概要
- PostgreSQLからBigQueryへデータを転送し、分析に使いたい
- 出来るだけ手軽に・簡単に・3分くらいで実現したい
- 分析基盤向けデータ統合サービス「trocco」を使って実現してみる
※MySQL→BigQueryのデータ統合は、こちらの記事にあります
その他にも広告やデータベースなど、様々な分析データをETL・転送した事例をまとめました。
troccoの使い方まとめ(CRM・広告・データベース他)
troccoとは
https://trocco.io/lp/index.html
- 分析基盤向けのデータ統合サービス
- 分析に必要な様々なデータ(DB/ストレージ/SaaS/API)を、DWHに統合可能
- DWH自体の管理機能や、運用保守サポート機能も豊富
用意するもの
- PostgreSQL接続情報(転送元テーブルへの読み取り権限が必要)
- 接続先ホスト(例
trocco.hogehoge.ap-northeast-1.rds.amazonaws.com) - 接続先ポート(例
5432) - 接続ユーザー(例
readonly_user) - 接続パスワード(例
hogehoge) - BigQuery接続情報(転送先データセット・テーブルへの書き込み権限が必要)
- JSON Key(例
{''private_key_id'': ''123456789'', ''private_key'': ''-----BEGIN PRIVATE KEY-----...'', ''client_email'': ''...''})
- JSON Key(例
- S3のセキュリティ設定
-
troccoは
18.182.232.21113.231.52.1643.113.216.138の3つのIPアドレスでS3に接続します - ポリシー等でIP制限等を行っている場合は、こちらのIPを許可しておいてください。
-
troccoは
-
troccoの登録
- 無料トライアルもやっているみたいなので、事前に申し込み・登録しておいてください!
- 申込時に、この記事を見た旨を記載して頂ければご案内がスムーズです
1. 転送設定を作成する
1-1. 転送元・転送先を決定
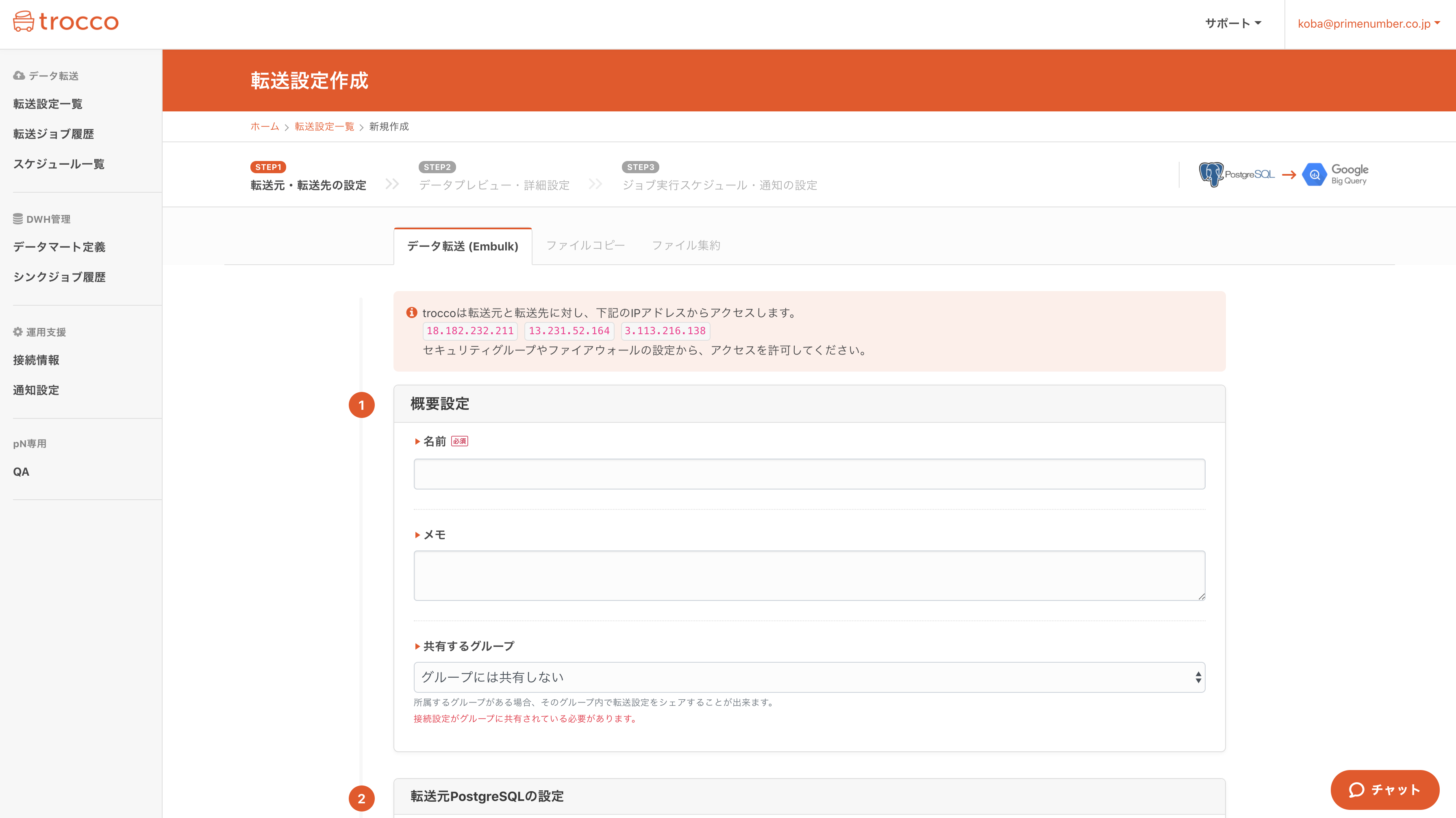
トップページより、転送元にS3を、転送先にBigQueryを選択し、転送設定作成ボタンを押す
すると、以下のような画面になるかと思いますが、これが設定画面です。
わからないことは右下のチャットで、直接聞いたりSlackのサポートから問い合わせることが出来ます。
1-2. 接続設定を作成
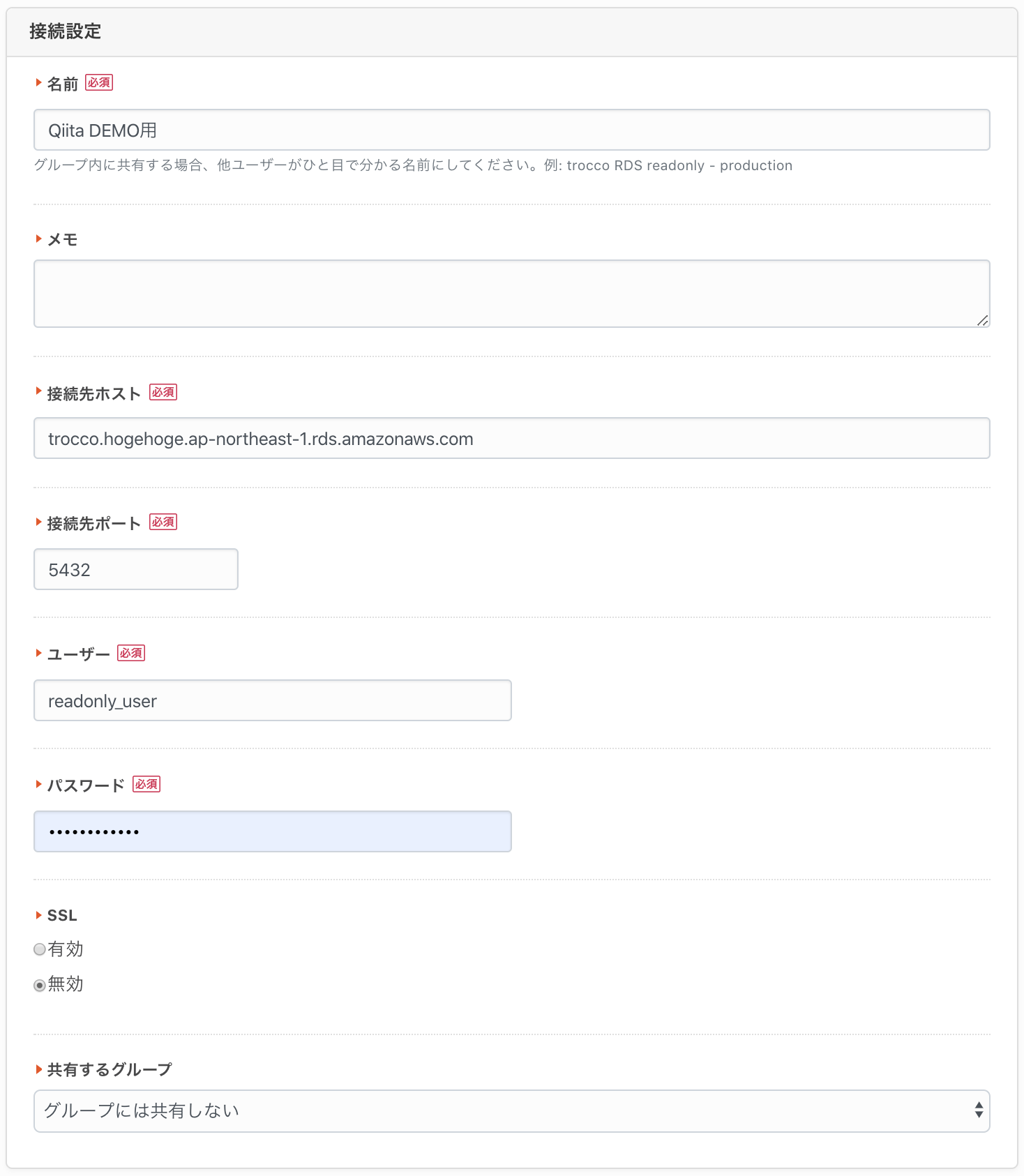
転送設定の名前とメモを適当に入力したら、「転送元の設定」内の「接続情報を追加」ボタンを押します。

別タブで接続情報の新規作成画面が開きますので、予め準備した接続情報を入力して下さい。
再度転送設定画面に戻り、S3接続情報の「再読込」ボタンを押すと、作成した接続情報が選択できるかと思います。
このステップが若干面倒ではありますが、一度保存した設定は再利用したり、チーム内で共有することが出来ます。
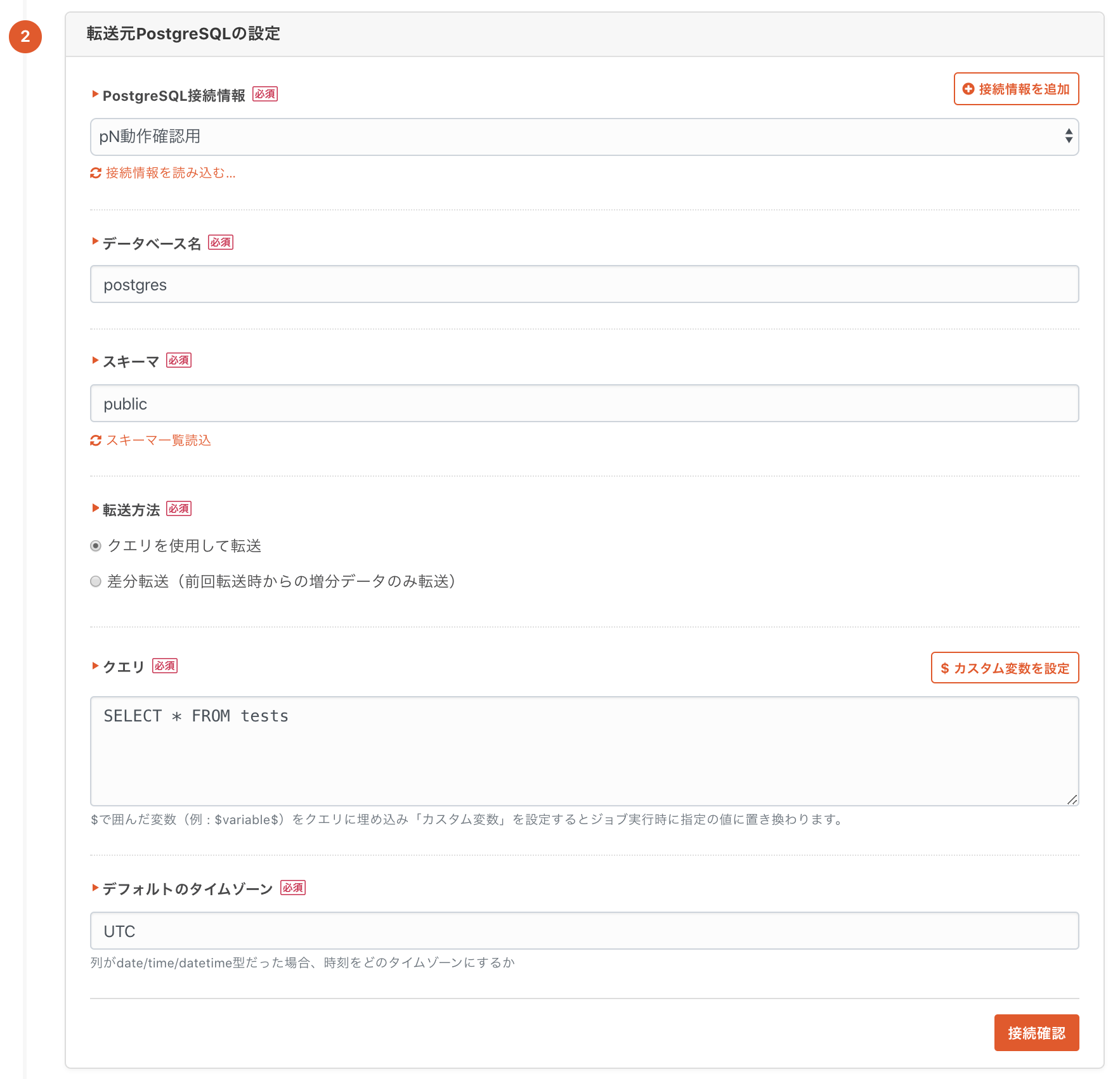
1-3. 転送元の設定
下記のように入力します。接続確認を押せば、入力した情報が正しいかを確認出来ます。
差分転送機能もサポートしているので、日次で増分データのみ転送したいみたいな用途にも使えます。
1-4. 転送先の設定
転送元と同じ要領で設定していきます。
データセットとテーブルは既存のものを使っても良いですし、新しい名前で入力した上で自動生成オプションを有効にすれば、自動で作成されます。
転送モードはappend(追記)やreplace(テーブル作り替え)などが選択可能で、いずれもトランザクション内で処理されるため、途中で処理が失敗したらロールバックされます。
少量のデータを定期的に転送する場合はreplaceを、大量データで増分のみを転送する場合はappendを選択すると良いかと思います。
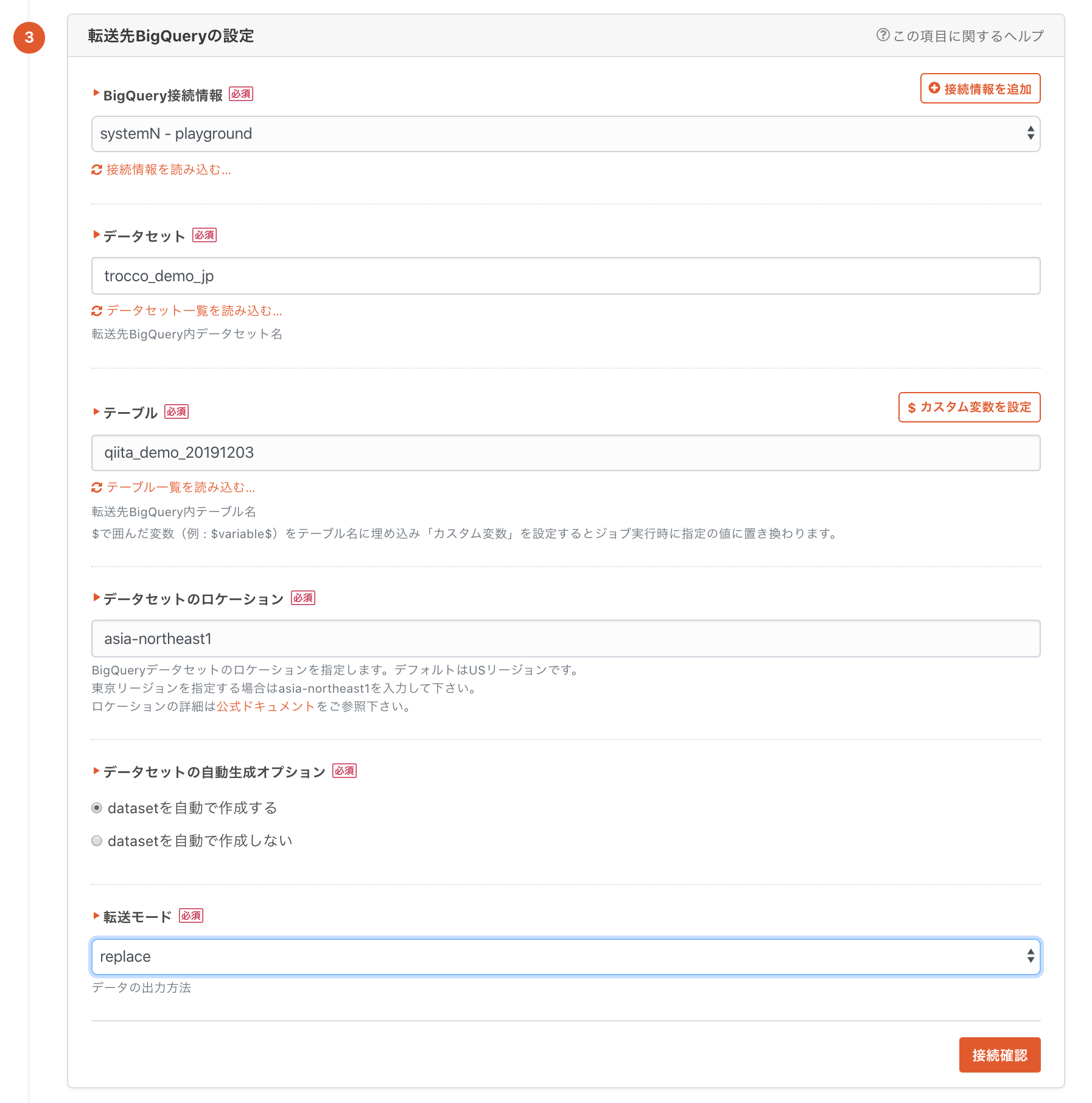
また、入力した情報に誤りがないか、疎通確認や権限確認をすることが出来ます。
(転送元も同様に確認が出来ます)
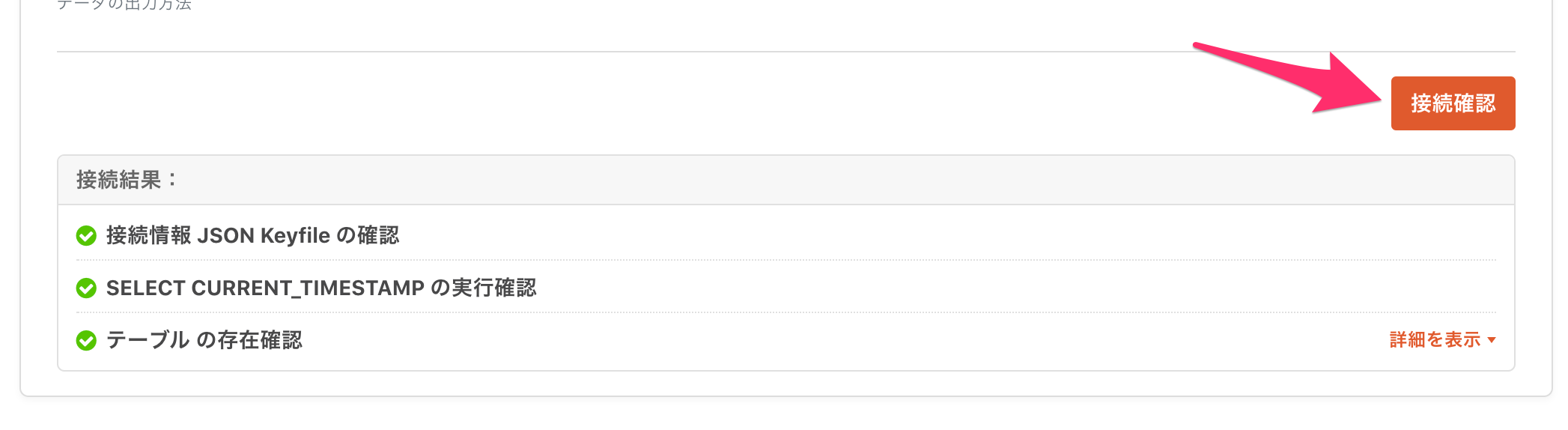
この段階で疎通や権限が正しいことを確認できると、安心感がありますね。
2. プレビューを確認
転送元のデータがプレビューされます。列名や、自動推論されたデータ型が正しく判定されているか確認して下さい。
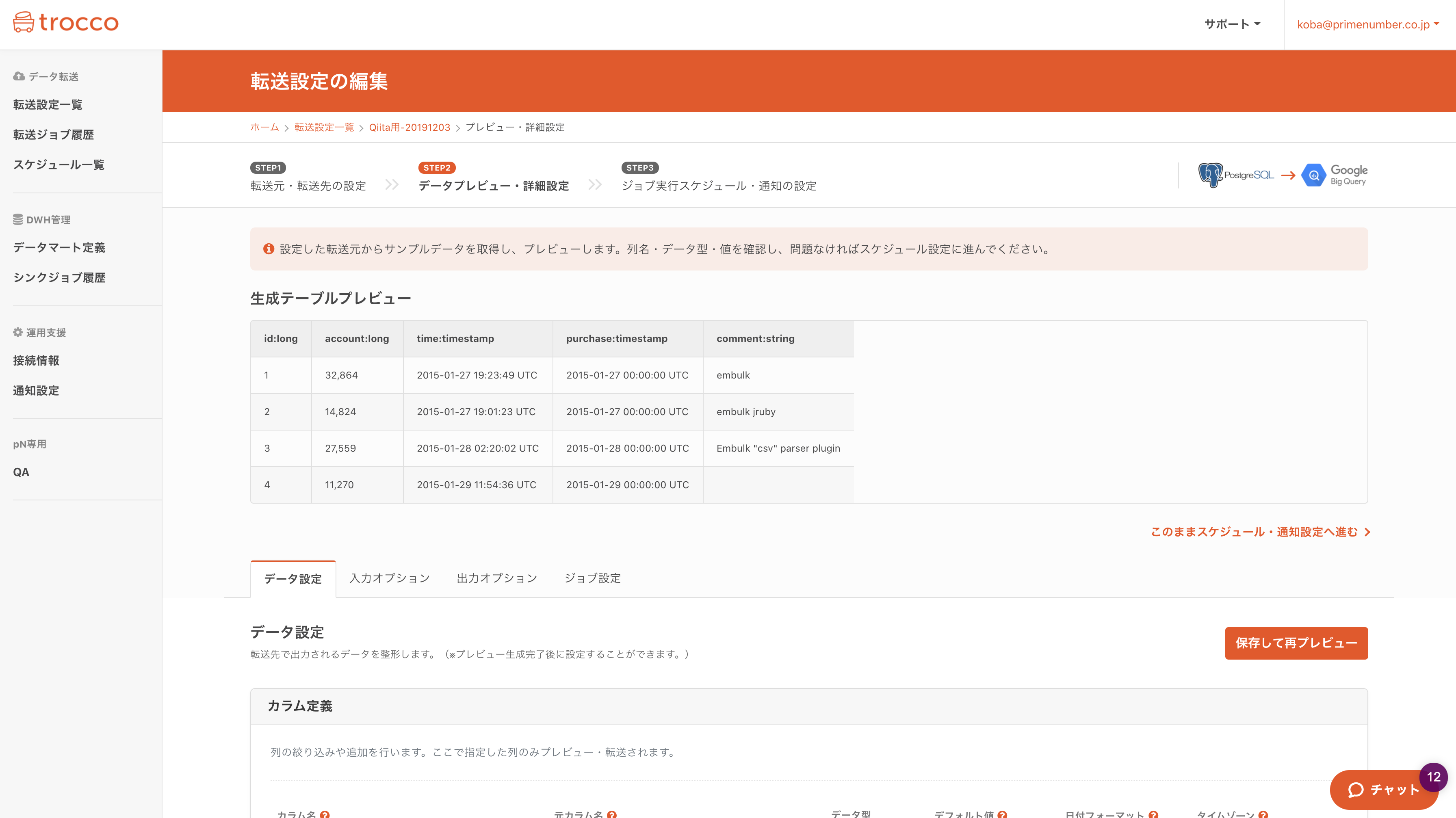
データのスキーマは自動で推論されますので、間違っていたら「データ設定」タブから修正することも出来ます。
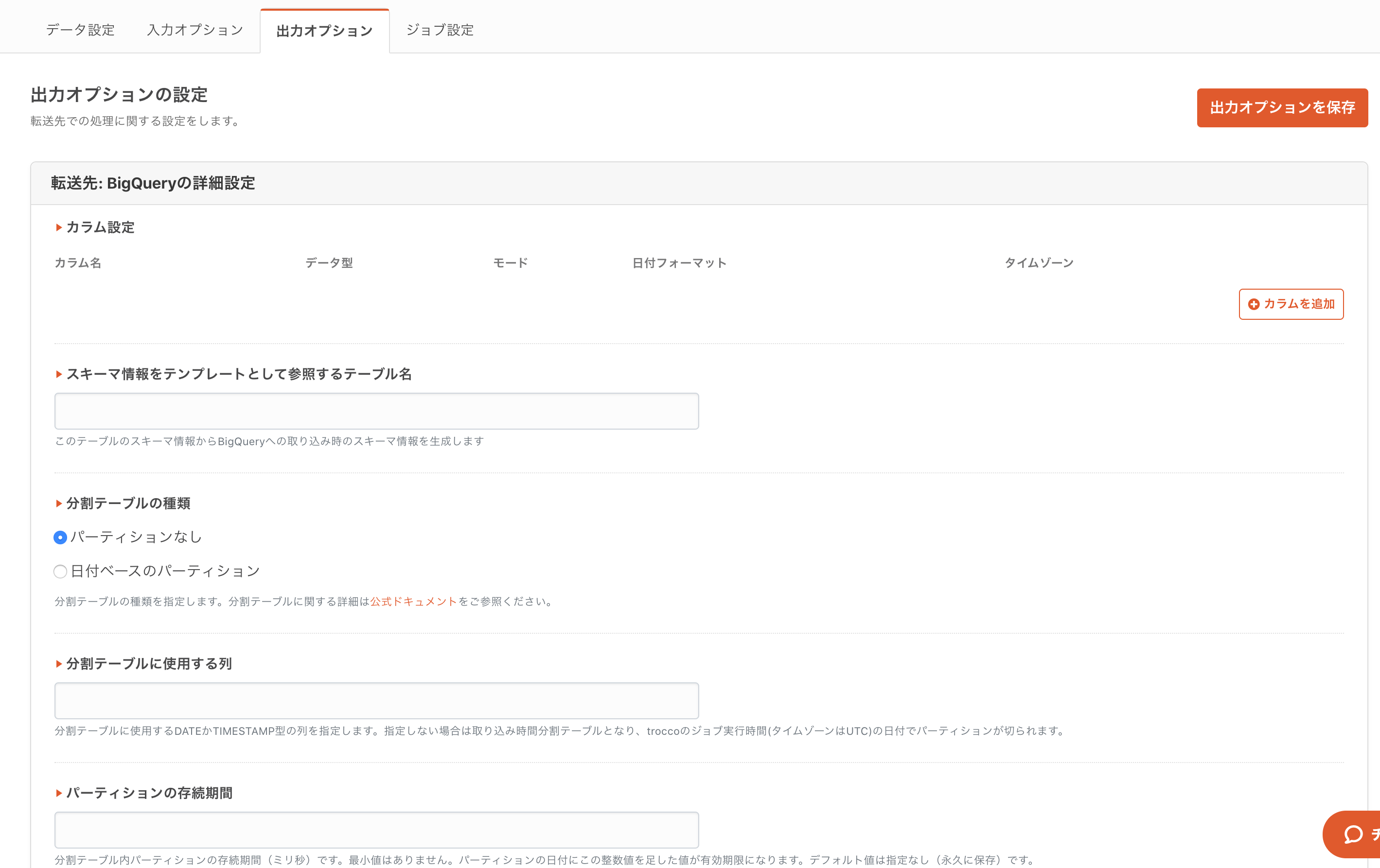
また、BigQueryの分割テーブルなど、詳細な設定も「入力設定」や「出力設定」から行うことが出来ます。
3. 定期実行・Slack通知を設定
最後は定期実行のスケジューリングや、通知設定の入力画面です。
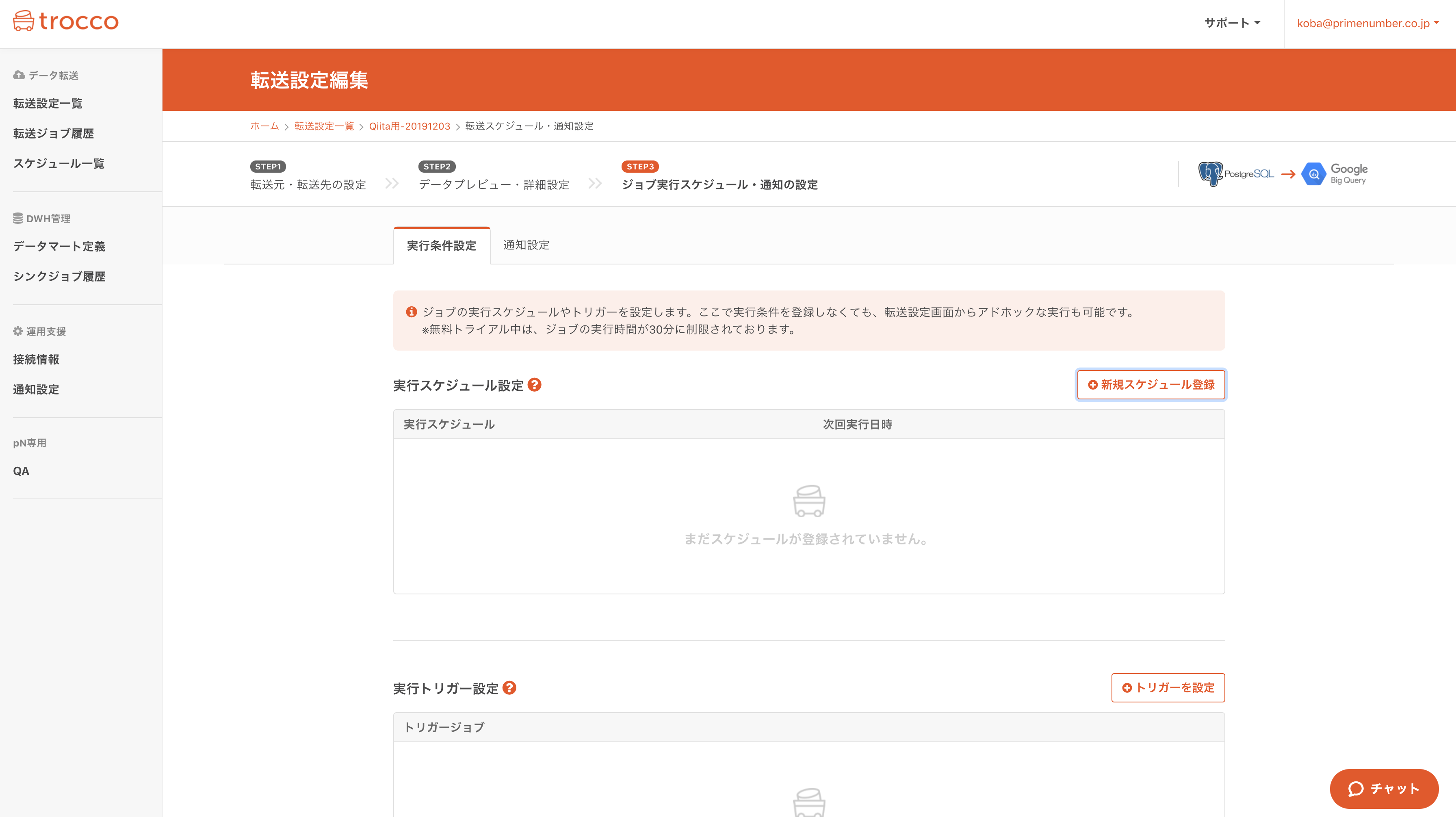
日次バッチだったら、以下のようなUIで、数クリックで設定可能です。
(最短1分間隔で転送可能)

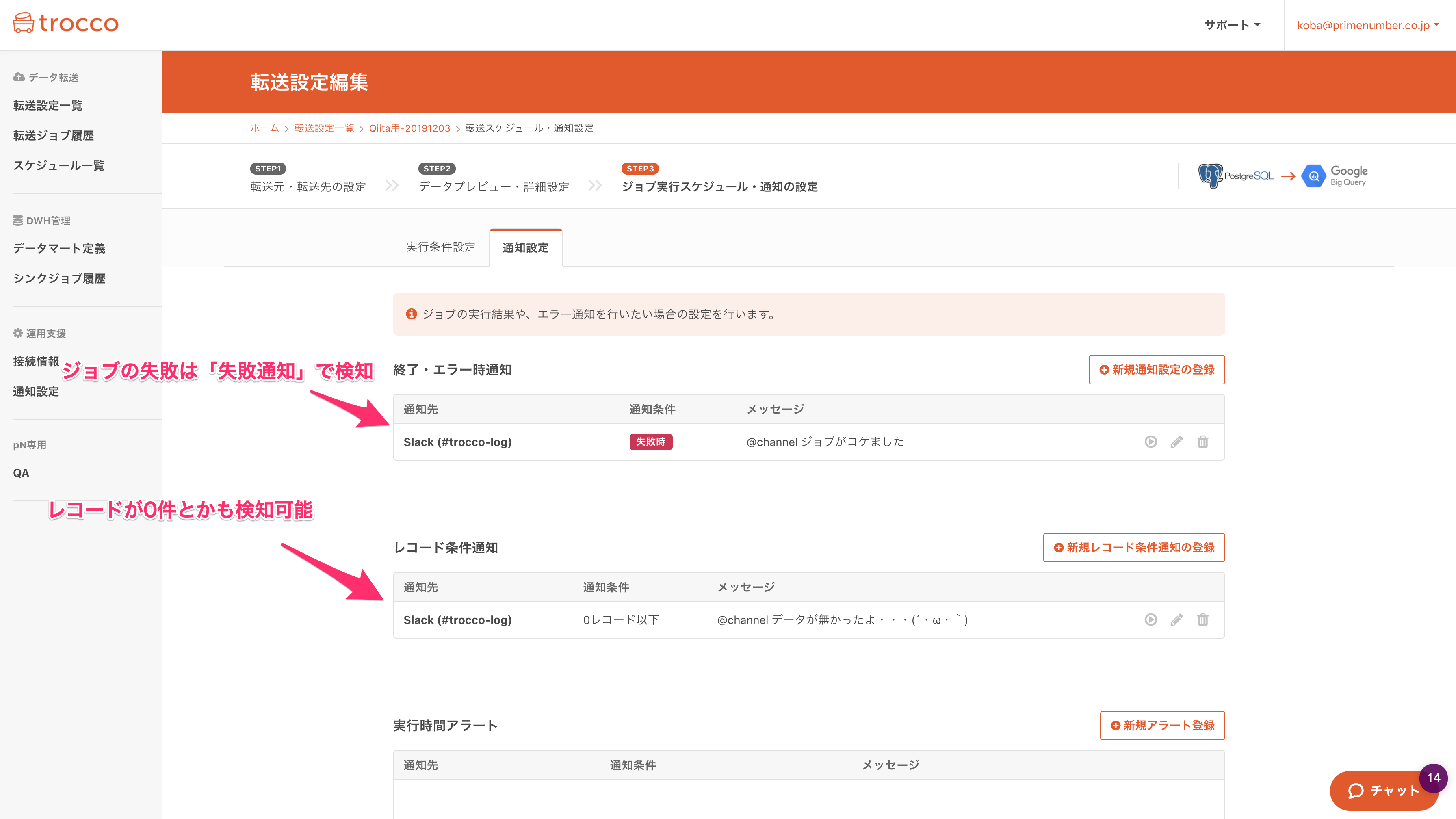
地味に嬉しいのが、この通知設定。
当然ジョブが失敗したらSlack通知とかはできるんですが、よくある「データが0件でジョブが正常完了してしまった」みたいなのまで検知できるんです。
4. ジョブ実行
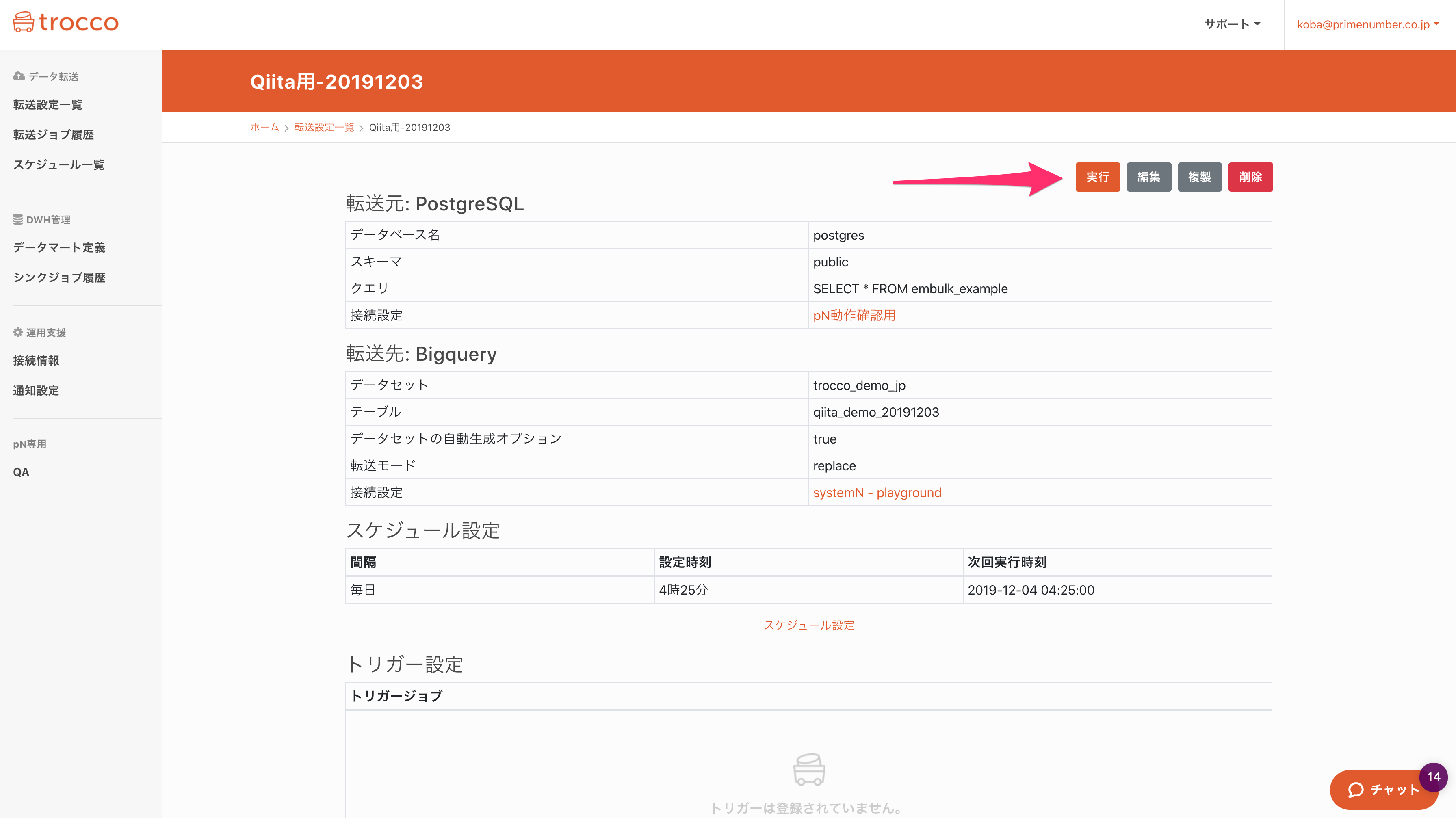
定期実行の他に、アドホックな実行も可能です。
下図の実行ボタンを押せば実行が始まります。
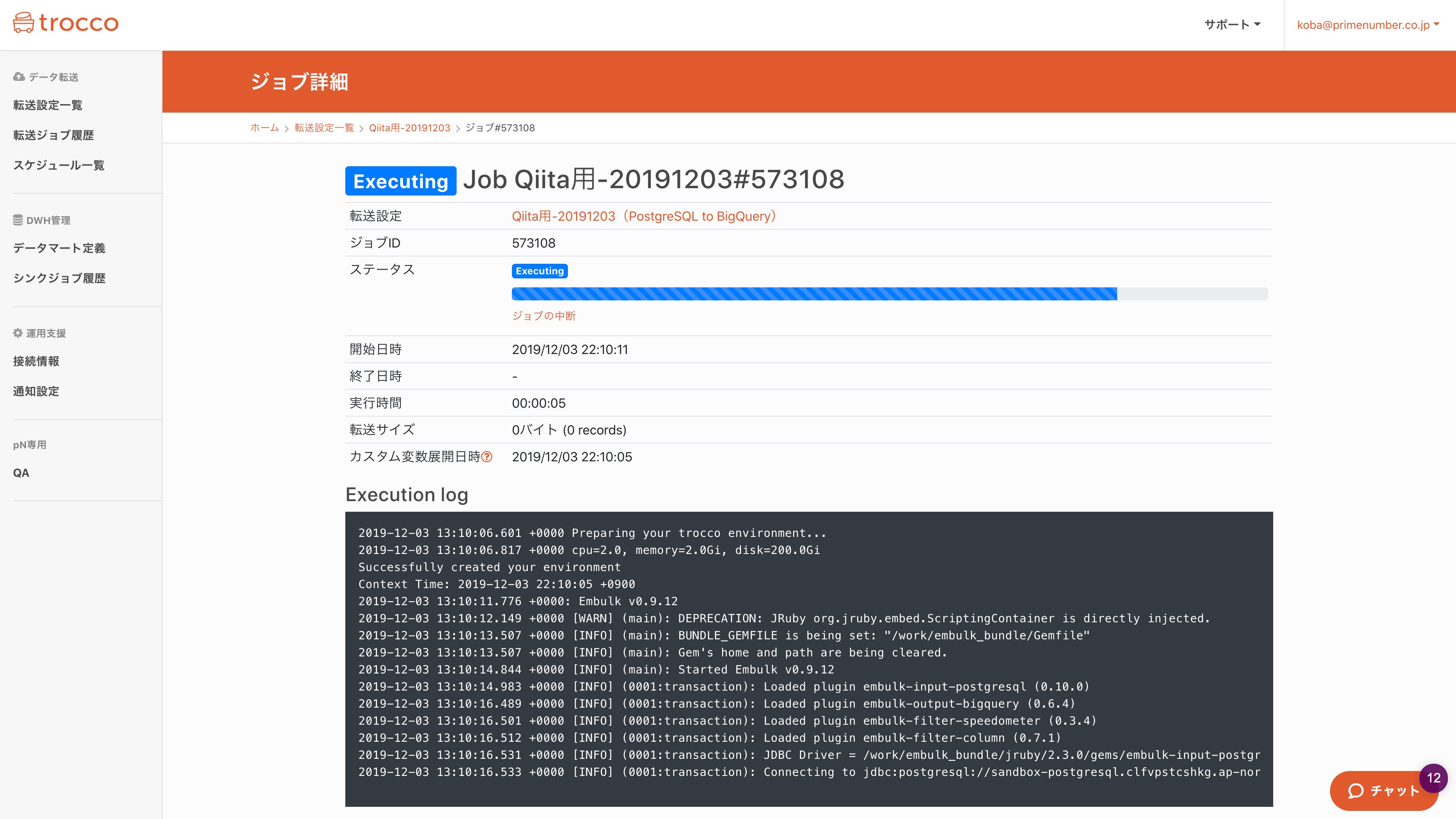
実行画面こんな感じです。ちなみにジョブ実行のたびに専用コンテナが立ち上がり、かつCPUやメモリの割当を動的に変更できるので、パフォーマンス要件が厳しい場合も大丈夫らしいです。
まとめ
- troccoを使うことで、約3分ほどでデータの転送設定を作ることが出来ました
- 昨今機会が急激に増えつつあるデータ転送を、より手軽に実現できました
- 複雑な作業はほぼないので、エンジニアだけでなく、マーケター・ディレクターの方まで幅広く利用出来るかと思います
試してみたい場合は、無料トライアルを実施しているので、この機会にぜひ一度お試しください。
(申込時に、この記事を見た旨を記載して頂ければスムーズにご案内できます)
その他にも広告やデータベースなど、様々な分析データをETL・転送した事例をまとめました。
troccoの使い方まとめ(CRM・広告・データベース他)
※1 今回はembulk-input-postgresqlとembulk-output-bigqueryのホスティング環境を利用