はじめに
以前、物体検出アルゴリズムを使用してiPad用のアプリケーションを開発しました。
その時メモした、自前データの学習からKeras・CoreML用のモデル作成方法まで紹介します。
以下の順で進めます。
- Darknetで物体検出モデルを作成
- 物体検出モデルをKeras用に変換
- Keras用モデルをCoreML用に変換
必要環境
検証環境
- Google Compute Engine (GCE)
- マシンタイプ
- n1-standard-4(vCPU x 4、メモリ 15 GB)
- GPU
- 2 x NVIDIA Tesla V100
- OS
- Ubuntu 16.04.4 LTS
- マシンタイプ
Darknetで物体検出モデルを作成
自前データセットを用意してDarknetで学習を行い、物体検出モデルを作成します。
Darknetの環境構築
自前データを学習した物体検出モデルを作成するのに、Darknetというディープラーニングのフレームワークを使用します。
Darknetを使用することで、YOLOと呼ばれる物体検出アルゴリズムを簡単に利用することができます。
Darknetをインストール
GitHubにあるリポジトリをCloneします。
$ git clone https://github.com/pjreddie/darknet.git
makeします。
(makeコマンドが入っていない場合は、apt-getなのでbuid-essentialをインストール)
$ make
DarknetでGPUを使用する
この後に行うオリジナルデータの学習では、GPUを使用しないと、ありえないくらいの学習時間が発生します。
CUDAを導入してGPUを使用できるようにします。
(CUDAはnvidiaが開発したライブラリで、nvidia製のGPUのみ対応します)
CUDA8.0をインストールします。
$ sudo dpkg -i cuda-repo-ubuntu1604_8.0.*_amd64.deb
$ sudo apt update
$ sudo apt upgrade
$ sudo apt install cuda-8-0
パスを設定します。
$ echo -e "\n## CUDA and cuDNN paths" >> ~/.bashrc
$ echo 'export PATH=/usr/local/cuda-8.0/bin:${PATH}' >> ~/.bashrc
$ echo 'export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64:${LD_LIBRARY_PATH}' >> ~/.bashrc
$ source ~/.bashrc
cuDNNをインストールします。
「xzvf cudnn-8.0-linux-x64-v5.1.tgz」はnvidiaのページからダウンロードしてください。
$ tar xzvf cudnn-8.0-linux-x64-v5.1.tgz
$ sudo cp -a cuda/lib64/* /usr/local/cuda-8.0/lib64/
$ sudo cp -a cuda/include/* /usr/local/cuda-8.0/include/
$ sudo ldconfig
DarknetのMakefileを以下のように編集してからmakeします。
GPU=1
CUDNN=1
~
これで、Darknetの環境構築が完了しました。
動作確認する。
動作確認用のモデル(weightsファイル)をダウンロードします。
$ wget https://pjreddie.com/media/files/yolov2-tiny.weights
Darknetを実行して、物体検出を試します。
$ ./darknet detect cfg/yolov2-tiny.cfg yolov2-tiny.weights data/person.jpg
該当のオブジェクトにバウンティボックス付きのイメージ「predictions.png」というファイルが出力されます。

良いですね!バッチリです。
データセットの準備
必要なデータ
- 複数の画像データ(.jpg)
- 画像データに対となる座標データ(.txt)
- 画像リスト
- train.txt
- text.txt
- クラスリスト
- obj.names
- パス情報を記録したファイル
- obj.data
(ファイル名は、何でもOK)
座標データ
画像データ内で学習させる物体(オブジェクト)の座標情報を記録したファイルです。
画像データと対で必要で、ファイル名は拡張子を除いて画像データと合わせる必要があります。
データの書式は以下になります。
[カテゴリ番号] [オブジェクトの中心x座標] [オブジェクトの中心y座標] [オブジェクトの幅] [オブジェクトの高さ]
カテゴリ番号は、学習させる物体(オブジェクト)ごとに付ける、0から始まる整数数字で、学習させるオブジェクトの数が5つある場合、0〜4のカテゴリ番号が付きます。
オブジェクトの中心X座標、中心Y座標、オブジェクトの幅、高さは、画像データの幅、高さを1とした時の割合でオブジェクトの座標を指定します。
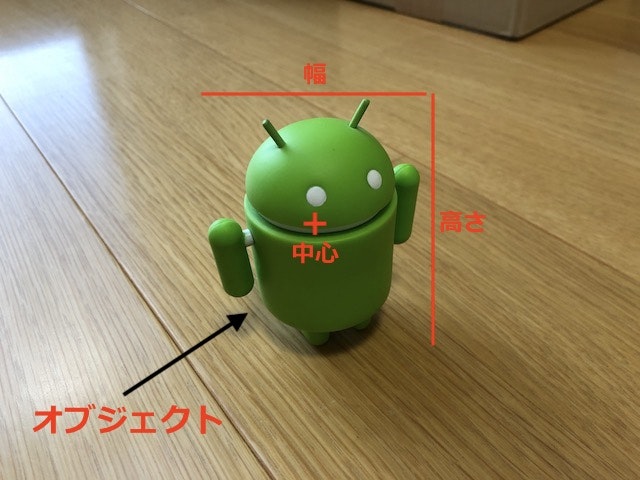
内容例は以下になります。
0 0.31875 0.19375 0.6609375 0.73125
画像リスト
学習させる画像データのフルパス、その一覧を記録したファイルです。
学習データ用、テストデータ用に二種類の画像リストを作成します。
データの書式は以下になります。
data/000/image000_001.jpg
data/000/image000_002.jpg
data/000/image000_003.jpg
.
.
学習データとテストデータを9:1で分けて、それぞれで画像リストを作成します。
- train.txt (学習データ)
- test.txt (テストデータ)
クラスリスト
犬や猫など、物体検出させるオブジェクトの名前を列挙したファイルです。
データの書式は以下になります。
dog
cat
bird
.
.
大量の画像データから、座標データ、画像リストを作成するのは骨が折れます。。。
BBox-Label-Toolというツールを使用すると、楽に作成することができます。
(といってもデータが大量だと、結局大変ですが...)
こちらは、次の機会に記事にしたいと思います。
パス情報を記録したファイル
Darknetで学習を実行する際必要になります。
学習させるオブジェクトが5つある場合、以下のように入力します。
classes= 5
train = data/obj/train.txt
valid = data/obj/test.txt
names = data/obj/obj.names
backup = backup
準備したデータセットを適切な場所に配置
下の例では、Darknet直下にあるdataディレクトリにobjディレクトリを作成して、データセットを配置しています。
$ cd darknet/data/obj
$ ls -l
total ~
-rw-rw-r-- 1 hitaragx hitaragx 110 Jun 15 08:16 obj.data
-rw-r--r-- 1 hitaragx hitaragx 107 Jun 15 06:35 obj.names
-rw-r--r-- 1 hitaragx hitaragx 28121 Jun 12 13:06 image000_001.jpg
-rw-r--r-- 1 hitaragx hitaragx 65 Jun 12 13:06 image000_001.txt
-rw-r--r-- 1 hitaragx hitaragx 31214 Jun 12 13:07 image000_002.jpg
-rw-r--r-- 1 hitaragx hitaragx 67 Jun 12 13:07 image000_002.txt
~
-rw-r--r-- 1 hitaragx hitaragx 42028 Jun 13 02:19 image004_100.jpg
-rw-r--r-- 1 hitaragx hitaragx 59 Jun 13 02:19 image004_100.txt
-rw-r--r-- 1 hitaragx hitaragx 1375 Jun 15 06:35 test.txt
-rw-r--r-- 1 hitaragx hitaragx 12980 Jun 15 06:35 train.txt
これで、学習の準備ができました。
Darknetを実行して学習を開始
準備
学習の前に、学習元のモデルファイルをダウンロードします。
$ wget https://pjreddie.com/media/files/darknet19_448.conv.23
続いて、cfgファイルを作成します。
Darknet直下にあるcfgディレクトリに移動して、ベースとなるcfgファイルをコピーします。
ここでは、「yolov2-voc.cfg」をベースにします。
$ cd darknet/cfg
$ cp yolov2-voc.cfg yolo-obj.cfg
コピーしたcfgファイルを開き、以下のように修正します。
$ vim yolo-obj.cfg
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=8
~
max_batches = 10000 # 学習回数
~
classes=5 #オブジェクトの数
filters=50 #filters=(オブジェクトの数+5)*5
~
# 以下、コメントアウトしておかないと、CoreMLへの変換に失敗します。
< [route]
< layers=-9
<
< [reorg]
< stride=2
<
< [route]
< layers=-1,-3
学習開始
以下のコマンド学習を開始します。
- 通常の実行
$ ./darknet detector train data/obj/obj.data ./cfg/yolo-obj.cfg ./darknet19_448.conv.23
- GPUが複数ある場合(”0,1”で2つのGPUを指すっぽい)
$ ./darknet detector train data/obj/obj.data ./cfg/yolo-obj.cfg ./darknet19_448.conv.23 -gpus 0,1
学習終了
指定回数分、学習実行されると学習が完了します。
Darknetのモデルファイルが作成されているか確認します。
$ cd darknet/backup
$ ls -l
total ~
-rw-rw-r-- 1 hitaragx hitaragx 157680712 Jun 15 10:43 yolo-obj_10000.weights
-rw-rw-r-- 1 hitaragx hitaragx 157680712 Jun 15 08:27 yolo-obj_2000.weights
-rw-rw-r-- 1 hitaragx hitaragx 157680712 Jun 15 08:30 yolo-obj_4000.weights
-rw-rw-r-- 1 hitaragx hitaragx 157680712 Jun 15 08:32 yolo-obj_6000.weights
-rw-rw-r-- 1 hitaragx hitaragx 157680712 Jun 15 08:36 yolo-obj_8000.weights
-rw-rw-r-- 1 hitaragx hitaragx 157680712 Jun 15 10:43 yolo-obj.backup
-rw-rw-r-- 1 hitaragx hitaragx 157680712 Jun 15 10:43 yolo-obj_final.weights
「yolo-obj_final.weights」が、指定した全ての回数を学習した重みモデルファイルになります。
Darknet → Keras
Darknetの作成したモデルファイルをKeras用に変換します。
YAD2Kをインストール
GitHubにあるリポジトリをCloneします。
$ git clone https://github.com/allanzelener/YAD2K.git
Keras用モデルに変換
変換には、weightsファイルの他に、cfgファイルが必要です。
学習時に使用したcfgファイルをコピーして、以下の箇所を修正します。
$ cp yolo-obj.cfg yolo-obj-coreML.cfg
$ vim yolo-obj-coreML.cfg
# Testing
batch=1
subdivisions=1
# Training
# batch=64
# subdivisions=8
~
YAD2Kを実行して、Keras用モデルファイル(.h5)に変換します。
$ ./yad2k.py yolo-obj-coreML.cfg yolo-obj_final.weights yolo-obj_final.h5
yad2k.py実行時に、warningが出る場合は、yad2k.py内の下記を修正してから実行してください。
# 修正前
weights_header = np.ndarray(
shape=(4, ), dtype='int32', buffer=weights_file.read(16))
# 修正後 16を20に
weights_header = np.ndarray(
shape=(4, ), dtype='int32', buffer=weights_file.read(20))
Keras用モデルファイル「yolo-obj_final.h5」が作成できました。
Keras → CoreML
Keras用モデルファイルが作成できたら、続いてCoreML用モデルファイルを作成します。
CoreMLToolsをインストール
$ pip install -U coremltools
CoreML用モデルに変換
変換用のスクリプトを作成します。
import coremltools
# Yoloの Keras用モデルファイルを指定
coreml_model = coremltools.converters.keras.convert(
'./yolo-obj_final.h5',
input_names='image',
image_input_names='image',
output_names='grid',
image_scale=1/255.)
coreml_model.input_description['image'] = 'Input image'
coreml_model.output_description['grid'] = 'The 13x13 grid'
# CoreMLモデルファイルの出力先を指定
coreml_model.save('./yolo-obj_final.mlmodel)
スクリプトを実行して、CoreMLモデルを作成します。
$ python yolo2coreml.py
CoreML用モデルファイル「yolo-obj_final.mlmodel」が作成できました。
参考にしたサイト
YOLO: Real-Time Object Detection(YOLOv2)
[YOLOv2を独自データセットで訓練する]
(https://qiita.com/MOKSckp/items/061d2d0dfacf1fa8a83d)
[CUDA 8.0とcuDNN 6をUbuntu 16.04LTSにインストールする]
(https://qiita.com/JeJeNeNo/items/05e148a325192004e2cd)
[YOLOv2(Keras / TensorFlow)でディープラーニングによる画像の物体検出を行う]
(https://qiita.com/yampy/items/7a705acf4c6899bc11c7)
[YOLO: Core ML versus MPSNNGraph]
(http://machinethink.net/blog/yolo-coreml-versus-mps-graph/)
[CoreML conversion fails due to Lambda layer #80]
(https://github.com/allanzelener/YAD2K/issues/80)