TL;DR
入社当初、社員10-20名の小さいスタートアップでプロダクトのデータをもろもろまとめたい、ディレクター職や何か数値をまとめたいときに簡単に低予算、手間かけないで分析基盤を用意したことをおさらいします
背景
Moff AdventCalender第4号は私が入社してすぐに取り掛かったことで、低予算+抵工数の分析基盤作りについて紹介します。どういう変遷だったか詳しくは覚えていないんですが、Moffが介護事業所や医療機関に提供するサービスでは、MoffBandを装着したユーザーが、あるトレーニング・動作を実施することで、そのトレーニング結果・動作結果(可動域の角度や速さ、回数、腕振りの腕の向きデータや歩行のバランスにまつわる数字データetc)を記録しております。
また、初期ローンチを少人数でカバーするために当時Serverless(API Gateway + Lambda + DynamoDB、ところによりKinesis Data Stream)にてプロダクトをリリースしてたので、ユーザーデータ含め、運動動作にまつわるデータは全てKVS(DynamoDB)で管理されておりました。
「このような運動データはいずれマーケティングデータとは違った価値がでてくるだろう」と自分的になんとなく思っていた節もあり、すぐにいろいろデータみてみたいよね、って話が入社当初からあったので、そこの基盤づくりを手早くやろうと思い、入社早々に取り組んだので、少しのHowとそれまでに必要だったスキルセットを紹介しようと思います。
低予算・低工数・低コスト
「データをすぐみたい!」と経営陣から煽られた要請もありましたが、自身の経験として、プロダクトのデータの可視化はリリースされているならあるべきでしょ、くらいには思っていました。ただ、正直「データをみる」だけのためにしぼっていちいち時間かけて重厚なシステム作っても意味あんのかしら?とすこし懐疑的でもあったので、持っている技術であまり考えることを多くせずにやってみようというかんじですすめました。
当時データを集計してまとめられる作業ができたのは自分一人だけだったので、基本的に分析の作業があるのも自分のみが対応、経営層から何かあったとしても当時はせいぜい月に2、3リクエスト程度だったため、この「月に2、3」を運営コストとして定義し、必要以上にお金がかからないが、やりたいことはだいたい数字周りをチェックできることや、そこから追加分析しやすい状況がつくれればいいかな、くらいに思っておりました。
要件と設計・前提条件
Moffのサービスは基本的にServerlessで構成しているため基本DynamoDBを多用している(Serverless構成でも十分サービスとして耐えうる)ので、DynamoDBをとりあえずローカルに保存するスクリプトが必要でした。
boto3のDynamoDBの仕様(というかAWSが提供しているSDK等)より、一括でDBからデータを取得できるバッチを用意しました。
とりあえず作る
とりあえず形にするところからということで
- DynamoDBからデータを全て抜き出す
- 抜き出したデータを分析しやすい形に整形する
- 整形したデータをBigQueryにimportする
をローカルPCからできるようにしていこうと思います。
DynamoDBから一括でデータを抜き出す
DynamoDBは容量にもよりますが1回のリクエストで1MBまでのデータを引っ張るしかできないため、それ以上の容量を取得するには実質複数回リクエストを投げる形(厳密には一度のscan()を実行し、LastEvaluatedKeyを含む結果を元に、再度scan()を発行する)になります。
後々のデータの整形のことを考えて、プログラム上で扱いやすいライブラリ(Pandas)を使用することを想定してPythonで実装しました。(ぶっちゃげやりやすければなんでもいいとは思うけど)
(下記はあくまでサンプルコードです。)
まずはローカル用のバッチを作るので、AWSとProfileとテーブル名を指定できる様にしておきます。
import argparse
import pandas as pd
from boto3.session import Session
parser = argparse.ArgumentParser()
parser.add_argument('-p', '--profile', type=str, required=True,
help='input aws profile name (DO NOT USE DEFAULT PROFILE)')
parser.add_argument('-t', '--table', type=str, required=True,
help='input dynammodb table name')
# debug用
parser.add_argument('-c', '--count', action="store_true",
help='output # of scaned data.')
args = parser.parse_args()
profile = args.profile
table_name = args.table
counting = args.count
session = Session(profile_name=profile)
client = session.client('dynamodb')
# CSVに出力するためのファイルパス
file_path = 'output/' + table_name + '.csv'
print('table: ' + table_name)
# ※Scanなので、深夜実行前提とする
response = client.scan(TableName=table_name)
DynamoDBでは一度にScanできる容量は限られている(1MBまで)のでデータを読み切るまで何回もアクセスする必要があります。
どこかの変数に固めることにはなってしまいますが、処理を書いてループで取得させます。
(計算量がO(n)にはなりますが一旦無視)
while 'LastEvaluatedKey' in response:
response = client.scan(
TableName=table_name,
ExclusiveStartKey=response['LastEvaluatedKey']
)
responseの内容は基本的にはDict型なのでappendするなりして退避したあと、Pandasに読み取らせてCSV出力しちゃいます。DynamoDBでリスト形式でレコードが返ってくるんですが
{'key': {N:Decimal(1)}}みたいに、value部分が型をキーとて値を返す形式になっているので、このままではPandasを読み取れないので、せめて{'key': Decimal(1}}みたいな形に変換して対処します。
# Pandasで読み取れるDictに変形するための関数を用意
# DynamoDBで返却されているデータ型がリストだったり辞書だったりは一旦文字列にしてしまっている
def _upper_key(dictionary):
new_data = {}
if type(dictionary) == dict:
for key, value in dictionary.items():
if type(value) == dict:
new_data[key.upper()] = _upper_key(value)
elif type(value) == list:
new_list = []
for obj in value:
new_list.append(_upper_key(obj))
new_data[key.upper()] = new_list
else:
new_data[key.upper()] = value
return new_data
else:
return dictionary
def _transform_data(record):
tmp_data = {}
new_record = {}
for key, value in record.items():
if type(value) == dict:
tmp_data[key] = _upper_key(value)
for key, val in tmp_data.items():
if list(val.keys()).pop() == 'N':
new_record[key] = str(list(val.values()).pop())
elif list(val.keys()).pop() == 'L':
list_data = []
for obj in list(val.values()):
for v in obj:
if list(v.keys()).pop() != 'M':
list_data.append(str(list(v.values()).pop()))
new_record[key] = ','.join(list_data)
else:
new_record[key] = list(val.values()).pop()
return new_record
# dict型の内容をPandasで読み取れる様に整形(_transoform_data())
new_records = []
for item in response['Items']:
new_records.append(_transform_data(item))
new_data = pd.DataFrame(new_records)
for column in new_data.columns:
new_data.rename(columns={column: column.upper()}, inplace=True)
new_data = pd.DataFrame(new_records)
for column in new_data.columns:
new_data.rename(columns={column: column.upper()}, inplace=True)
# 初期時はファイルが存在しないので、一旦書き出し、そのあとは書き出したファイルに付け足す形
if initialize_flag:
new_data.to_csv(
file_path, mode='w', index=False,
sep=',', header=True
)
else:
old_data = pd.read_csv(file_path)
merged_data = pd.concat([new_data, old_data])
merged_data.to_csv(
file_path, mode='w', index=False,
sep=',', header=True
)
3年前くらい?だったんですけど今見返すともっといい方法ありますね。。。
https://stackoverflow.com/questions/45636460/use-pythons-pandas-to-treat-aws-dynamodb-data
BigQueryにimportする
本当は色々考える分には中間で加工したテーブルを用意してもよかったかもしれませんが、
まずは地でそのままimportしてしまいます。
CSV形式で整形されたテーブルをimportしますが、BigQueryのAPIを叩く設定を入れる必要があるので、
それを行う必要があります。
gcloudよりbigqueryにてバッチ実行できるよう設計しました。
(下記はサンプルコードです)
import os
import sys
import json
import codecs
import pandas as pd
from gcloud import bigquery
from gcloud.bigquery import SchemaField
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--dataset', type=str, required=True,
help='input dataset name')
parser.add_argument('-t', '--table', type=str, required=True,
help='input table name')
parser.add_argument('-f', '--file', type=str, required=True,
help='input file path')
args = parser.parse_args()
data_set = args.dataset
table_name = args.table
file_path = args.file
private_key = os.environ.get('JSON_PATH')
bq_client = bigquery.Client.from_service_account_json(
private_key,
project=os.environ.get('PROJECT_NAME')
)
dataset = bq_client.dataset(data_set)
table = dataset.table(name=tale_name)
if table.exists():
table.delete()
# schemaは各テーブル別々で読み取らせるとより良いかも
# (サンプルコード様にコード用意するのが煩雑だったので実運用のコードを少し改悪しています。)
table.schema = {
"schema": {
"fields": [
{
"mode": "NULLABLE",
"name": "CREATED_AT",
"type": "TIMESTAMP"
},
.
.
.
},
"tableReference": {
"datasetId": "Check",
"projectId": "moff-bq-sync-170707",
"tableId": "TUG"
},
"type": "TABLE"
}
table.create()
with open(file_path, 'rb') as f:
table.upload_from_file(
f, 'CSV', field_delimiter=',', skip_leading_rows=1,
ignore_unknown_values=False
)
Tableauで可視化
非エンジニアのことを考えてTableauを導入しました。BigQueryもS3も対処できますが、料金的には月次での無料枠が割り当てられているBigQueryを採用しています。(BigQuery周りは今でも料金的には無料枠の範囲内でおさまってはいる)
あとはTableauからアクセスするだけ
個人情報に関して
基本的は社内内部にての扱いに限定しているものの、ゆくゆくいろんなパートナーさんと分析業務をやっていくことを考えると、個人情報の取り扱いになるので、結構慎重にならなければなりません。
データ整形時にデータとして伏せたい該当カラムを削除することで解消させました。
一番ベストなのはエクスポートする時点でboto3よりAttirubuteを指定してあげればいいんですが。
これだけ?
これだけだと、いちいち自分でスクリプト実行してアップロードする作業しなければデータが最新にならんので、ちょっと辛いわけです。でもここまでやって分析の頻度が月2、3回程度であればこれでも十分かなと思います。タイトルの通り「片手間で手抜き」なので。
Pythonとboto3の扱い方とDynamoDBへのそれなりの理解だけで抽出作業部分は実装できるかと思います。
import部分はBigQuery周りの知見がいるのでちょっと面倒かもしれませんね。
一方、サービス自体はセールスチームが顧客折衝してお客さんをデータが多くなればなるほどサービス運営することも踏まえてこの処理系統はいずれどこかで作業的に頭打ちになることは間違い無いでしょう。手動運用ほど辛いものはありません。
そこでStepFunctionである程度分散制御できる仕組みを用意して対処することにしています。
自動化のためのアーキテクチャ
基本的には、
- Lambdaより定期時刻にStepFunctionを実行
- StepFunctionを起動
- AWS内でデータ整形、import処理までをStepFunctionsで制御
- 途中、中間DBみたいなことを想定してセカンドステップも用意している
- 以降Google Cloud StorageにてCloud FunctionベースでBigQueryにimport
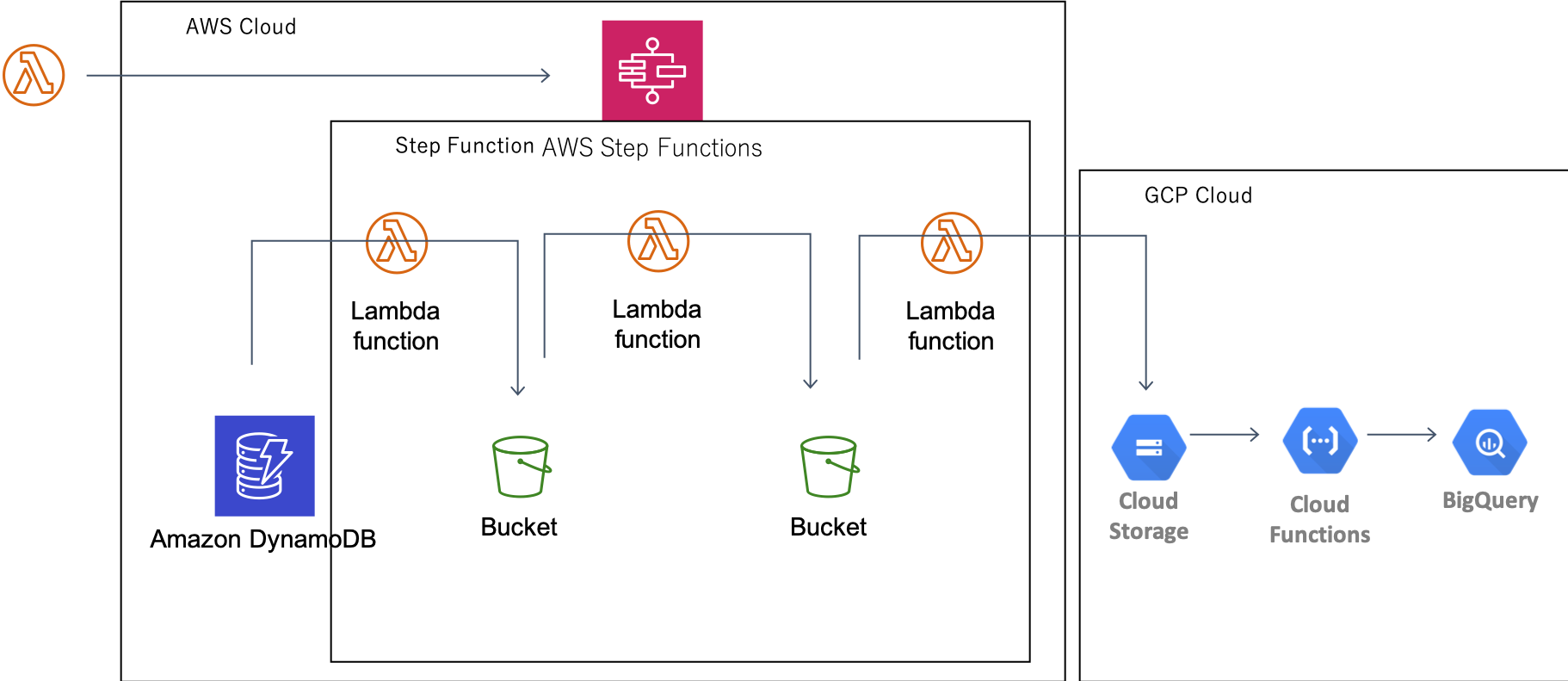
これでAWSのデータからGCPまでをこれでデータを入れられるようにしました。
可視化
可視化に関しては割愛させてもらいます。とりあえずSlackでレポート流すくらいはやってますが、工夫ポイントがなさすぎるのでなしです。
2年半経過した今となっては
入社して、S3からアクセスさせるとお金が普通に発生するので初期コストで一定容量まで無料に惹かれてBigQueryを採用していますが、自動化した今では、ここに1秒間20レコード程度発生するセンサーデータなどを分析できる様に拡充することを考えると、正直GCSに配置するだけで将来的に結構料金かかるんじゃないの?みたいな話があり、管理のことも考えてAWS一本にしてもいい気がしています。そろそろこれも工事をしなければいけないなあとか思っています。
と、最初作って普通に運用してものの2年で振り返ってみるとちょっと古く感じるのは時代の流れを感じさせます。
加えて2年も同じシステムを使っていることを考えてみると、自身のスキルが固定化されている気がするので、1年に1回でもアップデートしていくようなことは、タスクとしては微妙かもしれないけどやっておいて損ではないというのも感じました。
まとめ・展望
- お手軽手抜きでデータ分析できる基盤を用意するメソッドを紹介しました。
- ローカルから開発して、最終的にAWSの部分を自動化しました。
- データ処理時間はちょっと対策を考えなければいけない。
- 諸々古いところもあるのでアップデートしたいなあ
膨大なデータ量になって、分析需要が増えてきたらこのアーキテクチャは破棄することになるかもしれませんが、費用的で損益分岐点みたいなところにさしかかってからの変更でもいいのかなと思ったりしています。ありがとうございました。