概要
PostgreSQLからBigQueryにデータを転送する際、転送の設定が複雑で面倒に感じることがあるかもしれません。
そこで、今回はtroccoというETL & ワークフローサービスを使い、CDC形式で転送する方法をご紹介します。
CDC形式を取り入れることで、効率的で低レイテンシなデータ転送を実現できます。

1-0. CDCとは?
今回はPostgreSQLのWALをCDC(Change Data Capture = 変更データキャプチャ)形式で転送します。
これにより、初回のみ全件転送、それ以後は差分転送をして、転送量の削減・転送の高速化を図ることができます。
DBへの負荷を抑えつつバッチ処理でのデータ同期を行いたいときには、CDC形式での転送がうってつけです。
全件転送との比較は以下の通りです。
| 全件転送 | CDC | |
|---|---|---|
| trocco転送量(初回実行時) | ソーステーブルの全データ | ソーステーブルの全データ |
| trocco転送量(2回目以降) | ソーステーブルの全データ | 更新ログのみ(※1) |
| スキーマ変更発生時 (列追加等) |
自動追従 | 自動追従 |
| データ削除(DELETE)の挙動 | 物理削除 | 論理削除 |
| データ更新(UPDATE)の挙動 | 物理更新 | 物理更新 |
| BigQueryスキャン量 | なし | 現在のBigQuery上のテーブル全量+更新ログ |
| データソースDBへの負荷 | 高 | 低(初回転送時のみ全量のため高負荷) |
※1 INSERT,DELETE,DDL文については1行文、UPDATE文については更新前後の2行分
troccoでCDC転送をする際には
(1)troccoがPostgreSQLのWALをBigQuery上に転送
(2)WALのデータから重複を排除し、それぞれのレコードの最新のレコードの集合を作成
(3)↑の集合を現在のBigQueryテーブルとマージし、マージ後のテーブルで置換する
という手順を踏んでいます。
2-1. MySQLのパラメータ設定
troccoのドキュメントを参照しつつ、PostgreSQLのパラメータ設定をします。今回はRDSを使っていますので、AWSのコンソールから環境変数を確認します。
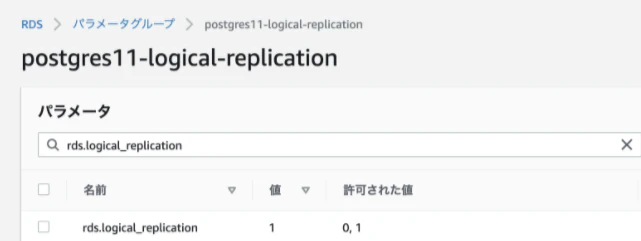
rds.logical_replicationは1に設定されています。
max_replication_slotsとmax_wal_sendersも連携するテーブルの数と同じになっていることが確認できたので、このまま次のステップに進めます。
2-2. Slotの作成
troccoのドキュメントを参照しつつ、Slotの作成をします。
SUPERUSERでログイン後、下記SQLでスロットを作成してください。
SELECT * FROM pg_create_logical_replication_slot('trocco_<table_name>', 'wal2json');
作成後、下記のSQLでSlotからデータが取得できるかの確認ができます。
SELECT COUNT(*) FROM pg_logical_slot_peek_changes('<replication_slot_name>', null, null);
2-3. PostgreSQLの権限設定
troccoのドキュメントを参照しつつ、PostgreSQLの権限設定をします。
ここではCONNECT, USAGE, SELECT, rds_replication, ALTER DEFAULT PRIVILEGES の5つの権限を設定します。
(rds_replicationは、RDSの場合のみ必要となります)
GRANT CONNECT ON DATABASE <database_name> TO <username>;
GRANT USAGE ON SCHEMA <schema_name> TO <username>;
GRANT SELECT ON <schema_name>.<table_name> TO <username>;
GRANT rds_replication TO <username>;
ALTER DEFAULT PRIVILEGES IN SCHEMA <schema_name> GRANT SELECT ON TABLES TO <username>;
2-4. Primary Keyの設定
転送元のテーブルにはPrimary Keyが設定されている必要があります。
ここでは既に設定されているものとして、割愛します。
その他、troccoで転送する際の必須条件などについてはこちらのドキュメントを参照してください。
これにてPostgreSQL側での設定は完了です。
次に、troccoの設定をします。
3-0. troccoに登録
troccoのアカウントが必要です。
フリープランがありますので、前もって申し込み・登録をしておいてください!
https://trocco.io/lp/inquiry_free.html
3-1. 転送元・転送先を決定
troccoにアクセスし、ダッシュボードから「転送設定を作成」のボタンを押します。
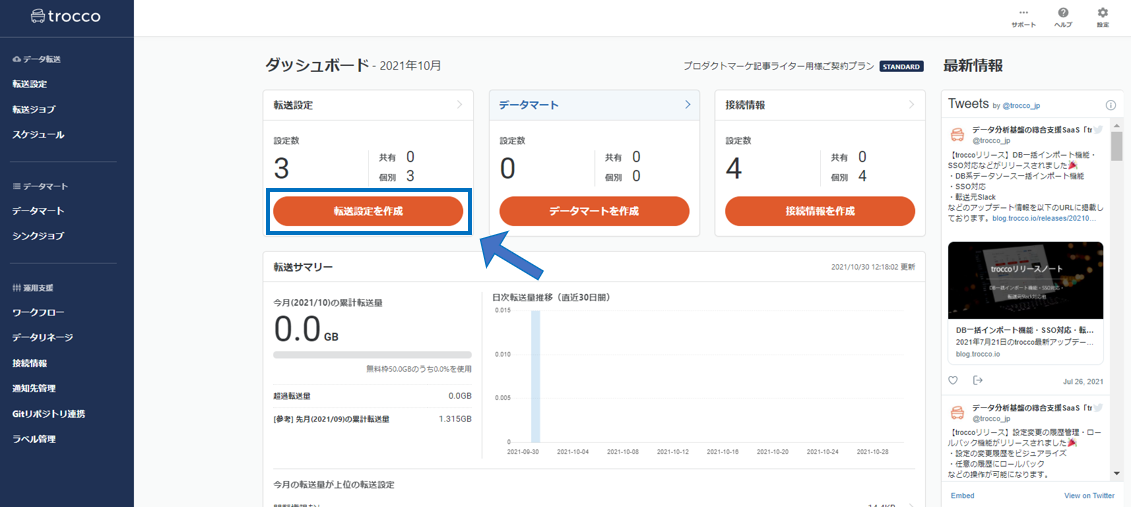
転送元にPostgreSQL WAL(CDC)、転送先にBigQueryを選択し、転送設定作成ボタンを押します。
すると、設定画面になるので、転送に必要な情報を入力していきます。
3-2. PostgreSQLとの連携設定
転送設定の名前とメモを入力します。
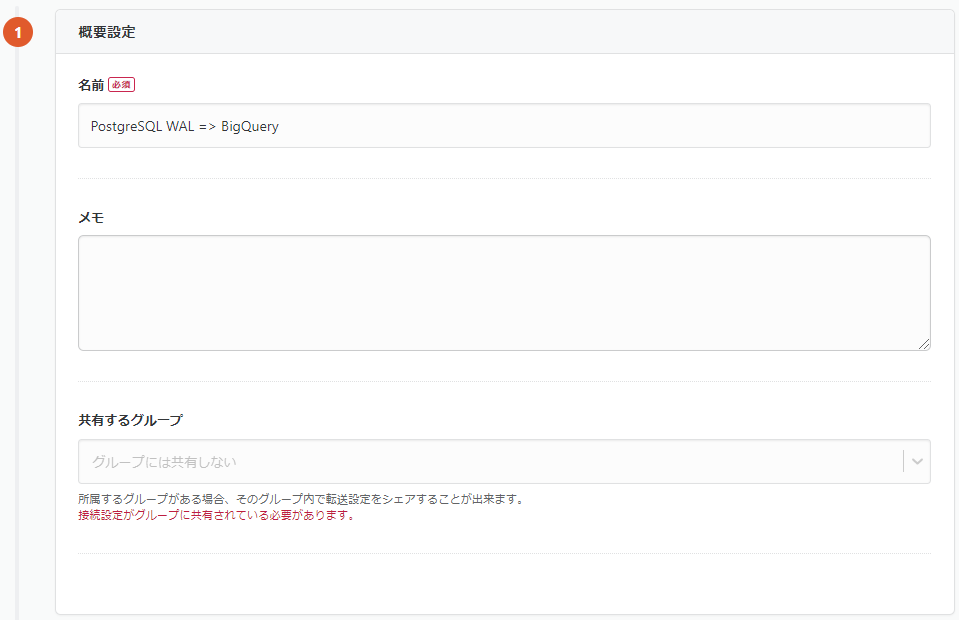
転送設定の名前を決めたら、「転送元の設定」内の「接続情報を追加」ボタンを押し、PostgreSQLの接続情報の設定をします。

接続設定の名前・ホスト・ポート・ユーザー名・パスワードを入力します。
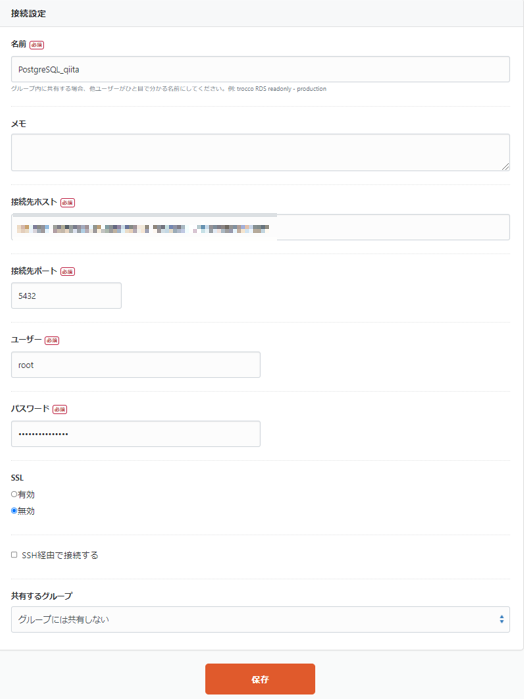
入力をしたのち、設定の保存をします。

再び転送設定画面に戻り、「接続情報を読み込む」ボタンを押すと、作成した接続情報が選択できます。
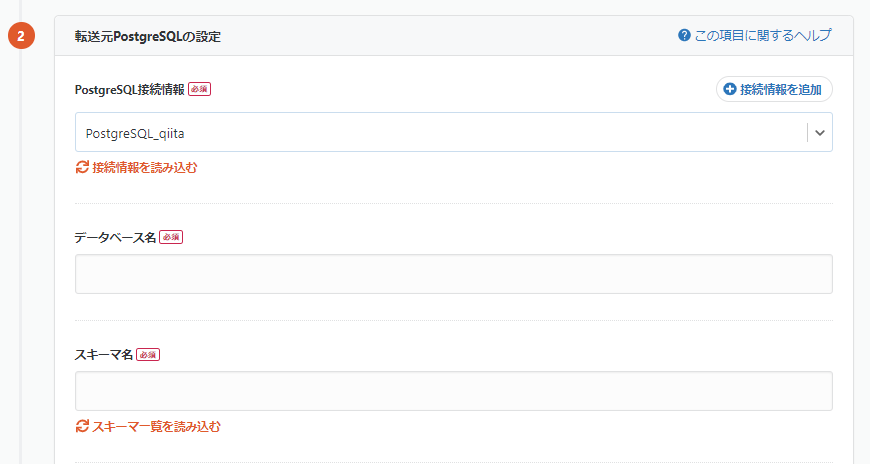
3-3. PostgreSQLからのデータ抽出設定
これでPostgreSQLとの連携は完了です。
次に、PostgreSQLの取得データを設定します。
まずは必須項目の「データベース名」「スキーマ名」「テーブル」「スロット」をセレクトボックスの中から選択します。

次に、スキーマ追従の有効/無効を指定します。

スキーマ追従が有効になっている場合、
- クエリにRENAME COLUMNが含まれている場合、変更後の名前でデータ連携される
- クエリにADD COLUMNが含まれている場合、追加したテーブルが自動で転送されるようになる
といった挙動になります。
最後に接続確認が通るか確認します。
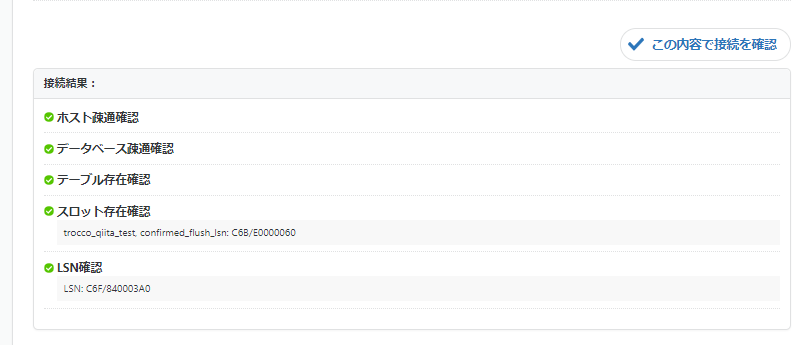
大丈夫ですね。以上でPostgreSQL側の設定は完了です。
次は転送先のBigQueryの設定をしていきましょう。
3-4. 転送先BigQueryの設定
「接続情報を追加」ボタンからBigQueryの接続設定を行います。名前と、認証方式としてサービスアカウント(JSONキー)を入力します。

JSONキーの取得方法についてはこちらのドキュメントを参照してください。
「接続情報を追加」ボタンからBigQueryの接続設定を行い、データベース・テーブル・データセットのロケーションを指定します。
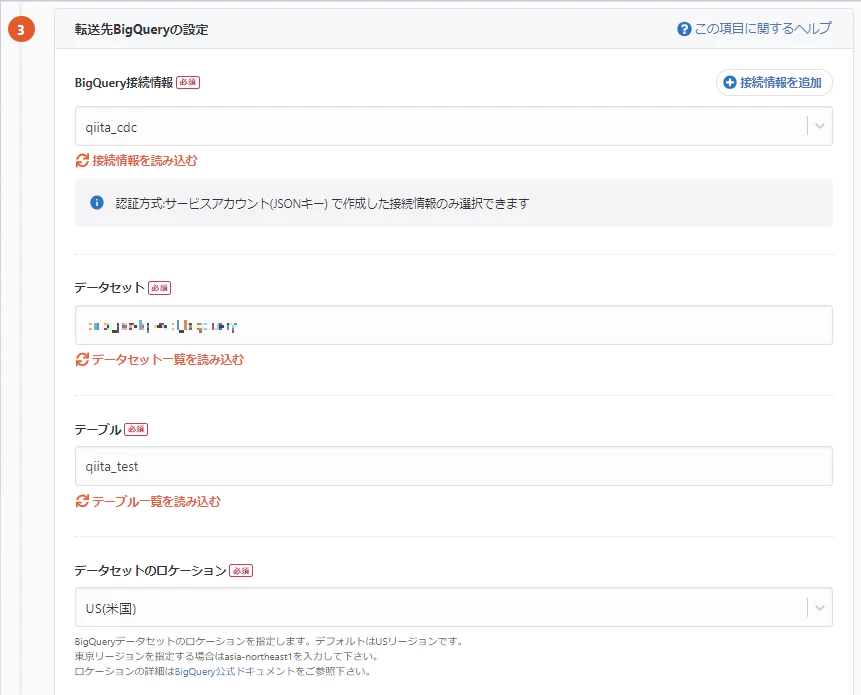
最後に、接続確認が問題なく通るか確認します。
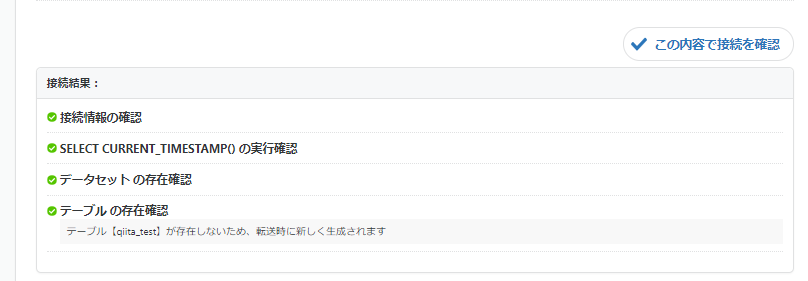
これで入力は完了です。「次のステップへ」をクリックして次に進みましょう。
3-5. カラム名・データ型の確認
「データプレビュー」の画面でカラム名・データ型の確認をします。
PostgreSQLのデータは自動的にBigQueryのデータ型に変換されます。
データ型についてはこちらのドキュメントをご参照ください。
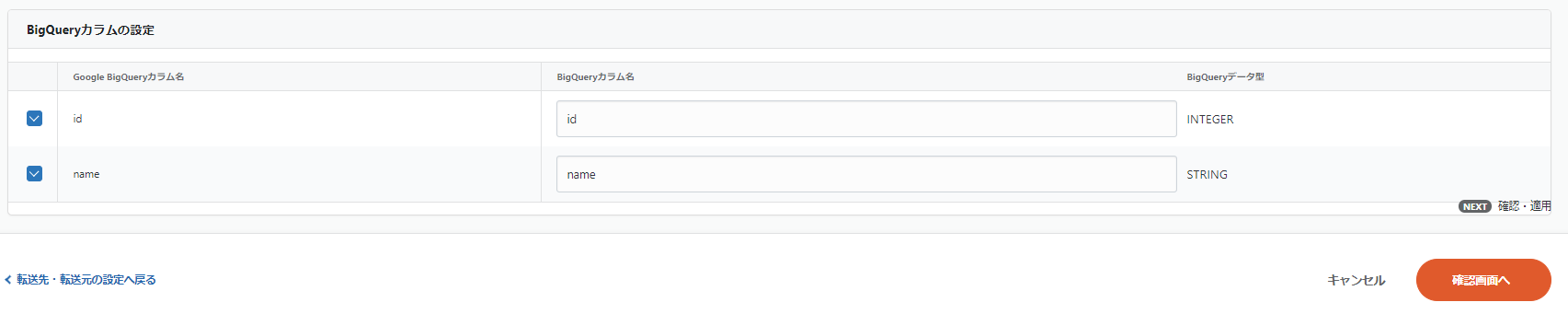
問題なければ、確認画面に移り、保存して適用しましょう。
3-6. 初回転送
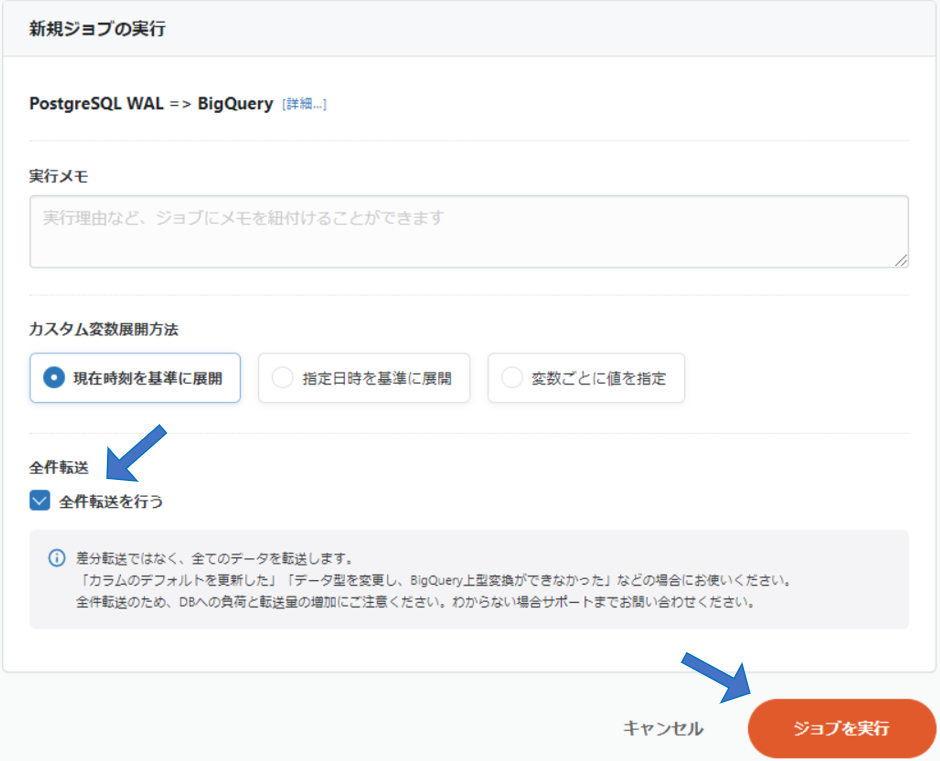
CDCは変更データのみを転送する方式ですが、初回だけは全件転送をする必要があります。
このステップでは、手動で全件転送をします。
右上にある「実行」ボタンを押します。

「全件転送を行う」にチェックマークを入れて、「ジョブを実行」を押します。
転送完了まで待ちます。

転送が成功しました。これで初回の全件転送は完了です。

次に、次回以降に行うCDC転送の設定をします。
転送設定の詳細画面に戻りましょう。
3-7. スケジュール設定
「スケジュール・トリガー設定」タブを開き、スケジュールを追加します。
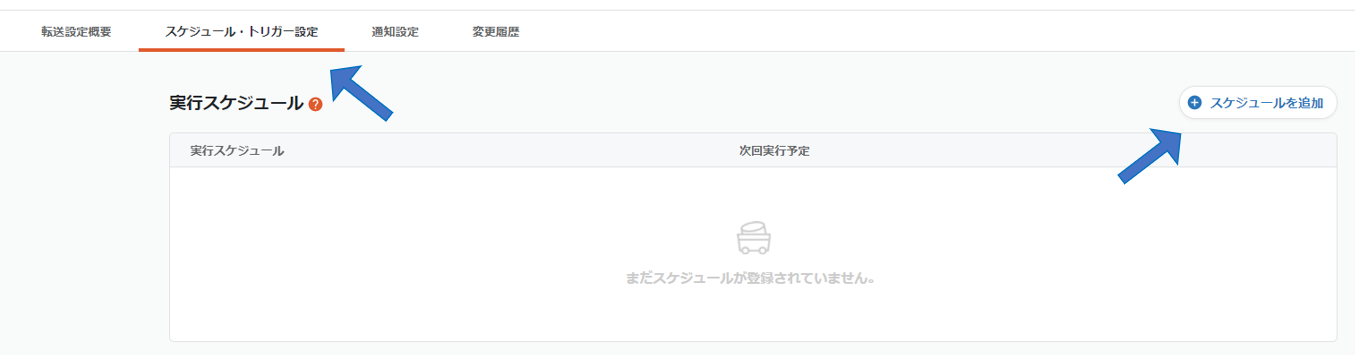
以下のように実行スケジュールを設定することで、転送を自動化することが出来ます。

3-8. 通知設定
必須の設定ではないですが、ジョブの実行ステータスに応じてEmailやSlackに通知することが出来ます。
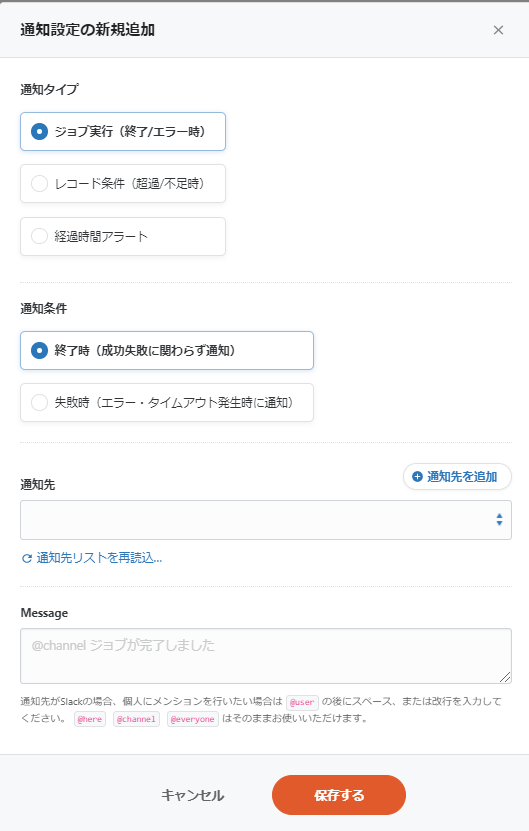
ここまでで全設定が完了しました。
これ以降は、設定したスケジュールに合わせてCDC転送が実行され、差分のデータがBigQueryへ統合されるようになります。
4-1. 転送結果の確認
最後に、PostgreSQLのデータがBigQueryに統合できているか確認してみます。
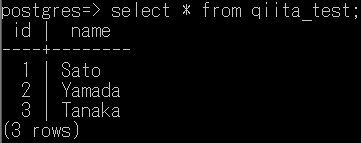
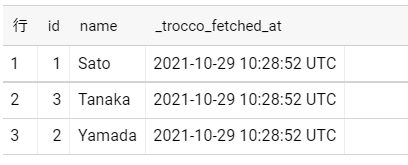
両方とも同じデータが入っていることが確認できますね。
ここで、元のテーブルにいくつか変更を加えて、BigQuery側でどのように表示されるのかを確認してみましょう。
DELETE FROM qiita_test WHERE id = 1;
INSERT INTO qiita_test VALUES (4, 'Kimura');
ALTER TABLE qiita_test ADD NewColumn VARCHAR(20) NULL;
id=1 の行を削除
id=4 の行を追加
新たに「NewColumn」のカラムを追加
この3点が変更されています。
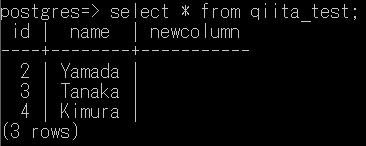
このようにMySQLのテーブルに変更を加えたうえでCDC転送をすると…
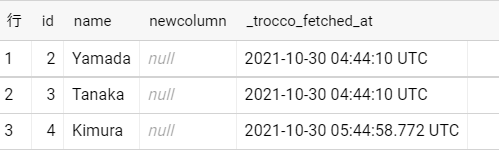
先ほどのクエリで変更した部分がBigQueryでも反映されていることが分かります。
今回は「スキーマ追従」の設定を有効にしているのでカラムの追加が反映されていますが、スキーマ追従が無効の場合には反映されないのでご注意ください。
4-2. おわりに
転送が不要になりましたら、「2-2. Slotの作成」で作成したスロットを削除してください。
スロットを削除し忘れた場合、WALがストレージを圧迫してDBがクラッシュする可能性があります。
まとめ
いかがでしたでしょうか。troccoを使うと、簡単にPostgreSQLのデータを取得し、DWH(BigQuery)に貯めることが出来ました。
ぜひデータ分析の際にご活用ください。
troccoを試してみたい場合は、フリープランがありますので、この機会にぜひ一度お試しください。
その他にも様々な分析データをETL・転送した事例をまとめています。ご活用ください。
troccoの使い方まとめ(CRM・広告・データベース他)