
ゴッホの「星月夜」のような火星で馬にのる宇宙飛行士 (Stable Diffusionで作成)
この記事は、Supershipグループ Advent Calendar 2022の13日目の記事になります。
Supership プロダクト開発本部の @ps010 です。普段は広告・マーケティング領域で、分析業務や広告セグメントの作成を担当しています。
記事の目的
最近、チャットAIや画像生成AIが話題ですね。特に画像生成AIの Stable Diffusion は、無料かつ無制限で実装を試せることで注目を集めています。
そこでこの記事では、Stable Diffusion の仕組みの理解を目指します。
画像生成AIがどのような仕組みでテキストから画像を生成するのか、Stable Diffusion に焦点を当て、基本構造をわかりやすく解説します。
画像生成のメカニズムをイメージしやすいように、以下の方針で説明します。
- 深層学習の基本知識を持っている人を対象とします。
- わかりやすさを重視し、以下について図解します。
- 全体の構成
- 技術の仕組み
- 軽量化(VAE)
- テキストから画像への変換(Text Encoder)
- 画像生成(拡散モデル)
技術の詳細については、おすすめのブログや動画を紹介します。
また、本記事は主に元論文と モデルの提供元の HuggingFaceのブログポスト1を参照しています。
忙しい方の為の要約

(犬画像はphoto-ac フリー素材使用)
Stable Diffusionの特徴は、次の3つです。
- Stable Diffusionは、最近流行の Diffusion Model(拡散モデル)をベースとしたtext-to-imageの画像生成モデルです
- VAEでピクセル画像を潜在表現に変換することで、モデルの軽量化に成功しました
- U-Netを用いた画像生成の条件づけにText EncoderのCLIPを使用します
概要
特徴
Stable Diffusionとは、テキストから画像を作る画像生成モデルです。英系スタートアップ企業の Stability AIを中心に、CompVis、Runway、LAION 他により共同で研究・開発され、2022年8月に Stability AI から Stable Diffusion v1 として一般公開されました。
元論文の Latent Diffusion Model(潜在拡散モデル) をベースにしており、潜在空間を利用して効率的に学習するため、ピクセルごとに計算が必要な DALL-E22 などに比べモデルが軽く、ユーザー環境でも実行可能です。複数のタスクやデータセットで高性能を達成しており、安定的に画像が生成できることも嬉しいポイントです。
もう一つ、Stable Diffusion のすごいところは、コードと学習済みの重みが OSS として公開されており、無料かつ無制限で利用できる点です。重みの更新や商用利用も可能で、HuggingFaceを通じてモデルを利用できます。
公開の詳細情報は、Stability AIのアナウンスをご参照ください。
リファレンス
論文
Stable Diffusionの元論文です。CVPR 2022で発表されました。
Githubリポジトリ
開発者や提供会社ごとに複数存在します。
- by HuggingFace: diffusers
- モデルを提供するHugging Faceのリポジトリ。ブログ1で使い方を説明しています。
- by CompVis: latent-diffusion、 stable-diffusion
- ComVis版。
latent-diffusionは元論文、stable-diffusionは Stable Diffusion v1です
- ComVis版。
- by StabilityAI: stablediffusion
- StabilityAIが2022年秋に公開した Stable Diffusion v2のリポジトリです
データセット
学習データは、LAION 5Bのサブセット LAION-Aestheticsを17億サンプル使用しています(参照)。
LAION 5Bは 512x512 画像とテキストのペアで構成されるデータセットです。研究目的の大規模データセットで、自由にアクセスが可能です。CLIPによりテキストと関連性が高い画像のペアに絞り込まれています。
LAION-Aestheticsは、LAION 5Bからテスターの審美性スコアが高い画像が選ばれています。
テキスト&画像ペアのデータセットはこちらで確認ができます。
Stable Diffusionの実行
Hugging faceのサイトでアカウントを登録してtokenを発行すると、モデルの読み込みが可能になります。利用方法は Hugging Faceのブログポスト1が詳しいですが、利用の段取りは↓こちらの説明がわかりやすいです。興味のある方はご参照ください。
アーキテクチャ(構成)

Stable Diffusionは3つのコンポーネントで構成されています。
- VAE
- Text Encoder(モデル: CLIP)
- 拡散モデル(モデル: U-Net)
VAEとText Encoderは、拡散モデルとユーザーの入出力との橋渡しを担当します。VAEは画像、Text Encoderはテキストをモデルが処理しやすい形に変換しています。画像生成は拡散モデルが担当します。次のセクションで、各々の仕組みを説明します。
各コンポーネントの仕組み
VAE
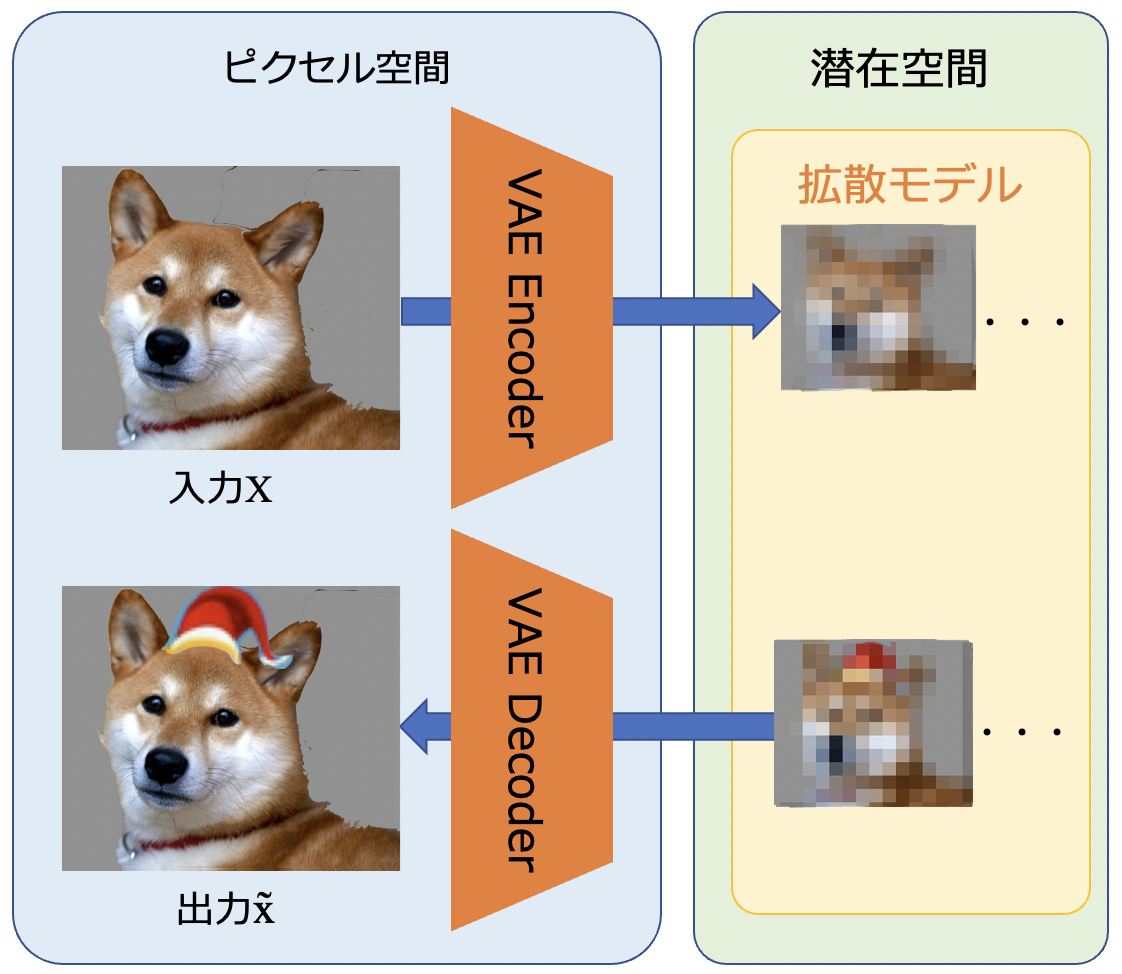
VAE(Variational Autoencoder)は、単体でも画像生成モデルとして使われますが、Stable Diffusionではピクセル画像を潜在的な画像埋め込み表現に変換するために使われています。512×512サイズのピクセル画像から、8×8サイズの潜在表現に変換されるため、処理の負担が 64分の1 に大幅に軽減されます。
エンコーダーとデコーダーに分かれており、エンコーダーはピクセル画像をU-Netで使われる低次元の潜在表現に変換します。デコーダーは生成された潜在表現をピクセル画像に変換します。
VAEで使われる技術の概要説明は、こちらのサイトがわかりやすいです。
Text Encoder

Text Encoderは入力プロンプト サンタ風の犬 をU-Netで使う潜在的なテキスト埋め込みにマッピングします。Googleの画像生成モデル Imagen3にヒントを得て、Stable DiffusionでText Encoderを学習することはせず、CLIPのTransformerベースの学習済みText Encoder「CLIPTextModel」を使用しています。
CLIPとは
CLIPはOpenAIが開発した画像分類モデルで、幅広いタスクでゼロショット転移が可能な事前学習モデルです。インターネットの4億組の画像とテキストのペアを教師データとして使用しており、汎用性の高さが魅力です。
拡散モデル(Diffusion Model)
次は、画像生成を担う拡散モデルです。英語では Diffusion Model と呼ばれます。
モデルの基本コンセプトをざっくりと説明した後に、Stable Diffusion における学習、推論それぞれについて説明します。
基本コンセプト
拡散モデルの基本コンセプトです。

画像生成においてノイズからデータを生成するのは難しいですが、データに徐々にノイズを加えてノイズに変換することは可能です。そこで、まずデータからノイズへの変換(拡散プロセス:forward diffusion process)を考え、それを逆変換して、ノイズからデータへの変換(逆拡散プロセス:reverse diffusion process)を考えます。つまり、ノイズからデータへの変換を徐々にノイズを除去する処理であると考え、それを学習します。

モデル(U-Net)は、拡散プロセスで付加される微小なノイズを正規分布と仮定し、その分布を学習します。逆拡散プロセスでモデルが出力するノイズと正解データのノイズの二乗誤差を計算し、それを最小化するよう学習を進めます。
拡散モデルの詳細な解説は、ソニーの動画が大変わかりやすいのでオススメです。逆拡散プロセスの定式化についても触れているので、興味がある方はご参照ください。
学習の流れ
Stable Diffusionにおける拡散モデルの学習について説明します。
拡散モデルは最適化が単純で、確率過程を利用するため結果が安定的である一方、生成に時間がかかるという短所があります。これを潜在空間で学習することで解決したのが Stable Diffusion です。

拡散モデルは、拡散プロセスと逆拡散プロセスで構成されます。
拡散プロセスは、VAEのEncoderからピクセル画像を低次元化した潜在表現を受け取り、ノイズを付加してノイズZtを作成します。逆拡散プロセスはノイズZtを受け取り、U-Netで繰り返しノイズを除去し、その過程で得られる誤差を最小化することで学習を進めます。
推論の流れ
次に推論です。推論では、逆拡散プロセスのみ実行されます。

拡散モデルは潜在表現のランダムノイズをシードとして画像生成を始めます。Text Encoderからユーザーの入力を潜在表現に変換したテキスト埋め込みを受け取り、U-Netのノイズ除去処理の条件付けに使用します。
U-Net
次はU-Netの基本コンセプトとStable Diffusion における動きについて説明します。
U-Netは画像のセマンティックセグメンテーションでよく使われる技術で、Diffusion Modelのノイズ除去でも多用されています。
基本コンセプト
一般的なU-Netの概念図です。
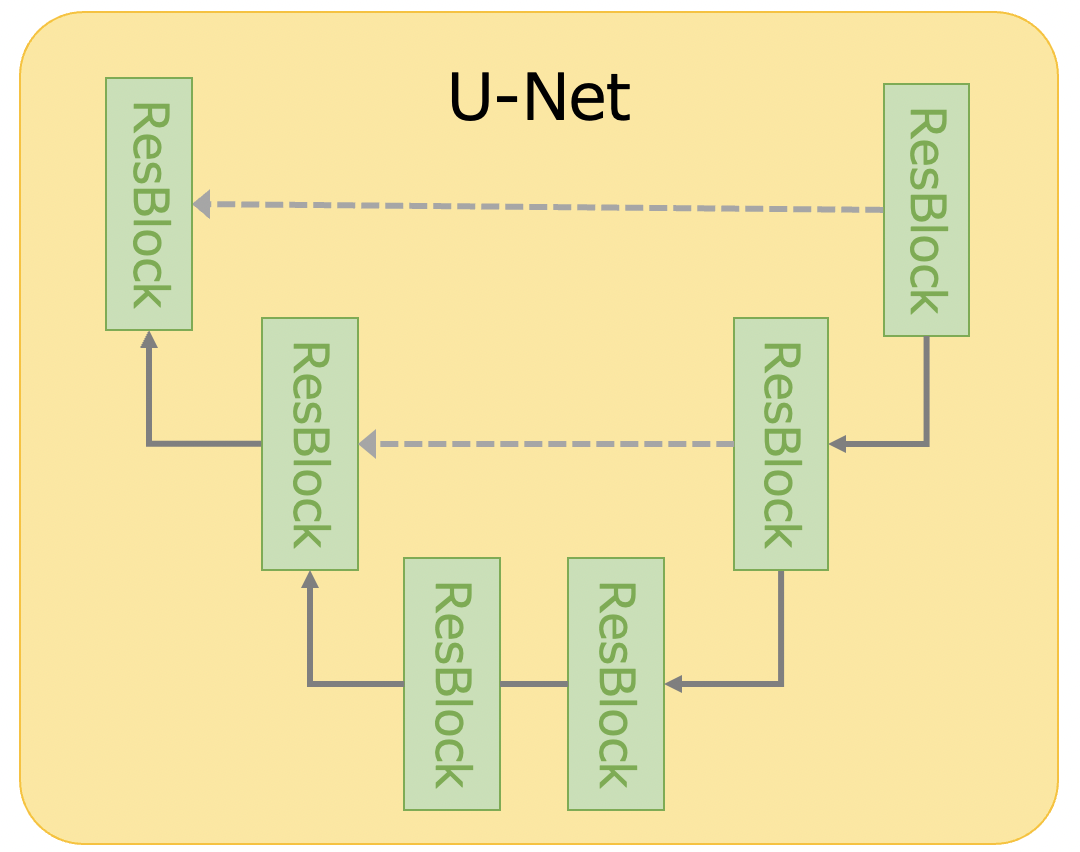
U-Netはエンコーダ・デコーダ構造を持ちます。エンコーダはResNetによる畳み込み(ダウンサンプリング)で特徴マップ(物体が何であるか)を抽出し、デコーダは逆畳み込み(アップサンプリング)で入力と同じサイズの確率マップを生成します。特徴マップ抽出で失われる位置情報(物体がどこにあるか)を補うため、同じ階層の特徴マップをエンコーダからデコーダに渡す構造となっています。
セマンティックセグメンテーションは、上記の仕組みで画面に配置するオブジェクトが何であるかを分類できるようになります。以下の場合は、背景と犬を分類します。

Stable DiffusionにおけるU-Net
Stable DiffusionのU-Netの概念図4です。

画像生成では、意図に沿った画像を生成するために条件付けという手法を用いますが、Stable DiffusionではU-Netの条件付けに交差注意(Cross Attention)を使ってテキストに沿った画像の生成を試みています。ResBlockの間に挟み込まれたAttentionがその役割を果たします。
処理のイメージです。

ノイズ除去のステップにおいて、ResBlockの畳み込みとAttentionが交互に動作します。
Attentionには、畳み込み結果とテキストの両方の潜在表現が渡されます。前回のAttentionの記事でも触れた 以下の式の Q(Query)を ResBlock から、K(Key)・V(Value)を Text Encoderから受け取ることで、テキストに沿った確率マップが出力される仕組みです。
$$Attention(Q, K, V ) = softmax\Bigl(\frac{QK^T}{\sqrt{d_k}}\Bigr)V$$
説明は以上となります。
まとめ
今回は、画像生成AIのStable Diffusionを取り上げました。
DALL-E2やImagenなど、現在主流の画像生成AIでは拡散モデルが多く使われており、Stable Diffusionも同様であること、また潜在空間を利用することでモデルを軽量化し、画像生成の民主化に貢献していることがわかりました。使用技術の狙いと工夫が見事で、理にかなっているので、とても興味深かったです。
おまけ
Stable Diffusionでこんなプロンプトを試してみました。
「空飛ぶタクシーでプレゼントを配るサンタ」

ファンタスティックで割と好きです。
別バージョン。

いやいや、空飛ぶタクシーで部屋の中で浮いてるだけって!怠け者すぎませんかw?
Stable Diffusion、結構遊べそうです。
正月休みに、いろいろ試してみようと思います!
宣伝
Supershipではプロダクト開発やサービス開発に関わる人を絶賛募集しております。
ご興味がある方は以下リンクよりご確認ください。
是非ともよろしくお願いします!
参考
- 【Deep Learning研修(発展)】データ生成・変換のための機械学習 第7回前編「Diffusion models」
- What are Diffusion Models?(日本語翻訳)
- Stable Diffusion を基礎から理解したい人向け論文攻略ガイド【無料記事】
- 世界に衝撃を与えた画像生成AI「Stable Diffusion」を徹底解説!
- 解剖! Stable Diffusion (1)
- 【徹底解説】VAEをはじめからていねいに
- 画像セグメンテーションのためのU-net概要紹介
-
ブログタイトル「Stable Diffusion with 🧨 Diffusers」。Hugging FaceがStable Diffusionの使い方を説明しています。 ↩ ↩2 ↩3
-
DALL-E2は、OpenAIが開発した Diffusion Modelベースの画像生成モデルです。CLIP と Diffusion Modelによる画像生成を組み合わせた2段階構造が特徴的です。技術説明はステート・オブ・AI ガイドのサイト(DALL-E2)がわかりやすいです。 ↩
-
Imagenは、Googleが開発したDiffusion Modelベースの画像生成モデルです。言語モデルをスケールすることで、画像の生成品質の向上を図りました。技術説明はステート・オブ・AI ガイドのサイト(Imagen)がオススメです。 ↩
-
論文・ブログおよびHugging Faceのリポジトリの記述とU-Netの一般的な構造から概念図を作成しています。実際のブロックやレイヤー数などはリポジトリをご参照ください。 ↩