PyTorch全盛の今ですが、よわよわAI人材としてはkerasの使いやすさは捨てがたい、TensorFlowが2.0になりkerasが統合されたなら試してみなきゃ!ということで試してみました。
ソースは GITHUB で公開しています。Google Colaboratory で実行可能です。
import
Google Colaboratory ではまだデフォルトのTensorFlowは1.xなので、2.0に変更してインポート(近々デフォルトがアップデートされる予定のようです。)
try:
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
Data
MNISTを使います。mnist を fashion_mnist に変更すれば FashionMNISTで実行できます。
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure()
plt.imshow(x_train[0])
plt.colorbar()
plt.show()
/255 します。
x_train, x_test = x_train / 255.0, x_test / 255.0
MNISTの画像を確認
plt.figure(figsize=(8,8))
for i in range(4*4):
plt.subplot(4,4,i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_train[i], cmap=plt.cm.binary)
plt.xlabel(y_train[i])
plt.show()

Model
CNNですらない、シンプルなモデルで試します。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 128) 100480
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
Train
学習します。
history = model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
Train on 60000 samples, validate on 10000 samples
Epoch 1/5
60000/60000 [==============================] - 6s 97us/sample - loss: 0.2945 - accuracy: 0.9140 - val_loss: 0.1456 - val_accuracy: 0.9568
Epoch 2/5
60000/60000 [==============================] - 5s 86us/sample - loss: 0.1450 - accuracy: 0.9563 - val_loss: 0.1032 - val_accuracy: 0.9687
Epoch 3/5
60000/60000 [==============================] - 5s 86us/sample - loss: 0.1074 - accuracy: 0.9676 - val_loss: 0.0854 - val_accuracy: 0.9741
Epoch 4/5
60000/60000 [==============================] - 5s 84us/sample - loss: 0.0884 - accuracy: 0.9726 - val_loss: 0.0794 - val_accuracy: 0.9759
Epoch 5/5
60000/60000 [==============================] - 5s 85us/sample - loss: 0.0754 - accuracy: 0.9772 - val_loss: 0.0763 - val_accuracy: 0.9776
history はこんな感じで記録されます。
history.history
{'accuracy': [0.91398335, 0.95626664, 0.96756667, 0.97263336, 0.97723335],
'loss': [0.29453386657238007,
0.14502795292908946,
0.10736251953157286,
0.08835241570609312,
0.0753600429897507],
'val_accuracy': [0.9568, 0.9687, 0.9741, 0.9759, 0.9776],
'val_loss': [0.14558823936395346,
0.10317659587264061,
0.08543990215128287,
0.07936833947175183,
0.07629033072737511]}
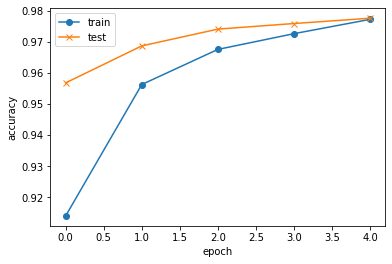
学習の推移を確認
plt.plot(history.history["accuracy"], label="train", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="test", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
Test
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=1)
10000/10000 [==============================] - 1s 65us/sample - loss: 0.0763 - accuracy: 0.9776
結果をいくつか確認しましょう。
import numpy as np
plt.figure(figsize=(16,16))
for i in range(10):
plt.subplot(1, 10, i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_test[i], cmap=plt.cm.binary)
plt.xlabel(y_test[i])
plt.show()
print(np.argmax(model.predict(x_test[0:10]), axis=1))
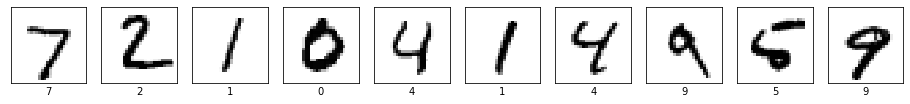
[7 2 1 0 4 1 4 9 5 9]
10個全部あってます。
混合行列で確認
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm = confusion_matrix(y_test,np.argmax(preds,axis=1))
plt.figure(figsize=(16,8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.show()
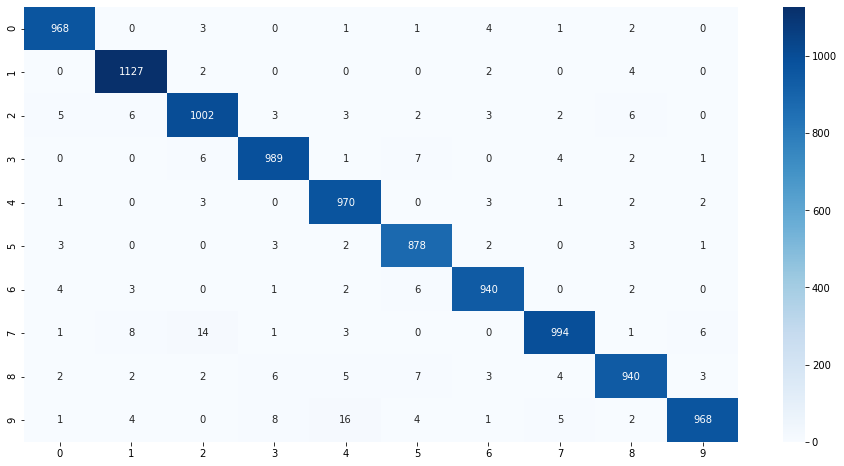
今気づきましたが、MNISTのtestって1,000枚ずつじゃなかったんですね。