はじめに
今回は以下について紹介します。
-
手書き数字のデータセットとして有名なMnistをTensoflowAPIを使わずにダウンロード
-
Tensorflow Subclass APIによる分類モデルの実装~評価まで一連の流れ
- データのダウンロード・読み込み
- データの前処理およびジェネレータによる出力
- モデルの学習
- モデルの評価
なおここでSubclass APIも含めた機械学習のモデルを構築する3つの方法について網羅的に紹介しているのでご覧ください。
【対象読者】
- 色んなpythonライブラリを活用して分類モデルを実装してみたい人
- TensorFlow2.xのチュートリアルレベルよりスキルをアップグレードしたい人
- 実装した分類モデルを 様々な指標で評価したい人
1. データの準備
1-1) Mnist csvファイルのダウンロード
まず、Mnistデータセットを準備しましょう。
前の記事でも紹介しましたが、
Mnistとは‘Mixed National Institute of Standards and Technology database’の略語で手書き数字画像60,000枚と、テスト画像10,000枚を集めた画像データセットです。
前回同様、tensorflow.keras.datasets.mnistでMnistデータセットを簡単にロードできますが、
今回はMnistデータセットを私が作りたい形で変更してPickle形式で保存して利用しようと思っているので、
Mnist in CSV(kaggle)でMnistのcsvファイルをダウンロードしました。
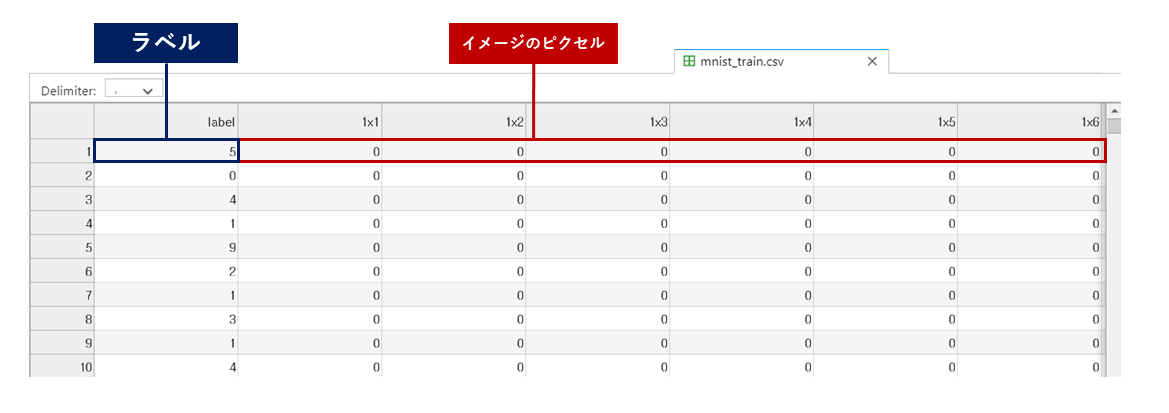
MnistのCSVファイルを開くと数字の羅列がされたデータなので、どのような意味を持ったファイルなのか画像処理初心者では把握するのが難しい印象です。
しかし、意味が分かれば難しくなく…
- 結論から言うとMnistのCSVファイルの1つの行は1つの画像情報に当たります。
- 各行の先頭の数字はラベルとしてその行のイメージがどんな数字か表示しています。
- それ以外の784個の数字は0~255の間の値(画素値)で縦横28×28(784)を表現しているにすぎません。
2-1) Pickle形式で保存
csvファイルそのまま使用して学習させても大丈夫ですが、Pickle形式のファイルで保存してみましょう。
Pickleはオブジェクトをファイルとして保存するものであり、保存時・読み込み時に特別な設定や処理をすることなくオブジェクトをそのまま読み書きできるという利点があるのでPickle形式で保存することが都合のいい場合があります。
csvファイルをPickle形式で保存するにはpandas.DataFrameを使うと簡単に作成できます。
( ※ tf.data.Datasetの活用が推奨されているようですが、今回の記事では説明を割愛します。)
(1) ライブラリのインポート
ライブラリをインポートします。
import os, sys
import csv
import numpy as np
import pandas as pd
import tensorflow as tf
pandasはPythonのデータ解析用のライブラリで機械学習ではデータの整理、可視化、前処理するため使います。
(2) データの読み込み
Mnistデータセットをダウンロード(URLは上記1-1参照)して保存したパスを指定しpd.read_csvでcsvファイルを読み込んでいます。
file = open("/Mnistデータセットが保存されているパス/mnist_train.csv")
data_train = pd.read_csv(file)
read_csv関数の引数で区切り文字の指定するsepやインデックスラベルの指定するindex_col等を設定することができますが、ここではcsvファイルを読み込むだけなので詳しい説明は省略します。
(3) イメージとラベルを分離してpandas.DataFrameへの変更
pythonのスライス記法という要素の指定方法でcsvファイルのイメージとラベルを分離します。
x_train = np.array(data_train.iloc[:, 1:]) # イメージのデータ
y_train = np.array(data_train.iloc[:, 0]) # ラベルのデータ
img_id = list(range(len(x_train)))
df = pd.DataFrame({'img_id':img_id,'mnist_img':list(x_train), 'mnist_label':list(y_train)})
pd.DataFrameは二次元の表形式のデータ(テーブルデータ)を取り扱う、pandasのインスタンスです。
(※ 一次元の表形式はpd.Seriesです。)
pd.DataFrameはまずPythonの辞書型データの定義した後、DataFrameを定義する流れになります。
-
Pythonの辞書型データの定義
{“キー”:list型のデータ,...}- 'キー'の数 = 列(Columns)の数
-
list型のデータの数 = 行(index)の数
-
作った辞書型データを
pd.DataFrameメソッドに引数として入力
x_tain, y_trainはデータ型はnumpy.ndarrayのため、上記の通りlist型で変更しなければpandas.DataFrameで保存できません。
display(df) # 確認
上記のコードで確認してみると下記の表ように画面で見目よい表示されます。
| img_id | mnist_img | mnist_label | |
|---|---|---|---|
| 0 | 0 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 5 |
| 1 | 1 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 0 |
| 2 | 2 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 4 |
| ... | ... | ... | ... |
| 59998 | 59998 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 6 |
| 59999 | 59999 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 8 |
60000 rows × 3 columns
(4) 指定したパスでPickle形式のファイルを保存
dataset_name = 'ファイルの名'
filename = '{}_train_df.pkl'.format(dataset_name)
filepath = os.path.join(ファイルまでのパス, filename)
df.to_pickle(filepath)
テストデータセットのファイルも同じ方法でPickle形式への保存ができますので、上のコードを参考して作成してください。
2. ジェネレータの実装
今回はオリジナルのクラスでジェネレータを実装します。
generator.pyというファイルにジェネレータを実装します。
ジェネレータとはイテレータ(;反復可能オブジェクト)の一種であり、1要素を取り出そうとする度に処理を行い、要素をジェネレートするタイプのものです。
AIのプログラムにおいては、モデルに数枚づつ画像を提供し続ける処理(ミニバッチ処理)が必要になる為、ジェネレータでその機能を実現します。
イテレータを理解すればジェネレータがどんなものかすぐわかると思いますので話が横道にそれますが、イテレータの起動についてしばらく説明します。
- オブジェクトの
__iter__()メソッドが呼ばれ、イテレータ実装を返すことが求められます。 - この返り値で得られたオブジェクトは
__next__()というメソッドが呼ばれます。 -
__next__()メソッドは1つずつ要素を取り出します。 -
__next__()メソッドはイテレータが尽きている場合、 default が与えられていればそれが返され、 そうでなければ StopIteration が送出されます。
下記のコードは私が作ったジェネレータの全体です。上記の内容を参考にコードの動作を考えてみると良いかと思われます。
以降でコードの重要な部分を少し詳しく説明します。
class BatchGenerator():
def __init__(self, df, shuffle = False, random_state = None):
self.data_list = df.to_dict(orient='records')
self.batch_size = 32
self.input_shape = (28, 28, 1)
self.img_size = 28
self.shuffle = shuffle
if random_state is None:
random_state = np.random.RandomState(1234)
self.random_state = random_state
self._idx = 0
self._reset()
def __len__(self):
N = len(self.data_list)
b = self.batch_size
return N // b + bool(N % b)
def __iter__(self):
return self
def __next__(self):
if self._idx >= len(self.data_list):
self._reset()
raise StopIteration()
selected_data_list = self.data_list[self._idx:(self._idx + self.batch_size)]
img_list = []
label_list = []
batch = {}
for data in selected_data_list:
img = self.load_img(data)
agu_img = self.data_augmentation(img)
agu_img = np.expand_dims(agu_img, axis=-1)
one_hot_labeled = self.one_hot_labeling(data)
img_list.append(agu_img)
label_list.append(one_hot_labeled)
batch['batch_id'] = np.asarray([i['img_id']for i in selected_data_list])
batch['batch_mnist_img'] = np.asarray(img_list)
batch['batch_mnist_label'] = np.asarray(label_list)
self._idx += self.batch_size
return batch
def _reset(self):
if self.shuffle:
self.data_list = shuffle(self.data_list, random_state=self.random_state)
self._idx = 0
def load_img(self, data):
img = data['mnist_img']
img = img/255.0
img = img.reshape(28, 28, 1)
img = img.astype('float32')
return img
def one_hot_labeling(self, data):
one_hot_label = tf.keras.utils.to_categorical(data['mnist_label'], num_classes=10)
return one_hot_label
def data_augmentation(self,image):
bg_value = np.median(image)
angle_1 = np.random.randint(-45, 45, 1)
mat_1 = cv2.getRotationMatrix2D((self.img_size/2, self.img_size/2), angle_1[0], 1)
affine_img = cv2.warpAffine(image, mat_1, (self.img_size, self.img_size), borderValue=(0, 0, 0))
tr_x = self.img_size*np.random.uniform()-self.img_size/2
tr_y = self.img_size*np.random.uniform()-self.img_size/2
mat_2 = np.array([[1,0,tr_x],[0,1,tr_y]], dtype=np.float32)
affine_img_translation = cv2.warpAffine(affine_img, mat_2, (self.img_size, self.img_size))
return affine_img_translation
2-1) データをbatch_sizeほど読み込み
__iter__()メソッドにより__next__()メソッドが呼ばれます。
__next__()メソッドでは設定したself.batch_sizeだけself.data_listからデータを取得します。
self.data_listはdf.to_dict(orient)が割り当てられていますが、これはpandas.DataFrameを辞書型(dict)に変換することです。
df.to_dict(orient)
引数
- orient : 以下の形式を指定することが可能です。
- dict(デフォルト) : keyが列ラベル、valueが行ラベルと値の辞書となる。
{column -> {index -> value}} - list:keyが列ラベル、valueが値のリストとなる。行名の情報は失われる。
{column -> [values]} - series:keyが列ラベル、valueが行ラベルと値のpandas.Seriesとなる。
{column -> Series(values)} - split:keyが'index', 'columns', 'data'となり、それぞれのvalueが行ラベル、列ラベル、値のリストとなる。
{index -> [index], columns -> [columns], data -> [values]} - records : keyが列ラベル、valueが値となる辞書を要素とするリストとなる。行名の情報は失われる。
[{column -> value}, ... , {column -> value}] - index:keyが行ラベル、valueが列ラベルと値の辞書となる。
{index -> {column -> value}}
- dict(デフォルト) : keyが列ラベル、valueが行ラベルと値の辞書となる。
戻り値
-
dict、listまたはcollections.abc.Mapping
2-2) データの前処理
load_imgとone_hot_labeling関数でデータの前処理を行います。Mnistのデータの普通の前処理流れはです。
(1) イメージの前処理
def load_img(self, data):
img = data['mnist_img']
img = img/255.0
img = img.reshape(28, 28, 1)
img = img.astype('float32')
return img
-
データを (600000, 784) から (60000,28,28,1)に
reshapeします。- 最後の1はチャンネルでグレースケール化するために追加します。
-
イメージを255.で割り算を行い、0~1に正規化(normalization)します。
- 正規化をすることで、精度がよくなります。
-
データ型を
float32で変更する。- ニューラル ネットワークをトレーニングする時は32ビット整数を使用するのが一般的なため、
float32で変更します。
- ニューラル ネットワークをトレーニングする時は32ビット整数を使用するのが一般的なため、
(2) ラベルの前処理
ラベルはOne-Hotエンコーディングします。One-Hotエンコーディングとはカテゴリカル変数に対して、各要素が該当するなら1、該当しないなら0とするカラムを変数の要素数分作ることです。
Mnistのラベルは[0 ~ 9]の10個の数字が存在するのでone-hot結果の次元数は10になります。
例えば、‘5’である正解ラベルをOne-Hotエンコーディング場合は、[0.,0.,0.,0.,0.,1.,0.,0.,0.,0.]になります。
One-hot表現のメリットとデメリットは下記の通りです。
| メリット | デメリット |
|---|---|
| 変数の全ての値を平等に扱えて、機械学習アルゴリズムの予想(prediction)結果向上 | 次元数が増えて、メモリ使用量や計算量が爆発的に増加 |
def one_hot_labeling(self, data):
one_hot_label = tf.keras.utils.to_categorical(data['mnist_label'], num_classes=10)
return one_hot_label
今回はkeras.utilsに実装されたto_categoricalを使います。
( ※ NumPyのeyeまたはidentity等もone-hot表現に変換できます。)
keras.utils.to_categorical(y, num_classes=None)
クラスベクトル(0からnb_classesまでの整数)をcategorical_crossentropyとともに用いるためのバイナリのクラス行列に変換します。
引数
- y: 行列に変換されるクラスベクトル(0からnum_classesまでの整数)
- num_classes: 総クラス数
戻り値
- 入力のバイナリ行列表現
2-3) DataAugumentation(データ拡張)
DataAugumentationとは学習データ(訓練データ)の画像に対して平行移動、拡大縮小、回転、ノイズの付与等の人為的に処理を加えてデータ水増しするテクニックです。機械学習における普遍的な課題である過学習(Overfitting)を予防する利点があります。
【過学習とは?】
統計学や機械学習において、あるデータ群を基につくったモデルが、そのデータ群に含まれない新しいデータ群に対しては、同水準の予測精度を示すことができない状態
DataAugumentationではtf.keras.preprocessing.image.ImageDataGeneratorを利用して簡単に色んな処理の実装ができますが、ここでは直接openCV(;画像や動画を処理するのに必要な、さまざま機能が実装されているライブラリ)を使ってイメージをを回転と平行移動の処理を加えてみました。
def data_augmentation(self,image):
bg_value = np.median(image)
# 回転の処理
angle_1 = np.random.randint(-45, 45, 1)
mat_1 = cv2.getRotationMatrix2D((self.img_size/2, self.img_size/2), angle_1[0], 1)
affine_img = cv2.warpAffine(image, mat_1, (self.img_size, self.img_size), borderValue=(0, 0, 0))
# 平行移動の処理
tr_x = self.img_size*np.random.uniform()-self.img_size/2
tr_y = self.img_size*np.random.uniform()-self.img_size/2
mat_2 = np.array([[1,0,tr_x],[0,1,tr_y]], dtype=np.float32)
affine_img_translation = cv2.warpAffine(affine_img, mat_2, (self.img_size, self.img_size))
return affine_img_translation
openCVを使うためにデータ型がnumpy.ndarrayである必要がありますが、これらのイメージは既にnumpy.ndarrayデータ型なので型変換はしなくても大丈夫です。
data_augmentation関数を適用したMnistは下のようになります。

左図は普通のMnistイメージで右図は回転と平行移動の処理されたイメージです。openCVを利用するこのように画像で細かいAugmentation処理を加えることができることがわかります。
3. Subclassing APIによるモデルを作成
TendorFlow 2.0以降ではモデルを構築する方法がSequential API、Functional API、Subclassing API 3つあります。各々の詳しい説明は前回の記事を参考してください。ここでは優柔なモデルを構築するため、3つの中で一番優柔性が高いKerasのmodel Subclassing APIを使ってtf.kerasモデルを作ります。
3-1) モデルの構築
モデルの構成は25 Million Images! (0.99757) MNISTを参考に作成してみました。モデルの具体的な実装方法を知りたい方は前回の記事をご覧ください。
class ClassificationModel(tf.keras.Model):
def __init__(self):
super(ClassificationModel, self).__init__()
self.conv1_1 = layers.Conv2D(32, 3, activation='relu')
self.conv1_2 = layers.BatchNormalization()
self.conv1_3 = layers.Conv2D(32, 3, activation='relu')
self.conv1_4 = layers.BatchNormalization()
self.conv1_5 = layers.Conv2D(32, 5, strides=2, padding='same', activation='relu')
self.conv1_6 = layers.BatchNormalization()
self.drop1 = layers.Dropout(0.4)
self.conv2_1 = layers.Conv2D(64, 3, activation='relu')
self.conv2_2 = layers.BatchNormalization()
self.conv2_3 = layers.Conv2D(64, 3, activation='relu')
self.conv2_4 = layers.BatchNormalization()
self.conv2_5 = layers.Conv2D(64, 5, strides=2, padding='same', activation='relu')
self.conv2_6 = layers.BatchNormalization()
self.drop2 = layers.Dropout(0.4)
self.conv3_1 = layers.Conv2D(128, kernel_size = 4, activation='relu')
self.conv3_2 = layers.BatchNormalization()
self.conv3_3 = layers.Flatten()
self.drop3 = layers.Dropout(0.4)
self.d3 = layers.Dense(10, activation='softmax')
def call(self, x):
x = self.conv1_1(x)
x = self.conv1_2(x)
x = self.conv1_3(x)
x = self.conv1_4(x)
x = self.conv1_5(x)
x = self.conv1_6(x)
x = self.drop1(x)
x = self.conv2_1(x)
x = self.conv2_2(x)
x = self.conv2_3(x)
x = self.conv2_4(x)
x = self.conv2_5(x)
x = self.conv2_6(x)
x = self.drop2(x)
x = self.conv3_1(x)
x = self.conv3_2(x)
x = self.conv3_3(x)
x = self.drop3(x)
return self.d3(x)
3-2) モデルのビルド
model = ClassificationModel()
model.build((32, 28, 28, 1))
model.summary()
-
model.build()メソッド : 重みを定義するメソッド -
model.summary()メソッド : 作成すると作ったモデルの構成を簡単確認ができるメソッド
Model: "classification_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 320
_________________________________________________________________
batch_normalization (BatchNo multiple 128
_________________________________________________________________
conv2d_1 (Conv2D) multiple 9248
_________________________________________________________________
batch_normalization_1 (Batch multiple 128
_________________________________________________________________
conv2d_2 (Conv2D) multiple 25632
_________________________________________________________________
batch_normalization_2 (Batch multiple 128
_________________________________________________________________
dropout (Dropout) multiple 0
_________________________________________________________________
conv2d_3 (Conv2D) multiple 18496
_________________________________________________________________
batch_normalization_3 (Batch multiple 256
_________________________________________________________________
conv2d_4 (Conv2D) multiple 36928
_________________________________________________________________
batch_normalization_4 (Batch multiple 256
_________________________________________________________________
conv2d_5 (Conv2D) multiple 102464
_________________________________________________________________
batch_normalization_5 (Batch multiple 256
_________________________________________________________________
dropout_1 (Dropout) multiple 0
_________________________________________________________________
conv2d_6 (Conv2D) multiple 131200
_________________________________________________________________
batch_normalization_6 (Batch multiple 512
_________________________________________________________________
flatten (Flatten) multiple 0
_________________________________________________________________
dropout_2 (Dropout) multiple 0
_________________________________________________________________
dense (Dense) multiple 1290
=================================================================
Total params: 327,242
Trainable params: 326,410
Non-trainable params: 832
_________________________________________________________________
3-3) 損失関数・オプティマイザの定義
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
4. 学習
まず、先ほどの作ったgenerator.pyを呼び出すために、インポートします。
今回のケースでは./data/にgenerator.pyを配置しています。
from data.generator import BatchGenerator
そして、保存したpickle形式のファイルを読み込みます。
train_df = pd.read_pickle("/フォルダのパス/指定したファイルの名_train_df.pkl")
インポートしたジェネレータを定義しましょう。
train_gen = BatchGenerator(train_df, config)
batch = next(train_gen)
学習とテストを行います。
@tf.function
def train_step(x, t):
with tf.GradientTape() as tape:
predictions = model(x, training=True)
loss = loss_object(t, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(t, predictions)
@tf.function
def test_step(x, t):
test_predictions = model(x)
t_loss = loss_object(t, test_predictions)
test_loss(t_loss)
test_accuracy(t, test_predictions)
EPOCHS = 5
for epoch in range(EPOCHS):
for batch in tqdm(train_gen):
x = batch['batch_mnist_img']
t = batch['batch_mnist_label']
t = np.argmax(t, axis=1).reshape(-1,1)
train_step(x, t) #学習
for batch in tqdm(train_gen):
x = batch['batch_mnist_img']
t = batch['batch_mnist_label']
t = np.argmax(t, axis=1).reshape(-1,1)
test_step(x, t) #テスト
template = 'Epoch {}, Loss: {}, Accuracy: {}, test-Loss: {}, test-Accuracy:{}'
print(template.format(epoch + 1,
train_loss.result(),
train_accuracy.result() * 100,
test_loss.result(),
test_accuracy.result()*100))
5. 分類モデルの評価
分類モデルを未知データ(;あるモデルの訓練データに含まれない新しいデータ群)を利用して評価しましょう。そのため、先ほどの作ったpickle形式のテストデータを読み込みます。
test_df = pd.read_pickle("/テストデータが保存されているパス/ファイル名_test_df.pkl")
display(test_df)
| img_id | mnist_test_img | mnist_real_label | |
|---|---|---|---|
| 0 | 0 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 7 |
| 1 | 1 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 2 |
| 2 | 2 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 1 |
| ... | ... | ... | ... |
| 9998 | 9998 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 5 |
| 9999 | 9999 | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... | 6 |
10000 rows × 3 columns
今回はジェネレータを利用せずに、評価用のデータを準備します。
img_id = pd.Series.tolist(test_df['img_id'])
mnist_test_img = pd.Series.tolist(test_df['mnist_test_img'])
mnist_test_label= pd.Series.tolist(test_df['mnist_real_label'])
mnist_test_img_list = [] #イメージ
mnist_test_label_list = [] #ラベル
for i in range(len(img_id)):
mnist_test_img_list.append((mnist_test_img[i].reshape(28,28,1))/255.)
mnist_test_label_list.append(mnist_test_label[i])
分類モデルの評価に次のような指標を使います。
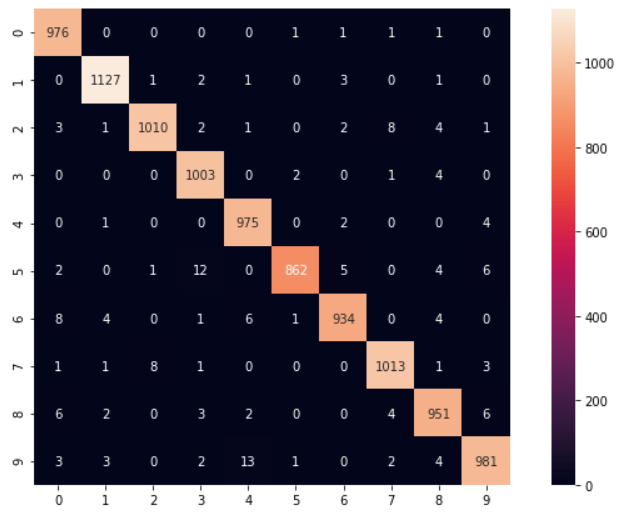
5-1) 混同配列
まずは、混同配列です。混同行列の主対角成分の要素は、正確にクラス分類されたサンプル数を示し、それ以外の要素は、実際とは違うクラスに分類されたサンプル数を示します。
混同配列を作るにはsklearnライブラリまたはseabornライブラリを利用することができます。
(1) sklearnライブラリを利用する方法
scikit-learnは、分類、回帰、クラスタリング等が実装されているPythonの機械学習ライブラリです。scikit-learnライブラリを読み込む時はsklearnと書きます。
from sklearn.metrics import confusion_matrix
y_true = np.asarray(mnist_test_label_list)
y_pred = model(np.asarray(mnist_test_img_list))
y_pred = np.argmax(y_pred, axis=1) #reshape(-1,1)
confusion_matrix(y_true, y_pred)
array([[ 976, 0, 0, 0, 0, 1, 1, 1, 1, 0],
[ 0, 1127, 1, 2, 1, 0, 3, 0, 1, 0],
[ 3, 1, 1010, 2, 1, 0, 2, 8, 4, 1],
[ 0, 0, 0, 1003, 0, 2, 0, 1, 4, 0],
[ 0, 1, 0, 0, 975, 0, 2, 0, 0, 4],
[ 2, 0, 1, 12, 0, 862, 5, 0, 4, 6],
[ 8, 4, 0, 1, 6, 1, 934, 0, 4, 0],
[ 1, 1, 8, 1, 0, 0, 0, 1013, 1, 3],
[ 6, 2, 0, 3, 2, 0, 0, 4, 951, 6],
[ 3, 3, 0, 2, 13, 1, 0, 2, 4, 981]])
(※ 結果は実装したゼネレーターやモデルによって異なります。)
(2) seabornライブラリを利用する方法
seabornはデータの可視化(グラフ作成)を行うPythonライブラリです。sklearnライブラリを利用すると結果は同じですが、sklearnライブラリより視覚的に見えます。インポート文でseaborn書くことで使用できます。
import seaborn as sn
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
def print_cmx(y_true, y_pred):
labels = sorted(list(set(y_true)))
cmx_data = confusion_matrix(y_true, y_pred, labels=labels)
df_cmx = pd.DataFrame(cmx_data, index=labels, columns=labels)
plt.figure(figsize = (12,7))
sn.heatmap(df_cmx, annot=True, fmt='g' ,square = True)
plt.show()
print_cmx(y_true , y_pred)
(※ 結果は実装したジェネレーターやモデル、乱数によって異なります。)
5-2) 精度(正解率)
精度は、すべてのサンプルについて、正確に予測できた割合を示します。
from sklearn.metrics import accuracy_score
print('正解率(accuracy):', accuracy_score(y_true, y_pred))
正解率(accuracy): 0.9832
(※ 結果は実装したジェネレーターやモデル、乱数によって異なります。)
感覚的にはこの指標が一番分かりやすいですが、陽性クラスと陰性クラスでサンプル数に大きな差があるとき、うまく性能を表せない場合があります。それで他の指標で確認する必要があります。
5-3) 適合率
適合率は、陽性であると予測されたものが、実際にどのくらい陽性だったのかを示す指標です。偽陽性と予測することを低く抑えたい場合は、適合率を用います。
from sklearn.metrics import accuracy_score
print('正解率(accuracy):', accuracy_score(y_true, y_pred))
適合率(precision): 0.9832536618523209
(※ 結果は実装したジェネレーターやモデル、乱数によって異なります。)
5-4) 再現率
再現率は、実際に陽性のサンプルのうち、どのくらい陽性と予測されたかを示す指標です。偽陰性と予測することを低く抑えたい場合は、再現率を用います。
from sklearn.metrics import recall_score
print('再現率(recall):',recall_score(y_true, y_pred, average='macro'))
再現率(recall): 0.9828852947538065
(※ 結果は実装したジェネレーターやモデル、乱数によって異なります。)
5-5) F1値
適合率と再現率は重要な指標ですが、片方だけではモデルの全体像が把握できません。この2つの指標をまとめた評価指標がF値で、適合率と再現率の調和平均がF1値です。
from sklearn.metrics import f1_score
print('F1値(F1-measure):',f1_score(y_true, y_pred, average='macro'))
F1値(F1-measure): 0.9830195547575524
(※ 結果は実装したジェネレーターやモデル、乱数によって異なります。)
6. まとめ
前回の記事より多くのpythonライブラリを利用して画像分類モデル実装・学習・評価しました。
またPytorchの書き方に似ているSubclass APIによるモデルを実装したため、Pytorchユーザーにも馴染みやすい書き方だったと思います。
ぜひ試してみてください。
以上です。
記事に誤り等ありましたら、ご指摘ください。