2022/12/20:irisデータセットの実行結果も追加。(multiも実行可能です)

はじめに
AutoGluonは、Amazon Web Services(AWS)が開発しているMXNetというディープラーニングフレームワークがベースのAutoMLライブラリです。
機械学習モデルの構築するだけでなく、それらを基本的なモデルとして積み重ねる、多層スタックアンサンブルにより新たなモデルも構築してくれます。
何ができるかは、以下の記事にわかりやすく紹介されています。
https://pages.awscloud.com/rs/112-TZM-766/images/1.AWS_AutoML_AutoGluon.pdf
この記事から一部引用させていただきます。
AutoGlounの探索対象範囲は以下です。


これをみると、データを与え → 最適なモデルを導く までの過程は、ほぼおまかせできる感じです。すごいですね。
本記事では、テーブルデータを対象としたAutoGluon-TabularをGoogleColabで実行します。
いくつかのデータセットを読み込めるようにセットし、読込んだデータを訓練データとテストデータに分割してAutoGluonに与えます。
その後、AutoGlounを実行し、モデル比較のサマリー、特徴量重要度、評価指標や予測値の表示します。
実行はノーコードです。いくつかの設定をドロップダウンとスライドバーで指定するだけです。
実行条件など
-Google colabで実行
-任意のデータセットとsklearn等のデータセットを読み出せるようにしています。
実行
1.読み込むデータセットとデータセットのタイプを設定します

2.データを読み込みます。
以下は、BostonHousingデータセット(回帰)を読み込んだ際の表示です
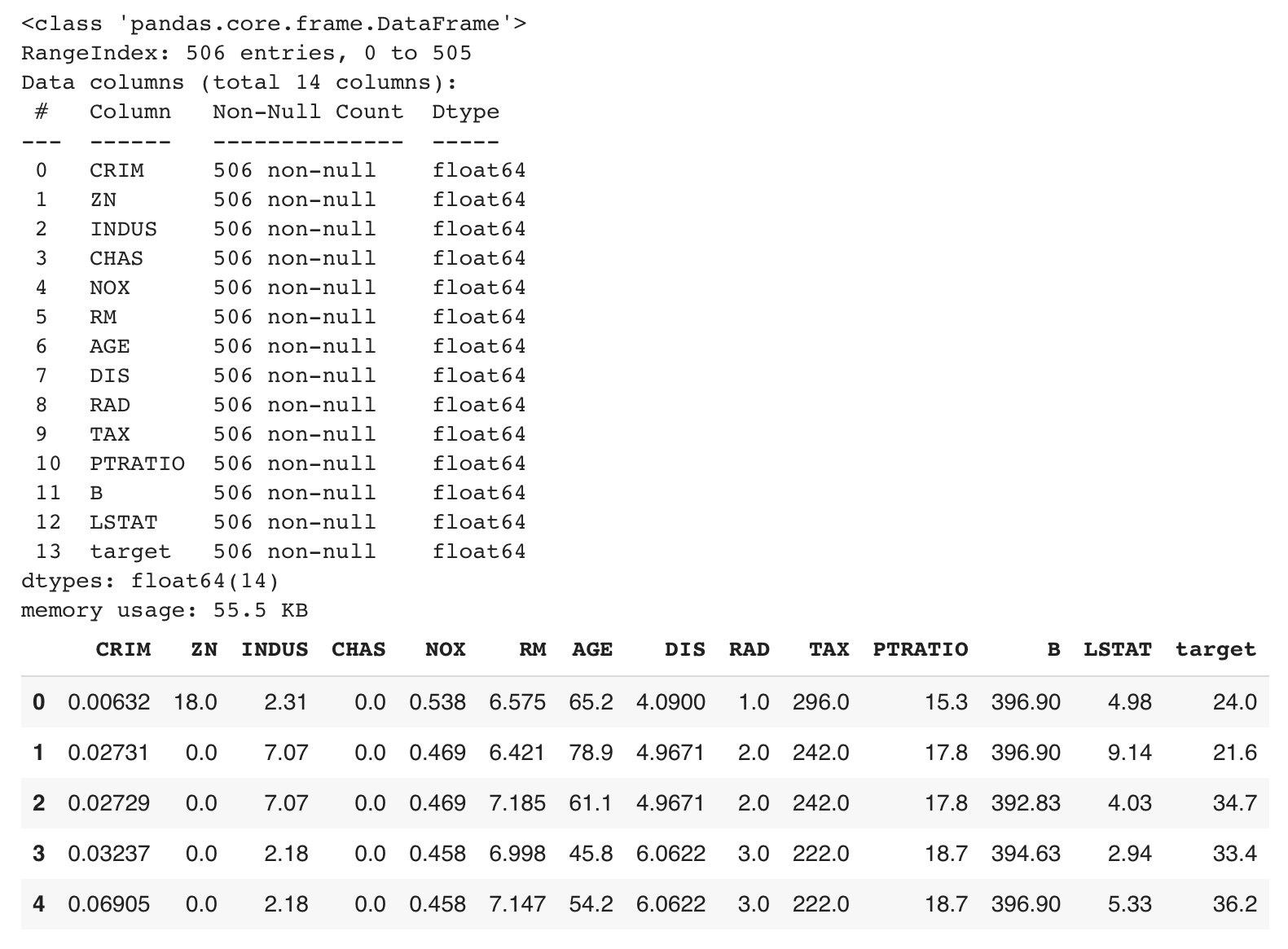
3.データクリーニングを実行します。
実装しているのは必要最小限のクリーニング項目だけです。AutoGlounはデータ前処理も実行してくれますので、スルーしていただいてもいいかもしれません。
実装しているクリーニング項目は以下です
1.記号識別され欠損データをN.A.(NaN)に置換、2.不要なデータ項目の削除、3.欠損データを含む行を削除、4.カテゴリーデータ項目を Labelエンコード、5.すべての Obeject_col を Label encord、6.データ項目名を英訳
BostonHousingデータセットは、データ型がすべて数値(float64)で欠損値のない完全データなので、このデータクリーニングはスルーしています。
4.AutoGluon
精度優先度をpreset_typeで、制限時間をtime_limitで選択します。

preset_type の選択肢は次の通りです。上から精度優先、3つ目がデフォルト、下にいくほど速度優先です。
- best_quality
- best_quality_with_high_quality_refit
- high_quality_fast_inference_only_refit
- medium_quality_faster_train
- optimize_for_deployment
実行すると、以下のような学習プログレスが示されます。
Presets specified: ['best_quality']
Stack configuration (auto_stack=True): num_stack_levels=0, num_bag_folds=5, num_bag_sets=1
Beginning AutoGluon training ...
AutoGluon will save models to "AutoGloun_section/"
AutoGluon Version: 0.6.2b20221217
Python Version: 3.8.16
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP Fri Aug 26 08:44:51 UTC 2022
Train Data Rows: 379
Train Data Columns: 13
Label Column: target
Preprocessing data ...
AutoGluon infers your prediction problem is: 'regression' (because dtype of label-column == float and many unique label-values observed).
Label info (max, min, mean, stddev): (50.0, 5.0, 22.34459, 8.92093)
If 'regression' is not the correct problem_type, please manually specify the problem_type parameter during predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
(以下省略)
実行完了すると、結果が表示されます。
AutoGluon training complete, total runtime = 121.44s ... Best model: "WeightedEnsemble_L2"
TabularPredictor saved. To load, use: predictor = TabularPredictor.load("AutoGloun_section/")
判定結果
AutoGlounは、データが分類問題か回帰問題かや各データ項目のデータ型が何かを推測してくれます。
また、推測内容を呼び出すことができますので、最適モデルとともに表示させたのが以下です。

leaderboard
これは、モデル比較結果のサマリーです。これもAutoGloun実行後、簡単に呼び出せます。

Parmutation importance
特徴量重要度とありますが、“特徴量をシャッフルして”導かれているようなので、Parmutation importanceだと思います。

seabornでグラフ表示しています。

5.モデル評価・予測
BostonHousingデータセットでの実行結果は以下の通りです。
評価尺度もAutoGlounから呼び出すことはできますが、これはsklearnライブラリを利用しています。

分類データで実行した場合は、以下のように混同行列とClassificationReportを表示します。
これは、datasetでTitanic(seaborn):binary を選択して実行した結果です。このデータには文字列や欠損値が混在しています。あらかじめ実装した前処理(データクリーニング)は実行せず、すべてAutoGlounに任せています。

2022/12/20追記
irisデータセットでも実行しました。設定は、preset_type:high_quality_fast_inference_only_refit(デフォルト)time_limit:100 です。テストデータのスコアは、以下の通り完璧!です。

testデータ予測値
最適モデルにtestデータの特徴量Xを与えた時の目的変数yの値をpred、実際の値をtrueとし、データフレームに格納して表示させています。☑︎で、このデータをcsv保存できます。

最後に
この記事では、Boston(回帰データ)とTitanic(分類データ)でAutoGlounを実行しました。
訓練データとテストデータの分割は行いましたが、あとは完全にAutoGlounまかせです。あらかじめいくつかの前処理も準備しましたが、不要でした。^_^;
前回の記事では、同じデータでTPOTを適用しました。
これはこれですごいのですが、TPOTは最低限の前処理は必要です。私の前処理が中途半端ということもあると思いますが、いずれのデータセットもまかせっぱなしのAutoGlounのスコアの方が勝りました。
上記の前処理やスタッキング(積み重ね)学習までを手離しでしてくれるいうのはすごいです。
分析者が選択するのは、精度や学習コスト(時間)をどの程度にするかが主です。
このアプローチ含め、機械学習がより身近なものになる可能性を感じさせてくれるライブラリだと思います。
実行コード
ライブラリのインストール
!pip install --upgrade pip
!pip install --upgrade setuptools
!pip install --upgrade "mxnet<2.0.0"
!pip install --pre autogluon
!pip install googletrans==4.0.0-rc1 --quiet
#matplotlib日本語化
!pip install japanize-matplotlib
import japanize_matplotlib
データセット読込み
データセットとデータセットタイプ(分類か回帰)選択のフォームセット
#@title Select_Dataset { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset_type = 'Regression' #@param ["Classification", "Regression"]
dataset = 'Boston_housing :regression' #@param ['Boston_housing :regression', 'Diabetes :regression', 'Breast_cancer :binary','Titanic :binary', 'Titanic(seaborn) :binary', 'Iris :classification', 'Loan_prediction :binary','wine :classification', 'Occupancy_detection :binary', 'Upload']
データセット読み込み→データセットのインフォと先頭5行表示
#@title Load dataset
#ライブラリインポート
import numpy as np
import pandas as pd #データを効率的に扱うライブラリ
import seaborn as sns #視覚化ライブラリ
import warnings #警告を表示させないライブラリ
warnings.simplefilter('ignore')
'''
dataset(ドロップダウンメニュー)で選択したデータセットを読込み、データフレーム(df)に格納。
目的変数は、データフレームの最終列とし、FEATURES、TARGET、X、yを指定した後、データフレーム
に関する情報と先頭5列を表示。
任意のcsvデータを読込む場合は、datasetで'Upload'を選択。
'''
#任意のcsvデータ読込み及びデータフレーム格納、
if dataset =='Upload':
from google.colab import files
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target)
#Diabetes データセットの読込み及びデータフレーム格納、
elif dataset == "Diabetes :regression":
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns = diabetes.feature_names)
df['target'] = diabetes.target
#Breast_cancer データセットの読込み及びデータフレーム格納、
elif dataset == "Breast_cancer :binary":
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
df = pd.DataFrame(breast_cancer.data, columns = breast_cancer.feature_names)
#df['target'] = breast_cancer.target #目的変数をカテゴリー数値とする時
df['target'] = breast_cancer.target_names[breast_cancer.target]
#Titanic データセットの読込み及びデータフレーム格納、
elif dataset == "Titanic :binary":
data_url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
df = pd.read_csv(data_url)
#目的変数 Survived をデータフレーム最終列に移動
X = df.drop(['Survived'], axis=1)
y = df['Survived']
df = pd.concat([X, y], axis=1) #X,yを結合し、dfに格納
#Titanic(seaborn) データセットの読込み及びデータフレーム格納、
elif dataset == "Titanic(seaborn) :binary":
df = sns.load_dataset('titanic')
#重複データをカットし、目的変数 alive をデータフレーム最終列に移動
X = df.drop(['survived','pclass','embarked','who','adult_male','alive'], axis=1)
y = df['alive'] #目的変数データ
df = pd.concat([X, y], axis=1) #X,yを結合し、dfに格納
#iris データセットの読込み及びデータフレーム格納、
elif dataset == "Iris :classification":
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns = iris.feature_names)
#df['target'] = iris.target #目的変数をカテゴリー数値とする時
df['target'] = iris.target_names[iris.target]
#wine データセットの読込み及びデータフレーム格納、
elif dataset == "wine :classification":
from sklearn.datasets import load_wine
wine = load_wine()
df = pd.DataFrame(wine.data, columns = wine.feature_names)
#df['target'] = wine.target #目的変数をカテゴリー数値とする時
df['target'] = wine.target_names[wine.target]
#Loan_prediction データセットの読込み及びデータフレーム格納、
elif dataset == "Loan_prediction :binary":
data_url = "https://github.com/shrikant-temburwar/Loan-Prediction-Dataset/raw/master/train.csv"
df = pd.read_csv(data_url)
#Occupancy_detection データセットの読込み及びデータフレーム格納、
elif dataset =='Occupancy_detection :binary':
data_url = 'https://raw.githubusercontent.com/hima2b4/Auto_Profiling/main/Occupancy-detection-datatest.csv'
df = pd.read_csv(data_url)
df['date'] = pd.to_datetime(df['date']) #[date]のデータ型をdatetime型に変更
#Boston データセットの読込み及びデータフレーム格納
else:
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns = boston.feature_names)
df['target'] = boston.target
#データフレーム表示
df.info(verbose=True) #データフレーム情報表示(verbose=Trueで表示数制限カット)
df.head() #データフレーム先頭5行表示
データクリーニング
AutoGlounは、前処理も実行してくれますので、必要になるのは「データ項目の削除」くらいかと思います。
不要なデータ項目の削除(項目名を指定し削除|7割以上が欠損値の項目を削除☑)
#@title 不要なデータ項目の削除(項目名を指定し削除|7割以上が欠損値の項目を削除☑)
#@markdown **<font color= "Crimson">注意</font>:Drop_label_is(カラムを指定して削除)の記載は <u> ' ID ' , ' Age ' </u> などとしてください。**</font>
Drop_label_is = 'sibsp', 'parch'#@param {type:"raw"}
try:
if Drop_label_is is not "":
Drop_label_is = pd.Series(Drop_label_is)
print('-----------------------------------------------------------------------------------------')
print("Drop of specified column:", Drop_label_is.values)
df.drop(columns=list(Drop_label_is),axis=1,inplace=True)
else:
print('※削除カラムの指定なし→処理スキップ')
except:
print("※正常に処理されませんでした。入力に誤りがないか確認してください。")
#データの7割以上が欠損値のカラムを削除(☑ =実行)
Over_70percent_missing_value_is_drop = True #@param {type:"boolean"}
#各列ごとに、7割欠損がある列を削除
if Over_70percent_missing_value_is_drop == True:
for col in df.columns:
nans = df[col].isnull().sum() # nanになっている行数をカウント
# nan行数を全行数で割り、7割欠損している列をDrop
if nans / len(df) > 0.7:
# 7割欠損列を削除
print('-----------------------------------------------------------------------------------------')
print("Drop of missing 70% column:", col)
df.drop(col, axis=1, inplace=True)
print('-----------------------------------------------------------------------------------------')
df.head()
欠損データを含む行を削除(☑ =実行)
#@title 欠損データを含む行を削除(☑ =実行)
Null_Drop = True #@param {type:"boolean"}
if Null_Drop == True:
df = df.dropna(how='any')
df.head()
カテゴリーデータ項目を Labelエンコード(対象:Dtype が int64, float64 以外のデータ項目)
#@title カテゴリーデータ項目を Labelエンコード(**対象:Dtype が int64, float64 以外のデータ項目**)
#@markdown **<font color= "Crimson">注意</font>:指定は <u> ' ID ' , ' Age ' , </u> などとしてください。**
Object_label_to_encode_is = '', '', '' #@param {type:"raw"}
Object_label_to_encode_is = pd.Series(Object_label_to_encode_is)
from sklearn.preprocessing import LabelEncoder
encoders = dict()
try:
for i in Object_label_to_encode_is:
if Object_label_to_encode_is is not "":
series = df[i]
le = LabelEncoder()
df[i] = pd.Series(
le.fit_transform(series[series.notnull()]),
index=series[series.notnull()].index
)
encoders[i] = le
print('-----------------------------------------------------------------------------------------')
print('[エンコードカラム]:',i)
le_name_mapping = dict(zip(le.classes_, le.transform(le.classes_)))
print(le_name_mapping)
else:
print('skip')
except:
print("※正常に処理されなかった場合は入力に誤りがないか確認してください。")
print('-----------------------------------------------------------------------------------------')
df.head()
すべての Obeject_col を Label encord(☑ =実行)
#@title すべての Obeject_col を Label encord(☑ =実行)
Encord_all_object_label = True #@param {type:"boolean"}
from sklearn.preprocessing import LabelEncoder
if Encord_all_object_label == True:
le = LabelEncoder()
for col in df.columns:
if df[col].dtype == 'object':
df[col] = le.fit_transform(df[col].astype(str))
print('-----------------------------------------------------------------------------------------')
print(col)
print(le.classes_, "= [0, 1, 2...]" )
# else:
# print(col,':エンコードしない→処理スキップ')
print('-----------------------------------------------------------------------------------------')
df.head()
データ項目名を英訳(☑ =実行)
#@title データ項目名を英訳(☑ =実行)
Column_English_translation = False #@param {type:"boolean"}
from googletrans import Translator
if Column_English_translation == True:
eng_columns = {}
columns = df.columns
translator = Translator()
for column in columns:
eng_column = translator.translate(column).text
eng_column = eng_column.replace(' ', '_')
eng_columns[column] = eng_column
df.rename(columns=eng_columns, inplace=True)
print('-----------------------------------------------------------------------------------------')
print('[カラム名_翻訳結果(翻訳しない場合も表示)]')
print('-----------------------------------------------------------------------------------------')
df.head(0)
AutoGluon
AutoGluon実行
#@title **AutoGluon実行**
#@markdown **<font color= "Crimson">注意</font>: best_quality は精度優先 ⇔ time_limit は速度優先**</font>
preset_type = 'best_quality' #@param ["best_quality", "time_limit"]
from autogluon.tabular import TabularDataset, TabularPredictor
#FEATURES、TARGET、X、yを指定
FEATURES = df.columns[:-1] #説明変数のデータ項目を指定
TARGET = df.columns[-1] #目的変数のデータ項目を指定
X = df.loc[:, FEATURES] #FEATURESのすべてのデータをXに格納
y = df.loc[:, TARGET] #TARGETのすべてのデータをyに格納
#testとtrainを分割
from sklearn.model_selection import train_test_split
if dataset_type == 'Classification':
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 1, stratify = y)
else:
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 1, test_size=0.25)
train_data = pd.concat([X_train, y_train], axis=1)
test_data = pd.concat([X_test, y_test], axis=1)
predictor = TabularPredictor(label=TARGET, path='AutoGloun_section')
if preset_type == 'best_quality':
predictor.fit(train_data, presets="best_quality")
else:
predictor.fit(train_data, time_limit=60)
AutoGluon 判定結果
#@title AutoGluon 判定結果
import pprint
print("Best_model:",predictor.get_model_best())
print('-----------------------------------------------------------------------------------------')
print("AutoGluonが推察した問題のタイプ:", predictor.problem_type)
print('-----------------------------------------------------------------------------------------')
print("AutoGluonが各特徴量に対して推察したデータの型:")
pprint.pprint(predictor.feature_metadata.to_dict())
#@title leaderboard
leaderboard = predictor.leaderboard(test_data)
#display(leaderboard)
#@title Permutation Importance
predictor_importance = predictor.feature_importance(test_data)
print('-----------------------------------------------------------------------------------------')
print("Permutation Importance:")
display(predictor_importance)
import seaborn as sns
sns.set(rc = {'figure.figsize':(8.3,4)})
sns.set_style('whitegrid') #style指定
sns.set(font='IPAexGothic')
sns.barplot(y=predictor_importance.index, x='importance',data=predictor_importance);
モデル評価
#@title **モデル評価**
#指標関連ライブラリインストール
from sklearn.metrics import r2_score # 決定係数
from sklearn.metrics import mean_squared_error # RMSE
from sklearn.metrics import mean_absolute_error #MAE
from sklearn.metrics import f1_score #F1スコア
from sklearn.metrics import confusion_matrix #混同行列
from sklearn.metrics import classification_report #classification report
import matplotlib.pyplot as plt
y_test_pred = predictor.predict(X_test)
y_train_pred = predictor.predict(X_train)
if dataset_type == 'Classification':
print('Confusion matrix_test')
#混同行列
sns.set(rc = {'figure.figsize':(1.5,1.5)})
sns.heatmap(confusion_matrix(y_test,y_test_pred),
square=True, cbar=True, annot=True, cmap='Blues',fmt='g')
plt.xlabel('Predicted', fontsize=11)
plt.ylabel('Actual', fontsize=11)
plt.show()
print('-----------------------------------------------------------------------------------------')
print('Classification report_test')
print(classification_report(y_true=y_test, y_pred=y_test_pred))
else:
print('Regression report')
print('-----------------------------------------------------------------------------------------')
print(' RMSE\t train: %.2f,\t test: %.2f' % (
mean_squared_error(y_train, y_train_pred, squared=False),
mean_squared_error(y_test, y_test_pred, squared=False)))
print(' MAE\t train: %.2f,\t test: %.2f' % (
mean_absolute_error(y_train, y_train_pred),
mean_absolute_error(y_test, y_test_pred)))
print(' R²\t train: %.2f,\t test: %.2f' % (
r2_score(y_train, y_train_pred), # 学習
r2_score(y_test, y_test_pred) # テスト
))
print('-----------------------------------------------------------------------------------------')
plt.figure(figsize = (5,5))
plt.title('Prediction Accuracy')
ax = plt.subplot(111)
ax.scatter(y_test, y_test_pred,alpha=0.7)
ax.set_xlabel('y_test')
ax.set_ylabel('y_test_pred')
ax.plot(y_test,y_test,color='red',alpha =0.5)
plt.show()
#@title testデータ予測(☑ =csv保存実行)
csv_output = False #@param {type:"boolean"}
#y_pred = predictor.predict(X_test)
result = pd.concat([y_test,y_test_pred],axis=1, keys=['true','pred'])
#csv出力
if csv_output == True:
result.to_csv('pred_test_data.csv',encoding='utf_8_sig',index=False)
from google.colab import files
files.download('pred_test_data.csv')
result