ ↩2 -
拡散モデルに入門してみる
https://qiita.com/momo10/items/e19aaf66cc7088ef3da3 ↩ -
拡散モデルの基礎と研究事例: Imagen
https://qiita.com/iitachi_tdse/items/6cdd706efd0005c4a14a ↩ -
GANと拡散モデルの調査
https://zenn.dev/d2c_mtech_blog/articles/13551863282e59 ↩ -
Diffusion model(拡散モデル)とは?仕組みやGAN・VAEとの違いを解説
https://aismiley.co.jp/ai_news/what-is-the-diffusion-model/ ↩ -
SSII2023 [SS1] 拡散モデルの基礎とその応用 ~Diffusion Models入門~
https://speakerdeck.com/ssii/ssii2023-ss1?slide=7 ↩ -
拡散と流れに基づく学習と推論
https://hillbig.github.io/JNNS2023_okanohara.pdf ↩ -
図で見てわかる!画像生成AI「Stable Diffusion」の仕組み
https://qiita.com/ps010/items/ea4e8ddeff4de62d1ab1 ↩ -
【Deep Learning研修(発展)】データ生成・変換のための機械学習 第7回前編「Diffusion models」
https://www.youtube.com/watch?v=10ki2IS55Q4 ↩