この記事では
以前の記事‘tensorflow2.0でU-Netを実装する’で紹介したU-netは画像のセグメンテーションためのネットワークの構造でしたが、今回は動画のセグメンテーションのためU‐netの2D演算から3Dへの拡張した3D U-netを紹介し、脳の海馬領域データセットを利用して細胞領域を検出するモデルを実装してみます。
対象読者
- 動画のセグメンテーションモデルを実装してみたい人
- 3D U-netとは何か知りたい人
1. 3D U-Netとは
3D U-netについて簡単に説明します。
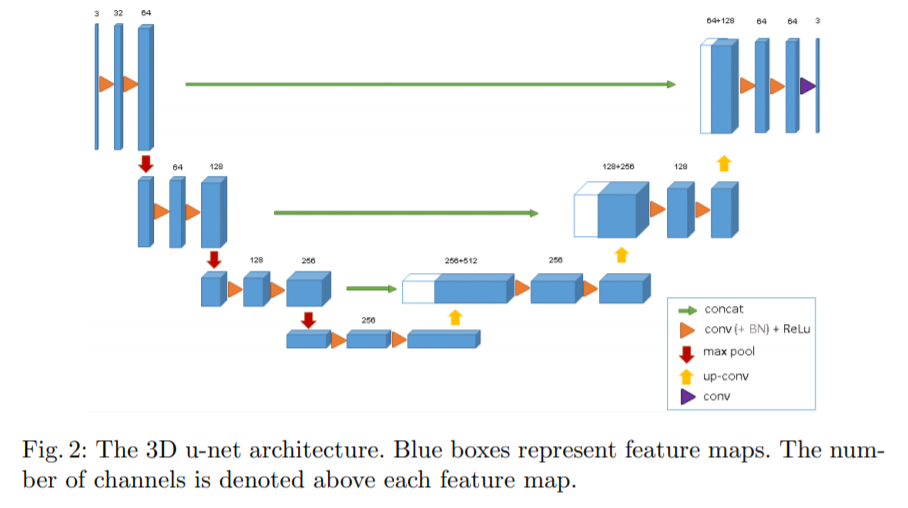
3D U-netの図案
(論文「3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation」 Fig. 2.より引用)
3D U-netは時系列を意識して動画のセグメンテーション(物体がどこにあるか)をするためのネットワークです。
動画セグメンテーション
動画を複数のセグメント(画像オブジェクトとも呼ばれるピクセルのセット)に分割するプロセス
動画版のU-netのためU-netのネットワークと構造的に大きい違いはありません。
3D U-NetもU-Netと同様に全結合層を持たず、畳み込み層で構成されています。3D U-NetもU-Netのようにほ左右対称のEncoder–Decoder構造で、Encoderのpoolingを経てダウンサンプリングされた特徴マップをDecoderでアップサンプリングしていきます。
( ※ 具体的な説明は'tensorflow2.0でU-Netを実装する'記事を参考してください。)
| ボックス | 矢印 |
|---|---|
| 青ボックス:動画、特徴マップ | オレンジ矢印:kernel size 3×3x3, padding0の畳み込み、ReLU |
| 白ボックス:コピーされた特徴マップ | 緑矢印:特徴マップのコピーをクロップ |
| ボックスの上の数字:チャンネル数 | 赤矢印:kernel size 2×2x2のmax-pooling |
| ボックスの左下の数字:縦横のサイズ | 黄矢印:kernel size 2×2x2のup-sampling |
| 紫矢印:kernel size 1×1x1の畳み込み |
2. データの準備
2-1) データセットのダウンロード
今回、使うデータセットはElectron Microscopy 3D Segmentationです。これはEPFL CVLabの脳のCA1海馬領域から取得した5x5 μm セクションの動画データセットを.tif拡張子のファイルで保存したものです。一つの動画は縦横768x1024サイズのイメージが165フレームで構成されています。
Data Explorer(緑ボックス)でダウンロードしたいデータを選択してダウンロードボタン(赤いボックス)を押すとダウンロードできます。

全部ダウンロードするとこのように脳のCA1海馬領域の教師データとテストデータ動画を確認することができます。
しかし、容量も大きく3DU-Netの実装に焦点を置いた記事なので、教師データ(training.tif、training_groundtruth.tif)でテストまで致します。
2-2) マルチページTIFFの分割
ダウンロードしたマルチページ.tif拡張子のデータを1枚づつ切り出して.png拡張子で保存します。そのため、pillowライブラリを利用します。
( ※ .mp4や.aviなどの動画ファイルからフレームを切り出して静止画の画像ファイルとして保存することも可能です。)
Pillowライブラリ
Pillow(PIL)は画像処理ライブラリの1つです。
処理の内容にはよるものの、画像認識など高度な画像処理を行なうことのできるOpenCVと比較して、単純な操作や基本的な操作を行なうことができるという点がPillowの特徴です。
(公式サイト : https://pillow.readthedocs.io/)
from PIL import Image, ImageSequence
im = Image.open('/データが保存されているパス/training.tif')
for i, page in enumerate(ImageSequence.Iterator(im)):
page.save("/保存しようと思うフォルダのパス/page%d.png" % i)
Pillowで画像を開くには、Imageクラスのopenメソッドを使います。
Image.open(fp, [mode])
引数
- fp(str型,Path,file) : 画像ファイル名、またはPathオブジェクトかopen済みのファイルオブジェクト。
- mode(str型) : 省略可。既定値は'r'。
戻り値
- Imageオブジェクト
コードのポイントはPIL.ImageSequence.Iteratorクラスです。 PIL.Imageで開いた画像をこのコンストラクタに渡すと、アニメーションGIFや動画内の各フレーム(静止画)を返すイテレータオブジェクトを生成してくれます。
ImageSequence.Iterator(im)
引数
- im : Imageオブジェクト
training_groundtruth.tifファイルも同じ処理をします。私はimg、segフォルダを作ってtraining.tifから得たイメージはimgフォルダにtraining_groundtruth.tifから得たイメージはsegフォルダに保存しました。
2-3) Pickle形式で保存
今回は、画像のピクセル自体をpickleで保存するのではなく、画像のパスと対で紐づくセグメンテーションのパスをそれぞれをpickle化します。
そのため、pandasライブラリ以外にPythonのosモジュール、globモジュールも利用します。
import os, sys
from glob import glob
import pandas as pd
basic_path = '/分割したイメージが保存されていろパス'
glob_train_imgs = os.path.join(basic_path, 'img/page*.png')
glob_seg_imgs = os.path.join(basic_path, 'seg/page_seg*.png')
train_img_paths = glob(glob_train_imgs)
train_seg_paths = glob(glob_seg_imgs)
img_id = list(range(len(train_img_paths)))
df = pd.DataFrame({'img_id':img_id,'tmp_img_path':train_img_paths, 'tmp_seg_path':train_seg_paths})
-
pandasライブラリPythonのデータ解析用のライブラリで機械学習ではデータの整理、可視化、前処理するため使います。この記事でも以下のような流れで実装します。
- Pythonの辞書型データの定義
{“キー”:list型のデータ,...}- 'キー'の数 = 列(Columns)の数
-
list型のデータの数 = 行(index)の数
- 作った辞書型データを
pd.DataFrameメソッドに引数として入力
- Pythonの辞書型データの定義
-
osモジュール
OSに依存しているさまざまな機能を利用するためのモジュールです。
ここで使うos.path()モジュールは「ファイルやディレクトリの存在確認」、「指定したパスのファイル名の取得」、「パスやファイル名の結合」などの用途で使用します。 -
globモジュール条件を満たすパスの一覧を再帰的に取得します。ということで、特定のディレクトリに存在するファイルに処理を加えたい場合などに使います。
例えば、現在のディレクトリにt_1.log, t_2.log, abc.logのファイルが存在したとするとglob.glob('*.log')実行により、
['abc.log', 't_1.log', 't_2.log']リストデータ型が返却されます。
そのような理由で、前の記事のようにリスト型で変更する必要がありません。
display(df) #確認
| img_id | tmp_img_path | tmp_seg_path | |
|---|---|---|---|
| 0 | 0 | /分割したイメージが保存されていろパス/img/page0.png | /分割したイメージが保存されていろパス/seg/page_seg0.png |
| 1 | 1 | /分割したイメージが保存されていろパス/img/page1.png | /分割したイメージが保存されていろパス/seg/page_seg1.png |
| 2 | 2 | /分割したイメージが保存されていろパス/img/page2.png | /分割したイメージが保存されていろパス/seg/page_seg2.png |
| ... | ... | ... | ... |
| 163 | 163 | /分割したイメージが保存されていろパス/img/page163.png | /分割したイメージが保存されていろパス/seg/page_seg163.png |
| 164 | 164 | /分割したイメージが保存されていろパス/img/page164.png | /分割したイメージが保存されていろパス/seg/page_seg164.png |
165 rows × 3 columns
その後、df.to_pickle()メソッドを利用してPickle形式のファイルに保存します。
dataset_name = 'ファイル名'
filename = '{}_train_df.pkl'.format(dataset_name)
filepath = os.path.join(保存しようと思っているフォルダパス, filename)
df.to_pickle(filepath)
3. ジェネレータの実装
generator.pyというファイルで実装します。
ジェネレータについては前の記事でも触れていますが、ここでもまとめておきます。
ジェネレータ(Generator)
イテレータ(;反復可能オブジェクト)の一種であり、1要素を取り出そうとする度に処理を行い、要素をジェネレートするタイプのものです。
下記のコードは私が作ったジェネレータの全体です。以降でコードの重要な部分を少し詳しく説明します。
class threeDUnetGenerator():
def __init__(self, df, shuffle = False, random_state = None):
self.data_list = df.to_dict(orient='records')
self.batch_size = 2
self.frame_size = 16
self.input_shape = (64, 64, 3)
self.shuffle = shuffle
if random_state is None:
random_state = np.random.RandomState(1234)
self.random_state = random_state
self._idx = 0
self._reset()
def __len__(self):
N = len(self.data_list)
b = self.batch_size
f = self.frame_size
return N // (b*f)
def __iter__(self):
return self
def __next__(self):
if self._idx >= len(self.data_list)-5:
self._reset()
raise StopIteration()
selected_data_list = self.data_list[self._idx:(self._idx + (self.batch_size*self.frame_size))]
img_list = []
seg_list = []
batch = {}
batch_img_list = []
batch_seg_list = []
for n in range(self.batch_size):
depth_img_list = []
depth_seg_list = []
for f in range(self.frame_size):
data_idx = (n*self.frame_size) + f
img, seg = self.load_img(selected_data_list[data_idx])
depth_img_list.append(img)
depth_seg_list.append(seg)
batch_img_list.append(depth_img_list)
batch_seg_list.append(depth_seg_list)
batch['batch_id'] = np.array([i['img_id']for i in selected_data_list])
batch['batch_img'] = np.array(batch_img_list)
batch['batch_seg'] = np.array(batch_seg_list)
self._idx += (self.batch_size*self.frame_size)
return batch
def _reset(self):
if self.shuffle:
self.data_list = shuffle(self.data_list, random_state=self.random_state)
self._idx = 0
def load_img(self, data):
img = cv2.imread(data['tmp_img_path'], cv2.IMREAD_COLOR)
img = self.add_margin(img,(0,0,0)).resize((64, 64))
img = np.array(img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = img.astype(np.float32)
img /= 255.0
img = img[:, :,np.newaxis] #グレースケールイメージのため、チャンネル追加
seg = cv2.imread(data['tmp_seg_path'], cv2.IMREAD_COLOR)
seg = self.add_margin(seg,(0,0,0)).resize((64, 64))
seg = np.array(seg)
seg = cv2.cvtColor(seg, cv2.COLOR_BGR2GRAY)
seg = seg.astype(np.float32)
seg /= 255.0
seg[seg > 0.1] = 1.0
seg[seg <= 0.1] = 0.0
seg = seg[:, :,np.newaxis] #グレースケールイメージのため、チャンネル追加
return img,seg
def add_margin(self,img, background_color):
height,width= img.shape[:2]
if width == height:
return img
elif width > height:
img = Image.fromarray(img)
result = Image.new(img.mode, (width, width), background_color)
result.paste(img, (0, (width - height) // 2))
return result
else:
result = Image.new(img.mode, (height, height), background_color)
result.paste(img, ((height - width) // 2, 0))
return result
前回の記事のコードとの差異がないですが、異なることは2つあります。
1. 長方形のイメージを正方形で作ること。
2. データが動画のため、frame_size変数を追加するための多次元配列を処理すること。
3-1) イメージを正方形への変更
イメージが長方形でも問題ないですが、畳み込みを行う際は正方形が一般的です。
そのため、長方形の画像を正方形で変更して使います。
画像の変形はOpenCV等のライブラリを利用することができますが、 ここではPillowライブラリを利用します。
このコードで入力画像の短辺と長辺の差を計算して、画像がなるべく真ん中に配置されるように、短辺を上下あるいは左右を延長します。
def add_margin(self,img, background_color):
height,width= img.shape[:2]
if width == height:
return img
elif width > height:
img = Image.fromarray(img)
result = Image.new(img.mode, (width, width), background_color)
result.paste(img, (0, (width - height) // 2))
return result
else:
result = Image.new(img.mode, (height, height), background_color)
result.paste(img, ((height - width) // 2, 0))
return result
上記のコードで使ったPillowライブラリのメソッドについて簡単に説明します。
Image.fromarray()はndarrayをPIL.Imageのオブジェクトに変換するために使うメソッドです。
Image.fromarray()にndarrayを渡すとPIL.Imageが得られ、色んなPillowライブラリの操作ができます。
Image.fromarray(ndarray)
引数
- ndarray : NumPyで使われる多次元配列のデータ構造
戻り値
- Imageオブジェクト
Image.new()メソッドはイメージは新しいイメージを生成します。
Image.new(mode, size, color)
引数
- mode : Imageモード
- 1 : 1bit マスクに使用、論理演算が可能
- L : 8bit グレイスケール
- P : パレットモード
- RGB : 8bit x 3
- RGBA : 8bit x 4 透明度(アルファ)付き
- CMYK : 8bit x 4 印刷関連でよく使われる
- YCbCr : 8bit x 3 ビデオ関連でよく使われる
- HSV : 8bit x 3 pillowのみ
- RGBa : アルファチャンネルでRGB値を乗算
- LA : アルファチャンネルでL値を乗算
- I : 32bit 整数
- F : 32bit 浮動少数
- size:イメージのサイズを設定
- color : イメージの色を設定
戻り値
- Imageオブジェクト
短辺の延長によってできた空白領域はload_img関数で黒 (0, 0, 0) 一色で塗りつぶします。
( ※ 今回はGPUメモリが不足しないよう、(64,64)にリサイズしました。)
def load_img(self, data):
# (コード省略)
img = self.add_margin(img,(0,0,0)).resize((64, 64))
# (コード省略)
seg = self.add_margin(seg,(0,0,0)).resize((64, 64))
# (コード省略)
return img,seg

3-2) 時系列情報の追加処理
動画のフレーム(時系列)を意識した学習にしたいので、既存の多次元のデータ(batch_size, height, width, channel)にframe_size変数を追加して(batch_size, frame_size, height, width, channel)のデータを作ります。
そうするためのPythonの多次元配列を扱う方法について簡単に解説します。
多次元配列
次元とは配列の深さという意味で、[ ]を使って表します。中でも2次元以上の配列を多次元配列といいます。
多次元配列はlist型のため、要素を追加するにはPythonでlist型のリスト(配列)に要素を追加するメソッド使います。
リストに要素を追加するメソッドではappend()、extend()等があります。
-
append()
リストの末尾に要素「item」を追加する。
リスト.append(item)- item : 追加する要素の値
-
extend()
リストの末尾に「iterable」に含まれる全要素を追加する。
リスト.extend(iterable)- iterable : リストに追加する要素を含んだ反復可能オブジェクト
これら2つのメソッドは共にリストの末尾に要素を追加するものですが、appendメソッドでは引数が反復可能オブジェクトの場合、それを1つの要素としてリストの末尾に追加します。これに対して、extendメソッドに反復可能オブジェクトを渡した場合には、その要素が展開(extend)されて、別々の要素としてリストに追加されます。以下に例を示します。
# 例)
intlist = list(range(5))
intlist.append(5) # リストの末尾に要素「5」を追加
intlist.append([6, 7]) # リストの末尾にリスト「[6, 7]」を追加
intlist.extend([8, 9]) # リストの末尾に要素「8」と要素「9」を追加
print(intlist) # 出力:[0, 1, 2, 3, 4, 5, [6, 7], 8, 9]
そういうわけで次元を追加するにappend()メソッドを使います。
for n in range(self.batch_size):
depth_img_list = []
depth_seg_list = []
for f in range(self.frame_size):
data_idx = (n*self.frame_size) + f
img, seg = self.load_img(selected_data_list[data_idx])
depth_img_list.append(img)
depth_seg_list.append(seg)
batch_img_list.append(depth_img_list)
batch_seg_list.append(depth_seg_list)
4. 3D U-net
4-1) 3D U-netモデルの実装
3D U-netとU-netは構造的に同じなので実装の流れも異なることがあまりありません。唯一違う点はtensorflow.keras.layersのモジュールを2Dレイヤーではなく、3Dレイヤーを利用することです。
つまり、U-NetではレイヤーでConv2D, MaxPooling2D, UpSampling2Dを利用しましたが、3D U‐netではConv3D, MaxPooling3D, UpSampling3Dを使って実装します。
( ※ この実装では確保するGPUメモリを削減するためレイヤーの層を本来より浅くしています。)
import os
import numpy as np
import random
import tensorflow as tf
from tensorflow.keras import datasets
from tensorflow.keras import regularizers
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv3D, MaxPooling3D, UpSampling3D, Activation, BatchNormalization, Dropout
class threeD_UNet(Model):
def __init__(self):
super().__init__()
# Network
self.enc = Encoder(config)
self.dec = Decoder(config)
# Optimizer
self.optimizer = tf.keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
# loss
self.loss_object = tf.keras.losses.BinaryCrossentropy()
self.train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
self.valid_loss = tf.keras.metrics.Mean('valid_loss', dtype=tf.float32)
def call(self, x):
forw1, forw2, forw3_dropOut, forw4_dropOut = self.enc(x)
y = self.dec(forw1, forw2, forw3_dropOut, forw4_dropOut)
return y
@tf.function
def train_step(self, x, t):
with tf.GradientTape() as tape:
y = self.call(x)
loss = self.loss_object(t, y)
grads = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(grads, self.trainable_variables))
self.train_loss(loss)
@tf.function
def valid_step(self, x, t):
y = self.call(x)
v_loss = self.loss_object(t, y)
self.valid_loss(v_loss)
return y
class Encoder(Model):
def __init__(self):
super().__init__()
#Encoder
# data_format='channels_last'
self.dcon1_1 = tf.keras.layers.Conv3D(32,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.dcon1_2 = tf.keras.layers.Conv3D(64,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.pool_1 = tf.keras.layers.MaxPooling3D(pool_size=(2,2,2), data_format = 'channels_last')
self.dcon2_1 = tf.keras.layers.Conv3D(64,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.dcon2_2 = tf.keras.layers.Conv3D(128,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.pool_2 = tf.keras.layers.MaxPooling3D(pool_size=(2,2,2), data_format = 'channels_last')
self.dcon3_1 = tf.keras.layers.Conv3D(128,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.dcon3_2 = tf.keras.layers.Conv3D(256, (3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.drop_3 = tf.keras.layers.Dropout(0.5)
self.pool_3 = tf.keras.layers.MaxPooling3D(pool_size=(2,2,2), data_format = 'channels_last')
self.dcon4_1 = tf.keras.layers.Conv3D(256,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.dcon4_2 = tf.keras.layers.Conv3D(512,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.drop_4 = tf.keras.layers.Dropout(0.5)
def call(self,x):
forw1 = self.dcon1_1(x)
forw1 = self.dcon1_2(forw1)
forw1_pool = self.pool_1(forw1)
forw2 = self.dcon2_1(forw1_pool)
forw2 = self.dcon2_2(forw2)
forw2_pool = self.pool_2(forw2)
forw3 = self.dcon3_1(forw2_pool)
forw3 = self.dcon3_2(forw3)
forw3_dropOut = self.drop_3(forw3)
forw3_pool = self.pool_3(forw3)
forw4 = self.dcon4_1(forw3_pool)
forw4 = self.dcon4_2(forw4)
forw4_dropOut = self.drop_4(forw4)
return forw1, forw2, forw3_dropOut, forw4_dropOut
class Decoder(Model):
def __init__(self):
super().__init__()
self.up_4 = tf.keras.layers.UpSampling3D(size=(2,2,2),data_format = 'channels_last')
self.ucon3_1 = tf.keras.layers.Conv3D(256,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.up_3 = tf.keras.layers.UpSampling3D(size=(2,2,2), data_format = 'channels_last')
self.ucon2_1 = tf.keras.layers.Conv3D(128,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.up_2 = tf.keras.layers.UpSampling3D(size=(2,2,2), data_format = 'channels_last')
self.ucon1_1 = tf.keras.layers.Conv3D(64,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.ucon1_2 = tf.keras.layers.Conv3D(64,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.ucon1_3 = tf.keras.layers.Conv3D(1,(1,1,1), padding= 'same', data_format = 'channels_last')
def call(self, forw1, forw2, forw3_dropOut, forw4_dropOut):
forw4_upSampling = self.up_4(forw4_dropOut)
forw5 = tf.keras.layers.concatenate([forw3_dropOut,forw4_upSampling], axis = -1)
forw5 = self.ucon3_1(forw5)
forw5_upSampling = self.up_3(forw5)
forw6 = tf.keras.layers.concatenate([forw2,forw5_upSampling], axis = -1)
forw6 = self.ucon2_1(forw6)
forw6_upSampling = self.up_2(forw6)
forw7 = tf.keras.layers.concatenate([forw1,forw6_upSampling], axis = -1)
forw7 = self.ucon1_1(forw7)
forw7 = self.ucon1_2(forw7)
forw7 = self.ucon1_3(forw7)
return forw7
(1) Encoderの定義
3D U-NetのEncoderの特徴は下記の通りです。
- 典型的なConvolution network
- 3X3X3 convolutionを二回反復して行う
- 活性化関数でReLUを使う
- 2X2X2 max poolingする
- downsampling時、 2倍のfeature channelを利用する
これらの特徴を元に実装して行くとこのようになります
class Encoder(Model):
def __init__(self):
super().__init__()
#Encoder
# data_format='channels_last'
# 3X3X3 convolutionを二回反復して行う
# 活性化関数でReLUを使う
# downsampling時、 2倍のfeature channelを利用する
self.dcon1_1 = tf.keras.layers.Conv3D(32,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.dcon1_2 = tf.keras.layers.Conv3D(64,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
# 2X2X2 max poolingする
self.pool_1 = tf.keras.layers.MaxPooling3D(pool_size=(2,2,2), data_format = 'channels_last')
self.dcon2_1 = tf.keras.layers.Conv3D(64,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.dcon2_2 = tf.keras.layers.Conv3D(128,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.pool_2 = tf.keras.layers.MaxPooling3D(pool_size=(2,2,2), data_format = 'channels_last')
self.dcon3_1 = tf.keras.layers.Conv3D(128,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.dcon3_2 = tf.keras.layers.Conv3D(256, (3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.drop_3 = tf.keras.layers.Dropout(0.5)
self.pool_3 = tf.keras.layers.MaxPooling3D(pool_size=(2,2,2), data_format = 'channels_last')
self.dcon4_1 = tf.keras.layers.Conv3D(256,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.dcon4_2 = tf.keras.layers.Conv3D(512,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.drop_4 = tf.keras.layers.Dropout(0.5)
def call(self,x):
forw1 = self.dcon1_1(x)
forw1 = self.dcon1_2(forw1)
forw1_pool = self.pool_1(forw1)
forw2 = self.dcon2_1(forw1_pool)
forw2 = self.dcon2_2(forw2)
forw2_pool = self.pool_2(forw2)
forw3 = self.dcon3_1(forw2_pool)
forw3 = self.dcon3_2(forw3)
forw3_dropOut = self.drop_3(forw3)
forw3_pool = self.pool_3(forw3)
forw4 = self.dcon4_1(forw3_pool)
forw4 = self.dcon4_2(forw4)
forw4_dropOut = self.drop_4(forw4)
return forw1, forw2, forw3_dropOut, forw4_dropOut
(2) Decoderの定義
3D U-NetのDecoderの特徴は下記の通りです。
- 2X2X2 convolution (up-convolution)を使う
- feature channelは半分で減らして使用する
- EncoderでMax-Poolingする前のfeature mapをCropして、Up-Convolutionする時concatenationする
- 3X3X3 convolutionを二回反復して行う
( ※ メモリ不足の問題が発生してコードではレイヤーの数を減らしました。) - 活性化関数でReLUを使う
- 最後のレイヤーでは1X1X1 convolutionを使って2個のクラスで分類する
これらの特徴を元に実装して行くとこのようになります。
class Decoder(Model):
def __init__(self):
super().__init__()
# 2X2X2 convolution (up-convolution)を使う
# 活性化関数でReLUを使う
self.up_4 = tf.keras.layers.UpSampling3D(size=(2,2,2),data_format = 'channels_last')
self.ucon3_1 = tf.keras.layers.Conv3D(256,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.up_3 = tf.keras.layers.UpSampling3D(size=(2,2,2), data_format = 'channels_last')
# feature channelは半分で減らして使用する
self.ucon2_1 = tf.keras.layers.Conv3D(128,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.up_2 = tf.keras.layers.UpSampling3D(size=(2,2,2), data_format = 'channels_last')
self.ucon1_1 = tf.keras.layers.Conv3D(64,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
self.ucon1_2 = tf.keras.layers.Conv3D(64,(3,3,3), activation = 'relu', padding= 'same', data_format = 'channels_last')
# 最後のレイヤーでは1X1X1 convolutionを使って2個のクラスで分類する
self.ucon1_3 = tf.keras.layers.Conv3D(1,(1,1,1), padding= 'same', data_format = 'channels_last')
def call(self, forw1, forw2, forw3_dropOut, forw4_dropOut):
forw4_upSampling = self.up_4(forw4_dropOut)
# EncoderでMax-Poolingする前のfeature mapをCropして、Up-Convolutionする時concatenationする
forw5 = tf.keras.layers.concatenate([forw3_dropOut,forw4_upSampling], axis = -1)
forw5 = self.ucon3_1(forw5)
forw5_upSampling = self.up_3(forw5)
forw6 = tf.keras.layers.concatenate([forw2,forw5_upSampling], axis = -1)
forw6 = self.ucon2_1(forw6)
forw6_upSampling = self.up_2(forw6)
forw7 = tf.keras.layers.concatenate([forw1,forw6_upSampling], axis = -1)
forw7 = self.ucon1_1(forw7)
forw7 = self.ucon1_2(forw7)
forw7 = self.ucon1_3(forw7)
return forw7
5. 学習
作ったgenerator.pyを呼び出すために、インポートします。
from フォルダの名.generator import threeDUnetGenerator
そして、保存したpickle形式のファイルを読み込みます。
train_df = pd.read_pickle("/フォルダのパス/指定したファイルの名_train_df.pkl")
インポートしたジェネレータを定義しましょう。
train_gen = threeDUnetGenerator(train_df, config)
batch = next(train_gen)
学習とテストを行います。
@tf.function
def train_step(x, t):
with tf.GradientTape() as tape:
predictions = model(x, training=True)
loss = loss_object(t, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(t, predictions)
@tf.function
def test_step(x, t):
test_predictions = model(x)
t_loss = loss_object(t, test_predictions)
test_loss(t_loss)
test_accuracy(t, test_predictions)
EPOCHS = 200
for epoch in range(EPOCHS):
for batch in tqdm(train_gen):
x = batch['batch_img']
t = batch['batch_seg']
train_step(x, t) #学習
for batch in tqdm(train_gen):
x = batch['batch_img']
t = batch['batch_seg']
valid_step(x, t) #テスト
template = 'Epoch {}, Loss: {}, Accuracy: {}, test-Loss: {}, test-Accuracy:{}'
print(template.format(epoch + 1,
train_loss.result(),
train_accuracy.result() * 100,
test_loss.result(),
test_accuracy.result()*100))
6.学習の結果
6-1) 予測結果を確認
Matplotlibライブラリを使って結果を視覚的に確認します。
Matplotlibライブラリ
Pythonにおけるグラフ描画の標準的なライブラリ
(公式サイト: https://matplotlib.org/)
model = threeD_UNet(train_gen)
data = next(train_gen)
x = data['batch_img']
t = data['batch_seg']
y = model.call(x)
batch_idx = 1
frame_idx = 7
fig, ax = plt.subplots(1,3, figsize=(15, 15), squeeze=False)
ax[0][0].imshow(x[batch_idx, frame_idx, :, :,0])
ax[0][0].set_title("training image")
ax[0][0].axis('off')
ax[0][1].imshow(t[batch_idx, frame_idx,:, :, 0])
ax[0][1].set_title("training segmentation image")
ax[0][1].axis('off')
ax[0][2].imshow(y[batch_idx,frame_idx, :, :, 0])
ax[0][2].set_title("AI is predicted segmentation image")
ax[0][2].axis('off')

一番目と二番目のイメージは教師データ、三番目は教師データから学習したAIが一番目のイメージを見て自ら予測した細胞領域です。所々誤りのありますが、かなり上手に正解を当たっていることをわかります。
batch_idxは0~1、frame_idxは0~15の領域の数で変更しながらフレームづつ結果を確認できます。
6-2) 結果をアニメーションGIFファイルで保存
それらのイメージファイルをアニメーションGIFファイルで保存するには色んな方法が使用できます。
今回は、Pillow(PIL)を使って連番の画像ファイルからGIFファイルを作ります。
PillowライブラリのImageクラスが提供するsaveメソッドを実行してアニメーションGIFファイルを作ることができます。全体的にはImage.fromarray()から得られたPIL.Imageをsave()メソッドで渡すと画像ファイルとして保存し、保存されるファイルのフォーマットはsave()の引数に指定したパスの拡張子から自動的に判定される流れになります。
im.save(fp, [format], [params])
引数
- im (Image) : Imageオブジェクト。
- fp (str,Path,file) : 画像ファイル名、またはPathオブジェクトかopen済みのファイルオブジェクト。
- format (str) : 省略可。既定値はNone。ファイル形式。Noneの場合は、拡張子から推定される。
- params : 省略可。writerに渡す個別の指定。
戻り値
None
ファイルフォーマットがGIFの場合だけparamsに指定できる引数があります。つまり、アニメーションGIFを出力したいときは次のようになります。
im.save(fp, save_all, append_images, [include_color_table], [interlace], [disposal], [palette], [optimize], [transparency], duration, loop, [comment])
引数
- im (Image) : 1フレーム目になるImageオブジェクト。
- fp (str) : 画像ファイル名。拡張子をgifにする。
- save_all (bool) : 全てのフレームを保存するか。静止画像ならFalse、アニメーションならTrue。
- append_images (list) : 2フレーム目以降のImageオブジェクトのリスト。
- duration (int) : フレームの表示間隔。ミリ秒で指定。
- loop (int) : ループ回数の指定。無限ループの場合は0。ループしない場合は1。
戻り値
None
fig = plt.figure()
ims = []
for i in range(2):
for j in range(16):
tmp = y[i, j, :, :, :]
tmp = np.uint8(tmp*255)
tmp = cv2.cvtColor(tmp, cv2.COLOR_GRAY2RGB)
tmp = Image.fromarray(tmp)
ims.append(tmp)
ims[0].save('/保存しようと思っているパス/ファイル名.gif',save_all=True, append_images=ims[1:], optimize=False, loop=0)
(※ ndarrayのデータ型dtypeがfloatなどの場合はエラーとなるため、uint8に変換する必要があるります。)
7. まとめ
pillowライブラリ主に利用して動画版U-Netである3D U-Netを実装してみました。
U-Netとさほど構成の違いがない為、U-Netを理解していれば簡単に実装できると感じました。
以上です。
誤り等ありましたら、ご指摘ください。